What Do Deepfake Benchmarks Measure? An Audit Using Frozen Self-Supervised Representations
Pith reviewed 2026-06-26 01:22 UTC · model grok-4.3
The pith
Deepfake benchmarks largely reward general modality understanding rather than forensic skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
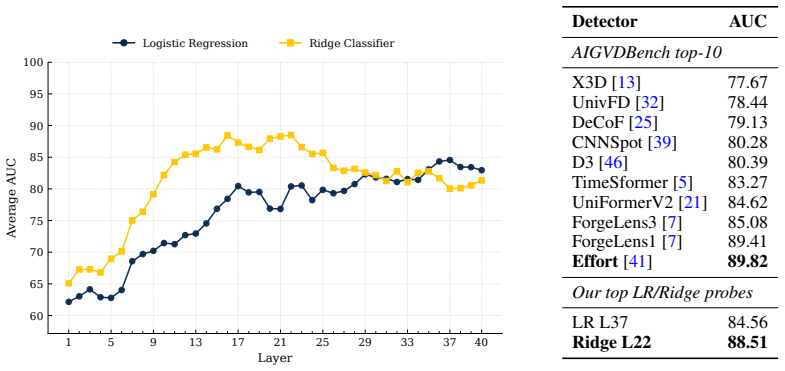
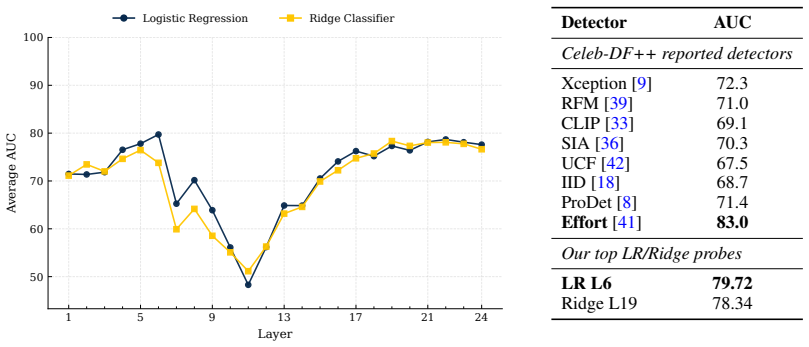
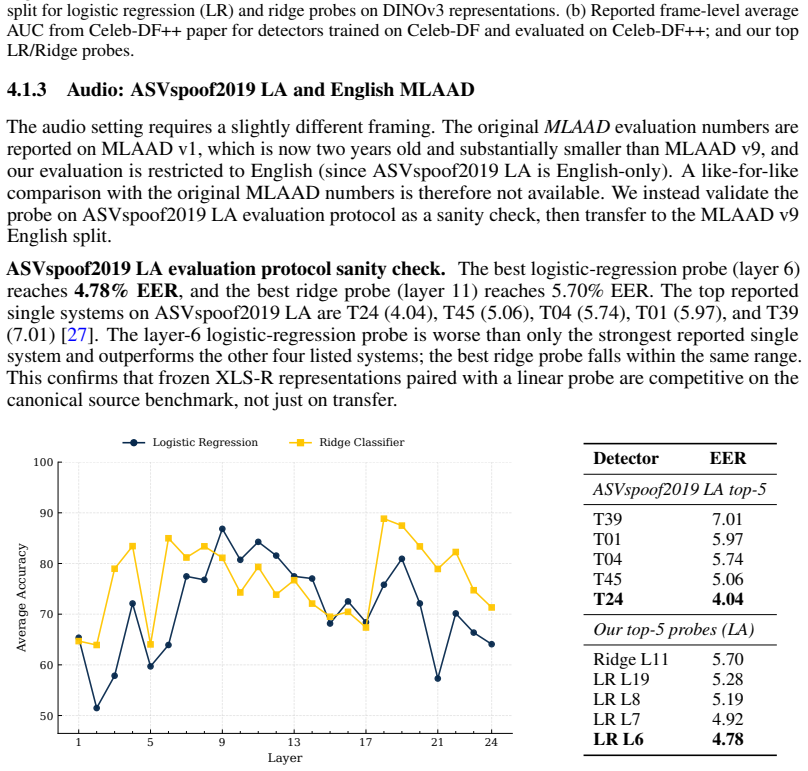
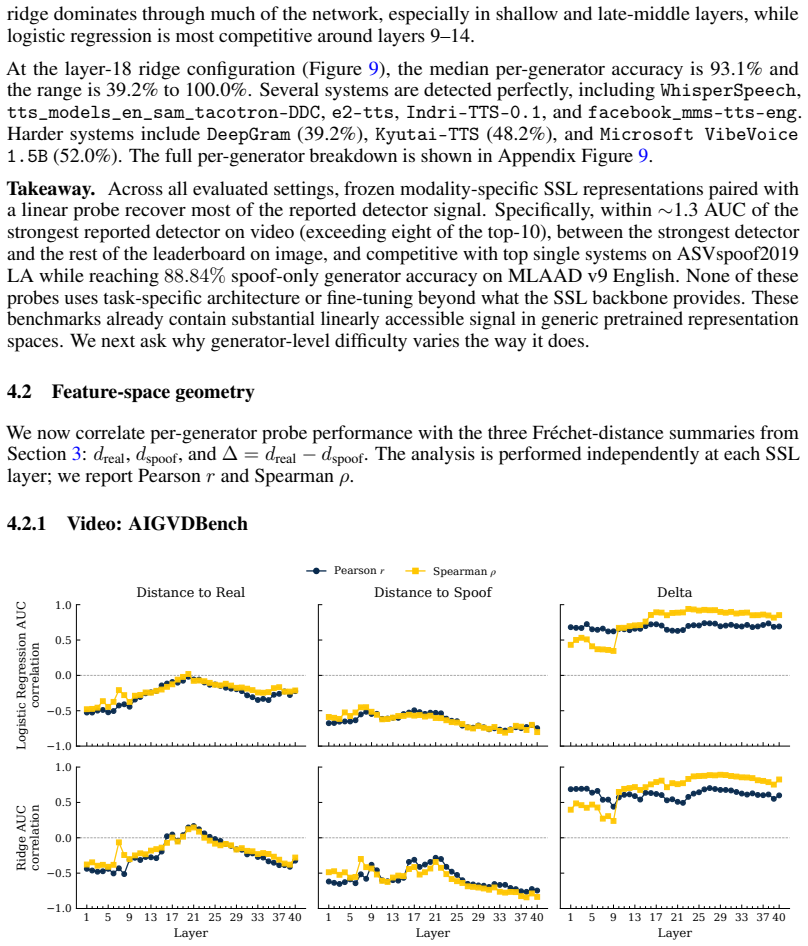
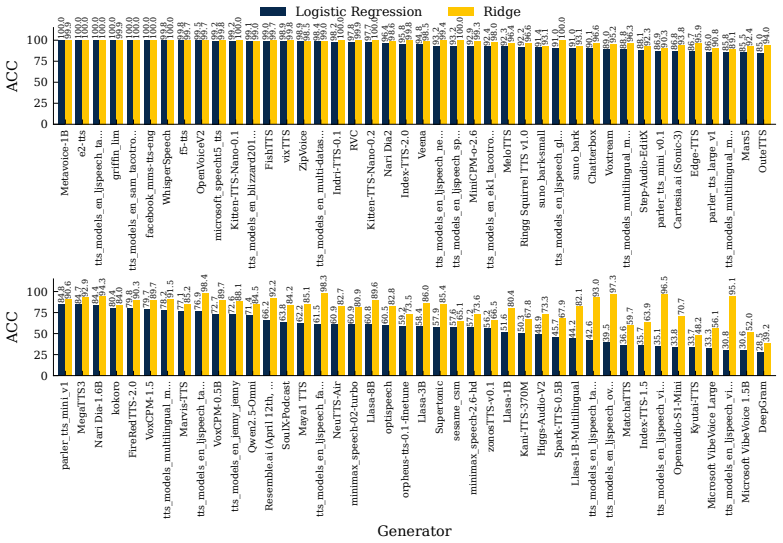
Across three modalities, linear probes trained on frozen self-supervised representations closely approach the performance of bespoke deepfake detectors on standard benchmarks. Generator-level difficulty rankings are partly explained by Frechet geometry distances computed in the identical representation space. These observations indicate that the benchmarks are largely solved by general-purpose representations and therefore measure modality understanding more than forensic understanding of fakes.
What carries the argument
Linear probe on frozen general-purpose self-supervised representations, serving as a diagnostic that isolates how much of benchmark performance is already captured without task-specific forensic training.
If this is right
- High scores on existing benchmarks cannot be read as direct evidence of forensic understanding.
- Detector development may be optimizing for signals already present in general representations.
- Benchmark design should incorporate controls that separate general modality features from manipulation-specific cues.
- Generator difficulty can be predicted in advance using geometry in a fixed representation space.
Where Pith is reading between the lines
- The same audit could be run on other detection or classification benchmarks to check whether they also collapse to general representations.
- Future benchmarks might deliberately include examples where general representations fail, forcing models to learn forensic features.
- Deployment settings where distribution shift is large may still require forensic-specific training even if benchmarks appear solved.
Load-bearing premise
That a linear probe matching bespoke detector performance on the benchmark means the benchmark is testing general modality understanding rather than forensic understanding.
What would settle it
A bespoke detector that substantially outperforms the frozen linear probe on the benchmark while also showing markedly better generalization to real-world unseen deepfakes would falsify the audit conclusion.
Figures
read the original abstract
As deepfake generators approach perceptual indistinguishability, reliable detection becomes critical. Yet, detectors that score well on benchmarks routinely fail in the wild. A concerning feedback loop has emerged: benchmarks drive increasingly complex, engineered detectors, yet if those benchmarks do not reflect real-world deepfakes, this complexity may be solving the wrong problem entirely. This raises a prior question: what are these benchmarks actually measuring? We conduct an audit of video, image, and audio deepfake benchmarks using a deliberately simple diagnostic. If a linear probe on frozen, general-purpose self-supervised representations can approximate the performance of a bespoke detector, the benchmark is largely rewarding general modality understanding rather than forensic understanding. This has two implications: the benchmark may not reflect realistic threat models, and it raises the question of whether the bespoke detectors the probe approaches are truly learning forensic understanding. We observe, across three modalities, linear probes on general-purpose self-supervised representations closely approach the performance of bespoke detectors. We further show that generator-level difficulty is partly explained by Frechet geometry in the same representation space. Together, these results support a benchmark-audit view of deepfake detection: before high scores are read as evidence of forensic understanding, it is worth asking how much of the benchmark is already solved by general-purpose representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper audits deepfake benchmarks across video, image, and audio modalities using a diagnostic based on linear probes trained on frozen general-purpose self-supervised representations. It claims that if such probes closely approach the performance of bespoke detectors, the benchmarks largely reward general modality understanding rather than forensic understanding. The authors report that this holds in their experiments and that generator-level difficulty is partly explained by Fréchet geometry in the same representation spaces.
Significance. If the central diagnostic and its interpretation hold after clarification, the work supplies a lightweight, reproducible method for auditing whether deepfake benchmarks align with intended forensic goals. It could shift how benchmark results are interpreted and encourage more realistic threat models. The reliance on public SSL models and the geometric analysis of difficulty are concrete strengths that make the approach falsifiable and extensible.
major comments (2)
- [Abstract] Abstract (diagnostic premise): The claim that linear-probe success means the benchmark is 'largely rewarding general modality understanding rather than forensic understanding' requires evidence that forensic cues (blending boundaries, spectral artifacts, etc.) are not linearly separable in the SSL embedding space. If they are linearly accessible, the probe is still performing forensic detection and the closeness to bespoke detectors only shows that those detectors also use linearly accessible signals. This assumption is load-bearing for the audit's central conclusion.
- [Results] Results and methods description: The statement that probes 'closely approach' bespoke performance is central to the claim, yet the provided text gives no quantitative metrics, statistical tests, confidence intervals, or controls for confounds (e.g., dataset overlap, probe regularization). Without these, it is impossible to verify whether the observed closeness supports the diagnostic or could be explained by other factors.
minor comments (1)
- [Results] The Fréchet-geometry analysis is presented as downstream support, but the manuscript should clarify how the geometry is computed (e.g., which layers, covariance estimation) and whether it is independent of the linear-probe results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our audit of deepfake benchmarks. The comments help clarify the scope of our diagnostic and the need for stronger quantitative support. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (diagnostic premise): The claim that linear-probe success means the benchmark is 'largely rewarding general modality understanding rather than forensic understanding' requires evidence that forensic cues (blending boundaries, spectral artifacts, etc.) are not linearly separable in the SSL embedding space. If they are linearly accessible, the probe is still performing forensic detection and the closeness to bespoke detectors only shows that those detectors also use linearly accessible signals. This assumption is load-bearing for the audit's central conclusion.
Authors: We agree this distinction is important and that the original abstract wording risks overstating the separation between 'general' and 'forensic' signals. Our intended claim is narrower: because the SSL representations were trained without any forensic supervision, their ability to linearly approximate bespoke detector performance indicates that the benchmark does not require learning representations specialized for the detection task. This still supports questioning whether high benchmark scores reflect capabilities that would transfer beyond the distribution captured by general-purpose models. We will revise the abstract and introduction to make this scope explicit and to note that linear separability of forensic cues within SSL space remains an open question not resolved by the current experiments. revision: partial
-
Referee: [Results] Results and methods description: The statement that probes 'closely approach' bespoke performance is central to the claim, yet the provided text gives no quantitative metrics, statistical tests, confidence intervals, or controls for confounds (e.g., dataset overlap, probe regularization). Without these, it is impossible to verify whether the observed closeness supports the diagnostic or could be explained by other factors.
Authors: The full manuscript contains tables with per-modality accuracy/F1 numbers comparing linear probes to published bespoke detectors, but we acknowledge the absence of formal statistical comparisons and confound controls in the version seen by the referee. In revision we will add: (1) bootstrap confidence intervals on all reported metrics, (2) paired statistical tests between probe and detector performance, (3) explicit checks for train/test overlap between the SSL pretraining corpora and the deepfake benchmarks, and (4) ablation results on probe regularization strength and hidden-layer choice. These additions will be placed in a new 'Quantitative validation' subsection. revision: yes
Circularity Check
No significant circularity; derivation relies on external models and detectors
full rationale
The paper conducts an empirical audit by applying linear probes to publicly available frozen self-supervised representations (e.g., standard SSL models) and comparing performance to published bespoke detectors. No equations, fitted parameters, or results reduce by construction to quantities defined or optimized inside the paper. The central diagnostic premise is an interpretive inference from these external comparisons rather than a self-referential definition or self-citation chain. The Frechet geometry observation is likewise computed in the same external representation space without internal fitting that forces the outcome. This is a standard non-circular empirical audit against independent benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A linear probe on frozen general-purpose self-supervised representations is a valid diagnostic for whether a benchmark measures general modality understanding versus forensic understanding.
Reference graph
Works this paper leans on
-
[1]
A superb-style benchmark of self-supervised speech models for audio deepfake detection
Hashim Ali, Nithin Sai Adupa, Surya Subramani, and Hafiz Malik. A superb-style benchmark of self-supervised speech models for audio deepfake detection. InICASSP, 2026
2026
-
[2]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
AI deepfakes blur reality in 2026 US midterm campaigns
Joseph Ax and Helen Coster. AI deepfakes blur reality in 2026 US midterm campaigns. Reuters, March 2026
2026
-
[4]
Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick V on Platen, Yatharth Saraf, Juan Pino, et al. Xls-r: Self-supervised cross-lingual speech representation learning at scale.arXiv preprint arXiv:2111.09296, 2021
-
[5]
Is space-time attention all you need for video understanding? InICML, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InICML, 2021
2021
-
[6]
Deepfake-Eval-2024: A Multi-Modal In-the-Wild Benchmark of Deepfakes Circulated in 2024
Nuria Alina Chandra, Ryan Murtfeldt, Lin Qiu, Arnab Karmakar, Hannah Lee, Emmanuel Tanumihardja, Kevin Farhat, Ben Caffee, Sejin Paik, Changyeon Lee, et al. Deepfake-eval- 2024: A multi-modal in-the-wild benchmark of deepfakes circulated in 2024.arXiv preprint arXiv:2503.02857, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Forgelens: Data-efficient forgery focus for general- izable forgery image detection
Yingjian Chen, Lei Zhang, and Yakun Niu. Forgelens: Data-efficient forgery focus for general- izable forgery image detection. InICCV, 2025
2025
-
[8]
Can we leave deepfake data behind in training deepfake detector? InNeurIPS, 2024
Jikang Cheng, Zhiyuan Yan, Ying Zhang, Yuhao Luo, Zhongyuan Wang, and Chen Li. Can we leave deepfake data behind in training deepfake detector? InNeurIPS, 2024
2024
-
[9]
Xception: Deep learning with depthwise separable convolutions
François Chollet. Xception: Deep learning with depthwise separable convolutions. InCVPR, 2017
2017
-
[10]
Raising the bar of ai-generated image detection with clip
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nießner, and Luisa Verdoliva. Raising the bar of ai-generated image detection with clip. InCVPR, 2024
2024
-
[11]
Forensics adapter: Adapting clip for generalizable face forgery detection
Xinjie Cui, Yuezun Li, Ao Luo, Jiaran Zhou, and Junyu Dong. Forensics adapter: Adapting clip for generalizable face forgery detection. InCVPR, 2025
2025
-
[12]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[13]
X3d: Expanding architectures for efficient video recognition
Christoph Feichtenhofer. X3d: Expanding architectures for efficient video recognition. In CVPR, 2020
2020
-
[14]
On the content bias in fréchet video distance
Songwei Ge, Aniruddha Mahapatra, Gaurav Parmar, Jun-Yan Zhu, and Jia-Bin Huang. On the content bias in fréchet video distance. InCVPR, 2024
2024
-
[15]
A kernel two-sample test.The Journal of Machine Learning Research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.The Journal of Machine Learning Research, 13(1):723–773, 2012
2012
-
[16]
Leveraging real talking faces via self-supervision for robust forgery detection
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic. Leveraging real talking faces via self-supervision for robust forgery detection. InCVPR, 2022
2022
-
[17]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InNeurIPS, 2017
2017
-
[18]
Implicit identity driven deepfake face swapping detection
Baojin Huang, Zhongyuan Wang, Jifan Yang, Jiaxin Ai, Qin Zou, Qian Wang, and Dengpan Ye. Implicit identity driven deepfake face swapping detection. InCVPR, 2023. 10
2023
-
[19]
Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection. InCVPR, 2020
2020
-
[20]
Fr\'echet Audio Distance: A Metric for Evaluating Music Enhancement Algorithms
Kevin Kilgour, Mauricio Zuluaga, Dominik Roblek, and Matthew Sharifi. Fr\’echet audio dis- tance: A metric for evaluating music enhancement algorithms.arXiv preprint arXiv:1812.08466, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[21]
Uni- formerv2: Unlocking the potential of image vits for video understanding
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Limin Wang, and Yu Qiao. Uni- formerv2: Unlocking the potential of image vits for video understanding. InICCV, 2023
2023
-
[22]
Celeb-df: A large-scale challenging dataset for deepfake forensics
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deepfake forensics. InCVPR, 2020
2020
-
[23]
Yuezun Li, Delong Zhu, Xinjie Cui, and Siwei Lyu. Celeb-df++: A large-scale challenging video deepfake benchmark for generalizable forensics.arXiv preprint arXiv:2507.18015, 2025
-
[24]
Your one-stop solution for ai-generated video detection.arXiv preprint arXiv:2601.11035, 2026
Long Ma, Zihao Xue, Yan Wang, Zhiyuan Yan, Jin Xu, Xiaorui Jiang, Haiyang Yu, Yong Liao, and Zhen Bi. Your one-stop solution for ai-generated video detection.arXiv preprint arXiv:2601.11035, 2026
-
[25]
Detecting ai-generated video via frame consistency
Long Ma, Zhiyuan Yan, Qinglang Guo, Yong Liao, Haiyang Yu, and Pengyuan Zhou. Detecting ai-generated video via frame consistency. InICME, 2025
2025
-
[26]
Mlaad: The multi-language audio anti-spoofing dataset
Nicolas M Müller, Piotr Kawa, Wei Herng Choong, Edresson Casanova, Eren Gölge, Thorsten Müller, Piotr Syga, Philip Sperl, and Konstantin Böttinger. Mlaad: The multi-language audio anti-spoofing dataset. InIJCNN, 2024
2024
-
[27]
Andreas Nautsch, Xin Wang, Nicholas Evans, Tomi H Kinnunen, Ville Vestman, Massimiliano Todisco, Héctor Delgado, Md Sahidullah, Junichi Yamagishi, and Kong Aik Lee. Asvspoof 2019: Spoofing countermeasures for the detection of synthesized, converted and replayed speech.IEEE Transactions on Biometrics, Behavior , and Identity Science, 3(2):252–265, 2021
2019
-
[28]
Exploring self-supervised vision trans- formers for deepfake detection: A comparative analysis
Huy H Nguyen, Junichi Yamagishi, and Isao Echizen. Exploring self-supervised vision trans- formers for deepfake detection: A comparative analysis. InIJCB, 2024
2024
-
[29]
Genvidbench: A 6-million benchmark for ai-generated video detection
Zhenliang Ni, Qiangyu Yan, Mouxiao Huang, Tianning Yuan, Yehui Tang, Hailin Hu, Xinghao Chen, and Yunhe Wang. Genvidbench: A 6-million benchmark for ai-generated video detection. InAAAI, 2026
2026
-
[30]
Attorney general jeff jackson warns north carolinians of investment scams on meta platforms
North Carolina Department of Justice. Attorney general jeff jackson warns north carolinians of investment scams on meta platforms. Press Release, April 2026
2026
-
[31]
INVESTOR ALERT: Attorney general james warns new yorkers of investment scams on meta platforms
Office of the New York State Attorney General. INVESTOR ALERT: Attorney general james warns new yorkers of investment scams on meta platforms. Press Release, April 2026
2026
-
[32]
Towards universal fake image detectors that generalize across generative models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards universal fake image detectors that generalize across generative models. InCVPR, 2023
2023
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[34]
Faceforensics++: Learning to detect manipulated facial images
Andreas Rossler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, and Matthias Nießner. Faceforensics++: Learning to detect manipulated facial images. InICCV, 2019
2019
-
[35]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
An information theoretic approach for attention-driven face forgery detection
Ke Sun, Hong Liu, Taiping Yao, Xiaoshuai Sun, Shen Chen, Shouhong Ding, and Rongrong Ji. An information theoretic approach for attention-driven face forgery detection. InECCV, 2022
2022
-
[37]
Synthetic audio forensics evaluation (safe) challenge.arXiv preprint arXiv:2510.03387, 2025
Kirill Trapeznikov, Paul Cummer, Pranay Pherwani, Jai Aslam, Michael S Davinroy, Peter Bautista, Laura Cassani, Matthew Stamm, and Jill Crisman. Synthetic audio forensics evaluation (safe) challenge.arXiv preprint arXiv:2510.03387, 2025. 11
-
[38]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Cnn- generated images are surprisingly easy to spot
Sheng-Yu Wang, Oliver Wang, Richard Zhang, Andrew Owens, and Alexei A Efros. Cnn- generated images are surprisingly easy to spot... for now. InCVPR, 2020
2020
-
[40]
Yunet: A tiny millisecond-level face detector.Machine Intelligence Research, 2023
Wei Wu, Hanyang Peng, and Shiqi Yu. Yunet: A tiny millisecond-level face detector.Machine Intelligence Research, 2023
2023
-
[41]
Orthogonal Subspace Decomposition for Generalizable AI-Generated Image Detection
Zhiyuan Yan, Jiangming Wang, Zhendong Wang, Peng Jin, Ke-Yue Zhang, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Effort: Efficient orthogonal modeling for generalizable ai-generated image detection.arXiv preprint arXiv:2411.15633, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Ucf: Uncovering common features for generalizable deepfake detection
Zhiyuan Yan, Yong Zhang, Yanbo Fan, and Baoyuan Wu. Ucf: Uncovering common features for generalizable deepfake detection. InICCV, 2023
2023
-
[43]
Deepfakebench: A comprehensive benchmark of deepfake detection.arXiv preprint arXiv:2307.01426, 2023
Zhiyuan Yan, Yong Zhang, Xinhang Yuan, Siwei Lyu, and Baoyuan Wu. Deepfakebench: A comprehensive benchmark of deepfake detection.arXiv preprint arXiv:2307.01426, 2023
-
[44]
Deepfake detection that generalizes across benchmarks
Andrii Yermakov, Jan Cech, Jiri Matas, and Mario Fritz. Deepfake detection that generalizes across benchmarks. InWACV, 2026
2026
-
[45]
Bank of italy warns over deepfake video scams using governor panetta
Valentina Za. Bank of italy warns over deepfake video scams using governor panetta. Reuters, February 2026
2026
-
[46]
D3: Training-free ai-generated video detection using second-order features
Chende Zheng, Ruiqi Suo, Chenhao Lin, Zhengyu Zhao, Le Yang, Shuai Liu, Minghui Yang, Cong Wang, and Chao Shen. D3: Training-free ai-generated video detection using second-order features. InICCV, 2025
2025
-
[47]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024. 12 A Appendix Open-Sora Pyramid-Flow SEINE IPOC SVD LTX Cogvideox1.5 VideoCrafter RepVideo EasyAnimate HunyuanVideo AccVideo Opensora caus...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.