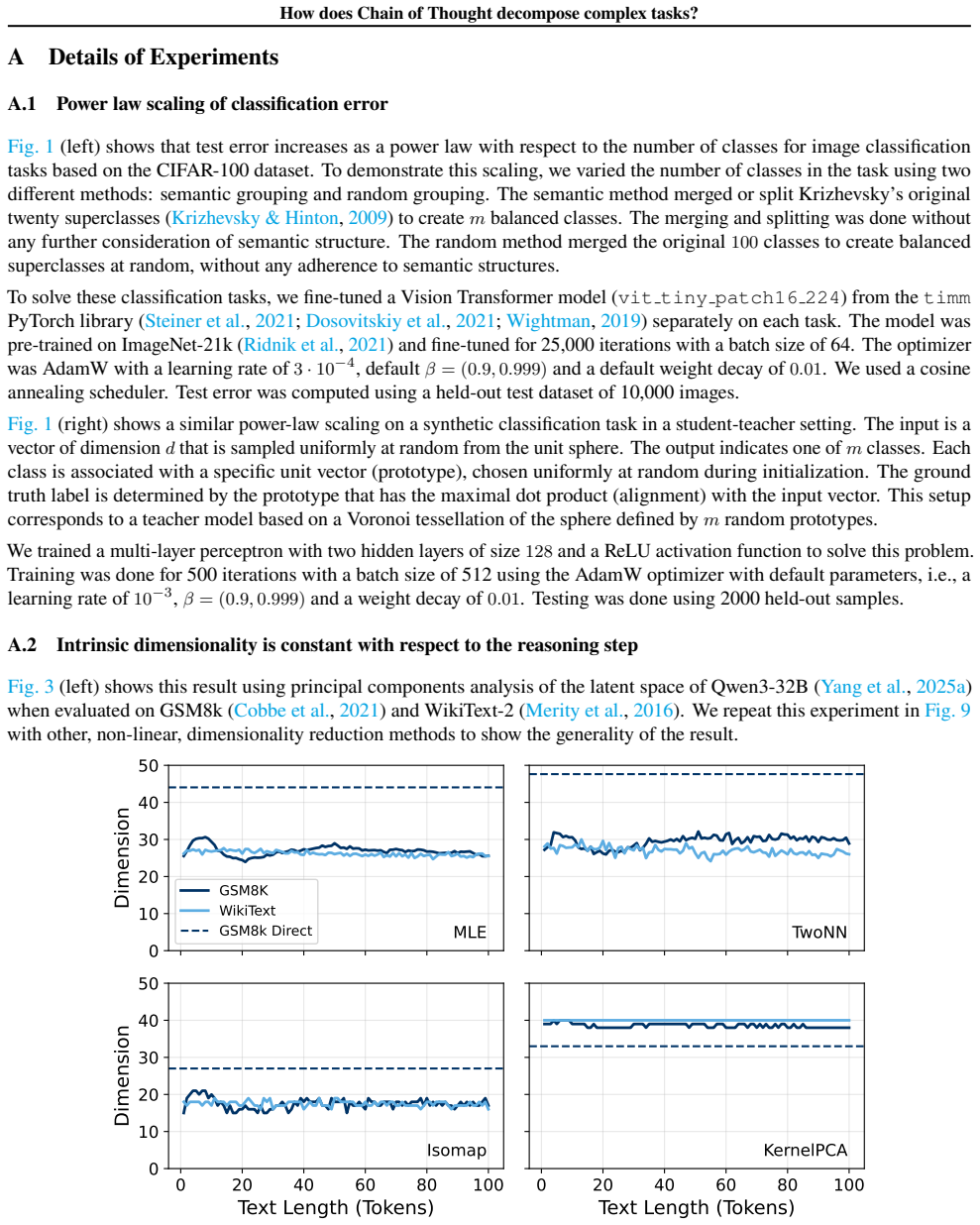
How does Chain of Thought decompose complex tasks?
Pith reviewed 2026-05-22 10:12 UTC · model grok-4.3
The pith
Decomposing complex tasks into trees of smaller classifications with fixed degree reduces LLM prediction error to a minimum at optimal depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
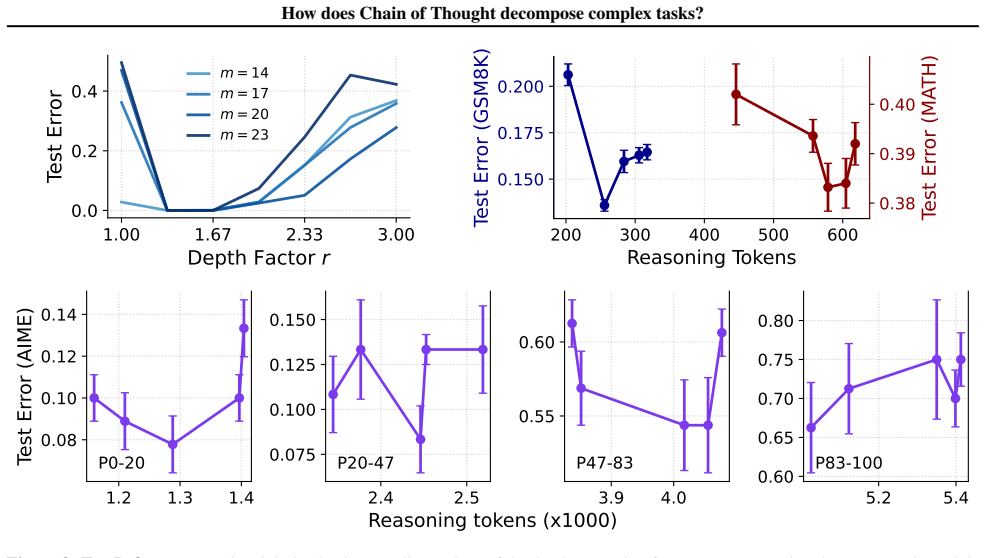
The classification error of a large language model scales as a power law in the number of classes. Consequently, any task can be decomposed into a tree of smaller classification subproblems, each with the same fixed number of classes called the degree. This tree models chain-of-thought reasoning. For degrees above a critical threshold, there exists an optimal depth that minimizes the total error, and this minimum cannot be improved by increasing the depth further.
What carries the argument
The power-law scaling of classification error with number of classes, which enables error reduction via tree-structured decomposition with fixed degree.
Load-bearing premise
The classification error scales as a power law in the number of classes.
What would settle it
Measuring the error rate for classifications with varying numbers of classes and finding that it does not follow a power law, or finding that error keeps decreasing with depth without bound.
Figures









read the original abstract
Many language tasks can be modeled as classification problems where a large language model (LLM) is given a prompt and selects one among many possible answers. We show that the classification error in such problems scales as a power law in the number of classes. This has a dramatic consequence: the prediction error can be reduced substantially by splitting the overall task into a sequence of smaller classification problems, each with the same number of classes ("degree"). This tree-structured decomposition models chain-of-thought (CoT). It has been observed that CoT-based predictors perform better when they "think", i.e., when they develop a deeper tree, thus decomposing the problem into a larger number of steps. We identify a critical threshold for the degree, below which thinking is detrimental, and above which there exists an optimal depth that minimizes the error. It is impossible to surpass this minimal error by increasing the depth of thinking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper models language tasks as multi-class classification problems and asserts that the per-step classification error scales as a power law in the number of classes. It represents chain-of-thought as a tree decomposition with fixed branching factor (degree) k and variable depth d, derives a critical threshold on k, and shows that above this threshold an optimal finite depth exists that minimizes total error; the model further implies that this minimum cannot be improved by additional depth.
Significance. If the power-law scaling is valid, the work supplies a clean theoretical account of why and when chain-of-thought improves performance and identifies an interior optimum for thinking depth. The tree-structured error analysis is a useful formalization that could guide future empirical studies of decomposition strategies.
major comments (3)
- [§3] The power-law form for single-step error E(k) is introduced as the central modeling assumption and is used both to demonstrate error reduction from decomposition and to locate the optimal depth; however, the manuscript provides neither a derivation from the LLM's token-level probabilities nor empirical measurements across varying class cardinalities. This assumption is load-bearing for the claims of a critical threshold and an unsurpassable minimum error.
- [§4.2] §4.2, the derivation of total error as a function of depth d and the subsequent proof that error cannot decrease beyond the optimum both rely on the strict power-law dependence; if the true scaling is sub-power-law, saturating, or task-dependent, neither the existence of an interior minimum nor the impossibility of further improvement follows. A brief sensitivity analysis or alternative functional forms should be included.
- [§4.3] The critical threshold on degree k and the optimal depth d* are obtained analytically from the power-law model; because the same functional form is used to establish both the benefit of decomposition and the location of the minimum, the argument risks circularity unless the scaling law is independently justified or validated.
minor comments (2)
- [Figure 1] Figure 1 caption should explicitly state whether the plotted error curves are purely theoretical or include any empirical LLM evaluations.
- [§2] The notation for total error (perhaps denoted E_total(d,k)) and the precise definition of 'degree' should be introduced with a small concrete example in the model section to improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments correctly identify the power-law scaling as the central modeling assumption. We respond point-by-point below, clarifying its status as an input assumption rather than a derived result, adding a sensitivity analysis, and removing any appearance of circularity. We have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§3] The power-law form for single-step error E(k) is introduced as the central modeling assumption and is used both to demonstrate error reduction from decomposition and to locate the optimal depth; however, the manuscript provides neither a derivation from the LLM's token-level probabilities nor empirical measurements across varying class cardinalities. This assumption is load-bearing for the claims of a critical threshold and an unsurpassable minimum error.
Authors: We agree that the power-law E(k) ∝ k^α is a modeling assumption rather than a derivation from token-level probabilities. The manuscript motivates the form by reference to known scaling phenomena in classification error versus class cardinality, but does not derive it from a specific LLM output distribution; such a derivation would require additional assumptions about the model's generative process that lie outside the paper's theoretical scope. We have expanded §3 to state this explicitly and to cite related empirical scaling laws from the literature. A full empirical sweep across class cardinalities is valuable future work but would expand the manuscript beyond its current theoretical focus; we have added a brief discussion of possible experimental tests in the conclusion. revision: partial
-
Referee: [§4.2] §4.2, the derivation of total error as a function of depth d and the subsequent proof that error cannot decrease beyond the optimum both rely on the strict power-law dependence; if the true scaling is sub-power-law, saturating, or task-dependent, neither the existence of an interior minimum nor the impossibility of further improvement follows. A brief sensitivity analysis or alternative functional forms should be included.
Authors: We accept this point. The revised manuscript now includes a new sensitivity subsection in §4.2 that examines three alternative forms: logarithmic scaling, linear scaling, and power-law with varying exponents. We show analytically that an interior optimum for depth d* exists whenever the per-step error grows super-linearly with k (including the original power-law regime), while saturating or sub-linear forms yield a minimum at infinite depth. The revised text states the precise conditions under which the critical threshold and finite optimum hold, thereby clarifying the scope of the claims. revision: yes
-
Referee: [§4.3] The critical threshold on degree k and the optimal depth d* are obtained analytically from the power-law model; because the same functional form is used to establish both the benefit of decomposition and the location of the minimum, the argument risks circularity unless the scaling law is independently justified or validated.
Authors: We disagree that the argument is circular. The power-law scaling is introduced as an exogenous assumption about single-step classification error; the subsequent derivations of the critical k threshold and the optimal finite depth are logical consequences of that assumption applied to the tree decomposition. This structure is intentional: it isolates the implications of power-law error growth for hierarchical reasoning. To remove any ambiguity we have rewritten the opening of §4.3 to emphasize that the scaling law is an input hypothesis and have added a short paragraph discussing independent empirical routes to validation (e.g., controlled synthetic classification experiments). revision: partial
Circularity Check
No significant circularity; power-law scaling serves as independent modeling assumption.
full rationale
The paper states it shows that classification error scales as a power law in the number of classes and then derives consequences for CoT tree decomposition, including a critical degree threshold and an optimal finite depth that minimizes total error. The claim that this minimum cannot be surpassed by further depth increases follows mathematically from minimizing the composite error function E(d, k) under the stated scaling. No quoted step reduces the optimal-depth result or the 'impossible to surpass' statement to a fitted parameter, a self-citation, or a redefinition of the power-law input itself. The scaling is presented as a shown result whose derivation (if present in the full text) is separate from the subsequent minimization; the central claims are therefore consequences rather than tautological restatements of the inputs. This is the normal case of a modeling paper whose conclusions depend on an explicit assumption without self-referential collapse.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Classification error scales as a power law in the number of classes
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that the classification error in such problems scales as a power law in the number of classes... optimal degree m∗=e^{d/2}... It is impossible to surpass this minimal error by increasing the depth of thinking.
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the error is minimized when each sub-problem has a certain optimal degree m∗=e^{d/2}... thinking reduces the error up to a certain depth.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ISSN 1095-9203. doi: 10.1126/science.abq1158. Li, Z., Zhong, J., et al. Compressing chain-of-thought in llms via step entropy.arXiv preprint arXiv:2508.03346, 2025b. Lightman, H., Kosaraju, V., et al. Let’s verify step by step. arXiv preprint arXiv:2305.20050, 2023. Liu, A., Feng, B., et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 20...
-
[2]
Pointer Sentinel Mixture Models
ISBN 978-0-521-64298-9. Merity, S., Xiong, C., Bradbury, J., and Socher, R. Pointer sentinel mixture models.CoRR, abs/1609.07843, 2016. Muennighoff, N., Yang, Z., et al. s1: Simple test-time scaling.arXiv preprint arXiv:2501.19393, 2025. OpenAI. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2024. Park, S., Zhang, Y., Yu, S. X., Beery, S., and Hu...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.7551/mitpress/11474.001.0001 2016
-
[3]
doi: 10.5281/zenodo.4414861. Woodworth, R. S. and Sells, S. B. An atmosphere effect in formal syllogistic reasoning.Journal of Experimental Psy- chology, 18(4):451–460, 1935. ISSN 0022-1015(Print). doi: 10.1037/h0060520. Wu, Y., Wang, Y., et al. When more is less: Under- standing chain-of-thought length in llms.arXiv preprint arXiv:2502.07266, 2025. Xie, ...
-
[4]
You are a helpful assistant. Solve the math problem. Show your work. Only show important steps. Prepend #### to your final answer
-
[5]
You are a helpful assistant. Solve the math problem. Show your work step by step. Prepend #### to your final answer
-
[6]
You are a helpful assistant. Solve the math problem. Show your work step by step. Check each step to make sure it is correct. Prepend #### to your final answer
-
[7]
You are a helpful assistant. Solve the math problem. Show your work step by step. Explain each step. Explicitly check each step to make sure it is correct. Prepend #### to your final answer
-
[8]
You are a helpful assistant. Solve the math problem. Show your work step by step. Explain each step. Explicitly check each step to make sure it is correct. Then, check each step again to make sure it is correct. Prepend #### to your final answer. Each instruction in this list builds on the previous one. The first level encouraged the model to skip steps i...
-
[9]
How many clips did Natalia sell altogether in April and May? \n Natalia sold 48/2=24 clips in May
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? \n Natalia sold 48/2=24 clips in May. She sold 72 clips altogether in April and May. #### 72 \n Weng earns $12 an hour for babysitting. Yesterday, she just did 50 minutes of babysitting. How much did s...
-
[10]
How many clips did Natalia sell altogether in April and May? \n Natalia sold 48/2=24 clips in May
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? \n Natalia sold 48/2=24 clips in May. She sold 48 clips in April. She sold 48+24 = 72 clips altogether in April and May. #### 72 \n Weng earns $12 an hour for babysitting. Yesterday, she just did 50 mi...
-
[11]
How many clips did Natalia sell altogether in April and May? \n Natalia sold 48/2=24 clips in May
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? \n Natalia sold 48/2=24 clips in May. Checking, half of 48 is 24. She sold 48 clips in April. She sold 48+24 = 72 clips altogether in April and May. Checking, 48+24=72 is correct. #### 72 \n Weng earns...
-
[12]
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? \n I should calculate how many clips Natalia sold in May. Natalia sold 48/2=24 clips in May. Checking, half of 48 is 24. She sold 48 clips in April. The total will be the sum of the clips sold in April...
-
[13]
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May? \n I should calculate how many clips Natalia sold in May. Natalia sold 48/2=24 clips in May. Checking, half of 48 is 24. Checking again, 48 divided by 2 is 24. She sold 48 clips in April. The total wil...
-
[14]
You are a helpful assistant. Solve the math problem. Show your work. Only show important steps. Output the final answer in a box
-
[15]
You are a helpful assistant. Solve the math problem. Show your work step by step. Output the final answer in a box
-
[16]
You are a helpful assistant. Solve the math problem. Show your work step by step. Check each step to make sure it is correct. Output the final answer in a box
-
[17]
You are a helpful assistant. Solve the math problem. Show your work step by step. Explain each step. Explicitly check each step to make sure it is correct. Output the final answer in a box
-
[18]
You are a helpful assistant. Solve the math problem. Show your work step by step. Explain each step. Explicitly double-check each step to make sure it is correct. Output the final answer in a box. And the few shot examples for these two datasets are listed below in the same order
-
[19]
Let \[f(x) = \left\{ \begin{array}{cl} ax+3, &\text{ if }x>2, \\ x-5 &\text{ if } -2 \le x \le 2, \\ 2x-b &\text{ if } x <-2. \end{array} \right.\]Find $a+b$ if the piecewise function is continuous (which means that its graph can be drawn without lifting your pencil from the paper). \n For the piecewise function to be continuous, the cases must meet at $2...
-
[20]
Let \[f(x) = \left\{ \begin{array}{cl} ax+3, &\text{ if }x>2, \\ x-5 &\text{ if } -2 \le x \le 2, \\ 2x-b &\text{ if } x <-2. \end{array} \right.\]Find $a+b$ if the piecewise function is continuous (which means that its graph can be drawn without lifting your pencil from the paper). \n For the piecewise function to be continuous, the cases must meet at $2...
-
[21]
Let \[f(x) = \left\{ \ begin{array}{cl} ax+3, & \text{ if }x>2, \\ x-5 &\text{ if } -2 \le x \le 2, \\ 2x-b &\text{ if } x <-2. \end{array} \ right.\]Find $a+b$ if the piecewise function is continuous (which means that its graph can be drawn without lifting your pencil from the paper). \n For the piecewise function to be continuous, the cases must meet at...
-
[22]
Let \[f(x) = \left\{ \begin{array}{cl} ax+3, &\text{ if }x>2, \\ x-5 &\text{ if } -2 \le x \le 2, \\ 2x-b &\text{ if } x <-2. \end{array} \right.\]Find $a+b$ if the piecewise function is continuous (which means that its graph can be drawn without lifting your pencil from the paper). \n For the piecewise function to be continuous, the cases must meet at $2...
-
[23]
Let \[f(x) = \left\{ \begin{array}{cl} ax+3, &\text{ if }x>2, \\ x-5 &\text{ if } -2 \le x \le 2, \\ 2x-b &\text{ if } x <-2. \end{array} \right.\]Find $a+b$ if the piecewise function is continuous (which means that its graph can be drawn without lifting your pencil from the paper). \n For the piecewise function to be continuous, the cases must meet at $2...
work page 2024
-
[24]
“This is not chain-of-thought”, “This is not how reasoning works”, “This is not how thinking is implemented in an LLM” In our theory, CoT-based reasoning is characterized by a sequence of predictions made by a model on intermediate classification sub-tasks. The set of all possible sequences of predictions (chains of thought) can be organized into a tree w...
-
[25]
What is the optimal degree and depth in real problems? How can you check the degree m of a given task?Our scaling law in Eq. (4) as well as prior empirical and theoretical results (Bahri et al., 2024; Kaplan et al., 2020) indicate that error should scale as roughly D−1/d. By evaluating the test error of a model while varying the size of the dataset D, one...
work page 2024
-
[26]
How would this analysis change if the LLM were to use tree-of-thought, graph-of-thoughts, self-consistency etc.? We have assumed each reasoning step is sampled from the predicted probability distribution over the next token. However, it is common to use more sophisticated methods to improve the effectiveness of CoT-based reasoning (Yao et al., 2023; Besta...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.