Pareto LoRA: Mitigating Modality Imbalance in Unified Multimodal Models via Pareto-Optimal Gradient Integration
Pith reviewed 2026-06-27 03:27 UTC · model grok-4.3
The pith
Pareto LoRA balances text and image gradients via Pareto-optimal integration to fix modality imbalance during LoRA fine-tuning of unified multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
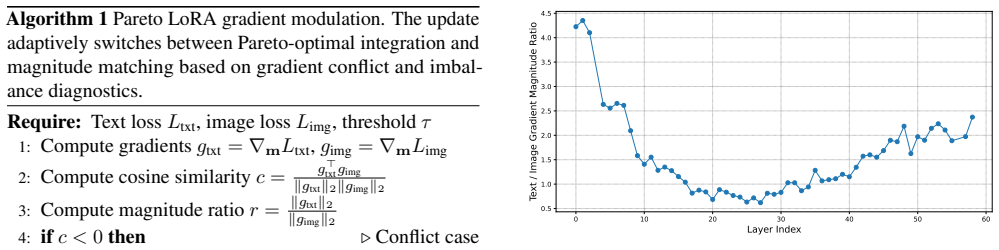
The authors claim that modality imbalance stems from large differences in gradient magnitude and direction across text and image objectives, and that reformulating instruction tuning as a bi-objective problem permits a Pareto-optimal integration strategy to modulate those gradients and restore balanced optimization in LoRA-adapted unified multimodal models.
What carries the argument
Pareto-optimal gradient integration strategy that modulates the combined direction and strength of text and image gradients to reach a balanced trade-off point during LoRA updates.
If this is right
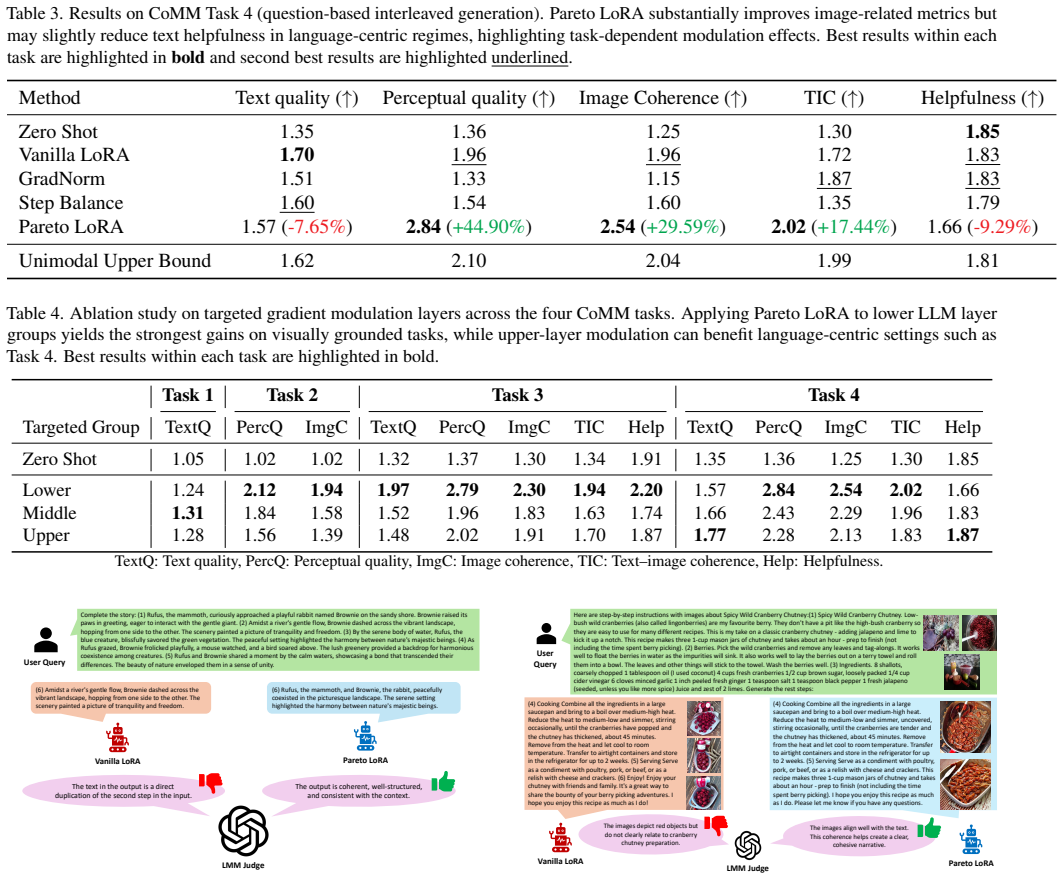
- Image perceptual quality on CoMM rises by as much as 44.9 percent compared with vanilla LoRA.
- Text generation performance stays at the level achieved by standard LoRA.
- The same gradient-magnitude gap appears across tasks and layers, so the balancing step applies broadly.
- The method keeps the model inside the original LoRA parameter budget.
Where Pith is reading between the lines
- The same balancing logic could be tested on other parameter-efficient adapters that also suffer objective conflicts.
- Extending the bi-objective framing to three or more modalities would require only a change in the Pareto front computation.
- Running the method on base models besides Emu2 would test whether the observed gradient disparity is architecture-specific.
- If the gradient disparity persists after full fine-tuning rather than only in LoRA, the approach might also apply outside the parameter-efficient regime.
Load-bearing premise
The assumption that modality imbalance is caused mainly by differing gradient magnitudes and directions and that a Pareto-optimal blend can correct it without creating new instabilities.
What would settle it
A controlled run on Emu2 with CoMM data in which random or magnitude-matched gradient scaling is substituted for the Pareto selection step and image quality fails to improve or text performance drops.
Figures



read the original abstract
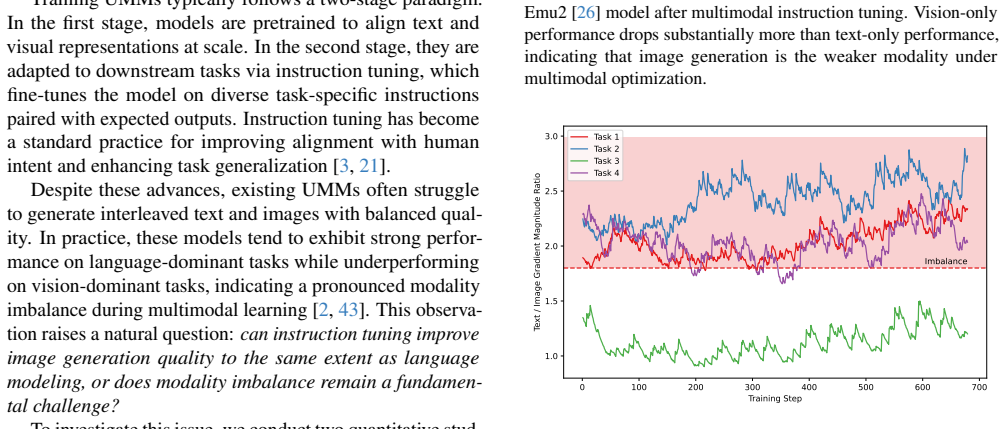
Unified multimodal models (UMMs) have recently emerged as a promising paradigm for integrating multimodal understanding and generation within a single autoregressive transformer. However, during multimodal instruction tuning, these models often exhibit pronounced modality imbalance: language gradients dominate optimization, thus leading to lower image generation quality, especially under parameter-efficient fine-tuning such as LoRA. In this work, we systematically analyze modality imbalance in LoRA-based fine-tuning of UMMs for interleaved text-image generation. We show that vision modality performance degrades substantially more than text modality performance when compared to unimodal counterparts, and that modality-specific gradients can differ by orders of magnitude across various tasks and layers. Motivated by this observation, we reformulate the multimodal instruction tuning as a bi-objective optimization problem and propose Pareto LoRA, a Pareto-optimal gradient integration strategy that balances the text and image objectives by modulating the gradient direction and strength. Experiments on the CoMM benchmark with Emu2 demonstrate that Pareto LoRA consistently improves multimodal generation balance, achieving up to 44.9% gains in perceptual image quality over vanilla LoRA while maintaining comparable text performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes modality imbalance during LoRA fine-tuning of unified multimodal models, where language gradients dominate and degrade image generation quality relative to unimodal baselines. It observes that modality-specific gradients differ by orders of magnitude across tasks and layers, reformulates instruction tuning as a bi-objective optimization problem, and proposes Pareto LoRA, which applies a Pareto-optimal gradient integration strategy to modulate direction and strength for balancing text and image objectives. Experiments on the CoMM benchmark with Emu2 report up to 44.9% gains in perceptual image quality over vanilla LoRA while maintaining comparable text performance.
Significance. If the central experimental claims hold under rigorous validation, the work could offer a practical gradient-modulation technique for improving balance in parameter-efficient multimodal fine-tuning, addressing a recurring optimization challenge in unified autoregressive models. The gradient-magnitude analysis provides a concrete diagnostic for modality imbalance that may inform future method design.
major comments (2)
- [Experiments on the CoMM benchmark with Emu2] Experiments on the CoMM benchmark with Emu2: the reported 44.9% perceptual image quality gain is stated without accompanying details on baselines (beyond vanilla LoRA), number of runs, variance, statistical tests, or ablation studies isolating the Pareto integration component from incidental effects such as altered effective step sizes. This information is load-bearing for attributing the improvement to the proposed strategy.
- [reformulate the multimodal instruction tuning as a bi-objective optimization problem] reformulate the multimodal instruction tuning as a bi-objective optimization problem and propose Pareto LoRA: the premise that the gradient modulation balances modalities without introducing new optimization instabilities or hidden trade-offs is invoked but not directly tested via convergence behavior, gradient-norm trajectories, or layer-wise trade-off analysis. This leaves the central claim that the method reliably avoids instabilities unanchored.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify areas where additional experimental details and analyses would strengthen the manuscript. We address each point below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Experiments on the CoMM benchmark with Emu2] Experiments on the CoMM benchmark with Emu2: the reported 44.9% perceptual image quality gain is stated without accompanying details on baselines (beyond vanilla LoRA), number of runs, variance, statistical tests, or ablation studies isolating the Pareto integration component from incidental effects such as altered effective step sizes. This information is load-bearing for attributing the improvement to the proposed strategy.
Authors: We agree that the manuscript would benefit from expanded experimental reporting to support attribution of the gains. In the revised version, we will add: results from multiple independent runs with means and standard deviations, statistical significance tests, comparisons against additional baselines, and ablations that control for effective step size to isolate the Pareto integration component. These changes will directly address the concern. revision: yes
-
Referee: [reformulate the multimodal instruction tuning as a bi-objective optimization problem] reformulate the multimodal instruction tuning as a bi-objective optimization problem and propose Pareto LoRA: the premise that the gradient modulation balances modalities without introducing new optimization instabilities or hidden trade-offs is invoked but not directly tested via convergence behavior, gradient-norm trajectories, or layer-wise trade-off analysis. This leaves the central claim that the method reliably avoids instabilities unanchored.
Authors: We acknowledge that direct empirical validation of optimization dynamics would better anchor the claims. The revised manuscript will include convergence curves, gradient-norm trajectories over training steps, and layer-wise trade-off analyses to demonstrate that the method balances modalities without introducing instabilities. This will provide the requested evidence. revision: yes
Circularity Check
No significant circularity detected; derivation is self-contained
full rationale
The paper motivates its approach from direct empirical observations of gradient magnitude and direction differences across text and image modalities during LoRA fine-tuning, which are measured and reported independently. It then reformulates the tuning process as a bi-objective optimization problem and introduces Pareto LoRA as an explicit new gradient modulation strategy. Performance improvements are demonstrated via external benchmark experiments on CoMM with Emu2 rather than by construction from fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the provided derivation chain. The central claims rest on observable inputs and external validation, satisfying the criteria for a non-circular result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jie An, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Lijuan Wang, and Jiebo Luo. Openleaf: Open-domain interleaved image-text generation and evalua- tion.arXiv preprint arXiv:2310.07749, 2023. 2
-
[2]
Dongping Chen, Ruoxi Chen, Shu Pu, Zhaoyi Liu, Yanru Wu, Caixi Chen, Benlin Liu, Yue Huang, Yao Wan, Pan Zhou, et al. Interleaved scene graphs for interleaved text-and-image generation assessment.arXiv preprint arXiv:2411.17188,
-
[3]
Visual instruction tuning with polite flamingo
Delong Chen, Jianfeng Liu, Wenliang Dai, and Baoyuan Wang. Visual instruction tuning with polite flamingo. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 17745–17753, 2024. 2
2024
-
[4]
Comm: A coherent interleaved image-text dataset for multimodal understanding and gener- ation
Wei Chen, Lin Li, Yongqi Yang, Bin Wen, Fan Yang, Tingting Gao, Yu Wu, and Long Chen. Comm: A coherent interleaved image-text dataset for multimodal understanding and gener- ation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8073–8082, 2025. 5
2025
-
[5]
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and An- drew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. InIn- ternational conference on machine learning, pages 794–803. PMLR, 2018. 6
2018
-
[6]
Multiple-gradient descent algorithm (mgda) for multiobjective optimization.Comptes Rendus Mathematique, 350(5-6):313–318, 2012
Jean-Antoine D´esid´eri. Multiple-gradient descent algorithm (mgda) for multiobjective optimization.Comptes Rendus Mathematique, 350(5-6):313–318, 2012. 4
2012
-
[7]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021. 3
2021
-
[8]
Guiding instruction-based image editing via multimodal large language models
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guiding instruction-based image editing via multimodal large language models. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[9]
Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning
Chendi Ge, Xin Wang, Zeyang Zhang, Hong Chen, Jiapei Fan, Longtao Huang, Hui Xue, and Wenwu Zhu. Dynamic mixture of curriculum lora experts for continual multimodal instruction tuning. InForty-second International Conference on Machine Learning, 2025. 3
2025
-
[10]
Geneval: An object-focused framework for evaluating text-to- image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to- image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023. 3
2023
-
[11]
Qingpei Guo, Kaiyou Song, Zipeng Feng, Ziping Ma, Qing- long Zhang, Sirui Gao, Xuzheng Yu, Yunxiao Sun, Tai-Wei Chang, Jingdong Chen, et al. M2-omni: Advancing omni- mllm for comprehensive modality support with competitive performance.arXiv preprint arXiv:2502.18778, 2025. 6
-
[12]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3,
-
[13]
Instruct-imagen: Image gen- eration with multi-modal instruction
Hexiang Hu, Kelvin CK Chan, Yu-Chuan Su, Wenhu Chen, Yandong Li, Kihyuk Sohn, Yang Zhao, Xue Ben, Boqing Gong, William Cohen, et al. Instruct-imagen: Image gen- eration with multi-modal instruction. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 4754–4763, 2024. 3
2024
-
[14]
arXiv preprint arXiv:2504.01934 (2025) 10
Runhui Huang, Chunwei Wang, Junwei Yang, Guansong Lu, Yunlong Yuan, Jianhua Han, Lu Hou, Wei Zhang, Lanqing Hong, Hengshuang Zhao, et al. Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement. arXiv preprint arXiv:2504.01934, 2025. 3
-
[15]
Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction-based image editing with multimodal large lan- guage models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8362– 8371, 2024. 3
2024
-
[16]
Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024
Dongfu Jiang, Xuan He, Huaye Zeng, Cong Wei, Max Ku, Qian Liu, and Wenhu Chen. Mantis: Interleaved multi-image instruction tuning.arXiv preprint arXiv:2405.01483, 2024. 3
-
[17]
Unified language-vision pretraining in LLM with dynamic discrete visual tokenization
Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Chao Liao, Jian- chao Tan, Quzhe Huang, Bin Chen, Chengru Song, dai meng, Di Zhang, Wenwu Ou, Kun Gai, and Yadong Mu. Unified language-vision pretraining in LLM with dynamic discrete visual tokenization. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[18]
Orthus: Au- toregressive interleaved image-text generation with modality- specific heads
Siqi Kou, Jiachun Jin, Zhihong Liu, Chang Liu, Ye Ma, Jian Jia, Quan Chen, Peng Jiang, and Zhijie Deng. Orthus: Au- toregressive interleaved image-text generation with modality- specific heads. InForty-second International Conference on Machine Learning, 2025. 2
2025
-
[19]
Boosting multi-modal model performance with adap- tive gradient modulation
Hong Li, Xingyu Li, Pengbo Hu, Yinuo Lei, Chunxiao Li, and Yi Zhou. Boosting multi-modal model performance with adap- tive gradient modulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22214– 22224, 2023. 3
2023
-
[20]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 2, 3
2023
-
[21]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023. 2
2023
-
[22]
World model on million-length video and language with blockwise ringattention
Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with blockwise ringattention. InThe Thirteenth International Con- ference on Learning Representations, 2025. 3
2025
-
[23]
Holistic evaluation for interleaved text-and-image generation.arXiv preprint arXiv:2406.14643, 2024
Minqian Liu, Zhiyang Xu, Zihao Lin, Trevor Ashby, Joy Rimchala, Jiaxin Zhang, and Lifu Huang. Holistic evaluation for interleaved text-and-image generation.arXiv preprint arXiv:2406.14643, 2024. 5
-
[24]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[25]
Multi-task learning as multi- objective optimization.Advances in neural information pro- cessing systems, 31, 2018
Ozan Sener and Vladlen Koltun. Multi-task learning as multi- objective optimization.Advances in neural information pro- cessing systems, 31, 2018. 4 9
2018
-
[26]
Generative multimodal models are in- context learners
Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiying Yu, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal models are in- context learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14398– 14409, 2024. 2, 3, 5
2024
-
[27]
Emu: Generative pretraining in multimodality
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Emu: Generative pretraining in multimodality. InThe Twelfth International Conference on Learning Representations, 2024. 3
2024
-
[28]
Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks
Yi-Lin Sung, Jaemin Cho, and Mohit Bansal. Vl-adapter: Parameter-efficient transfer learning for vision-and-language tasks. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 5227–5237, 2022. 3
2022
-
[29]
Hongxuan Tang, Hao Liu, and Xinyan Xiao. Ugen: Unified autoregressive multimodal model with progressive vocabulary learning.arXiv preprint arXiv:2503.21193, 2025. 3
-
[30]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Mige: Mutually enhanced mul- timodal instruction-based image generation and editing
Xueyun Tian, Wei Li, Bingbing Xu, Yige Yuan, Yuanzhuo Wang, and Huawei Shen. Mige: Mutually enhanced mul- timodal instruction-based image generation and editing. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 10622–10631, 2025. 3
2025
-
[32]
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal under- standing and generation via instruction tuning.arXiv preprint arXiv:2412.14164, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Mar- tinet, Marie-Anne Lachaux, Timoth ´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Neural discrete representation learning.Advances in Neural Information Processing Systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in Neural Information Processing Systems, 30, 2017. 3
2017
-
[35]
Illume: Illuminating your llms to see, draw, and self-enhance.arXiv preprint arXiv:2412.06673, 2024
Chunwei Wang, Guansong Lu, Junwei Yang, Runhui Huang, Jianhua Han, Lu Hou, Wei Zhang, and Hang Xu. Illume: Illuminating your llms to see, draw, and self-enhance.arXiv preprint arXiv:2412.06673, 2024. 3
-
[36]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Miti- gating intra-and inter-modal forgetting in continual learning of unified multimodal models
Xiwen Wei, Mustafa Munir, and Radu Marculescu. Miti- gating intra-and inter-modal forgetting in continual learning of unified multimodal models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. 3
2025
-
[38]
Yake Wei and Di Hu. Mmpareto: Boosting multimodal learning with innocent unimodal assistance.arXiv preprint arXiv:2405.17730, 2024. 3, 4
-
[39]
Janus: Decoupling visual encoding for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encoding for unified multimodal understanding and generation. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 12966–12977, 2025. 2
2025
-
[40]
Junda Wu, Xintong Li, Tong Yu, Yu Wang, Xiang Chen, Jiuxiang Gu, Lina Yao, Jingbo Shang, and Julian McAuley. Commit: Coordinated instruction tuning for multimodal large language models.arXiv preprint arXiv:2407.20454, 2024. 3
-
[41]
VILA-u: a unified founda- tion model integrating visual understanding and generation
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, Song Han, and Yao Lu. VILA-u: a unified founda- tion model integrating visual understanding and generation. InThe Thirteenth International Conference on Learning Rep- resentations, 2025. 3
2025
-
[42]
Show-o: One single transformer to unify multimodal understanding and genera- tion
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and genera- tion. InThe Thirteenth International Conference on Learning Representations, 2025. 2, 3
2025
-
[43]
Modality- specialized synergizers for interleaved vision-language gener- alists
Zhiyang Xu, Minqian Liu, Ying Shen, Joy Rimchala, Jiaxin Zhang, Qifan Wang, Yu Cheng, and Lifu Huang. Modality- specialized synergizers for interleaved vision-language gener- alists. InThe Thirteenth International Conference on Learn- ing Representations, 2025. 2, 3
2025
-
[44]
Learning to rebalance multi-modal optimization by adaptively masking subnetworks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Yang Yang, Hongpeng Pan, Qing-Yuan Jiang, Yi Xu, and Jinhui Tang. Learning to rebalance multi-modal optimization by adaptively masking subnetworks.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 3
2025
-
[45]
Robust multimodal large language models against modal- ity conflict
Zongmeng Zhang, Wengang Zhou, Jie Zhao, and Houqiang Li. Robust multimodal large language models against modal- ity conflict. InForty-second International Conference on Machine Learning, 2025. 3
2025
-
[46]
Mllms are deeply affected by modality bias.arXiv preprint arXiv:2505.18657, 2025
Xu Zheng, Chenfei Liao, Yuqian Fu, Kaiyu Lei, Yuan- huiyi Lyu, Lutao Jiang, Bin Ren, Jialei Chen, Jiawen Wang, Chengxin Li, et al. Mllms are deeply affected by modality bias.arXiv preprint arXiv:2505.18657, 2025. 3
-
[47]
Transfusion: Pre- dict the next token and diffuse images with one multi-modal model
Chunting Zhou, LILI YU, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Pre- dict the next token and diffuse images with one multi-modal model. InThe Thirteenth International Conference on Learn- ing Representations, 2025. 2, 3 10
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.