SPARK: Low Latency Single-Camera 3D Pose Estimation for Autonomous Racing using Keypoints
Pith reviewed 2026-06-27 00:51 UTC · model grok-4.3
The pith
SPARK detects 3D poses of racing opponents from one camera using keypoints to achieve higher accuracy and lower latency than prior monocular methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPARK achieves long-range detection with high accuracy, exceeding the performance of state-of-the-art monocular camera detection algorithms while maintaining lower latency, by employing well-optimized YOLO models and leveraging the fixed geometry in the autonomous racing domain.
What carries the argument
Keypoint detection with well-optimized YOLO models that exploits fixed racetrack geometry to convert 2D image detections into 3D poses.
If this is right
- Detection latency drops enough to improve object tracking during high-dynamic racing maneuvers.
- Monocular systems can replace or supplement slower LiDAR for opponent pose estimation on edge hardware.
- Lower resource usage supports deployment on resource-constrained autonomous race vehicles.
- Long-range accuracy enables earlier planning of collision-free trajectories against non-cooperative opponents.
Where Pith is reading between the lines
- The method may extend to other structured environments where track geometry is known in advance, such as oval tracks or test circuits.
- Because it builds on standard YOLO detectors, retraining on new camera setups could be straightforward without custom hardware.
- Eliminating LiDAR reliance could lower vehicle cost and complexity for teams focused on vision-only autonomy.
Load-bearing premise
The fixed geometry of the autonomous racing domain combined with well-optimized YOLO models will deliver the claimed accuracy and latency gains on real-world data without additional post-processing or domain-specific tuning that affects the central performance claims.
What would settle it
A head-to-head test on the same real-world autonomous racing dataset where SPARK accuracy falls below state-of-the-art monocular methods or its latency exceeds the monocular baselines would falsify the central performance claim.
Figures



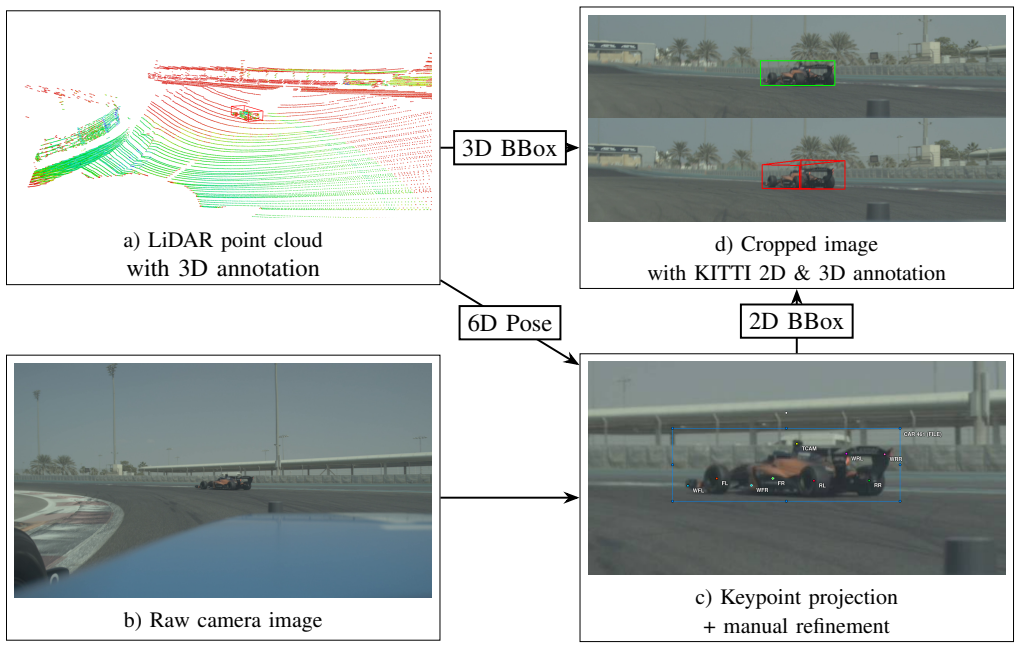


read the original abstract
In autonomous racing, fast detection of other participants' movements is required to plan safe, collision-free trajectories with non-cooperative opponents. LiDAR detection is inherently slower and harder to deploy on edge devices than vision methods, causing delayed detections that limit object tracking performance during high-dynamic maneuvering. Utilizing monocular 3D detection enables an easy-to-deploy, low-latency detection of other participants on the racetrack. We present SPARK, a single-camera pose-estimation algorithm for autonomous racing using keypoint detection. It achieves long-range detection with high accuracy, exceeding the performance of state-of-the-art monocular camera detection algorithms while maintaining lower latency. By employing well-optimized YOLO models and leveraging the fixed geometry in the autonomous racing domain, the algorithm also exhibits low latency and resource usage. We evaluate the performance of our approach on real-world autonomous racing data and compare it to state-of-the-art LiDAR and camera detection algorithms. The source code is available at: https://github.com/TUMFTM/SPARK-camera-det
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPARK, a monocular 3D pose estimation pipeline for autonomous racing that detects keypoints with optimized YOLO models and exploits the fixed track geometry to recover 3D poses. It claims long-range detection with accuracy superior to existing monocular detectors at lower latency than LiDAR, supported by evaluation on real-world racing data and direct comparisons to SOTA baselines; source code is released.
Significance. If the reported accuracy and latency advantages hold under the experimental conditions, the work provides a practical, edge-deployable vision alternative for high-dynamic racing scenarios where LiDAR latency is prohibitive. The public release of source code is a clear strength that supports reproducibility and community validation.
minor comments (3)
- Abstract: The superiority claims ('exceeding the performance of state-of-the-art monocular camera detection algorithms' and 'maintaining lower latency') are presented without any numerical values, error metrics, or dataset statistics, which is atypical and reduces the abstract's utility for readers.
- The manuscript would benefit from an explicit statement in the evaluation section of the number of frames/sequences, track variations, and whether cross-validation or multiple runs were used to establish statistical significance of the reported gains.
- Figure captions and table headers should consistently report units (e.g., latency in ms, range in meters) and the exact YOLO variant/backbone employed.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper describes an empirical computer-vision pipeline (YOLO-based keypoint detection plus domain geometry for monocular 3D pose) evaluated on real-world racing data with direct SOTA comparisons and released code. No equations, derivations, or first-principles claims appear in the abstract or described content that reduce a result to its own fitted inputs or self-citations by construction. The central performance claims rest on external benchmarks rather than internal self-definition or renamed fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Monocular keypoint detection can be combined with known track geometry to recover accurate 3D poses at long range.
Reference graph
Works this paper leans on
-
[1]
Indy Autonomous Challenge
IAC, “Indy Autonomous Challenge.” [Online]. Available: https: //www.indyautonomouschallenge.com/
-
[2]
Abu Dhabi Autonomous Racing League in UAE|A2RL
Aspire, “Abu Dhabi Autonomous Racing League in UAE|A2RL.” [Online]. Available: https://a2rl.io
-
[3]
Indy Autonomous Challenge – Autonomous Race Cars at the Handling Limits,
A. Wischnewskiet al., “Indy Autonomous Challenge – Autonomous Race Cars at the Handling Limits,” Feb. 2022, arXiv:2202.03807 [cs]. [Online]. Available: http://arxiv.org/abs/2202.03807
arXiv 2022
-
[4]
Head-to-Head autonomous racing at the limits of handling in the A2RL challenge,
S. Hoffmannet al., “Head-to-Head autonomous racing at the limits of handling in the A2RL challenge,” Feb. 2026, arXiv:2602.08571 [cs]. [Online]. Available: http://arxiv.org/abs/2602.08571
arXiv 2026
-
[5]
er.autopilot 1.1: A Software Stack for Autonomous Racing on Oval and Road Course Tracks,
A. Rajiet al., “er.autopilot 1.1: A Software Stack for Autonomous Racing on Oval and Road Course Tracks,”IEEE Transactions on Field Robotics, vol. 1, pp. 332–359, 2024. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/10756753
arXiv 2024
-
[6]
Multi-Modal Sensor Fusion and Object Tracking for Autonomous Racing,
P. Karle, F. Fent, S. Huch, F. Sauerbeck, and M. Lienkamp, “Multi-Modal Sensor Fusion and Object Tracking for Autonomous Racing,”IEEE Transactions on Intelligent V ehicles, vol. 8, no. 7, pp. 3871–3883, Jul. 2023. [Online]. Available: https://ieeexplore.ieee.org/ abstract/document/10113239
arXiv 2023
-
[7]
Overview of our OS sensors|Ouster
Ouster, “Overview of our OS sensors|Ouster.” [Online]. Available: https://ouster.com/os-overview
-
[8]
Pandar128 360° High-Performance Long-Range Lidar
Hesai, “Pandar128 360° High-Performance Long-Range Lidar.” [Online]. Available: https://www.hesaitech.com/product/pandar128/
-
[9]
Luminar’s Technologies
Luminar, “Luminar’s Technologies.” [Online]. Available: https: //www.luminartech.com/technology
-
[10]
Falcon K, Seyond 1st Generation Ultra-long Range LiDAR
Seyond, “Falcon K, Seyond 1st Generation Ultra-long Range LiDAR.” [Online]. Available: https://www.seyond.com/products/falcon-k1/
-
[11]
Center-based 3D Object Detection and Tracking,
T. Yin, X. Zhou, and P. Krahenbuhl, “Center-based 3D Object Detection and Tracking,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021, pp. 11 779–11 788. [Online]. Available: https://ieeexplore.ieee.org/document/9578166/
arXiv 2021
-
[12]
nuScenes: A Multimodal Dataset for Autonomous Driving,
H. Caesaret al., “nuScenes: A Multimodal Dataset for Autonomous Driving,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, W A, USA: IEEE, Jun. 2020, pp. 11 618–11 628. [Online]. Available: https://ieeexplore.ieee.org/ document/9156412/
arXiv 2020
-
[13]
V oxelNeXt: Fully Sparse V oxelNet for 3D Object Detection and Tracking,
Y . Chen, J. Liu, X. Zhang, X. Qi, and J. Jia, “V oxelNeXt: Fully Sparse V oxelNet for 3D Object Detection and Tracking,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver, BC, Canada: IEEE, 2023, pp. 21 674–21 683. [Online]. Available: https://ieeexplore.ieee.org/document/10204123/
arXiv 2023
-
[14]
YOLOv12: Attention-Centric Real-Time Object Detectors,
Y . Tian, Q. Ye, and D. Doermann, “YOLOv12: Attention-Centric Real-Time Object Detectors,” Feb. 2025, arXiv:2502.12524 [cs]. [Online]. Available: http://arxiv.org/abs/2502.12524
Pith/arXiv arXiv 2025
-
[15]
Ultralytics YOLO11
Ultralytics, “Ultralytics YOLO11.” [Online]. Available: https://docs. ultralytics.com/models/yolo11/
-
[16]
KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D,
Y . Liao, J. Xie, and A. Geiger, “KITTI-360: A Novel Dataset and Benchmarks for Urban Scene Understanding in 2D and 3D,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 3, pp. 3292–3310, Mar. 2023. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9786676
arXiv 2023
-
[17]
KITTI-360 3D Bounding Box Leaderboard
KITTI-360, “KITTI-360 3D Bounding Box Leaderboard.” [On- line]. Available: https://www.cvlibs.net/datasets/kitti-360/leaderboard scene understanding.php?task=box3d
-
[18]
MonoDTR: Monocular 3D Object Detection With Depth-Aware Transformer,
K.-C. Huang, T.-H. Wu, H.-T. Su, and W. H. Hsu, “MonoDTR: Monocular 3D Object Detection With Depth-Aware Transformer,” 2022, pp. 4012–4021
2022
-
[19]
MonoDETR: Depth-guided Transformer for Monocular 3D Object Detection,
R. Zhanget al., “MonoDETR: Depth-guided Transformer for Monocular 3D Object Detection,” in2023 IEEE/CVF International Conference on Computer Vision (ICCV). Paris, France: IEEE, Oct. 2023, pp. 9121–9132. [Online]. Available: https://ieeexplore.ieee.org/ document/10378586/
arXiv 2023
-
[20]
MonoCD: Monocular 3D Object Detection with Complementary Depths,
L. Yan, P. Yan, S. Xiong, X. Xiang, and Y . Tan, “MonoCD: Monocular 3D Object Detection with Complementary Depths,” 2024, pp. 10 248– 10 257
2024
-
[21]
SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation,
Z. Liu, Z. Wu, and R. Toth, “SMOKE: Single-Stage Monocular 3D Object Detection via Keypoint Estimation,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Seattle, W A, USA: IEEE, Jun. 2020, pp. 4289–4298. [Online]. Available: https://ieeexplore.ieee.org/document/9150775/
arXiv 2020
-
[22]
Disentangling Monocular 3D Object Detection,
A. Simonelli, S. R. Bulo, L. Porzi, M. Lopez-Antequera, and P. Kontschieder, “Disentangling Monocular 3D Object Detection,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV). Seoul, Korea (South): IEEE, Oct. 2019, pp. 1991–1999. [Online]. Available: https://ieeexplore.ieee.org/document/9010618/
arXiv 2019
-
[23]
Fully Sparse 3D Ob- ject Detection,
L. Fan, F. Wang, N. Wang, and Z.-X. Zhang, “Fully Sparse 3D Ob- ject Detection,”Advances in Neural Information Processing Systems, vol. 35, pp. 351–363, Dec. 2022
2022
-
[24]
onnx/onnx,
ONNX, “onnx/onnx,” Feb. 2026, original-date: 2017-09- 07T04:53:45Z. [Online]. Available: https://github.com/onnx/onnx
2026
-
[25]
NVIDIA/TensorRT,
NVIDIA, “NVIDIA/TensorRT,” Feb. 2026, original-date: 2019- 05-02T22:02:08Z. [Online]. Available: https://github.com/NVIDIA/ TensorRT
2026
-
[26]
NVIDIA-AI-IOT/CUDA-PointPillars,
NVIDIA, “NVIDIA-AI-IOT/CUDA-PointPillars,” Feb. 2026, original- date: 2021-11-16T02:50:38Z. [Online]. Available: https://github.com/ NVIDIA-AI-IOT/CUDA-PointPillars
2026
-
[27]
tier4/AWML,
Tier4, “tier4/AWML,” Feb. 2026, original-date: 2025-02- 26T07:17:44Z. [Online]. Available: https://github.com/tier4/AWML
2026
-
[28]
mmdet3d,
OpenMMLab, “mmdet3d,” Jul. 2020, original-date: 2020-07- 08T03:39:45Z. [Online]. Available: https://github.com/open-mmlab/ mmdetection3d
2020
-
[29]
Pose Estimation for Augmented Reality: A Hands-On Survey,
E. Marchand, H. Uchiyama, and F. Spindler, “Pose Estimation for Augmented Reality: A Hands-On Survey,”IEEE Transactions on Visualization and Computer Graphics, vol. 22, no. 12, pp. 2633–2651, Dec. 2016. [Online]. Available: https://ieeexplore.ieee.org/document/ 7368948
2016
-
[30]
Perspective-n-Point (PnP) pose computation
OpenCV, “Perspective-n-Point (PnP) pose computation.” [Online]. Available: https://docs.opencv.org/3.4/d5/d1f/calib3d solvePnP.html
-
[31]
A General Sufficient Condition of Four Positive Solutions of the P3P Problem,
C.-X. Zhang and Z.-Y . Hu, “A General Sufficient Condition of Four Positive Solutions of the P3P Problem,”Journal of Computer Science and Technology, vol. 20, no. 6, pp. 836–842, Nov. 2005. [Online]. Available: https://doi.org/10.1007/s11390-005-0836-0
-
[32]
EPnP: An Accurate O(n) Solution to the PnP Problem,
V . Lepetit, F. Moreno-Noguer, and P. Fua, “EPnP: An Accurate O(n) Solution to the PnP Problem,”International Journal of Computer Vision, vol. 81, no. 2, pp. 155–166, Feb. 2009. [Online]. Available: https://doi.org/10.1007/s11263-008-0152-6
-
[33]
A Consistently Fast and Globally Optimal Solution to the Perspective-n-Point Problem,
G. Terzakis and M. Lourakis, “A Consistently Fast and Globally Optimal Solution to the Perspective-n-Point Problem,” inComputer Vision – ECCV 2020, A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, Eds. Cham: Springer International Publishing, 2020, pp. 478– 494
2020
-
[34]
Rethinking on Multi-Stage Networks for Human Pose Estimation,
W. Liet al., “Rethinking on Multi-Stage Networks for Human Pose Estimation,” May 2019, arXiv:1901.00148 [cs]. [Online]. Available: http://arxiv.org/abs/1901.00148
Pith/arXiv arXiv 2019
-
[35]
OpenMMLab Pose Estimation Toolbox and Benchmark,
MMPose Contributors, “OpenMMLab Pose Estimation Toolbox and Benchmark,” Aug. 2020, original-date: 2020-07-08T06:02:55Z. [Online]. Available: https://github.com/open-mmlab/mmpose
2020
-
[36]
RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose,
T. Jianget al., “RTMPose: Real-Time Multi-Person Pose Estimation based on MMPose,” Jul. 2023, arXiv:2303.07399 [cs]. [Online]. Available: http://arxiv.org/abs/2303.07399
arXiv 2023
-
[37]
Monocular 6-DoF Pose Estimation of Spacecrafts Utilizing Self-iterative Optimization and Motion Consistency,
Y . Zhanget al., “Monocular 6-DoF Pose Estimation of Spacecrafts Utilizing Self-iterative Optimization and Motion Consistency,” 2024, pp. 6847–6856. [Online]. Available: https://openaccess.thecvf.com/content/CVPR2024W/AI4Space/html/ Zhang Monocular 6-DoF Pose Estimation of Spacecrafts Utilizing Self-iterative Optimization and CVPRW 2024 paper.html
2024
-
[38]
RTM3D: Real-Time Monocular 3D Detection from Object Keypoints for Autonomous Driving,
P. Li, H. Zhao, P. Liu, and F. Cao, “RTM3D: Real-Time Monocular 3D Detection from Object Keypoints for Autonomous Driving,” in Computer Vision – ECCV 2020. Springer, Cham, 2020, pp. 644–
2020
-
[39]
Available: https://link.springer.com/chapter/10.1007/ 978-3-030-58580-8 38
[Online]. Available: https://link.springer.com/chapter/10.1007/ 978-3-030-58580-8 38
-
[40]
Geometry-based Distance Decomposition for Monocular 3D Object Detection,
X. Shiet al., “Geometry-based Distance Decomposition for Monocular 3D Object Detection,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, Oct. 2021, pp. 15 152–15 161. [Online]. Available: https: //ieeexplore.ieee.org/document/9711219/
arXiv 2021
-
[41]
PETR: Position Embedding Transformation for Multi-view 3D Object Detection,
Y . Liu, T. Wang, X. Zhang, and J. Sun, “PETR: Position Embedding Transformation for Multi-view 3D Object Detection,” inComputer Vision – ECCV 2022, S. Avidan, G. Brostow, M. Ciss ´e, G. M. Farinella, and T. Hassner, Eds. Cham: Springer Nature Switzerland, 2022, vol. 13687, pp. 531–548, series Title: Lecture Notes in Computer Science. [Online]. Available:...
-
[42]
End-to-End 6DoF Pose Estimation From Monocular RGB Images,
W. Zouet al., “End-to-End 6DoF Pose Estimation From Monocular RGB Images,”IEEE Transactions on Consumer Electronics, vol. 67, no. 1, pp. 87–96, Feb. 2021. [Online]. Available: https://ieeexplore.ieee.org/document/9347540/
arXiv 2021
-
[43]
Vision meets robotics: The kitti dataset.Int
A. Geiger, P. Lenz, C. Stiller, and R. Urtasun, “Vision meets robotics: The KITTI dataset,”The International Journal of Robotics Research, vol. 32, no. 11, pp. 1231–1237, Sep. 2013. [Online]. Available: https://doi.org/10.1177/0278364913491297
-
[44]
Monocular 3D Detection With Geometric Constraint Embedding and Semi-Supervised Training,
P. Li and H. Zhao, “Monocular 3D Detection With Geometric Constraint Embedding and Semi-Supervised Training,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 5565– 5572, Jul. 2021. [Online]. Available: https://ieeexplore.ieee.org/ abstract/document/9361326
arXiv 2021
-
[45]
AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection,
Z. Liu, D. Zhou, F. Lu, J. Fang, and L. Zhang, “AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal, QC, Canada: IEEE, Oct. 2021, pp. 15 621–15 630. [Online]. Available: https://ieeexplore.ieee.org/document/9710211/
arXiv 2021
-
[46]
BETTY Dataset: A Multi-Modal Dataset for Full-Stack Autonomy,
M. Nyeet al., “BETTY Dataset: A Multi-Modal Dataset for Full-Stack Autonomy,” in2025 IEEE International Conference on Robotics and Automation (ICRA), May 2025, pp. 2453–2460. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/11127350/figures
arXiv 2025
-
[47]
RACECAR - The Dataset for High- Speed Autonomous Racing,
A. Kulkarniet al., “RACECAR - The Dataset for High- Speed Autonomous Racing,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Oct. 2023, pp. 11 458–11 463. [Online]. Available: https://ieeexplore.ieee.org/ abstract/document/10342053
arXiv 2023
-
[48]
Objects are Different: Flexible Monocular 3D Object Detection,
Y . Zhang, J. Lu, and J. Zhou, “Objects are Different: Flexible Monocular 3D Object Detection,” in2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, Jun. 2021, pp. 3288–3297. [Online]. Available: https://ieeexplore.ieee.org/document/9578273/
arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.