Beyond Static Leaderboards: Predictive Validity for the Evaluation of LLM Agents
Pith reviewed 2026-06-26 17:59 UTC · model grok-4.3
The pith
Aggregate scores on LLM agent benchmarks fail to predict rankings in new settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Aggregate-score leaderboards for LLM agents systematically underspecify evaluation because rankings derived from them do not transfer to out-of-distribution settings, as shown by direct rank instability in public-to-hidden competition retrospectives. The paper proposes ranking configurations by predictive validity, the correlation between in-sample and out-of-sample rank, rather than by in-sample mean, and operationalizes this position through three falsifiable out-of-distribution criteria with explicit thresholds.
What carries the argument
Predictive validity, the correlation between in-sample and out-of-sample rank, used to select and compare agent configurations instead of aggregate mean performance.
If this is right
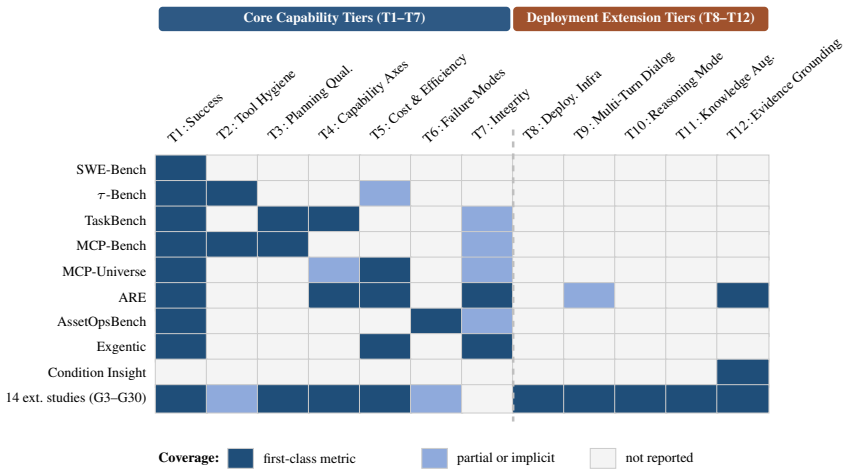
- Current benchmarks such as HELM and its successors collapse deployment-relevant dimensions that the twelve-tier apparatus makes visible.
- Agent configurations should be ranked by how well their order holds on unseen data rather than by current average scores.
- Three explicit out-of-distribution criteria with defined thresholds provide concrete tests for whether a leaderboard is predictively valid.
- Future agent benchmarks should report predictive-validity metrics in addition to raw scores.
Where Pith is reading between the lines
- Benchmark designers would need to maintain larger, more diverse held-out sets to compute reliable rank correlations.
- Deployed teams might run small targeted out-of-sample probes before trusting leaderboard orderings for production choices.
- If predictive validity remains low on many tasks, it would indicate that single-benchmark leaderboards are structurally insufficient for agent selection.
Load-bearing premise
The fourteen parallel studies and seven prior benchmarks supply representative evidence of systematic rank instability across the broader space of deployed LLM agents.
What would settle it
A study across many agent configurations that finds high correlation between aggregate-score ranks and out-of-distribution ranks would falsify the central claim.
Figures


read the original abstract
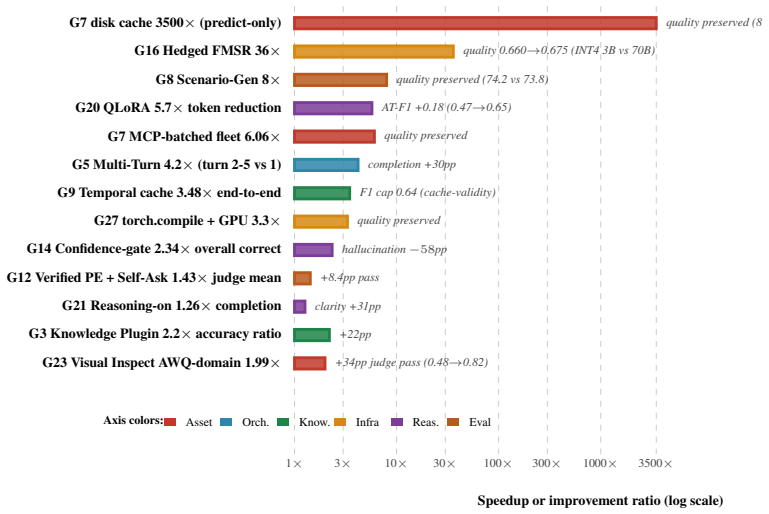
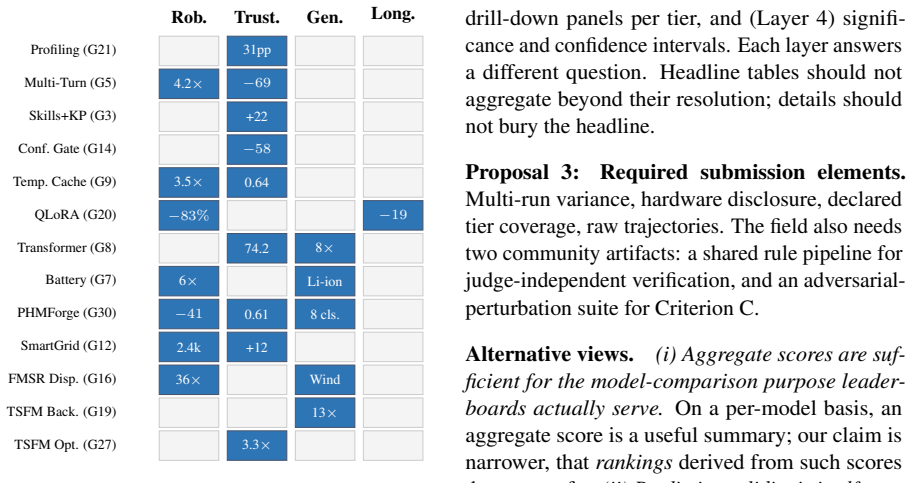
Agent benchmarks are growing fast, but no single benchmark touches more than four or five of the dimensions that deployment exposes. This paper aggregates the largest coordinated deep-dive of one MCP-based industrial-agent benchmark to date: fourteen parallel implementation studies covering new asset classes (including a multi-modal visual extension), alternative orchestrations, retrieval strategies, reasoning modes, infrastructure optimizations, and evaluation-methodology probes. Consolidating those studies with seven prior agent benchmarks, we argue that aggregate-score leaderboards systematically underspecify deployed-agent evaluation. Rankings derived from aggregate scores do not transfer to out-of-distribution settings; recent public-to-hidden competition retrospectives provide direct empirical evidence of this rank instability. We propose ranking configurations by predictive validity, the correlation between in-sample and out-of-sample rank, rather than in-sample mean, and report a twelve-tier measurement apparatus that exposes the deployment-relevant dimensions HELM and its agent-era successors collapse. The position is operationalized through three falsifiable out-of-distribution criteria with explicit thresholds; existing evidence partly supports it but is too thin to confirm. We close with a pre-registered pilot design and a field-level vision for what the next generation of agentic benchmarks should report.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper aggregates fourteen parallel implementation studies on one MCP-based industrial-agent benchmark (covering asset classes, orchestrations, retrieval, reasoning, infrastructure, and evaluation probes) together with seven prior agent benchmarks. It claims that aggregate-score leaderboards systematically underspecify deployed-agent evaluation because rankings derived from in-sample means do not transfer to out-of-distribution settings, citing public-to-hidden competition retrospectives as direct evidence of rank instability. The authors propose replacing mean-based ranking with predictive validity (correlation between in-sample and out-of-sample rank) and introduce a twelve-tier measurement apparatus exposing dimensions collapsed by HELM-style benchmarks, operationalized via three falsifiable OOD criteria with explicit thresholds. They note that existing evidence partly supports the position but is too thin to confirm, and close with a pre-registered pilot design.
Significance. If the rank-instability claim generalizes beyond the single benchmark family examined, the work could meaningfully shift LLM-agent evaluation practice toward predictive-validity metrics and multi-dimensional reporting. The explicit falsifiable criteria, acknowledgment that evidence is thin, and pre-registered pilot are strengths that align with open-science norms. However, the narrow evidence base limits immediate impact; the proposal's motivating premise depends on demonstrating that the observed instability is not an artifact of the MCP benchmark structure.
major comments (2)
- [Abstract] Abstract and the description of the fourteen studies: all fourteen parallel implementations are variants on a single MCP-based industrial benchmark (new asset classes, orchestrations, retrieval, etc.). The seven prior benchmarks are invoked to support the 'systematic' qualifier without an explicit domain-coverage or diversity analysis. This directly affects the load-bearing claim that aggregate-score rankings 'do not transfer' in general and that the predictive-validity alternative should replace mean-based ranking across deployed LLM agents.
- [Abstract] Abstract: the three falsifiable OOD criteria and twelve-tier apparatus are presented as operationalizing the position, yet no quantitative results, thresholds, or correlation values from the fourteen studies are supplied to show how these criteria were derived or validated. Without these details the apparatus remains a proposal rather than demonstrated machinery.
minor comments (2)
- The manuscript would benefit from a table or diagram summarizing the twelve tiers and their mapping to the three OOD criteria.
- Clarify whether the seven prior benchmarks were re-analyzed with the new predictive-validity metric or only cited qualitatively.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the strengths of the falsifiable criteria, acknowledgment of thin evidence, and pre-registered pilot. We respond point-by-point to the major comments below, with revisions where appropriate to strengthen clarity without overstating the current evidence base.
read point-by-point responses
-
Referee: [Abstract] Abstract and the description of the fourteen studies: all fourteen parallel implementations are variants on a single MCP-based industrial benchmark (new asset classes, orchestrations, retrieval, etc.). The seven prior benchmarks are invoked to support the 'systematic' qualifier without an explicit domain-coverage or diversity analysis. This directly affects the load-bearing claim that aggregate-score rankings 'do not transfer' in general and that the predictive-validity alternative should replace mean-based ranking across deployed LLM agents.
Authors: We agree that the fourteen studies examine variants within one MCP-based benchmark family to enable controlled analysis of rank instability. The seven prior benchmarks span distinct domains (e.g., web agents, coding agents, tool-use tasks), but we did not conduct a formal domain-coverage or diversity analysis. We will revise the manuscript to add a brief discussion of the combined benchmark coverage, qualify the generalization language to emphasize that the primary evidence is from the MCP family with supporting patterns from priors, and note that broader validation across additional families is required. This addresses the concern while preserving the core argument that instability was observed even under deep, coordinated probing. revision: partial
-
Referee: [Abstract] Abstract: the three falsifiable OOD criteria and twelve-tier apparatus are presented as operationalizing the position, yet no quantitative results, thresholds, or correlation values from the fourteen studies are supplied to show how these criteria were derived or validated. Without these details the apparatus remains a proposal rather than demonstrated machinery.
Authors: The abstract is a high-level summary. The full text describes the twelve-tier apparatus and the three OOD criteria (with explicit thresholds) in the methods and operationalization sections; the criteria were derived from patterns observed across the fourteen studies plus literature on public-to-hidden rank shifts. However, as the manuscript already states, the fourteen studies provide only partial support and the evidence remains too thin for full validation—the apparatus is therefore proposed rather than fully demonstrated. We will revise the abstract to explicitly note that the criteria and apparatus are proposed and will be tested via the pre-registered pilot, avoiding any implication of completed quantitative validation from the current studies. revision: yes
Circularity Check
No significant circularity; derivation relies on external retrospectives and independent empirical studies
full rationale
The paper's core argument—that aggregate-score rankings fail to transfer OOD—is supported by cited public-to-hidden competition retrospectives (external to the authors) plus the authors' own 14 implementation studies on one benchmark family. No equations, fitted parameters, or self-citations are shown to reduce the central claim or the proposed predictive-validity metric to those inputs by construction. The 14 studies function as new data collection rather than a statistical fit renamed as prediction, and the proposal to use in-sample/out-of-sample rank correlation is presented as an alternative metric without evidence that its thresholds or criteria were tuned on the same results. The abstract explicitly notes that existing evidence is 'too thin to confirm,' indicating the authors treat the claim as provisional rather than self-verifying. This satisfies the self-contained criterion with no load-bearing reduction to self-generated inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.03828 , year=
Assetopsbench: Benchmarking ai agents for task automation in industrial asset operations and maintenance , author=. arXiv preprint arXiv:2506.03828 , year=
-
[2]
2026 , url=
Zhenting Wang and Qi Chang and Hemani Patel and Shashank Biju and Cheng-En Wu and Quan Liu and Aolin Ding and Alireza Rezazadeh and Ankit Shah and Yujia Bao and Eugene Siow , booktitle=. 2026 , url=
2026
-
[3]
arXiv preprint arXiv:2508.14704 , year=
Mcp-universe: Benchmarking large language models with real-world model context protocol servers , author=. arXiv preprint arXiv:2508.14704 , year=
-
[4]
arXiv preprint arXiv:2509.17158 , year=
Are: Scaling up agent environments and evaluations , author=. arXiv preprint arXiv:2509.17158 , year=
-
[5]
Advances in Neural Information Processing Systems , volume=
Taskbench: Benchmarking large language models for task automation , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
arXiv preprint arXiv:2602.22953 , year=
General agent evaluation , author=. arXiv preprint arXiv:2602.22953 , year=
-
[7]
arXiv preprint arXiv:2603.08171 , year=
Evidence-Driven Reasoning for Industrial Maintenance Using Heterogeneous Data , author=. arXiv preprint arXiv:2603.08171 , year=
-
[8]
International Conference on Learning Representations , volume=
Swe-bench: Can language models resolve real-world github issues? , author=. International Conference on Learning Representations , volume=
-
[9]
arXiv preprint arXiv:2406.12045 , year=
tau-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
-
[10]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[11]
2026 , note =
AgentOpsBench: High-Throughput Agentic AI for Battery Analytics , author =. 2026 , note =
2026
-
[12]
2026 , note =
Towards Multi-Turn Dialog Systems for Industrial Asset Operations and Maintenance , author=. 2026 , note =
2026
-
[13]
2026 , note =
Profiling and Optimizing the AssetOpsBench Plan-Execute Pipeline , author =. 2026 , note =
2026
-
[14]
Skills and Knowledge Plugin
Li, Andrew and Natarajan, Kirthana and On, Thai and Maturi, Trisha and Bhuvanesh, Yeshitha , year=. Skills and Knowledge Plugin
-
[15]
Skill-Knowledge-Augmented Agents on
Mazeeva, Vera and Abbaszadeh, Mana and Arora, Shrey and Shejwal, Sanskruti , institution=. Skill-Knowledge-Augmented Agents on. 2026 , url =
2026
-
[16]
arXiv preprint arXiv:2605.20630 , year=
Evaluating Temporal Semantic Caching and Workflow Optimization in Agentic Plan-Execute Pipelines , author=. arXiv preprint arXiv:2605.20630 , year=
-
[17]
2026 , note =
Internalizing MCP Tool Knowledge in Small LLMs via QLoRA Fine-Tuning , author =. 2026 , note =
2026
-
[18]
Extending
Kumar, Sagar Chethan and Kanathur, Rohith and Kapoor, Ananya and Bahl, Dev , institution=. Extending. 2026 , note =
2026
-
[19]
arXiv preprint arXiv:2604.01532 , year=
PHMForge: Evaluating LLM Agents on Industrial Prognostics through MCP-Native, Algorithm-Grounded Tools , author=. arXiv preprint arXiv:2604.01532 , year=
-
[20]
Bhandari, Akshat and Fan, Aaron and Rathod, Tanisha and Xin, Wei Alexander , institution=
-
[21]
, institution=
Jebbouri, Yassine and Maes, Darief Rida and Rachakonda, Shriya Aishani and Iyer, Vivek G. , institution=. Performance Optimization for
-
[22]
Profiling and Optimizing the
Go, Sally and Colman, Sam and Kwon, Byeolah and Pasiecznik, Tomas , institution=. Profiling and Optimizing the
-
[23]
Performance Optimization of the
Vinod, Alisha and Ajai, Thomas and Ang, Jonathan and Vijayakumar, Sanjaii , institution=. Performance Optimization of the
-
[24]
Multi-Modal Agent Inference Optimization for Industrial Asset Operations: Extending
Sheikh, Amaan and Upganlawar, Aman and Rajkondawar, Madhav and Chen, Yang-Jung , institution=. Multi-Modal Agent Inference Optimization for Industrial Asset Operations: Extending
-
[25]
arXiv preprint arXiv:2211.09110 , year=
Holistic evaluation of language models , author=. arXiv preprint arXiv:2211.09110 , year=
-
[26]
Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies , pages=
Dynabench: Rethinking benchmarking in NLP , author=. Proceedings of the 2021 conference of the North American chapter of the Association for Computational Linguistics: human language technologies , pages=
2021
-
[27]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Beyond accuracy: Behavioral testing of NLP models with CheckList , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[28]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
What will it take to fix benchmarking in natural language understanding? , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2021
-
[29]
arXiv preprint arXiv:2111.15366 , year=
AI and the everything in the whole wide world benchmark , author=. arXiv preprint arXiv:2111.15366 , year=
-
[30]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Utility is in the eye of the user: A critique of NLP leaderboards , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[31]
International conference on machine learning , pages=
Do imagenet classifiers generalize to imagenet? , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[32]
arXiv preprint arXiv:2107.07002 , year=
The benchmark lottery , author=. arXiv preprint arXiv:2107.07002 , year=
-
[33]
arXiv preprint arXiv:2605.17829 , year=
Interactive Evaluation Requires a Design Science , author=. arXiv preprint arXiv:2605.17829 , year=
-
[34]
arXiv preprint arXiv:2605.08518 , year=
Results and Retrospective Analysis of the CODS 2025 AssetOpsBench Challenge , author=. arXiv preprint arXiv:2605.08518 , year=
Pith/arXiv arXiv 2025
-
[35]
arXiv preprint arXiv:2605.14167 , year=
The Evaluation Trap: Benchmark Design as Theoretical Commitment , author=. arXiv preprint arXiv:2605.14167 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.