Rethinking Efficient Crack Segmentation with Task-Aligned Structural-Directional Modeling
Pith reviewed 2026-06-28 22:35 UTC · model grok-4.3
The pith
Crack segmentation succeeds more with simple morphology-aligned models than with complex generic hybrid architectures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
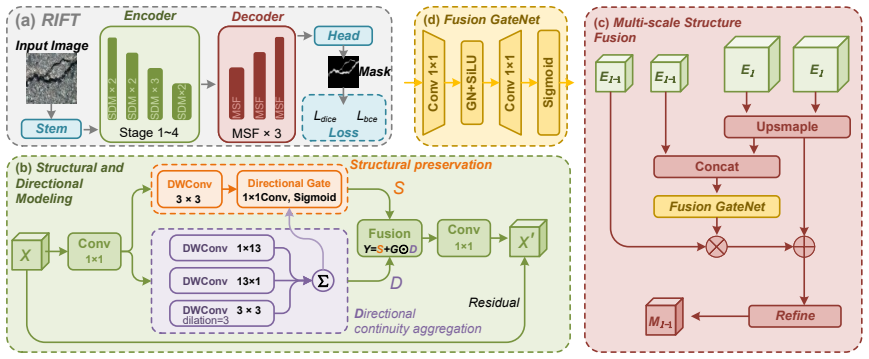
RIFT demonstrates that a deliberately simple architecture aligned to crack morphology—preserving local evidence, aggregating cooperative directional continuity, and restoring structures via lightweight multi-scale fusion—can match or exceed the accuracy of far more complex generic hybrid models while remaining compact enough for efficient deployment.
What carries the argument
RIFT, a family of compact models that preserve local evidence, aggregate directional continuity through task-specific operations, and restore crack structures with lightweight multi-scale fusion.
If this is right
- Task-aligned inductive bias can replace architectural complexity for problems with strong morphological regularities.
- Models under one million parameters can deliver state-of-the-art crack segmentation accuracy.
- Topology-aware evaluation becomes a necessary complement to standard pixel metrics for validating structural recovery.
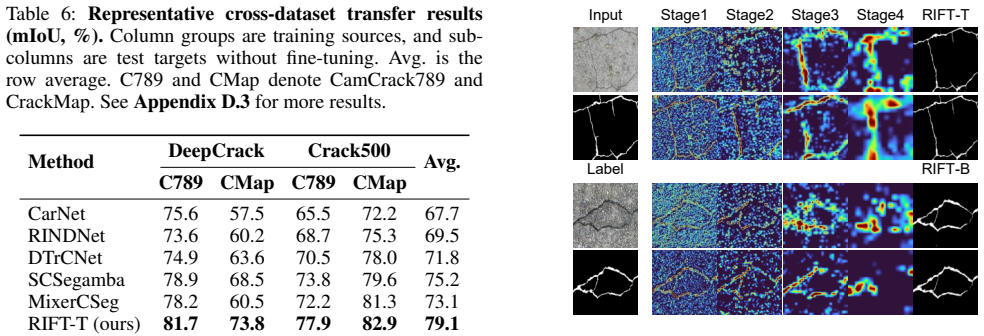
- Transfer experiments confirm that the same lightweight design generalizes across different crack imaging conditions without retraining from scratch.
Where Pith is reading between the lines
- The same structural-directional bias might apply directly to other thin sparse objects such as retinal vessels or road networks.
- Reducing reliance on generic feature mixing could lower compute budgets for real-time inspection systems.
- Future work could test whether adding explicit continuity constraints further improves performance on fragmented cracks.
Load-bearing premise
The four chosen public benchmarks and sixteen metrics sufficiently represent real-world crack segmentation challenges and that the reproduced baselines fairly represent current hybrid approaches.
What would settle it
A new crack dataset containing morphologies or textures outside the four benchmarks where any RIFT variant falls behind the strongest reproduced hybrid baseline on the majority of the sixteen metrics.
Figures







read the original abstract
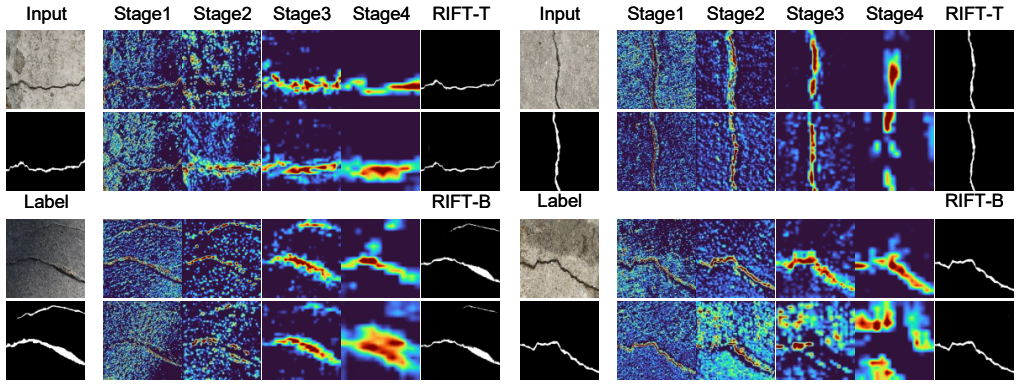
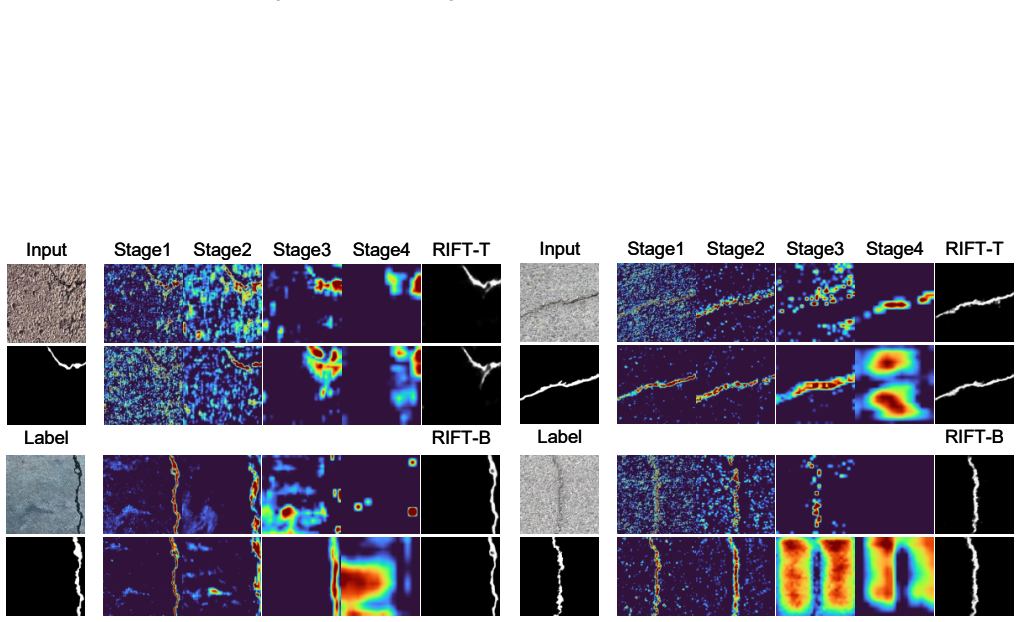
Recent crack segmentation methods often follow generic semantic segmentation designs, using stronger backbones, hybrid CNN-Transformer-Mamba encoders, and auxiliary enhancement branches. Although effective, this raises whether stronger generic feature mixing is the most suitable direction for crack segmentation. We instead formulate crack segmentation as sparse structural recovery. Cracks have limited category-level semantics but strong morphological regularities, being thin, sparse, anisotropic, locally fragmented, and easily confused with textures or shadows. Thus, the key bottleneck lies in preserving weak structural evidence, recovering directional continuity, and suppressing background coupling. We propose RIFT, a compact family of morphology-aligned crack segmentation models. Rather than compressing a complex generic architecture, RIFT is simple by design, preserving local evidence, aggregating cooperative directional continuity, and restoring crack structures through lightweight multi-scale fusion. Experiments on four public benchmarks show that RIFT achieves the best or tied-best results across the 16 main metrics against reproduced representative baselines. RIFT-B gives the strongest overall accuracy, while RIFT-T provides the best deployment efficiency with only 0.47M parameters and high inference speed. Topology-aware evaluation, ablations, transfer experiments, and visualizations further verify that task-aligned simplicity can match or surpass complex hybrid architectures when its inductive bias fits crack morphology. Code: https://github.com/xauat-liushipeng/RIFT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RIFT, a compact family of morphology-aligned models for crack segmentation reformulated as sparse structural recovery (preserving local evidence, aggregating directional continuity, lightweight multi-scale fusion) rather than generic semantic segmentation with hybrid backbones. It claims RIFT achieves best or tied-best results across 16 main metrics on four public benchmarks versus reproduced baselines, with RIFT-B strongest in accuracy and RIFT-T best for efficiency (0.47M parameters); additional support comes from topology-aware evaluation, ablations, transfer experiments, and visualizations.
Significance. If the empirical comparisons hold with fair and fully documented baseline reproductions, the result would be significant for crack segmentation and related sparse-structure tasks: it provides concrete evidence that task-aligned inductive biases can match or exceed complex generic hybrid CNN-Transformer-Mamba designs while enabling extreme efficiency, potentially redirecting research emphasis from backbone scaling to morphology preservation. Code release supports reproducibility.
major comments (2)
- [Abstract] Abstract: the central superiority claim ('best or tied-best results across the 16 main metrics against reproduced representative baselines') is load-bearing yet rests on unreported reproduction details (training protocols, hyperparameter matching, optimization settings). Without these, it is impossible to confirm the baselines fairly represent current generic hybrid approaches.
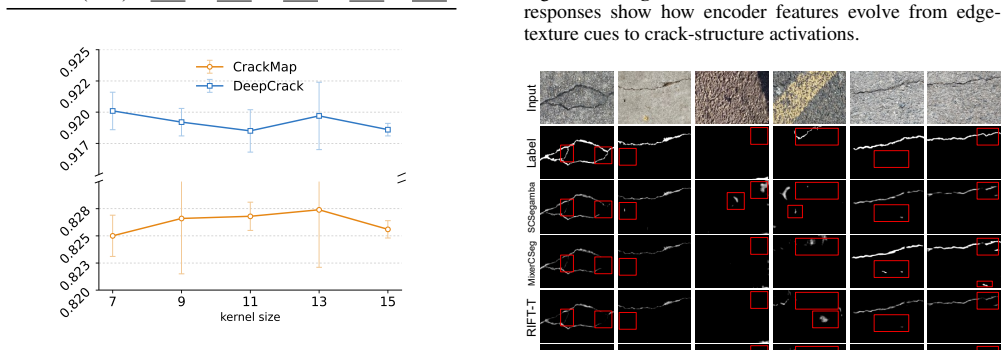
- [Experiments] Experiments section (implied by abstract claims): the 16 main metrics are not enumerated and topology-aware evaluation is mentioned separately, leaving unclear whether the primary metrics adequately capture crack-specific challenges such as thin/sparse/anisotropic continuity and texture confusion; this weakens the generalizability argument.
minor comments (1)
- [Abstract] Abstract: '16 main metrics' is referenced without a list or table reference; adding an explicit enumeration or pointer to the relevant table would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address the concerns regarding reproducibility and metric clarity below, and will revise the manuscript accordingly to improve transparency while preserving the core claims supported by our experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central superiority claim ('best or tied-best results across the 16 main metrics against reproduced representative baselines') is load-bearing yet rests on unreported reproduction details (training protocols, hyperparameter matching, optimization settings). Without these, it is impossible to confirm the baselines fairly represent current generic hybrid approaches.
Authors: We agree that full reproduction details are essential for verifying fair comparisons. The original manuscript followed the official training protocols, hyperparameters, and optimization settings from each baseline paper (with minor adaptations only for input resolution consistency across datasets). To address this, we will add a new subsection titled 'Reproduction Details' in the Experiments section that explicitly lists training epochs, batch sizes, learning rates, optimizers, loss functions, data augmentations, and hardware for all reproduced baselines and our models. This will confirm that the comparisons use matched settings representative of the original works. revision: yes
-
Referee: [Experiments] Experiments section (implied by abstract claims): the 16 main metrics are not enumerated and topology-aware evaluation is mentioned separately, leaving unclear whether the primary metrics adequately capture crack-specific challenges such as thin/sparse/anisotropic continuity and texture confusion; this weakens the generalizability argument.
Authors: The 16 main metrics consist of four standard pixel-level metrics (Precision, Recall, F1-score, mIoU) reported on each of the four benchmarks. We will explicitly enumerate and tabulate these 16 values in the revised Experiments section for clarity. On adequacy for crack-specific challenges: while these metrics are the established primary benchmarks in the crack segmentation literature, we supplement them with topology-aware metrics (e.g., connectivity and thin-structure scores) precisely to evaluate continuity, sparsity, and anisotropy. We will add a short paragraph discussing why the combination of standard and topology-aware metrics addresses texture confusion and morphological preservation, thereby strengthening the generalizability argument without altering the primary evaluation protocol. revision: partial
Circularity Check
No circularity: empirical validation of task-aligned architecture
full rationale
The paper proposes RIFT as a morphology-aligned model for crack segmentation formulated as sparse structural recovery, then reports empirical results on four benchmarks against baselines. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing steps appear in the provided text. Central claims rest on experimental comparisons rather than any reduction to inputs by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cracks have limited category-level semantics but strong morphological regularities (thin, sparse, anisotropic, locally fragmented).
Reference graph
Works this paper leans on
-
[1]
Automatic concrete infrastructure crack semantic seg- mentation using deep learning.Automation in Construction, 152: 104950. Chen, Z.; Shamsabadi, E. A.; Jiang, S.; Shen, L.; and Dias- da Costa, D. 2024. Vision Mamba-based autonomous crack segmentation on concrete, asphalt, and masonry surfaces. arXiv preprint arXiv:2406.16518. Ge, K.; Wang, C.; Guo, Y .;...
-
[2]
Gu, Y .; Meng, Y .; Zheng, K.; Sun, X.; Ji, J.; Ruan, W.; Cao, L.; and Ji, R
Fine-tuning vision foundation model for crack seg- mentation in civil infrastructures.Construction and Building Materials, 431: 136573. Gu, Y .; Meng, Y .; Zheng, K.; Sun, X.; Ji, J.; Ruan, W.; Cao, L.; and Ji, R. 2025. An Efficient and Mixed Het- erogeneous Model for Image Restoration.arXiv preprint arXiv:2504.10967. Guo, Y .; Liu, Y .; Georgiou, T.; and...
-
[3]
InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16560–16569
clDice-a novel topology-preserving loss function for tubular structure segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 16560–16569. Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polosukhin, I. 2017. At- tention is all you need.Advances in neural information ...
-
[4]
IEEE. Rethinking Efficient Crack Segmentation with Task-Aligned Structural-Directional Modeling Supplementary Materials A Implementation Details of RIFT This appendix provides implementation details of RIFT that are not fully described in the main text. To avoid redundancy, we do not repeat the high-level motivation of the proposed framework. Instead, we ...
-
[5]
Batch Normalization is not used in RIFT
SiLU is used consistently as the activation function throughout the network because it is empirically stable and well matched to the lightweight convolutional design. Batch Normalization is not used in RIFT. The main reason is that crack segmentation experiments are typically conducted with small batch sizes, especially under high-resolution inputs and re...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.