GroundControl: Anticipating Navigation Failures in Vision-Language Agents via Trajectory-Consistent Uncertainty Estimates
Pith reviewed 2026-06-26 17:11 UTC · model grok-4.3
The pith
Trajectory-consistent uncertainty anticipates navigation failures in vision-language agents by tracking deviation from goal-directed dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
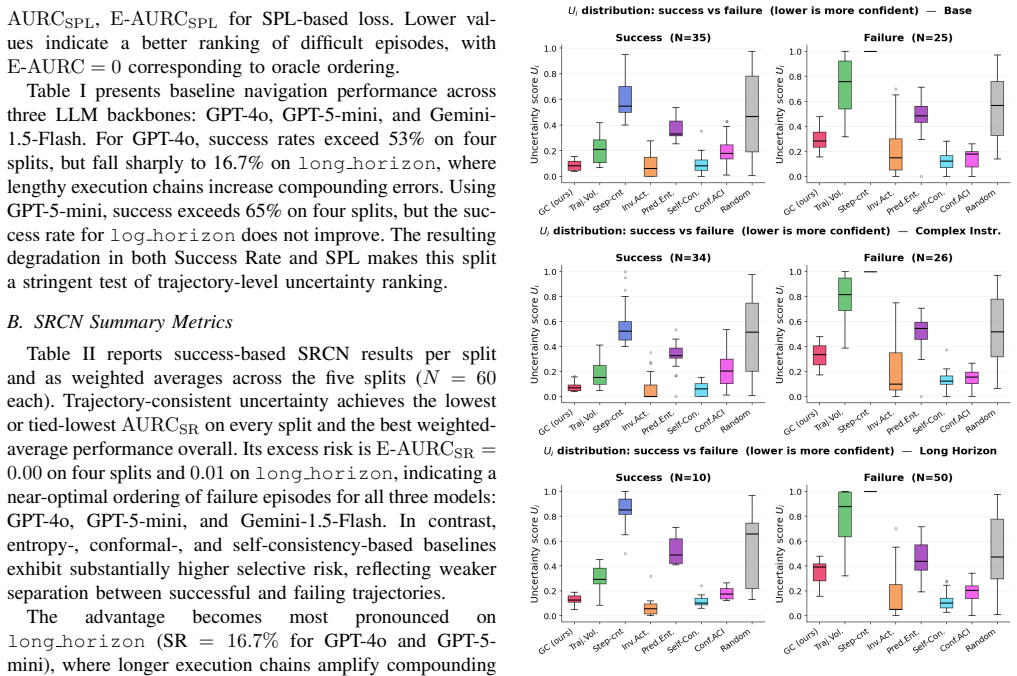
GroundControl defines uncertainty as the statistical deviation from nominal goal-directed distance-to-goal dynamics aggregated over an episode. It models distance evolution with a constant-velocity Kalman filter and combines normalized innovation statistics with trajectory features for progress, monotonicity, path efficiency, and oscillatory behavior. This produces a score reflecting geometric and temporal inconsistency that ranks navigation episodes by success or efficiency better than baselines under the SRCN protocol.
What carries the argument
GroundControl: statistical deviation from nominal goal-directed distance-to-goal dynamics using a constant-velocity Kalman filter combined with trajectory features.
If this is right
- Uncertainty can guide selective execution where only low-uncertainty episodes are attempted autonomously.
- The approach applies across multiple vision-language models without model-specific tuning.
- Risk-coverage curves allow trading off coverage for lower failure rates in navigation tasks.
- Trajectory features provide interpretable reasons for high uncertainty scores.
Where Pith is reading between the lines
- Similar deviation-based monitoring could apply to other embodied tasks involving paths or sequences.
- Real-time computation of the score might enable on-the-fly replanning or human handoff.
- Combining this with action-level entropy could create hybrid uncertainty estimates for more robust systems.
Load-bearing premise
That the expected behavior in successful navigation follows dynamics well-modeled by a constant-velocity Kalman filter on distance to goal.
What would settle it
Running the uncertainty ranking on a new set of navigation episodes and finding that the area under the risk-coverage curve is no better than that of random ranking or standard entropy measures.
Figures




read the original abstract
Vision-language navigation agents achieve competitive average success on benchmark tasks, yet failures often arise through predictable trajectory-level breakdowns such as oscillation, stagnation, or inefficient detours. Reliable deployment, therefore, requires uncertainty signals that anticipate emerging failure dynamics during execution rather than reflect only instantaneous action entropy. We introduce \emph{GroundControl}, a trajectory-consistent uncertainty estimator defined as statistical deviation from nominal goal-directed distance-to-goal dynamics aggregated over an episode. GroundControl models distance evolution using a constant-velocity Kalman filter and combines normalized innovation statistics with complementary trajectory features capturing progress, monotonicity, path efficiency, and oscillatory behavior. The resulting uncertainty score reflects geometric and temporal inconsistency in navigation behavior rather than local prediction dispersion. To evaluate uncertainty quality independently of task success, we formalize \emph{Selective Risk--Coverage Navigation (SRCN)}, a protocol that measures how effectively an uncertainty score ranks episodes by failure or inefficiency using risk--coverage curves and AURC / E-AURC summaries. Across five EB-Navigation splits ($N=300$ episodes), trajectory-consistent uncertainty achieves near-oracle ordering under success-based selective risk, with weighted-average $\mathrm{E\text{-}AURC}_{\mathrm{SR}}=0.0024$ for the GPT-4o model, substantially outperforming entropy-, conformal-, and heuristic baselines. Under SPL-based selective evaluation, GroundControl consistently achieves the lowest AURC and E-AURC across models and navigation splits. These results show that modeling deviation from goal-directed dynamics provides an interpretable and robust signal for anticipating navigation failures in vision-language agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GroundControl, a trajectory-consistent uncertainty estimator for vision-language navigation (VLN) agents. It defines uncertainty as statistical deviation from nominal goal-directed distance-to-goal dynamics, modeled via a constant-velocity Kalman filter and aggregated with trajectory features for progress, monotonicity, efficiency, and oscillation. The work formalizes Selective Risk-Coverage Navigation (SRCN) for evaluating uncertainty via risk-coverage curves and AURC/E-AURC metrics. On five EB-Navigation splits (N=300 episodes), it reports near-oracle performance under success-based selective risk (weighted-average E-AURC_SR=0.0024 for GPT-4o) and lowest AURC/E-AURC under SPL-based evaluation, outperforming entropy, conformal, and heuristic baselines across models.
Significance. If the modeling assumption holds, GroundControl offers an interpretable, episode-level uncertainty signal focused on geometric/temporal inconsistency rather than local action entropy, which could support more reliable selective deployment of VLN agents. The SRCN protocol is a clear methodological contribution for standardized uncertainty evaluation in navigation. Credit is given for the concrete empirical results across five splits and multiple models, with specific quantitative claims (e.g., E-AURC_SR=0.0024) and consistent outperformance under two selective criteria. The approach is plausible for anticipating predictable failure modes like oscillation or stagnation.
major comments (2)
- [§3] §3 (Method, Kalman filter definition): The central claim that normalized innovation statistics from the constant-velocity Kalman filter on distance-to-goal yield an independent failure signal (distinct from path inefficiency) is load-bearing for the 'trajectory-consistent' interpretation and the reported near-oracle E-AURC_SR. In obstacle-rich embodied settings, successful trajectories routinely exhibit non-constant effective velocity due to turns, avoidance, and discrete actions; the paper must show via correlation analysis or ablation that these statistics are not largely redundant with SPL, otherwise the selective-risk gains may be partly tautological with efficiency metrics already used in evaluation.
- [Experiments] Experiments (EB-Navigation results): The reported E-AURC_SR=0.0024 and consistent lowest AURC/E-AURC under SPL require explicit confirmation that baseline implementations (entropy, conformal, heuristics) match standard definitions and that no post-hoc tuning occurred across the five splits. Without this, the 'substantially outperforming' claim cannot be fully assessed as load-bearing evidence for the method's superiority.
minor comments (2)
- The SRCN protocol and AURC/E-AURC definitions would benefit from a short self-contained recap in the main text (rather than relying solely on appendix) to improve accessibility for readers outside selective-prediction literature.
- Figure captions for risk-coverage curves should explicitly state the number of episodes per split and whether curves are averaged or per-model to aid interpretation of the weighted-average metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential of the SRCN protocol and the empirical results across models and splits. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Method, Kalman filter definition): The central claim that normalized innovation statistics from the constant-velocity Kalman filter on distance-to-goal yield an independent failure signal (distinct from path inefficiency) is load-bearing for the 'trajectory-consistent' interpretation and the reported near-oracle E-AURC_SR. In obstacle-rich embodied settings, successful trajectories routinely exhibit non-constant effective velocity due to turns, avoidance, and discrete actions; the paper must show via correlation analysis or ablation that these statistics are not largely redundant with SPL, otherwise the selective-risk gains may be partly tautological with efficiency metrics already used in evaluation.
Authors: We agree that explicit evidence of non-redundancy with SPL is necessary to support the claim of an independent trajectory-consistent signal. The normalized innovation statistics are intended to capture deviations from expected constant-velocity goal-directed dynamics (including oscillation and non-monotonicity), which are conceptually distinct from aggregate path efficiency. To address this, the revised manuscript will include a correlation analysis (Pearson and Spearman) between each GroundControl component and SPL, computed across all five EB-Navigation splits and models. We will also report the incremental predictive value of the innovation statistics when SPL is already controlled for via partial correlation or ablation. revision: yes
-
Referee: [Experiments] Experiments (EB-Navigation results): The reported E-AURC_SR=0.0024 and consistent lowest AURC/E-AURC under SPL require explicit confirmation that baseline implementations (entropy, conformal, heuristics) match standard definitions and that no post-hoc tuning occurred across the five splits. Without this, the 'substantially outperforming' claim cannot be fully assessed as load-bearing evidence for the method's superiority.
Authors: We confirm that baseline implementations follow standard definitions from the literature and that no post-hoc tuning or split-specific optimization was performed. Entropy is the mean per-step predictive entropy over the action distribution; conformal prediction uses the standard inductive nonconformity score with a fixed calibration set; heuristics are exactly as described in Section 4. All hyperparameters were fixed on a held-out validation split prior to the reported experiments. The revised manuscript will add an appendix subsection with pseudocode, exact parameter values, and library references for each baseline to enable direct reproduction. revision: yes
Circularity Check
No significant circularity in derivation or evaluation
full rationale
The paper defines GroundControl explicitly as normalized innovation statistics from a constant-velocity Kalman filter on distance-to-goal plus hand-specified trajectory features (progress, monotonicity, efficiency, oscillation). This construction is independent of the success or SPL labels used in evaluation. The SRCN protocol then measures empirical ranking quality via AURC/E-AURC on held-out episodes without any parameter fitting to the risk metric itself. No self-citations appear as load-bearing steps, no uniqueness theorems are imported, and no fitted input is relabeled as a prediction. The reported E-AURC_SR=0.0024 is therefore an empirical outcome rather than a definitional identity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Constant-velocity Kalman filter adequately models nominal goal-directed distance-to-goal dynamics in navigation episodes
Reference graph
Works this paper leans on
-
[1]
Navitrace: Evaluating embodied navigation of vision-language models,
T. Windecker, M. Patel, M. Reuss, R. Schwarzkopf, C. Cadena, R. Lioutikov, M. Hutter, and J. Frey, “Navitrace: Evaluating embodied navigation of vision-language models,”arXiv:2510.26909, 2025
arXiv 2025
-
[2]
Vision-language navigation with embodied intelligence: A survey,
P. Gao, P. Wang, F. Gao, F. Wang, and R. Yuan, “Vision-language navigation with embodied intelligence: A survey,”arXiv preprint arXiv:2402.14304, 2024
arXiv 2024
-
[3]
Embodied navigation,
Y . Liu, L. Liu, Y . Zheng, Y . Liu, F. Dang, N. Li, and K. Ma, “Embodied navigation,”Science China Information Sciences, vol. 68, no. 4, p. 141101, 2025
2025
-
[4]
Mind the gap: Improving success rate of vision-and-language navigation by revisiting oracle success routes,
C. Zhao, Y . Qi, and Q. Wu, “Mind the gap: Improving success rate of vision-and-language navigation by revisiting oracle success routes,” in Proceedings of the 31st ACM international conference on multimedia, 2023, pp. 4349–4358
2023
-
[5]
Vision-language navigation with self-supervised auxiliary reasoning tasks,
F. Zhu, Y . Zhu, X. Chang, and X. Liang, “Vision-language navigation with self-supervised auxiliary reasoning tasks,” inProceedings of the Fig. 5: Per-episode uncertainty scoreU i versusSPL i for each method. Points are coloured green (success) and red (failure). A well-calibrated estimator produces a negative correlation, highU i for failed/inefficient e...
2020
-
[6]
Vlingnav: Embodied navigation with adap- tive reasoning and visual-assisted linguistic memory,
S. Wang, Y . Luo, X. Chen, A. Luo, D. Li, C. Liu, S. Chen, Y . Zhang, and J. Yu, “Vlingnav: Embodied navigation with adap- tive reasoning and visual-assisted linguistic memory,”arXiv preprint arXiv:2601.08665, 2026
arXiv 2026
-
[7]
Room- across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room- across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 4392–4412
2020
-
[8]
Habitat: A platform for embodied ai research,
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik,et al., “Habitat: A platform for embodied ai research,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 9339–9347
2019
-
[9]
Beyond the nav-graph: Vision-and-language navigation in continuous environ- ments,
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environ- ments,” inEuropean Conference on Computer Vision, 2020
2020
-
[10]
S. Raychaudhuri, D. Ta, K. Ashton, A. X. Chang, J. Wang, and B. Bucher, “Zero-shot object-centric instruction following: Integrat- ing foundation models with traditional navigation,”arXiv preprint arXiv:2411.07848, 2024
arXiv 2024
-
[11]
Efficient-vln: A training-efficient vision-language navigation model,
D. Zheng, S. Huang, Y . Li, and L. Wang, “Efficient-vln: A training-efficient vision-language navigation model,”arXiv preprint arXiv:2512.10310, 2025
arXiv 2025
-
[12]
Embodied navigation foundation model,
J. Zhang, A. Li, Y . Qi, M. Li, J. Liu, S. Wang, H. Liu, G. Zhou, Y . Wu, X. Li,et al., “Embodied navigation foundation model,”arXiv preprint arXiv:2509.12129, 2025
arXiv 2025
-
[13]
A survey on evaluation of embodied ai,
L. Hou, L. Gao, Y . Wu, and Y . Chang, “A survey on evaluation of embodied ai,”Authorea Preprints, 2026
2026
-
[14]
S. Lin, Z. Li, X. Zhao, G. Zhou, L. Wang, R. Wei, R. Tang, J. Li, H. Wang, J. Pang,et al., “Vlnverse: A benchmark for vision- language navigation with versatile, embodied, realistic simulation and evaluation,”arXiv preprint arXiv:2512.19021, 2025
arXiv 2025
-
[15]
A survey of uncertainty in deep neural networks,
J. Gawlikowski, C. R. N. Tassi, M. Ali, J. Lee, M. Humt, J. Feng, A. Kruspe, R. Triebel, P. Jung, R. Roscher,et al., “A survey of uncertainty in deep neural networks,”Artificial intelligence review, vol. 56, no. Suppl 1, pp. 1513–1589, 2023
2023
-
[16]
Uncertainty in action: Confidence elicitation in embodied agents,
T. Yu, V . Shah, M. Wahed, K. A. Nguyen, A. Juvekar, T. August, and I. Lourentzou, “Uncertainty in action: Confidence elicitation in embodied agents,”arXiv preprint arXiv:2503.10628, 2025
arXiv 2025
-
[17]
S. Tayebati, D. Kumar, N. Darabi, D. Jayasuriya, R. Krishnan, and A. R. Trivedi, “Learning conformal abstention policies for adaptive risk management in large language and vision-language models,”arXiv preprint arXiv:2502.06884, 2025
arXiv 2025
-
[18]
Embodied navigation with auxiliary task of action description prediction,
H. Kondoh and A. Kanezaki, “Embodied navigation with auxiliary task of action description prediction,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 7025–7036
2025
-
[19]
A self- supervised auxiliary loss for deep rl in partially observable settings,
E. Ahmed, L. Zintgraf, C. A. S. de Witt, and N. Usunier, “A self- supervised auxiliary loss for deep rl in partially observable settings,” arXiv preprint arXiv:2104.08492, 2021
arXiv 2021
-
[20]
Auxiliary tasks and explo- ration enable objectgoal navigation,
J. Ye, D. Batra, A. Das, and E. Wijmans, “Auxiliary tasks and explo- ration enable objectgoal navigation,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 16 117–16 126
2021
-
[21]
Vision-and-language nav- igation: Interpreting visually-grounded navigation instructions in real environments,
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision-and-language nav- igation: Interpreting visually-grounded navigation instructions in real environments,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 3674–3683
2018
-
[22]
R. Yang, H. Chen, J. Zhang, M. Zhao, C. Qian, K. Wang, Q. Wang, T. V . Koripella, M. Movahedi, M. Li,et al., “Embodiedbench: Compre- hensive benchmarking multi-modal large language models for vision- driven embodied agents,”arXiv preprint arXiv:2502.09560, 2025
Pith/arXiv arXiv 2025
-
[23]
Adaptive conformal inference under dis- tribution shift,
I. Gibbs and E. Candes, “Adaptive conformal inference under dis- tribution shift,”Advances in Neural Information Processing Systems, vol. 34, pp. 1660–1672, 2021
2021
-
[24]
Self-consistency improves chain of thought reasoning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowd- hery, and D. Zhou, “Self-consistency improves chain of thought reasoning in language models,”arXiv:2203.11171, 2022
Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.