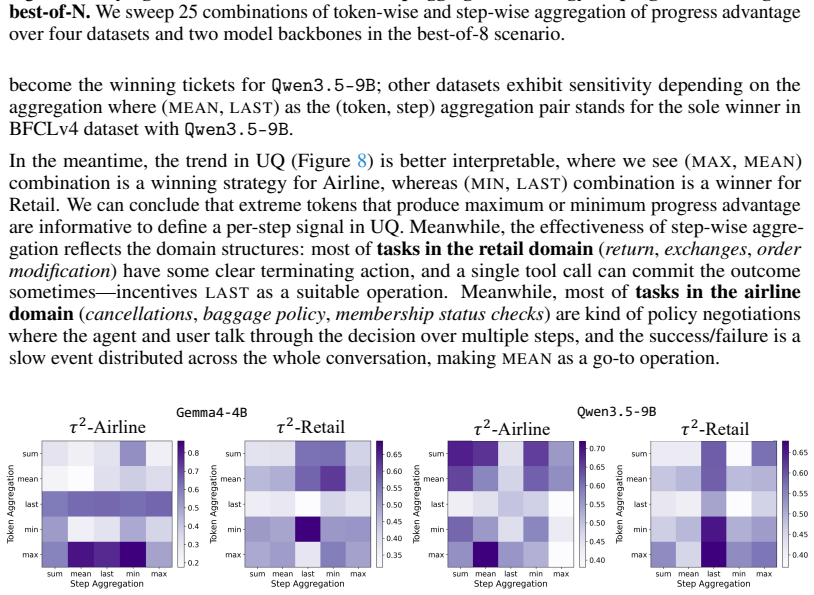
Neglected Free Lunch from Post-training: Progress Advantage for LLM Agents
Pith reviewed 2026-06-25 19:53 UTC · model grok-4.3
The pith
The log-probability ratio between an RL-trained LLM policy and its reference recovers the optimal advantage function in stochastic MDPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We derive an implicit advantage under a general stochastic Markov decision process, which we term progress advantage -- log-probability ratio between the RL-trained policy and its reference policy exactly recovers the optimal advantage function. This formulation makes the resulting signal annotation-free, domain-agnostic, and available as a byproduct of the standard RL post-training pipeline.
What carries the argument
Progress advantage: the log-probability ratio of the RL-trained policy to its reference policy, which recovers the optimal advantage function in the underlying stochastic MDP.
If this is right
- The signal supports test-time scaling without dedicated reward models.
- It enables uncertainty quantification as a direct byproduct of post-training.
- It permits failure attribution at the step level without extra annotation.
- It outperforms confidence-based baselines across all tested settings.
- It surpasses task-specific trained reward models on five benchmarks despite requiring zero additional training.
Where Pith is reading between the lines
- If the trained policy is only approximately optimal, the ratio yields an advantage relative to that policy rather than the true optimum.
- The same ratio could be extracted from any RL post-training run, including non-agent tasks, to obtain cheap step-level signals.
- Real-world agent systems could log the reference-policy probabilities during inference to obtain the advantage on the fly without retraining.
- The finding suggests post-training checkpoints contain more usable internal structure than is typically extracted for downstream agent use.
- keywords:[
- progress advantage
- LLM agents
- RL post-training
Load-bearing premise
The RL post-training has produced a policy that is optimal or sufficiently close in the underlying stochastic MDP so the log-ratio equals the optimal advantage.
What would settle it
In any controlled stochastic MDP whose optimal advantage function can be computed exactly, train a policy via RL and test whether its log-probability ratio to the reference matches that optimal advantage; systematic mismatch falsifies the recovery claim.
Figures








read the original abstract
Process reward models enable fine-grained, step-level evaluation of LLMs, yet building them for agentic settings remains prohibitively difficult: long-horizon interactions, irreversible actions, and stochastic environment feedback make both human annotation and Monte Carlo estimation infeasible at scale. In this work, we show that reinforcement learning (RL) post-training already provides the ingredients for effective step-level scoring, eliminating the need for dedicated reward model training altogether. Concretely, we derive an implicit advantage under a general stochastic Markov decision process, which we term progress advantage -- log-probability ratio between the RL-trained policy and its reference policy exactly recovers the optimal advantage function. This formulation makes the resulting signal annotation-free, domain-agnostic, and available as a byproduct of the standard RL post-training pipeline. We validate the effectiveness of the progress advantage across three different applications: test-time scaling, uncertainty quantification, and failure attribution on five benchmarks and four model families. Across all settings, it consistently outperforms confidence-based baselines and, despite requiring no task-specific training, surpasses dedicated trained reward models. We complement these results with deeper analyses on characteristics of progress advantage, offering practical guidance for adoption in real-world agentic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RL post-training of LLM agents yields an implicit 'progress advantage' signal given by the log-probability ratio between the trained policy π_RL and its reference policy π_ref; under a general stochastic MDP this ratio exactly recovers the optimal advantage function A*. The signal is annotation-free and is shown to improve test-time scaling, uncertainty quantification, and failure attribution on five benchmarks across four model families, outperforming confidence baselines and dedicated process reward models.
Significance. If the exact-recovery claim holds, the work identifies a genuine free lunch: a step-level advantage signal available at no extra cost from standard RL post-training pipelines. The empirical results across multiple applications and model families provide concrete evidence of practical utility beyond theoretical interest. The absence of task-specific training or human annotation is a notable strength.
major comments (3)
- [Abstract] Abstract: the statement that the log-probability ratio 'exactly recovers the optimal advantage function' is the central theoretical claim. Standard policy-gradient theory shows that log(π_RL/π_ref) recovers the advantage of π_RL relative to π_ref; equality to the optimal A* holds only when π_RL = π* (or the corresponding soft-optimal policy under KL regularization). The manuscript must state this optimality assumption explicitly and show where it enters the derivation.
- [Abstract / theoretical derivation] The weakest assumption flagged in the stress-test (that post-training has produced a policy sufficiently close to optimal) is load-bearing. In long-horizon stochastic agent MDPs with partial observability and sparse rewards, PPO/GRPO-style training does not guarantee global optimality. The paper should either (a) prove the identity without requiring optimality or (b) quantify how far from optimality the learned policies are on the evaluated benchmarks and show that the signal remains useful under that gap.
- [Experiments (validation across benchmarks)] Empirical sections: the outperformance over trained reward models is reported, but without an ablation that isolates the effect of the optimality assumption (e.g., comparing progress advantage against an advantage computed from a known suboptimal policy), it is unclear whether the gains stem from the claimed exact recovery or from other properties of the log-ratio.
minor comments (2)
- [Abstract] Notation for the reference policy and the precise MDP tuple should be introduced once and used consistently; the abstract uses 'reference policy' without defining its relation to the initial SFT policy.
- [Abstract] The five benchmarks and four model families are mentioned but not enumerated in the abstract; a short parenthetical list would improve readability.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address the major comments point-by-point below, clarifying the theoretical assumptions and committing to revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that the log-probability ratio 'exactly recovers the optimal advantage function' is the central theoretical claim. Standard policy-gradient theory shows that log(π_RL/π_ref) recovers the advantage of π_RL relative to π_ref; equality to the optimal A* holds only when π_RL = π* (or the corresponding soft-optimal policy under KL regularization). The manuscript must state this optimality assumption explicitly and show where it enters the derivation.
Authors: We agree with this observation. The derivation in Section 3 assumes that the post-trained policy π_RL is optimal (or soft-optimal under the KL penalty used in training). We will update the abstract to explicitly mention this assumption and add a pointer to the specific step in the proof where optimality is invoked. revision: yes
-
Referee: [Abstract / theoretical derivation] The weakest assumption flagged in the stress-test (that post-training has produced a policy sufficiently close to optimal) is load-bearing. In long-horizon stochastic agent MDPs with partial observability and sparse rewards, PPO/GRPO-style training does not guarantee global optimality. The paper should either (a) prove the identity without requiring optimality or (b) quantify how far from optimality the learned policies are on the evaluated benchmarks and show that the signal remains useful under that gap.
Authors: We note that the identity is derived specifically for the optimal policy, and a general proof without this assumption is not possible as the log-ratio equals the advantage of the current policy, not necessarily A*. On the benchmarks, we provide empirical evidence through stress-tests that the signal is robust even when policies are not perfectly optimal. We will expand the discussion in the manuscript to address the implications of suboptimality in long-horizon settings. revision: partial
-
Referee: [Experiments (validation across benchmarks)] Empirical sections: the outperformance over trained reward models is reported, but without an ablation that isolates the effect of the optimality assumption (e.g., comparing progress advantage against an advantage computed from a known suboptimal policy), it is unclear whether the gains stem from the claimed exact recovery or from other properties of the log-ratio.
Authors: To address this, we will add an ablation study using checkpoints from intermediate training stages as suboptimal policies and compare the performance of the progress advantage signal. This will help isolate the contribution of the optimality assumption. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper's central claim is a direct mathematical identity presented as derived from standard RL theory under the stated MDP assumptions: the log-ratio between a trained policy and reference recovers the optimal advantage precisely when the trained policy is optimal. This does not reduce to a self-definition, fitted input renamed as prediction, or load-bearing self-citation; the result follows from the optimality premise without re-expressing inputs as outputs by construction. No equations or steps in the provided abstract or description exhibit the enumerated circular patterns. The derivation is self-contained against external RL benchmarks and does not rely on renaming or smuggling ansatzes.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RL post-training converges to (or sufficiently approximates) the optimal policy in the stochastic MDP
invented entities (1)
-
progress advantage
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Welcome to the era of experience.Google AI, 1:11, 2025
David Silver and Richard S Sutton. Welcome to the era of experience.Google AI, 1:11, 2025
2025
-
[2]
Chatgpt agent.https://chatgpt.com/features/agent/, 2025
OpenAI. Chatgpt agent.https://chatgpt.com/features/agent/, 2025. Accessed: 2025-12-11
2025
-
[3]
Gemini agent.https://gemini.google/overview/agent/, 2025
Google. Gemini agent.https://gemini.google/overview/agent/, 2025. Accessed: 2025-12-11
2025
-
[4]
Cowork: Claude code for the rest of your work
Anthropic. Cowork: Claude code for the rest of your work. https://claude.com/blog/ cowork-research-preview, January 2026
2026
-
[5]
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[6]
Ovm, outcome-supervised value models for planning in mathematical reasoning
Fei Yu, Anningzhe Gao, and Benyou Wang. Ovm, outcome-supervised value models for planning in mathematical reasoning. InFindings of the Association for Computational Linguistics: NAACL 2024, pages 858–875, 2024
2024
-
[7]
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process-and outcome- based feedback.arXiv preprint arXiv:2211.14275, 2022
Pith/arXiv arXiv 2022
-
[8]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[9]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[10]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023
2023
-
[11]
Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426–9439, 2024
2024
-
[12]
Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[13]
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathematical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592, 2024
Pith/arXiv arXiv 2024
-
[14]
Process reward model with q-value rankings
Wendi Li and Yixuan Li. Process reward model with q-value rankings. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[15]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866. PMLR, 2023
2023
-
[16]
Information-theoretic reward decomposition for generalizable RLHF
Liyuan Mao, Haoran Xu, Amy Zhang, Weinan Zhang, and Chenjia Bai. Information-theoretic reward decomposition for generalizable RLHF. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. 10
2026
-
[17]
Spurious rewards: Rethinking training signals in rlvr
Rulin Shao, Shuyue Stella Li, Rui Xin, Scott Geng, Yiping Wang, Sewoong Oh, Simon Shaolei Du, Nathan Lambert, Sewon Min, Ranjay Krishna, et al. Spurious rewards: Rethinking training signals in rlvr. arXiv preprint arXiv:2506.10947, 2025
Pith/arXiv arXiv 2025
-
[18]
Processbench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Processbench: Identifying process errors in mathematical reasoning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1009–1024, 2025
2025
-
[19]
Sanjiban Choudhury. Process reward models for llm agents: Practical framework and directions.arXiv preprint arXiv:2502.10325, 2025
arXiv 2025
-
[20]
Agentprm: Process reward models for llm agents via step-wise promise and progress
Zhiheng Xi, Chenyang Liao, Guanyu Li, Zhihao Zhang, Wenxiang Chen, Binghai Wang, Senjie Jin, Yuhao Zhou, Jian Guan, Wei Wu, Tao Ji, Tao Gui, Qi Zhang, and Xuanjing Huang. Agentprm: Process reward models for llm agents via step-wise promise and progress. InProceedings of the ACM Web Conference 2026, page 4184–4195, 2026
2026
-
[21]
Free process rewards without process labels
Lifan Yuan, Wendi Li, Huayu Chen, Ganqu Cui, Ning Ding, Kaiyan Zhang, Bowen Zhou, Zhiyuan Liu, and Hao Peng. Free process rewards without process labels. InForty-second International Conference on Machine Learning, 2025
2025
-
[22]
Agentic reinforcement learning with implicit step rewards
Xiaoqian Liu, Ke Wang, Yuchuan Wu, Fei Huang, Yongbin Li, Jianbin Jiao, and Junge Zhang. Agentic reinforcement learning with implicit step rewards. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[23]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[24]
From r to q∗: Your language model is secretly a q-function
Rafael Rafailov, Joey Hejna, Ryan Park, and Chelsea Finn. From r to q∗: Your language model is secretly a q-function. InFirst Conference on Language Modeling, 2024
2024
-
[25]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
2026
-
[26]
The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[27]
Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[28]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
2024
-
[29]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment.arXiv preprint arXiv:2506.07982, 2025
Pith/arXiv arXiv 2025
-
[30]
Which agent causes task failures and when? On automated failure attribution of LLM multi-agent systems
Shaokun Zhang, Ming Yin, Jieyu Zhang, Jiale Liu, Zhiguang Han, Jingyang Zhang, Beibin Li, Chi Wang, Huazheng Wang, Yiran Chen, and Qingyun Wu. Which agent causes task failures and when? On automated failure attribution of LLM multi-agent systems. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Le...
2025
-
[31]
Gemma 4 model card
Google DeepMind. Gemma 4 model card. https://ai.google.dev/gemma/docs/core/model_ card_4, 2026. Last updated April 17, 2026
2026
-
[32]
Qwen3.5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
Qwen Team. Qwen3.5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
Pith/arXiv arXiv 2026
-
[33]
Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 11
Pith/arXiv arXiv 2025
-
[34]
Olmo 3.arXiv preprint arXiv:2512.13961, 2025
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, et al. Olmo 3.arXiv preprint arXiv:2512.13961, 2025
Pith/arXiv arXiv 2025
-
[35]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[36]
Carnegie Mellon University, 2010
Brian D Ziebart.Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010
2010
-
[37]
A general theoretical paradigm to understand learning from human preferences
Mohammad Gheshlaghi Azar, Zhaohan Daniel Guo, Bilal Piot, Remi Munos, Mark Rowland, Michal Valko, and Daniele Calandriello. A general theoretical paradigm to understand learning from human preferences. InInternational Conference on Artificial Intelligence and Statistics, pages 4447–4455. PMLR, 2024
2024
-
[38]
Model alignment as prospect theoretic optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Model alignment as prospect theoretic optimization. InProceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[39]
ORPO: Monolithic preference optimization without reference model
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11170–11189, 2024
2024
-
[40]
Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
Yu Meng, Mengzhou Xia, and Danqi Chen. Simpo: Simple preference optimization with a reference-free reward.Advances in Neural Information Processing Systems, 37:124198–124235, 2024
2024
-
[41]
MIT press Cambridge, 2 edition, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press Cambridge, 2 edition, 2018
2018
-
[42]
Understanding r1-zero-like training: A critical perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective. InSecond Conference on Language Modeling, 2025
2025
-
[43]
RLHF workflow: From reward modeling to online RLHF.Transactions on Machine Learning Research, 2024
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, and Tong Zhang. RLHF workflow: From reward modeling to online RLHF.Transactions on Machine Learning Research, 2024
2024
-
[44]
On a few pitfalls in kl divergence gradient estimation for rl.arXiv preprint arXiv:2506.09477, 2025
Yunhao Tang and Rémi Munos. On a few pitfalls in kl divergence gradient estimation for rl.arXiv preprint arXiv:2506.09477, 2025
arXiv 2025
-
[45]
Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879, 2026
Penghui Qi, Xiangxin Zhou, Zichen Liu, Tianyu Pang, Chao Du, Min Lin, and Wee Sun Lee. Rethinking the trust region in llm reinforcement learning.arXiv preprint arXiv:2602.04879, 2026
Pith/arXiv arXiv 2026
-
[46]
Hao Peng, Yunjia Qi, Xiaozhi Wang, Zijun Yao, Lei Hou, and Juanzi Li. Wildreward: Learning reward models from in-the-wild human interactions.arXiv preprint arXiv:2602.08829, 2026
arXiv 2026
-
[47]
Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, and Lu Wang. Process reward models that think.arXiv preprint arXiv:2504.16828, 2025
arXiv 2025
-
[48]
Scalable best-of-n selection for large language models via self-certainty
Zhewei Kang, Xuandong Zhao, and Dawn Song. Scalable best-of-n selection for large language models via self-certainty. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[49]
Deep think with confidence
Yichao Fu, Xuewei Wang, Hao Zhang, Yuandong Tian, and Jiawei Zhao. Deep think with confidence. In The Fourteenth International Conference on Learning Representations, 2026
2026
-
[50]
τ-bench: A benchmark for Tool-Agent-User interaction in real-world domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R Narasimhan. τ-bench: A benchmark for Tool-Agent-User interaction in real-world domains. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[51]
Changdae Oh, Seongheon Park, To Eun Kim, Jiatong Li, Wendi Li, Samuel Yeh, Xuefeng Du, Hamed Hassani, Paul Bogdan, Dawn Song, and Sharon Li. Uncertainty quantification in llm agents: Foundations, emerging challenges, and opportunities.arXiv preprint arXiv:2602.05073, 2026
Pith/arXiv arXiv 2026
-
[52]
Introducing Claude Sonnet 4.6
Anthropic. Introducing Claude Sonnet 4.6. https://www.anthropic.com/news/ claude-sonnet-4-6, February 2026
2026
-
[53]
Agentracer: Who is inducing failure in the LLM agentic systems? InThe Fourteenth International Conference on Learning Representations, 2026
Guibin Zhang, Junhao Wang, Junjie Chen, Wangchunshu Zhou, Kun Wang, and Shuicheng YAN. Agentracer: Who is inducing failure in the LLM agentic systems? InThe Fourteenth International Conference on Learning Representations, 2026. 12
2026
-
[54]
Contrastive decoding: Open-ended text generation as optimization
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 12286–12312, 2023
2023
-
[55]
Enhancing uncertainty-based hallucination detection with stronger focus
Tianhang Zhang, Lin Qiu, Qipeng Guo, Cheng Deng, Yue Zhang, Zheng Zhang, Chenghu Zhou, Xinbing Wang, and Luoyi Fu. Enhancing uncertainty-based hallucination detection with stronger focus. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 915–932, 2023
2023
-
[56]
Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5050–5063, 2024
2024
-
[57]
Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in LLM reasoning
Chen Qian, Dongrui Liu, Haochen Wen, Zhen Bai, Yong Liu, and Jing Shao. Demystifying reasoning dynamics with mutual information: Thinking tokens are information peaks in LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[58]
Oops, wait: Token-level signals as a lens into llm reasoning.arXiv preprint arXiv:2601.17421, 2026
Jaehui Hwang, Dongyoon Han, Sangdoo Yun, and Byeongho Heo. Oops, wait: Token-level signals as a lens into llm reasoning.arXiv preprint arXiv:2601.17421, 2026
arXiv 2026
-
[59]
Robust fine-tuning of zero-shot models
Mitchell Wortsman, Gabriel Ilharco, Jong Wook Kim, Mike Li, Simon Kornblith, Rebecca Roelofs, Raphael Gontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, and Ludwig Schmidt. Robust fine-tuning of zero-shot models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7959–7971, June 2022
2022
-
[60]
Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
Prateek Yadav, Derek Tam, Leshem Choshen, Colin A Raffel, and Mohit Bansal. Ties-merging: Resolving interference when merging models.Advances in neural information processing systems, 36:7093–7115, 2023
2023
-
[61]
Task arithmetic in the tangent space: Improved editing of pre-trained models.Advances in Neural Information Processing Systems, 36:66727–66754, 2023
Guillermo Ortiz-Jimenez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models.Advances in Neural Information Processing Systems, 36:66727–66754, 2023
2023
-
[62]
Adamerging: Adaptive model merging for multi-task learning
Enneng Yang, Zhenyi Wang, Li Shen, Shiwei Liu, Guibing Guo, Xingwei Wang, and Dacheng Tao. Adamerging: Adaptive model merging for multi-task learning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[63]
Language models are super mario: Absorbing abilities from homologous models as a free lunch
Le Yu, Bowen Yu, Haiyang Yu, Fei Huang, and Yongbin Li. Language models are super mario: Absorbing abilities from homologous models as a free lunch. InForty-first International Conference on Machine Learning, 2024
2024
-
[64]
Model stock: All we need is just a few fine-tuned models
Dong-Hwan Jang, Sangdoo Yun, and Dongyoon Han. Model stock: All we need is just a few fine-tuned models. InEuropean Conference on Computer Vision, pages 207–223. Springer, 2024
2024
-
[65]
Dawin: Training-free dynamic weight interpolation for robust adaptation
Changdae Oh, Yixuan Li, Kyungwoo Song, Sangdoo Yun, and Dongyoon Han. Dawin: Training-free dynamic weight interpolation for robust adaptation. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[66]
Linking process to outcome: Condi- tional reward modeling for LLM reasoning
Zheng Zhang, Ziwei Shan, Kaitao Song, Yexin Li, and Kan Ren. Linking process to outcome: Condi- tional reward modeling for LLM reasoning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[67]
Nakyung Lee, Sangwoo Hong, and Jungwoo Lee. Efficient process reward modeling via contrastive mutual information.arXiv preprint arXiv:2604.10660, 2026
Pith/arXiv arXiv 2026
-
[68]
Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards.arXiv preprint arXiv:2502.01456, 2025
Pith/arXiv arXiv 2025
-
[69]
The lessons of developing process reward models in mathematical reasoning
Zhenru Zhang, Chujie Zheng, Yangzhen Wu, Beichen Zhang, Runji Lin, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. The lessons of developing process reward models in mathematical reasoning. InFindings of the Association for Computational Linguistics: ACL 2025, pages 10495–10516, 2025. 13
2025
-
[70]
VersaPRM: Multi-domain process reward model via synthetic reasoning data
Thomas Zeng, Shuibai Zhang, Shutong Wu, Christian Classen, Daewon Chae, Ethan Ewer, Minjae Lee, Heeju Kim, Wonjun Kang, Jackson Kunde, Ying Fan, Jungtaek Kim, Hyung Il Koo, Kannan Ramchandran, Dimitris Papailiopoulos, and Kangwook Lee. VersaPRM: Multi-domain process reward model via synthetic reasoning data. InForty-second International Conference on Mach...
2025
-
[71]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024
Pith/arXiv arXiv 2024
-
[72]
Introducing Marin: An open lab for building foundation models
David Hall, Ahmed Ahmed, Christopher Chou, Abhinav Garg, Rohith Kuditipudi, Will Held, Nikil Ravi, Herumb Shandilya, Jason Wang, Jason Bolton, Siddharth Karamcheti, Suhas Kotha, Tony Lee, Nelson Liu, Joel Niklaus, Ashwin Ramaswami, Kamyar Salahi, Kaiyue Wen, Chi Heem Wong, Sherry Yang, Ivan Zhou, and Percy Liang. Introducing Marin: An open lab for buildin...
2025
-
[73]
Aaron Blakeman, Aaron Grattafiori, Aarti Basant, Abhibha Gupta, Abhinav Khattar, Adi Renduchintala, Aditya Vavre, Akanksha Shukla, Akhiad Bercovich, Aleksander Ficek, et al. Nemotron 3 nano: Open, efficient mixture-of-experts hybrid mamba-transformer model for agentic reasoning.arXiv preprint arXiv:2512.20848, 2025
arXiv 2025
-
[74]
Vedant Shah, Johan Obando-Ceron, Vineet Jain, Brian Bartoldson, Bhavya Kailkhura, Sarthak Mittal, Glen Berseth, Pablo Samuel Castro, Yoshua Bengio, Nikolay Malkin, et al. A comedy of estimators: On kl regularization in rl training of llms.arXiv preprint arXiv:2512.21852, 2025
arXiv 2025
-
[75]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[76]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, 2023
2023
-
[77]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with gpt-4.arXiv preprint arXiv:2303.12712, 2023
Pith/arXiv arXiv 2023
-
[78]
G-eval: NLG evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: NLG evaluation using gpt-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 2511–2522, 2023
2023
-
[79]
Length-controlled alpacaeval: A simple debiasing of automatic evaluators
Yann Dubois, Percy Liang, and Tatsunori Hashimoto. Length-controlled alpacaeval: A simple debiasing of automatic evaluators. InFirst Conference on Language Modeling, 2024
2024
-
[80]
RLAIF vs
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. RLAIF vs. RLHF: Scaling reinforcement learning from human feedback with AI feedback. InForty-first International Conference on Machine Learning, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.