RedEdit: Agentic Red-Teaming of Image Safety Classifiers via MCTS-Guided Photo-Editing
Pith reviewed 2026-06-28 00:40 UTC · model grok-4.3
The pith
Fewer than two photo edits on average allow 76.2 percent of unsafe images to evade safety classifiers while retaining 93 percent of their malicious semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
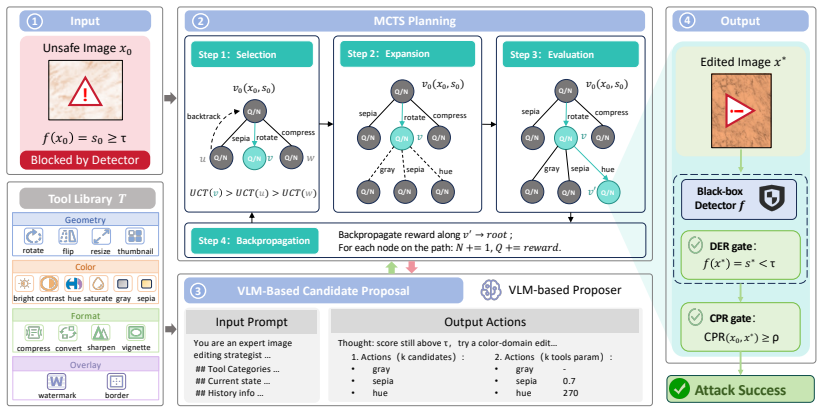
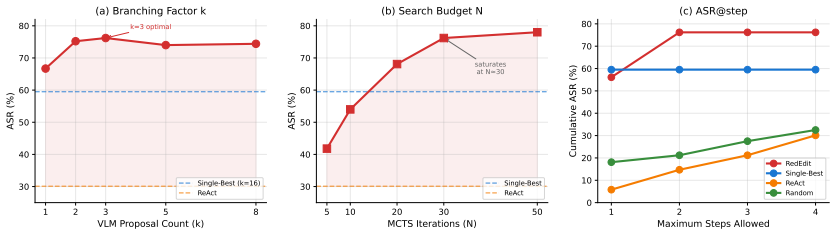
RedEdit formulates evasion of image safety classifiers as a search over sequences of photo-editing operations. A vision-language model proposes semantically targeted edits while a Monte Carlo tree search planner explores and backtracks among those proposals. On UnsafeBench this procedure succeeds in evading detectors for 76.2 percent of unsafe images using fewer than two edits on average and preserves 93.0 percent of the original malicious semantics as judged by humans.
What carries the argument
The RedEdit agent, which treats photo-editing evasion as combinatorial search over edit-tool sequences and combines a vision-language-model proposer with a Monte Carlo tree search planner.
If this is right
- Image safety classifiers exhibit systemic weaknesses against iterative, semantically targeted photo editing.
- Manipulated images that remain perceptually malicious to humans can still bypass automated moderation.
- The practical threat arises from everyday editing behaviors rather than exotic adversarial perturbations.
- Red-teaming that combines semantic proposal with backtracking search exposes vulnerabilities not captured by static benchmarks.
Where Pith is reading between the lines
- Moderation pipelines may need to evaluate images after plausible short edit sequences rather than in their original form.
- The same search structure could be applied to test robustness of classifiers for other media such as video or audio.
- Defenses that detect the presence of editing operations themselves might close part of the gap shown here.
Load-bearing premise
The vision-language model will consistently propose edits that preserve malicious semantics and the search procedure will reliably identify sequences that evade detectors without excessive trial and error.
What would settle it
A test set of unsafe images in which no sequence of one or two ordinary photo edits evades the classifiers on more than a small fraction of cases while still retaining at least 90 percent of the original semantics.
Figures



read the original abstract
Image safety classifiers serve as a critical component of contemporary content moderation systems on the internet. However, their resilience against user-style malicious image editing remains underexplored. Such behaviors are highly prevalent in daily scenarios but difficult to fully reproduce. To explore this vulnerability, we introduce RedEdit, a novel black-box red-teaming agent that formulates photo-editing evasion as a combinatorial search problem over edit-tool sequences. It adopts a Vision-Language-Model (VLM)-based proposer to generate semantically targeted candidate edits and a Monte Carlo Tree Search (MCTS) planner to prioritize promising edit paths while backtracking from ineffective ones. Together, the proposer and planner instantiate two key capabilities of human attackers, i.e., domain knowledge and iterative backtracking, respectively, to reproduce this practical threat. Our extensive experiments on UnsafeBench reveal profound systemic vulnerabilities: fewer than two edits on average enable 76.2% of unsafe images to evade detectors, while retaining 93.0% malicious semantics, meaning that such manipulated content remains perceptually malicious to humans while easily bypassing automated moderation. We therefore appeal to the community for more attention to this overlooked practical threat.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RedEdit, a black-box red-teaming agent that frames photo-editing evasion of image safety classifiers as a combinatorial search problem. It uses a VLM-based proposer to generate semantically targeted edits and an MCTS planner to prioritize and backtrack over edit sequences, instantiating human-like domain knowledge and iterative refinement. Experiments on UnsafeBench report that fewer than two edits on average enable 76.2% of unsafe images to evade detectors while retaining 93.0% malicious semantics, interpreted as evidence that the edited images remain perceptually malicious to humans.
Significance. If the quantitative results and the interpretation of the 93% semantics-retention metric are substantiated, the work would demonstrate a practical, low-effort attack vector against deployed image safety classifiers and motivate stronger defenses that account for iterative editing. The MCTS-guided search formulation provides a reproducible algorithmic template for future red-teaming studies.
major comments (2)
- [Abstract] Abstract: The central claim that edited images 'remain perceptually malicious to humans' rests on the 93.0% malicious-semantics retention figure, yet no human-subject validation, inter-rater agreement study, or correlation analysis between the automated metric and human perception is described. This directly affects whether the reported evasion rates constitute the claimed real-world moderation bypass.
- [Abstract / Experimental results] Methods / Experimental Setup (inferred from abstract description): The 76.2% evasion rate and <2-edit average are presented without accompanying details on the exact UnsafeBench subset used, the specific safety classifiers tested, the definition of 'evasion,' edit-quality metrics, or controls for post-hoc selection of successful paths. These omissions make it impossible to assess whether the headline numbers are robust or sensitive to implementation choices.
minor comments (1)
- The abstract states quantitative results but the manuscript should include a dedicated reproducibility section or appendix listing all classifier versions, VLM prompts, MCTS hyperparameters, and success criteria.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments identify important gaps in the interpretation of our metrics and the clarity of experimental reporting. We address each point below and outline planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that edited images 'remain perceptually malicious to humans' rests on the 93.0% malicious-semantics retention figure, yet no human-subject validation, inter-rater agreement study, or correlation analysis between the automated metric and human perception is described. This directly affects whether the reported evasion rates constitute the claimed real-world moderation bypass.
Authors: We agree that the 93.0% malicious-semantics retention is an automated metric obtained via VLM-based similarity scoring and that no human-subject validation or correlation analysis was performed. The abstract phrasing extrapolates this metric to human perceptual maliciousness. We will revise the abstract to report the automated metric factually, remove the direct claim of human perception, and add a limitations paragraph discussing the gap between automated semantics retention and human judgment. revision: partial
-
Referee: [Abstract / Experimental results] Methods / Experimental Setup (inferred from abstract description): The 76.2% evasion rate and <2-edit average are presented without accompanying details on the exact UnsafeBench subset used, the specific safety classifiers tested, the definition of 'evasion,' edit-quality metrics, or controls for post-hoc selection of successful paths. These omissions make it impossible to assess whether the headline numbers are robust or sensitive to implementation choices.
Authors: The full manuscript specifies the UnsafeBench subset (unsafe-labeled images across categories), the classifiers (those evaluated in UnsafeBench), the evasion definition (classifier output below the safety threshold), the edit-quality metric (semantics retention score), and the MCTS procedure (which evaluates all explored paths without post-hoc selection). To improve clarity, we will insert a concise summary of these elements into the abstract and expand the experimental setup section with explicit lists and controls for reproducibility. revision: yes
Circularity Check
No circularity: empirical red-teaming study with independent experimental outcomes
full rationale
The paper describes an empirical black-box red-teaming agent (RedEdit) using VLM proposer and MCTS planner, evaluated on UnsafeBench. Reported figures (76.2% evasion with <2 edits, 93.0% semantics retention) are direct experimental measurements, not quantities defined by or fitted from the method itself. No equations, self-definitional relations, fitted-input predictions, or load-bearing self-citation chains appear in the abstract or described structure. The work is self-contained as an empirical demonstration; success rates do not reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1706.06083 , year=
Towards deep learning models resistant to adversarial attacks , author=. arXiv preprint arXiv:1706.06083 , year=
-
[2]
Advances in Neural Information Processing Systems , volume=
On evaluating adversarial robustness of large vision-language models , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
arXiv preprint arXiv:1903.12261 , year=
Benchmarking neural network robustness to common corruptions and perturbations , author=. arXiv preprint arXiv:1903.12261 , year=
Pith/arXiv arXiv 1903
-
[4]
arXiv preprint arXiv:2603.22882 , year=
TreeTeaming: Autonomous Red-Teaming of Vision-Language Models via Hierarchical Strategy Exploration , author=. arXiv preprint arXiv:2603.22882 , year=
-
[5]
Forty-second International Conference on Machine Learning , year=
TRUST-VLM: Thorough Red-Teaming for Uncovering Safety Threats in Vision-Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[6]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Distraction is all you need for multimodal large language model jailbreaking , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[7]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
Unsafebench: Benchmarking image safety classifiers on real-world and ai-generated images , author=. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages=
2025
-
[8]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Ideator: Jailbreaking and benchmarking large vision-language models using themselves , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[9]
2024 IEEE symposium on security and privacy (SP) , pages=
Sneakyprompt: Jailbreaking text-to-image generative models , author=. 2024 IEEE symposium on security and privacy (SP) , pages=. 2024 , organization=
2024
-
[10]
Advances in Neural Information Processing Systems , volume=
Tree of attacks: Jailbreaking black-box llms automatically , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
arXiv preprint arXiv:2602.01539 , year=
MAGIC: A Co-Evolving Attacker-Defender Adversarial Game for Robust LLM Safety , author=. arXiv preprint arXiv:2602.01539 , year=
-
[12]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Reasoning with language model is planning with world model , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[13]
arXiv preprint arXiv:2310.04406 , year=
Language agent tree search unifies reasoning acting and planning in language models , author=. arXiv preprint arXiv:2310.04406 , year=
-
[14]
arXiv preprint arXiv:2601.18386 , year=
ARMOR: Agentic Reasoning for Methods Orchestration and Reparameterization for Robust Adversarial Attacks , author=. arXiv preprint arXiv:2601.18386 , year=
-
[15]
arXiv preprint arXiv:2210.03629 , year=
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
-
[16]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Jailbreaking black box large language models in twenty queries , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[17]
European Conference on Computer Vision , pages=
Mm-safetybench: A benchmark for safety evaluation of multimodal large language models , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[18]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Auditing image-based nsfw classifiers for content filtering , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[19]
Advances in neural information processing systems , volume=
Guardt2i: Defending text-to-image models from adversarial prompts , author=. Advances in neural information processing systems , volume=
-
[20]
arXiv preprint arXiv:2509.25896 , year=
LLaVAShield: Safeguarding Multimodal Multi-Turn Dialogues in Vision-Language Models , author=. arXiv preprint arXiv:2509.25896 , year=
-
[21]
Advances in neural information processing systems , volume=
Large language models as commonsense knowledge for large-scale task planning , author=. Advances in neural information processing systems , volume=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mma-diffusion: Multimodal attack on diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
IEEE transactions on image processing , volume=
Image quality assessment: from error visibility to structural similarity , author=. IEEE transactions on image processing , volume=. 2004 , publisher=
2004
-
[24]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
The unreasonable effectiveness of deep features as a perceptual metric , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[25]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Autoredteamer: Autonomous red teaming with lifelong attack integration , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Proceedings of the AAAI conference on artificial intelligence , volume=
Visual adversarial examples jailbreak aligned large language models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[28]
Advances in Neural Information Processing Systems , volume=
Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Red teaming visual language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[30]
Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
Can machines help us answering question 16 in datasheets, and in turn reflecting on inappropriate content? , author=. Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
2022
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
URL https://github
Nudenet: Neural nets for nudity detection and censoring, 2022 , author=. URL https://github. com/notAI-tech/NudeNet , volume=
2022
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Llavaguard: Vlm-based safeguard for vision dataset curation and safety assessment , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[34]
Introducing GPT-5.5 , howpublished =
-
[35]
Introducing Claude Opus 4.7 , howpublished =
-
[36]
Gemini 3.1 Pro Model Card , howpublished =
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
T2isafety: Benchmark for assessing fairness, toxicity, and privacy in image generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[38]
arXiv preprint arXiv:2210.04610 , year=
Red-teaming the stable diffusion safety filter , author=. arXiv preprint arXiv:2210.04610 , year=
-
[39]
Advances in neural information processing systems , volume=
Art: Automatic red-teaming for text-to-image models to protect benign users , author=. Advances in neural information processing systems , volume=
-
[40]
5: Visual Agentic Intelligence , author=
Kimi K2. 5: Visual Agentic Intelligence , author=. arXiv preprint arXiv:2602.02276 , year=
-
[41]
International Conference on Learning Representations , volume=
Ring-a-bell! how reliable are concept removal methods for diffusion models? , author=. International Conference on Learning Representations , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
Red-teaming text-to-image systems by rule-based preference modeling , author=. Advances in Neural Information Processing Systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.