ScreenSearch: Uncertainty-Aware OS Exploration
Pith reviewed 2026-05-20 18:12 UTC · model grok-4.3
The pith
Ambiguity reduction alone does not suffice as an exploration objective for desktop GUI agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
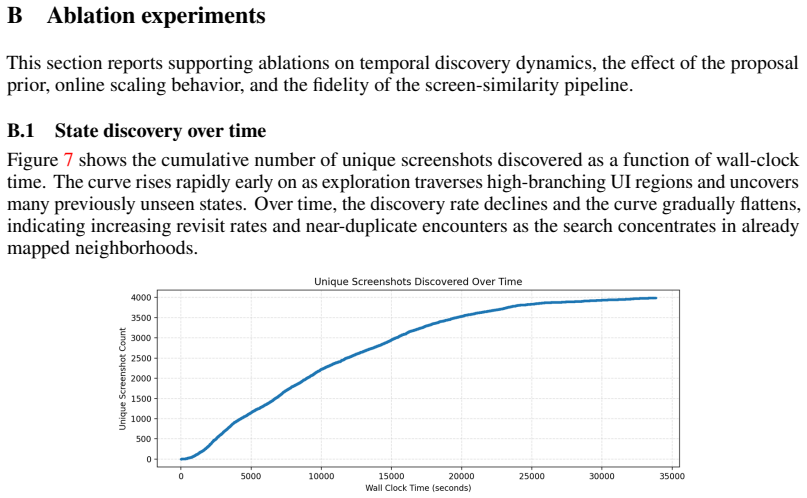
ScreenSearch combines structural screen retrieval and deduplication with an ambiguity-aware PUCT graph-bandit. The central ambiguity signal is matched-action outcome dispersion on the deduplicated state graph: when similar screens produce different next states under the same action signature, the state is treated as unresolved and scheduled for further probing. Across eleven desktop applications the system collects over one million screenshots and over thirty thousand deduplicated states. On a fixed replay-start slice, policies that reduce ambiguity quickly discover little frontier, showing that ambiguity reduction by itself is not a sufficient exploration objective.
What carries the argument
An ambiguity signal defined as matched-action outcome dispersion on a deduplicated state graph, used inside a PUCT graph-bandit to balance probing and committing.
Load-bearing premise
The ambiguity signal based on matched-action outcome dispersion accurately reflects true workflow uncertainty rather than noise from retrieval or execution.
What would settle it
Re-run the same exploration with a different screen-retrieval or deduplication method and check whether the novelty-ambiguity trade-off disappears and whether ambiguity-only policies then discover substantial new frontier states.
Figures







read the original abstract
Desktop GUI agents operate under partial observability: visually similar screens can correspond to different underlying workflow states, so locally plausible actions can lead to sharply different outcomes. We frame this as a problem of computer/OS state exploration, where effective behavior requires both expanding the reachable frontier and reducing ambiguity before committing. We present ScreenSearch, a system that combines structural screen retrieval and deduplication with an ambiguity-aware PUCT graph-bandit for large-scale desktop exploration. The retrieval layer converts UIA trees into location-aware structural features, indexes related screens through sparse token search and metadata filters, and maintains a shared deduplicated state graph across VM workers. On top of this graph, we define a scalable ambiguity signal based on matched-action outcome dispersion. If similar screens produce different next states under the same action signature, the state should be probed further rather than treated as resolved. We use this signal together with frontier rewards to drive large-scale exploration and replay-start policy evaluation over the shared graph. Across 11 desktop applications, ScreenSearch collects over 1M screenshots and over 30K deduplicated states, yielding large exploration corpora with substantial cross-application and within-application diversity. On a fixed replay-start slice, we observe a clear novelty--ambiguity trade-off: some policies reduce ambiguity quickly while discovering little frontier. Ambiguity reduction alone is therefore not a sufficient exploration objective. Appendix ablations show that stronger proposal priors can materially improve unique-state discovery during corpus building. These results suggest that state identity, proposal quality, and ambiguity-aware search all matter when deciding when to probe and when to commit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScreenSearch, a system for large-scale desktop OS exploration under partial observability. It combines UIA-tree structural retrieval and deduplication with an ambiguity signal (matched-action outcome dispersion on a shared state graph) and an ambiguity-aware PUCT graph-bandit. The work reports collecting >1M screenshots and >30K deduplicated states across 11 applications, and empirically observes a novelty-ambiguity trade-off across policies on replay-start slices, concluding that ambiguity reduction alone is not a sufficient exploration objective and that state identity, proposal quality, and ambiguity-aware search must be jointly considered.
Significance. If the central empirical observations hold, the manuscript contributes a large-scale, deduplicated exploration corpus and concrete evidence that single-objective strategies are inadequate for GUI agents. The scale of data collection and the shared-graph architecture are clear strengths that could support follow-on work; the explicit trade-off demonstration is a useful falsifiable claim for the community.
major comments (2)
- [Abstract (ambiguity signal paragraph) and §4 (method)] The ambiguity signal (described in the abstract as 'matched-action outcome dispersion on the deduplicated state graph') is load-bearing for the novelty-ambiguity trade-off claim. No explicit equation, pseudocode, or threshold definition is provided, nor is there validation that dispersion correlates with human-judged workflow differences rather than VM timing/async noise or retrieval artifacts. Without this, the trade-off could be an artifact of the measurement.
- [Results / replay-start evaluation] Results on the fixed replay-start slice report a 'clear novelty-ambiguity trade-off' but supply no quantitative baselines (e.g., random walk, standard PUCT without ambiguity term), error bars, or statistical tests. This makes it impossible to judge the magnitude or reliability of the observed differences that support the multi-objective conclusion.
minor comments (2)
- [Abstract] The abstract states 'over 1M screenshots and over 30K deduplicated states' but does not summarize per-application diversity metrics or deduplication false-positive rates.
- [Method] Notation for the PUCT exploration constant and ambiguity threshold is introduced without a consolidated table of all free parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the scale of the exploration corpus and the value of the observed trade-off. We address each major comment below and describe the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract (ambiguity signal paragraph) and §4 (method)] The ambiguity signal (described in the abstract as 'matched-action outcome dispersion on the deduplicated state graph') is load-bearing for the novelty-ambiguity trade-off claim. No explicit equation, pseudocode, or threshold definition is provided, nor is there validation that dispersion correlates with human-judged workflow differences rather than VM timing/async noise or retrieval artifacts. Without this, the trade-off could be an artifact of the measurement.
Authors: We agree that an explicit formulation is required for clarity and reproducibility. In the revised manuscript we will add a formal definition of the ambiguity signal in §4, including the equation for outcome dispersion (computed as the entropy of the distribution over deduplicated successor states reached by identical action signatures from structurally matched screens) together with pseudocode for its incremental update on the shared graph. We will also state any thresholds applied during policy selection. The current work does not contain a human validation study correlating dispersion scores with workflow differences; we will add an explicit limitations paragraph acknowledging that distinguishing genuine state ambiguity from retrieval or timing artifacts would benefit from such validation in follow-on work. We note that the UIA-tree structural features and metadata filters were chosen precisely to reduce sensitivity to VM timing noise, and the trade-off appears consistently across 11 applications, but we accept that stronger empirical grounding for the signal itself is desirable. revision: partial
-
Referee: [Results / replay-start evaluation] Results on the fixed replay-start slice report a 'clear novelty-ambiguity trade-off' but supply no quantitative baselines (e.g., random walk, standard PUCT without ambiguity term), error bars, or statistical tests. This makes it impossible to judge the magnitude or reliability of the observed differences that support the multi-objective conclusion.
Authors: We agree that the absence of explicit baselines and reliability measures weakens the interpretability of the reported trade-off. In the revision we will augment the replay-start evaluation with direct comparisons to random-walk and standard (ambiguity-agnostic) PUCT policies on the same fixed slices. We will report means and standard deviations across multiple independent runs to supply error bars and will include statistical significance tests (paired t-tests) either in the main results table or in the appendix. These additions will allow readers to assess both the magnitude and reliability of the novelty-ambiguity differences. revision: yes
Circularity Check
No circularity: empirical corpus statistics and policy comparisons
full rationale
The paper defines an ambiguity signal directly from observed matched-action outcome dispersion on the deduplicated state graph and reports large-scale empirical results (1M+ screenshots, 30K states) plus observed novelty-ambiguity trade-offs across policies. No equations, derivations, or self-citations are invoked that reduce a claimed prediction or uniqueness result to a fitted parameter or prior ansatz defined in terms of the target outcome. The central claim that multiple objectives matter rests on direct data comparisons rather than any self-referential construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- PUCT exploration constant and ambiguity threshold
axioms (2)
- domain assumption UIA trees yield location-aware structural features sufficient to distinguish workflow states across applications
- domain assumption Outcome dispersion under matched actions is a reliable proxy for state ambiguity
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define a scalable ambiguity signal based on matched-action outcome dispersion... u(s) := ρ(s)D(s) + (1−ρ(s))u0
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ambiguity reduction alone is not a sufficient exploration objective
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[2]
URLhttps://arxiv.org/abs/2204.01691. R. Bajcsy, Y. Aloimonos, and J. K. Tsotsos. Revisiting active perception.Autonomous Robots, 42 (2):177–196,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
URLhttps://doi.org/10.1007/ s10514-017-9615-3
doi: 10.1007/s10514-017-9615-3. URLhttps://doi.org/10.1007/ s10514-017-9615-3. Y. Burda, H. Edwards, A. J. Storkey, and O. Klimov. Exploration by random network distillation. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9,
-
[4]
URLhttps://dblp.org/rec/conf/ aaai/Chrisman92. X. Deng, Y. Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y. Su. Mind2web: Towards a generalist agent for the web. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing ...
work page 2023
-
[6]
URLhttps://arxiv.org/abs/2402.03610. E. Z. Liu, K. Guu, P. Pasupat, T. Shi, and P. Liang. Reinforcement learning on web interfaces using workflow-guided exploration. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net,
-
[7]
URLhttps://openreview.net/forum?id=ryTp3f-0-. D. Pathak, P. Agrawal, A. A. Efros, and T. Darrell. Curiosity-driven exploration by self-supervised prediction. In D. Precup and Y. W. Teh, editors,Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, volume 70 of Proceedings of Machine Lear...
work page 2017
-
[8]
R. Sekar, O. Rybkin, K. Daniilidis, P. Abbeel, D. Hafner, and D. Pathak. Planning to explore via self-supervised world models. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, pages 8583–8592. PMLR,
work page 2020
-
[9]
URLhttp://proceedings.mlr. press/v119/sekar20a.html. N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao. Reflexion: language agents with verbal reinforcement learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems 36: Annual Conference on NeuralInformationProcess...
work page 2023
-
[10]
URLhttps://dl.acm.org/doi/10.1145/3583068
doi: 10.1145/3583068. URLhttps://dl.acm.org/doi/10.1145/3583068. T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y. Liu, Y. Xu, S. Zhou, S. Savarese, C. Xiong, V. Zhong, and T. Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. In A. Glober- sons, L. Mackey, D. Belgrave,...
-
[11]
URL http://papers.nips.cc/paper_files/paper/ 2024/hash/5d413e48f84dc61244b6be550f1cd8f5-Abstract-Datasets_ and_Benchmarks_Track.html. S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rw...
work page 2024
-
[12]
URL https://openreview.net/pdf?id=WE_vluYUL-X. A. Zhou, K. Yan, M. Shlapentokh-Rothman, H. Wang, and Y. Wang. Language agent tree search unifies reasoning, acting, and planning in language models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
work page 2024
-
[13]
URLhttps://openreview.net/forum?id=njwv9BsGHF
OpenReview.net, 2024a. URLhttps://openreview.net/forum?id=njwv9BsGHF. S.Zhou,F.F.Xu,H.Zhu,X.Zhou,R.Lo,A.Sridhar,X.Cheng,T.Ou,Y.Bisk,D.Fried,U.Alon,and G.Neubig. Webarena: Arealisticwebenvironmentforbuildingautonomousagents. InTheTwelfth InternationalConferenceonLearningRepresentations,ICLR2024,Vienna,Austria,May7-11,2024. OpenReview.net, 2024b. URLhttps:/...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.