What Survives When You Compress a Recursive Reasoner for the Edge?
Pith reviewed 2026-06-26 05:34 UTC · model grok-4.3
The pith
Aggressive compression preserves local prediction but destroys global reasoning in recursive reasoners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
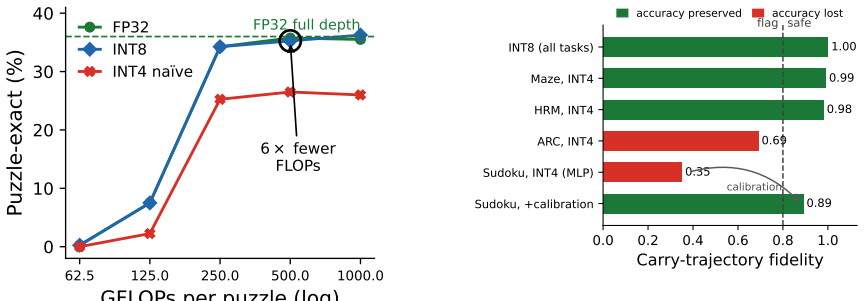
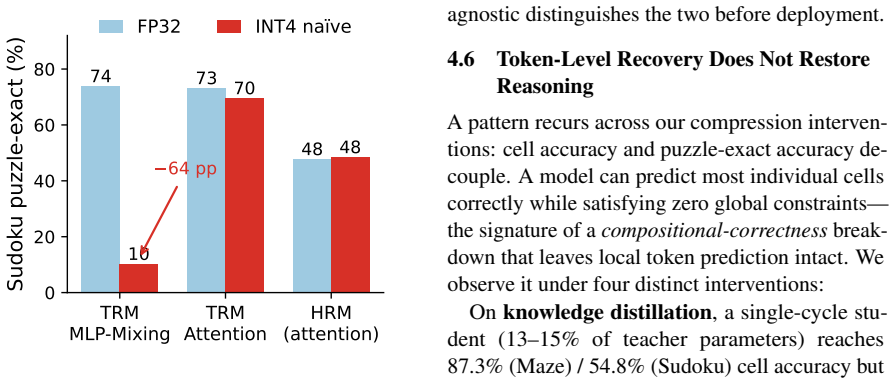
Across a full precision sweep, three tasks, and two recursive architectures, aggressive compression preserves local prediction but destroys global reasoning: cell accuracy holds while puzzle-exact accuracy collapses to zero under naive INT4 pruning, distillation, and linear attention alike. The collapse is architectural—it strikes MLP-mixing recursion but not attention on the same task—and is reversed with per-channel calibrated INT4 without retraining. Carry-trajectory fidelity predicts this damage and its recovery before a task evaluation.
What carries the argument
Per-channel calibrated INT4 quantization, which reverses the architectural collapse of global reasoning accuracy without retraining.
If this is right
- Token-level objectives including quantization-aware training cannot repair the global reasoning collapse.
- The collapse is specific to MLP-mixing recursion and does not appear in attention-based mixing on the same task.
- Carry-trajectory fidelity acts as a label-free predictor of both damage and recovery.
- Flash-streamed embeddings remove a 99.4 MB bottleneck and calibrated INT4 enables deployment on a 4 MB microcontroller.
Where Pith is reading between the lines
- The local-global accuracy split may appear in other iterative state-update models beyond the two architectures tested.
- Carry-trajectory fidelity could be used to monitor reasoning fidelity during other forms of compression or pruning.
- The deployment recipe suggests recursive reasoners become viable on microcontrollers once the calibration step is included.
Load-bearing premise
The three tasks and two recursive architectures used in the experiments are representative of the behavior of recursive reasoners under compression in general.
What would settle it
A new recursive reasoning task or architecture where naive INT4 pruning or distillation leaves puzzle-exact accuracy above zero, or where per-channel calibrated INT4 fails to restore it.
Figures

read the original abstract
Recursive reasoning models can solve complex structured tasks with only a few million parameters by repeatedly updating a latent state. Deploying these models on edge hardware requires significant compression, but unlike conventional sequence models, quantization errors compound across recursive reasoning cycles rather than across output tokens. As a result, standard intuitions about compression fail to apply. In this work, we ask what survives when recursive reasoners are compressed. Across a full precision sweep, three tasks, and two recursive architectures, we find that aggressive compression preserves local prediction but destroys global reasoning: cell accuracy holds while puzzle-exact accuracy collapses to zero under naive INT4 pruning, distillation, and linear attention alike. Token-level objectives, including quantization-aware training, cannot repair it. The collapse is architectural -- it strikes MLP-mixing recursion but not attention on the same task -- and we reverse it with per-channel calibrated INT4 without retraining. We also introduce carry-trajectory fidelity, the cosine similarity to the full-precision reasoning path, as a label-free signal that predicts this damage and its recovery before a task evaluation. The combined result is a deployment recipe: flash-streamed embeddings remove a 99.4MB bottleneck, INT8 at one cycle matches full-depth accuracy at 6x fewer FLOPs (8MB SoC), and calibrated INT4 fits a 4MB microcontroller.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines compression of recursive reasoning models for edge deployment, where quantization errors compound over reasoning cycles. Across a precision sweep, three tasks, and two architectures (MLP-mixing recursion and attention), it reports that aggressive methods (naive INT4, pruning, distillation, linear attention) preserve local cell accuracy but collapse global puzzle-exact accuracy to zero. The failure is architecture-dependent, reversed by per-channel calibrated INT4 without retraining. A new label-free metric, carry-trajectory fidelity (cosine similarity to full-precision path), is introduced to predict damage and recovery. Practical recipes include flash-streamed embeddings, INT8 at reduced depth, and calibrated INT4 for microcontrollers.
Significance. If the empirical results hold, the work identifies a distinctive failure mode for recursive reasoners under compression that differs from token-wise error accumulation in standard sequence models. The carry-trajectory fidelity metric provides a practical, label-free diagnostic, and the deployment recipes (e.g., 6x FLOP reduction with INT8, 4MB INT4 fit) are directly actionable for edge hardware. Credit is due for the controlled comparison across architectures and tasks plus the introduction of the fidelity metric as a predictive signal.
minor comments (2)
- [Abstract] Abstract: the reported sizes (99.4MB bottleneck, 8MB SoC, 4MB microcontroller) would benefit from explicit reference to the base model parameter count or embedding dimension to allow readers to reproduce the memory calculations.
- [Experimental setup] The manuscript should clarify in the experimental setup whether the three tasks share the same recursive depth schedule or whether depth is task-dependent, as this affects interpretation of the cycle-wise error compounding claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were enumerated in the report.
Circularity Check
No significant circularity
full rationale
The paper reports empirical results from quantization sweeps, accuracy measurements, and architectural comparisons on three tasks and two recursive models. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or described content. All claims rest on direct experimental observations (cell vs. puzzle-exact accuracy, carry-trajectory fidelity) that do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantization errors compound across recursive reasoning cycles rather than across output tokens.
invented entities (1)
-
carry-trajectory fidelity
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:2506.21734 , year =
Hierarchical Reasoning Model , author =. arXiv preprint arXiv:2506.21734 , year =
-
[9]
International Conference on Learning Representations , year =
Universal Transformers , author =. International Conference on Learning Representations , year =
-
[10]
Second Conference on Language Modeling , year =
Training Large Language Models to Reason in a Continuous Latent Space , author =. Second Conference on Language Modeling , year =
-
[11]
Advances in Neural Information Processing Systems , year =
End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking , author =. Advances in Neural Information Processing Systems , year =
-
[12]
AskariHemmat, MohammadHossein and Jeddi, Ahmadreza and Hemmat, Reyhane Askari and Lazarevich, Ivan and Hoffman, Alexander and Sah, Sudhakar and Saboori, Ehsan and Savaria, Yvon and David, Jean-Pierre , journal =
-
[13]
Javed, Saqib and Le, Hieu and Salzmann, Mathieu , booktitle =
-
[14]
2023 IEEE International Conference on Image Processing (ICIP) , pages=
Fighting Over-fitting with Quantization for Learning Deep Neural Networks on Noisy Labels , author=. 2023 IEEE International Conference on Image Processing (ICIP) , pages=. 2023 , organization=
2023
-
[15]
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , journal=
-
[16]
arXiv preprint arXiv:2106.08295 , year=
A White Paper on Neural Network Quantization , author=. arXiv preprint arXiv:2106.08295 , year=
-
[17]
arXiv preprint arXiv:2508.15008 , year=
Neural Network Quantization for Microcontrollers: A Comprehensive Survey of Methods, Platforms, and Applications , author=. arXiv preprint arXiv:2508.15008 , year=
-
[18]
ACM Computing Surveys , volume=
From Tiny Machine Learning to Tiny Deep Learning: A Survey , author =. ACM Computing Surveys , volume=. 2025 , publisher=
2025
-
[19]
Quantization Meets Reasoning: Exploring and Mitigating Degradation of Low-Bit
Li, Zhen and Su, Yupeng and Wang, Songmiao and Yang, Runming and Xie, Congkai and Liu, Aofan and Li, Ming and Cao, Jiannong and Xie, Yuan and Wong, Ngai and others , journal=. Quantization Meets Reasoning: Exploring and Mitigating Degradation of Low-Bit
-
[20]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Do Emergent Abilities Exist in Quantized Large Language Models: An Empirical Study , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[21]
International Conference on Learning Representations , year=
Latent Thinking Optimization: Your Latent Reasoning Language Model Secretly Encodes Reward Signals in Its Latent Thoughts , author =. International Conference on Learning Representations , year=
-
[22]
International Conference on Learning Representations , volume=
Tracing Representation Progression: Analyzing and Enhancing Layer-Wise Similarity , author=. International Conference on Learning Representations , volume=
-
[23]
2025 , journal =
Latent Chain-of-Thought? Decoding the Depth-Recurrent Transformer , author=. 2025 , journal =
2025
-
[24]
arXiv preprint arXiv:2510.04871 , year=
Less is More: Recursive Reasoning with Tiny Networks , author=. arXiv preprint arXiv:2510.04871 , year=
-
[25]
2019 , journal =
On the Measure of Intelligence , author =. 2019 , journal =
2019
-
[26]
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and
Han, Song and Mao, Huizi and Dally, William J , booktitle =. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and
-
[27]
Lin, Ji and Chen, Wei-Ming and Lin, Yujun and Gan, Chuang and Han, Song and others , journal=
-
[28]
2021 , organization=
Kim, Sehoon and Gholami, Amir and Yao, Zhewei and Mahoney, Michael W and Keutzer, Kurt , booktitle=. 2021 , organization=
2021
-
[29]
AskariHemmat, MohammadHossein and Hemmat, Reyhane Askari and Hoffman, Alex and Lazarevich, Ivan and Saboori, Ehsan and Mastropietro, Olivier and Sah, Sudhakar and Savaria, Yvon and David, Jean-Pierre , journal=
-
[30]
arXiv preprint arXiv:2512.18934 , year=
When Less is More: 8-bit Quantization Improves Continual Learning in Large Language Models , author=. arXiv preprint arXiv:2512.18934 , year=
-
[31]
Advances in Neural Information Processing Systems , volume=
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
On-device System of Compositional Multi-tasking in Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[33]
Proceedings of the Conference on Language Modeling , year =
Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models , author =. Proceedings of the Conference on Language Modeling , year =
-
[34]
Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
Revisiting Pruning vs Quantization for Small Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2025 , pages =
2025
-
[35]
arXiv preprint arXiv:2601.14888 , year=
What Makes Low-Bit Quantization-Aware Training Work for Reasoning LLMs? A Systematic Study , author=. arXiv preprint arXiv:2601.14888 , year=
-
[36]
arXiv preprint arXiv:2604.07822 , year =
Loop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers , author =. arXiv preprint arXiv:2604.07822 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.