Beta-trees for testing multivariate goodness-of-fit and localizing deviations from a model
Pith reviewed 2026-06-30 08:38 UTC · model grok-4.3
The pith
Beta-trees create adaptive partitions with finite-sample confidence intervals to test local fit of a model to data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
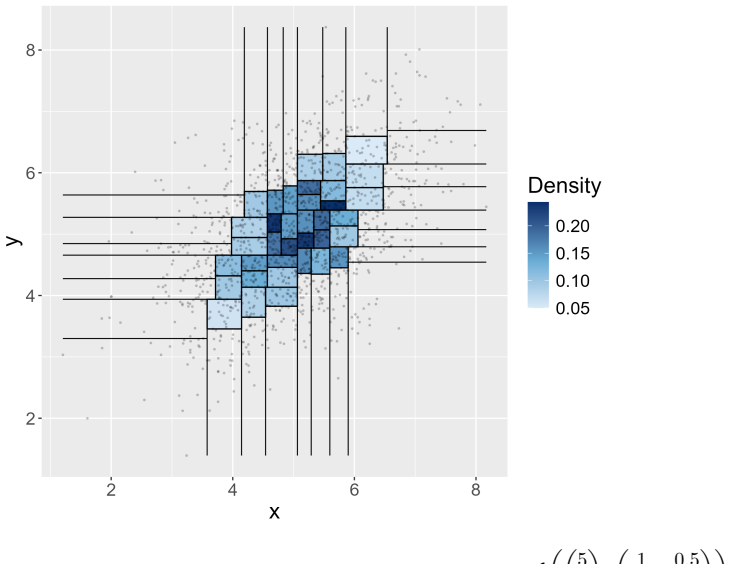
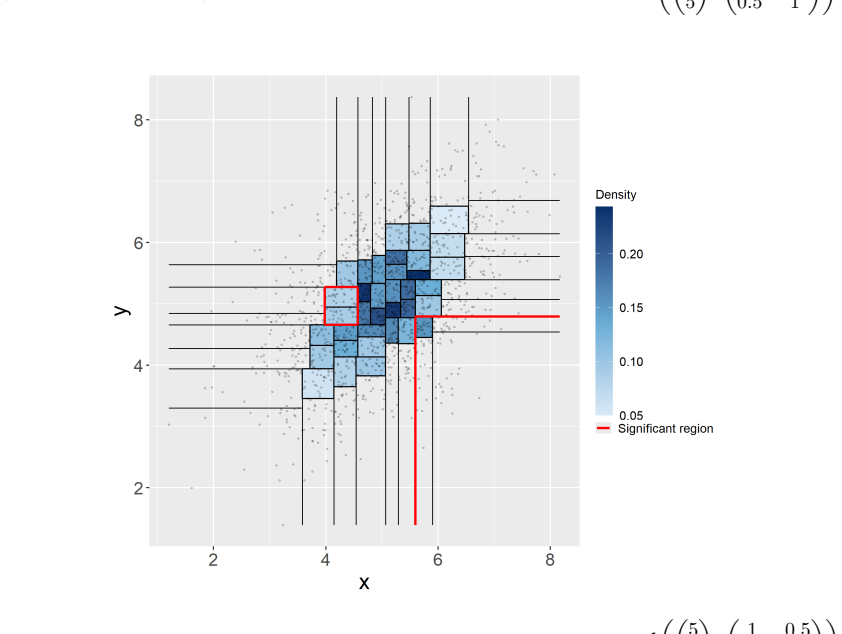
A Beta-tree produces a data-adaptive partition of the sample space into regions and provides guaranteed finite sample confidence intervals for the probability contents of each region. The proposed test assesses whether the probabilities assigned by a null distribution F0 fall within these intervals, thereby quantifying agreement between the model and the data.
What carries the argument
The Beta-tree, which generates a data-adaptive partition together with finite-sample confidence intervals for each region's probability content.
If this is right
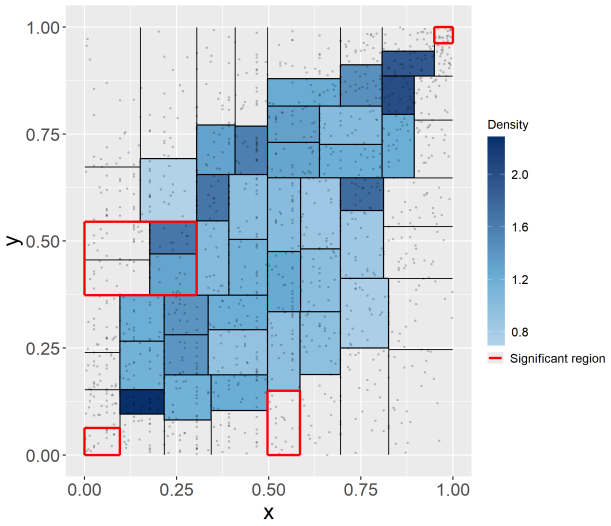
- The test identifies specific regions where the model and data disagree.
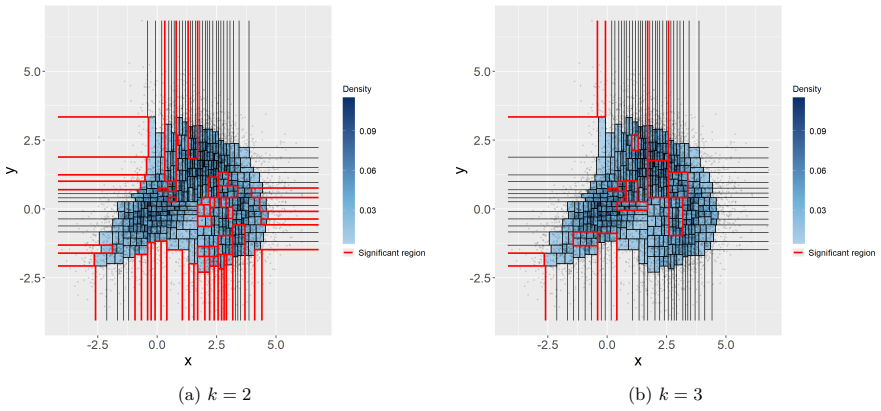
- It can be applied to select the number of mixture components by constructing the null via k-means.
- Unlike global tests like Kolmogorov-Smirnov, it localizes model misspecification.
- Simulation and real data examples show it detects departures from the null.
Where Pith is reading between the lines
- The method may generalize to other adaptive partitioning schemes beyond Beta-trees.
- Performance could be compared to other local goodness-of-fit procedures in high dimensions.
- Extensions might include continuous monitoring or sequential testing settings.
Load-bearing premise
The Beta-tree construction yields guaranteed finite-sample confidence intervals for the probability contents of the regions it produces.
What would settle it
A simulation study where data is generated from a distribution that locally deviates from F0, but the test fails to reject the null in the deviated regions despite the intervals being correctly calibrated.
Figures
read the original abstract
We introduce a novel goodness-of-fit (GOF) procedure based on Beta-tree partitions. A Beta-tree produces a data-adaptive partition of the sample space into regions and provides guaranteed finite sample confidence intervals for the probability contents of each region. The proposed test assesses whether the probabilities assigned by a null distribution $F_0$ fall within these intervals, thereby quantifying agreement between the model and the data. A key application is the selection of the number of components in a mixture model, where the null distribution is constructed via $k$-means clustering. In contrast to classical global GOF tests such as Kolmogorov-Smirnov or Anderson-Darling, which quantify the discrepancy through a single global statistic, our method is designed to detect local departures from the null and to identify regions of model misspecification. We demonstrate the efficiency of our test in detecting departures from the null on some simulated and real datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Beta-tree partitions that yield a data-adaptive partition of the sample space together with guaranteed finite-sample confidence intervals for the probability mass of each region. A goodness-of-fit test is then defined by checking whether the probabilities assigned by a fixed null distribution F0 lie inside these intervals. The abstract highlights an application to selecting the number of components in a finite mixture, where F0 is obtained by running k-means on the same sample; the method is positioned as a local alternative to global tests such as Kolmogorov-Smirnov or Anderson-Darling.
Significance. A procedure that supplies finite-sample, data-adaptive confidence intervals for region probabilities and uses them for local goodness-of-fit testing would be a useful addition to the multivariate GOF literature if the coverage and type-I guarantees survive the dependence induced by data-driven construction of both the partition and F0. The mixture-component-selection use case is practically relevant, but its validity hinges on the unresolved dependence issue.
major comments (1)
- [Abstract] Abstract (paragraph on the Beta-tree construction and the mixture application): the manuscript asserts that the Beta-tree supplies 'guaranteed finite sample confidence intervals' whose coverage can be used to control the type-I error of the GOF test. When F0 is constructed by k-means on the identical sample, however, both the regions and the null probabilities are random and dependent; the unconditional coverage argument no longer automatically delivers type-I control. A formal argument or simulation study establishing validity under this joint dependence is required for the central claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. The concern regarding the dependence induced by data-driven construction of both the partition and F0 in the mixture application is well-taken, and we address it below.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on the Beta-tree construction and the mixture application): the manuscript asserts that the Beta-tree supplies 'guaranteed finite sample confidence intervals' whose coverage can be used to control the type-I error of the GOF test. When F0 is constructed by k-means on the identical sample, however, both the regions and the null probabilities are random and dependent; the unconditional coverage argument no longer automatically delivers type-I control. A formal argument or simulation study establishing validity under this joint dependence is required for the central claim.
Authors: We agree that the finite-sample coverage guarantee for the Beta-tree intervals is established conditionally on a fixed partition and for a fixed F0. When both are constructed from the same data, this guarantee does not directly translate to unconditional type-I error control. The manuscript does not provide a formal proof for the dependent case in the mixture application. In the revision, we will include a dedicated simulation study that examines the empirical type-I error of the GOF test when F0 is obtained via k-means on the sample used to build the Beta-tree. This will clarify the practical validity of the procedure for the intended application. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The abstract and description present the Beta-tree as supplying finite-sample CI guarantees for data-adaptive region probabilities, with the GOF test checking whether an externally supplied null F0 (e.g., via k-means) falls inside those intervals. No equations, fitted parameters, or self-citations are shown that reduce the claimed coverage or test statistic to a tautology or input by construction. The central guarantee is stated as holding for the partition independently of the particular F0, so the derivation does not collapse into its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Beta-trees produce guaranteed finite sample confidence intervals for the probability contents of each region
invented entities (1)
-
Beta-tree
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A test of goodness of fit
Anderson, T. W. and D. A. Darling (1954). “A test of goodness of fit”. In:Journal of the American statistical association49.268, pp. 765–769
1954
-
[2]
Multidimensional Binary Search Trees Used for Associative Searching
Bentley, J. L. (1975). “Multidimensional Binary Search Trees Used for Associative Searching”. In: Communications of the ACM18.9, pp. 509–517
1975
-
[3]
Goodness-of-fit test statistics that dominate the Kolmogorov statistics
Berk, R. H. and D. H. Jones (1979). “Goodness-of-fit test statistics that dominate the Kolmogorov statistics”. In:Zeitschrift f¨ ur Wahrscheinlichkeitstheorie und verwandte Gebiete47.1, pp. 47–59
1979
-
[4]
The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial
Clopper, C. J. and E. S. Pearson (1934). “The Use of Confidence or Fiducial Limits Illustrated in the Case of the Binomial”. In:Biometrika26.4, pp. 404–413. Cram´ er, H. (1928). “On the composition of elementary errors: First paper: Mathematical deductions”. In:Scandinavian Actuarial Journal1928.1, pp. 13–74
1934
-
[5]
Higher criticism for detecting sparse heterogeneous mixtures
Donoho, D. and J. Jin (2004). “Higher criticism for detecting sparse heterogeneous mixtures”. In:The Annals of Statistics32.3, pp. 962–994
2004
-
[6]
Understanding Relationships Using Copulas
Frees, E. W. and E. A. Valdez (1998). “Understanding Relationships Using Copulas”. In:North Amer- ican Actuarial Journal2.1, pp. 1–25
1998
-
[7]
An Algorithm for Finding Best Matches in Logarithmic Expected Time
Friedman, J. H., J. L. Bentley, and R. A. Finkel (1977). “An Algorithm for Finding Best Matches in Logarithmic Expected Time”. In:ACM Transactions on Mathematical Software3.3, pp. 209–226
1977
-
[8]
Goodness-of-Fit Procedures for Copula Models Based on the Probability Integral Transformation
Genest, C., J.-F. Quessy, and B. R´ emillard (2006). “Goodness-of-Fit Procedures for Copula Models Based on the Probability Integral Transformation”. In:Scandinavian Journal of Statistics33.2, pp. 337–366
2006
-
[9]
Goodness-of-fit tests via phi-divergences
Jager, L. and J. A. Wellner (2007). “Goodness-of-fit tests via phi-divergences”. In:The Annals of Statistics35.5, pp. 2018–2053
2007
-
[10]
Computational Aspects of Optional P´ olya Tree
Jiang, H. et al. (2016). “Computational Aspects of Optional P´ olya Tree”. In:Journal of Computational and Graphical Statistics25.1, pp. 301–320.doi:10.1080/10618600.2014.1002927
-
[11]
Fitting Bivariate Loss Distributions with Copulas
Klugman, S. A. and R. Parsa (1999). “Fitting Bivariate Loss Distributions with Copulas”. In:Insur- ance: Mathematics and Economics24.1–2, pp. 139–148
1999
-
[12]
Sulla determinazione empirica di una legge di distribuzione
Kolmogorov, A. N. (1933). “Sulla determinazione empirica di una legge di distribuzione”. In:Giornale dell’Istituto Italiano degli Attuari4, pp. 83–91
1933
-
[13]
Ma, L. and W. H. Wong (2011). “Coupling Optional P´ olya Trees and the Two Sample Problem”. In: Journal of the American Statistical Association106.496, pp. 1553–1565.doi:10.1198/jasa.2011. tm10003
-
[14]
Table for estimating the goodness of fit of empirical distributions
Smirnov, N. (1948). “Table for estimating the goodness of fit of empirical distributions”. In:The Annals of Mathematical Statistics19.2, pp. 279–281
1948
-
[15]
The Cost of Using Exact Confidence Intervals for a Binomial Proportion
Thulin, M. (2014). “The Cost of Using Exact Confidence Intervals for a Binomial Proportion”. In: Electronic Journal of Statistics8.1, pp. 817–840.doi:10.1214/14-EJS909. 12 von Mises, R. (1928).Wahrscheinlichkeit, Statistik und Wahrheit. Wien: Julius Springer
-
[16]
Beta-trees: Multivariate histograms with confidence statements
Walther, G. and Q. Zhao (2023). “Beta-trees: Multivariate histograms with confidence statements”. In:arXiv preprint arXiv:2308.00950
-
[17]
Model Selection and Semiparametric Inference for Bivariate Failure-Time Data
Wang, W. and M. T. Wells (2000). “Model Selection and Semiparametric Inference for Bivariate Failure-Time Data”. In:Journal of the American Statistical Association95.449, pp. 62–72
2000
-
[18]
Optional P´ olya tree and Bayesian inference
Wong, W. H. and L. Ma (2010). “Optional P´ olya tree and Bayesian inference”. In:The Annals of Statistics38.3, pp. 1433–1459. 13
2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.