EvoIR-Agent: Self-Evolving Image Restoration Agentic System via Experience-Driven Learning
Pith reviewed 2026-05-22 07:45 UTC · model grok-4.3
The pith
A self-evolving hierarchical experience pool lets image restoration agents improve performance and efficiency while staying compatible with new tools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvoIR-Agent first systematically formulates the experience components of a training-free image restoration agent. Subsequently, a hierarchical experience pool is constructed, which enables coarse-to-fine guidance for diverse tools and removal orders. Furthermore, a self-evolving mechanism is introduced to update the pool from scratch using accumulated records, thereby greatly improving performance and efficiency.
What carries the argument
Hierarchical experience pool updated by a self-evolving mechanism that accumulates records to refine tool selection and removal-order decisions.
If this is right
- Achieves a significant lead in full-reference metrics over state-of-the-art methods.
- Yields a Pareto-optimal balance between performance and efficiency.
- Preserves compatibility with new tools and degradations without retraining.
- Reduces trial-and-error overhead that zero-shot planning otherwise incurs.
Where Pith is reading between the lines
- The same experience-pool structure could be tested in other MLLM agent domains that require sequential tool use.
- Continuous record accumulation might allow the system to handle gradually shifting real-world degradation distributions.
- The approach suggests a general pattern for making training-free agents improve over time without losing flexibility.
Load-bearing premise
The self-evolving mechanism can update the hierarchical experience pool from scratch using accumulated records to greatly improve performance and efficiency while preserving compatibility with new tools and degradations.
What would settle it
Run the agent on standard image-restoration benchmarks with held-out degradation types and measure whether full-reference metrics exceed current state-of-the-art agents while inference time stays low and new tools integrate without retraining.
Figures














read the original abstract
Multimodal Large Language Model (MLLM)-driven image restoration agent demonstrates effectiveness in degradation coupling scenarios by flexibly selecting tools and determining removal orders. However, their zero-shot planning often fails without experience, necessitating severe trial-and-error overhead to achieve satisfactory outcomes. Currently, two paradigms are employed to address this issue, yet a dilemma persists: Training-based methods embed intrinsic experience into parameters, achieving high inference efficiency but lacking compatibility with new tools or degradation. In contrast, training-free methods utilize explicit experience storage for compatibility but still incur trial-and-error overhead due to naive experience. To resolve the dilemma, we propose EvoIR-Agent, which first systematically formulates the experience components of a training-free image restoration agent. Subsequently, a hierarchical experience pool is constructed, which enables coarse-to-fine guidance for diverse tools and removal orders. Furthermore, a self-evolving mechanism is introduced to update the pool from scratch using accumulated records, thereby greatly improving performance and efficiency. Extensive experiments reveal that EvoIR-Agent achieves a significant lead in the full reference metrics and yields a remarkable Pareto-optimal balance between performance and efficiency compared to the state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EvoIR-Agent, an MLLM-based image restoration agent that formulates explicit experience components, builds a hierarchical experience pool for coarse-to-fine guidance on tool selection and removal orders, and introduces a self-evolving mechanism to update the pool from scratch using accumulated records. This is claimed to resolve the training-based vs. training-free dilemma by improving both performance and efficiency while preserving compatibility, with extensive experiments showing a significant lead in full-reference metrics and a Pareto-optimal performance-efficiency balance over SOTA methods.
Significance. If the self-evolving mechanism and hierarchical pool function as described, the work would provide a concrete path to accumulate and refine agent experience without parameter retraining, addressing a practical limitation in current MLLM-driven restoration agents. The explicit formulation of experience components and the reported Pareto balance are strengths that could influence follow-up agentic systems in low-level vision.
major comments (2)
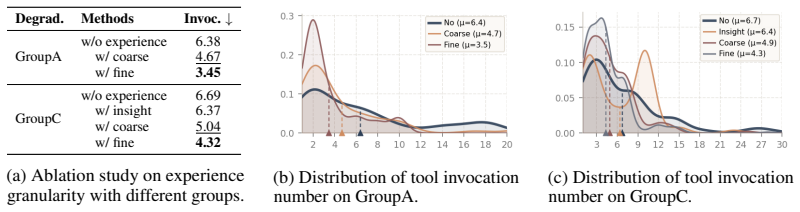
- [§3.3 (Self-evolving mechanism)] The central claim that the self-evolving mechanism 'updates the pool from scratch using accumulated records' and thereby avoids reintroducing trial-and-error overhead rests on the unexamined quality of the first records generated under zero-experience (naive) operation. This initialization step is load-bearing for the claimed resolution of the dilemma, yet the manuscript provides no ablation or iteration-wise analysis showing that early records are sufficiently informative to drive meaningful coarse-to-fine refinement.
- [§5.2 (Efficiency analysis)] Table 2 and the associated Pareto-front analysis: the reported efficiency gains are measured after the pool has evolved, but no corresponding measurements are given for the initial zero-experience phase or for the cumulative overhead incurred while the first records are collected. Without these data the efficiency claim cannot be fully evaluated against the training-free baseline.
minor comments (2)
- [§3.1] Notation for the hierarchical experience pool (e.g., the distinction between coarse and fine levels) is introduced in §3.1 but not consistently used in the algorithm pseudocode; a single consistent symbol set would improve readability.
- [Abstract] The abstract states 'significant lead in the full reference metrics' but does not specify which reference metrics (PSNR, SSIM, LPIPS, etc.) or the exact margins; adding these numbers to the abstract would help readers quickly gauge the improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address the major comments point-by-point below, agreeing to incorporate additional analyses to strengthen the presentation of the self-evolving mechanism and efficiency evaluation.
read point-by-point responses
-
Referee: [§3.3 (Self-evolving mechanism)] The central claim that the self-evolving mechanism 'updates the pool from scratch using accumulated records' and thereby avoids reintroducing trial-and-error overhead rests on the unexamined quality of the first records generated under zero-experience (naive) operation. This initialization step is load-bearing for the claimed resolution of the dilemma, yet the manuscript provides no ablation or iteration-wise analysis showing that early records are sufficiently informative to drive meaningful coarse-to-fine refinement.
Authors: We appreciate the referee's point regarding the importance of validating the initialization phase. The mechanism begins with zero-experience and accumulates records from successful restorations to evolve the pool. Although the manuscript emphasizes the final performance after evolution, we recognize that an iteration-wise analysis would better demonstrate how early records enable refinement. We will add this analysis, including performance curves over evolution steps and qualitative examples of record quality, in the revised manuscript. revision: yes
-
Referee: [§5.2 (Efficiency analysis)] Table 2 and the associated Pareto-front analysis: the reported efficiency gains are measured after the pool has evolved, but no corresponding measurements are given for the initial zero-experience phase or for the cumulative overhead incurred while the first records are collected. Without these data the efficiency claim cannot be fully evaluated against the training-free baseline.
Authors: We agree that the efficiency analysis should account for the initial phase to provide a complete picture. The reported results focus on the steady-state performance after the pool has evolved, as this is the intended use case. To fully address the concern, we will include additional experiments measuring the overhead during the initial record collection and the cumulative cost compared to training-free methods without evolution. This data will be added to the efficiency section in the revision. revision: yes
Circularity Check
No significant circularity; empirical system design is self-contained
full rationale
The paper describes an architectural proposal for EvoIR-Agent consisting of experience component formulation, a hierarchical experience pool for coarse-to-fine guidance, and a self-evolving update rule driven by accumulated operational records. No mathematical derivations, equations, or parameter-fitting steps are presented that reduce by construction to their own inputs. Performance and efficiency claims rest on experimental results rather than any self-referential definition or self-citation chain. The method is therefore an independent empirical contribution whose validity can be assessed externally via benchmarks, with no load-bearing circularity in the described chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Experience can be systematically formulated into components that enable coarse-to-fine guidance for tools and removal orders in image restoration agents.
invented entities (2)
-
Hierarchical experience pool
no independent evidence
-
Self-evolving mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising.IEEE transactions on image processing, 26(7): 3142–3155, 2017
work page 2017
-
[2]
Esrgan: Enhanced super-resolution generative adversarial networks
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy. Esrgan: Enhanced super-resolution generative adversarial networks. InProceedings of the European conference on computer vision (ECCV) workshops, pages 0–0, 2018
work page 2018
-
[3]
Scale-recurrent network for deep image deblurring
Xin Tao, Hongyun Gao, Xiaoyong Shen, Jue Wang, and Jiaya Jia. Scale-recurrent network for deep image deblurring. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8174–8182, 2018
work page 2018
-
[4]
Zhi Jin, Yuwei Qiu, Kaihao Zhang, Hongdong Li, and Wenhan Luo. Mb-taylorformer v2: Improved multi-branch linear transformer expanded by taylor formula for image restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[5]
Fourllie: Boosting low-light image enhancement by fourier frequency information
Chenxi Wang, Hongjun Wu, and Zhi Jin. Fourllie: Boosting low-light image enhancement by fourier frequency information. InProceedings of the 31st ACM international conference on multimedia, pages 7459–7469, 2023
work page 2023
-
[6]
Junjun Jiang, Zengyuan Zuo, Gang Wu, Kui Jiang, and Xianming Liu. A survey on all-in-one image restoration: Taxonomy, evaluation and future trends.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[7]
All in one bad weather removal using architectural search
Ruoteng Li, Robby T Tan, and Loong-Fah Cheong. All in one bad weather removal using architectural search. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3175–3185, 2020
work page 2020
-
[8]
Transweather: Transformer-based restoration of images degraded by adverse weather conditions
Jeya Maria Jose Valanarasu, Rajeev Yasarla, and Vishal M Patel. Transweather: Transformer-based restoration of images degraded by adverse weather conditions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2353–2363, 2022
work page 2022
-
[9]
Instructir: High-quality image restoration following human instructions
Marcos V Conde, Gregor Geigle, and Radu Timofte. Instructir: High-quality image restoration following human instructions. InEuropean Conference on Computer Vision, pages 1–21. Springer, 2024
work page 2024
-
[10]
Autodir: Automatic all-in-one image restoration with latent diffusion
Yitong Jiang, Zhaoyang Zhang, Tianfan Xue, and Jinwei Gu. Autodir: Automatic all-in-one image restoration with latent diffusion. InEuropean Conference on Computer Vision, pages 340–359. Springer, 2024
work page 2024
-
[11]
Jarvisir: Elevating autonomous driving perception with intelligent image restoration
Yunlong Lin, Zixu Lin, Haoyu Chen, Panwang Pan, Chenxin Li, Sixiang Chen, Kairun Wen, Yeying Jin, Wenbo Li, and Xinghao Ding. Jarvisir: Elevating autonomous driving perception with intelligent image restoration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22369–22380, 2025
work page 2025
-
[12]
Gradient as conditions: Rethinking hog for all-in-one image restoration
Jiawei Wu, Zhifei Yang, Zhe Wang, and Zhi Jin. Gradient as conditions: Rethinking hog for all-in-one image restoration. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 10682–10690, 2026
work page 2026
-
[13]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Jingyi Zhang, Jiaxing Huang, Sheng Jin, and Shijian Lu. Vision-language models for vision tasks: A survey.IEEE transactions on pattern analysis and machine intelligence, 46(8):5625–5644, 2024
work page 2024
-
[15]
Haoyu Chen, Wenbo Li, Jinjin Gu, Jingjing Ren, Sixiang Chen, Tian Ye, Renjing Pei, Kaiwen Zhou, Fenglong Song, and Lei Zhu. Restoreagent: Autonomous image restoration agent via multimodal large language models.Advances in Neural Information Processing Systems, 37:110643–110666, 2024
work page 2024
-
[16]
An intelligent agentic system for complex image restoration problems
Kaiwen Zhu, Jinjin Gu, Zhiyuan You, Yu Qiao, and Chao Dong. An intelligent agentic system for complex image restoration problems. InThe Thirteenth International Conference on Learning Representations. 10
-
[17]
Jianglin Lu, Yuanwei Wu, Ziyi Zhao, Hongcheng Wang, Felix Jimenez, Abrar Majeedi, and Yun Fu. Simplecall: A lightweight image restoration agent in label-free environments with mllm perceptual feedback.arXiv preprint arXiv:2512.18599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Tir-agent: Training an explorative and efficient agent for image restoration
Yisheng Zhang, Guoli Jia, Haote Hu, Shanxu Zhao, Kaikai Zhao, Long Sun, Xinwei Long, Kai Tian, Che Jiang, Zhaoxiang Liu, et al. Tir-agent: Training an explorative and efficient agent for image restoration. arXiv preprint arXiv:2603.27742, 2026
-
[19]
Multi-agent image restoration.arXiv preprint arXiv:2503.09403, 2025
Xu Jiang, Gehui Li, Bin Chen, and Jian Zhang. Multi-agent image restoration.arXiv preprint arXiv:2503.09403, 2025
-
[20]
4kagent: Agentic any image to 4k super-resolution
Yushen Zuo, Qi Zheng, Mingyang Wu, Xinrui Jiang, Renjie Li, Jian Wang, Yide Zhang, Gengchen Mai, Lihong Wang, James Zou, et al. 4kagent: Agentic any image to 4k super-resolution. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[21]
Expel: Llm agents are experiential learners
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Expel: Llm agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642, 2024
work page 2024
-
[22]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
LightMem: Lightweight and Efficient Memory-Augmented Generation
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, et al. Lightmem: Lightweight and efficient memory-augmented generation. arXiv preprint arXiv:2510.18866, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Llm2clip: Powerful language model unlocks richer cross-modality representation
Weiquan Huang, Aoqi Wu, Yifan Yang, Xufang Luo, Yuqing Yang, Usman Naseem, Chunyu Wang, Qi Dai, Xiyang Dai, Dongdong Chen, et al. Llm2clip: Powerful language model unlocks richer cross-modality representation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 5131–5139, 2026
work page 2026
-
[26]
G-memory: Tracing hierarchical memory for multi-agent systems
Guibin Zhang, Muxin Fu, Kun Wang, Guancheng Wan, Miao Yu, and Shuicheng YAN. G-memory: Tracing hierarchical memory for multi-agent systems. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[27]
Shuo Yu, Mingyue Cheng, Daoyu Wang, Qi Liu, Zirui Liu, Ze Guo, and Xiaoyu Tao. Memweaver: A hierarchical memory from textual interactive behaviors for personalized generation.arXiv preprint arXiv:2510.07713, 2025
-
[28]
Hadi Pouransari, David Grangier, C Thomas, Michael Kirchhof, and Oncel Tuzel. Pretraining with hierarchical memories: separating long-tail and common knowledge.arXiv preprint arXiv:2510.02375, 2025
-
[29]
Xiangtao Kong, Chao Dong, and Lei Zhang. Towards effective multiple-in-one image restoration: A sequential and prompt learning strategy.arXiv preprint arXiv:2401.03379, 2024
-
[30]
Vaishnav Potlapalli, Syed Waqas Zamir, Salman H Khan, and Fahad Shahbaz Khan. Promptir: Prompting for all-in-one image restoration.Advances in neural information processing systems, 36:71275–71293, 2023
work page 2023
-
[31]
Ziwei Luo, Fredrik K Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas B Schön. Controlling vision- language models for universal image restoration.arXiv preprint arXiv:2310.01018, 3(8), 2023
-
[32]
Unirestore: Unified perceptual and task-oriented image restoration model using diffusion prior
I Chen, Wei-Ting Chen, Yu-Wei Liu, Yuan-Chun Chiang, Sy-Yen Kuo, Ming-Hsuan Yang, et al. Unirestore: Unified perceptual and task-oriented image restoration model using diffusion prior. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17969–17979, 2025
work page 2025
-
[33]
Visual-instructed degradation diffusion for all-in-one image restoration
Wenyang Luo, Haina Qin, Zewen Chen, Libin Wang, Dandan Zheng, Yuming Li, Yufan Liu, Bing Li, and Weiming Hu. Visual-instructed degradation diffusion for all-in-one image restoration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12764–12777, 2025
work page 2025
-
[34]
Xiaole Tang, Xiaoyi He, Jiayi Xu, Xiang Gu, and Jian Sun. Learning continuous wasserstein barycenter space for generalized all-in-one image restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026. 11
work page 2026
-
[35]
Yingjie Zhou, Jiezhang Cao, Zicheng Zhang, Farong Wen, Yanwei Jiang, Jun Jia, Xiaohong Liu, Xiongkuo Min, and Guangtao Zhai. Q-agent: quality-driven chain-of-thought image restoration agent through robust multimodal large language model.arXiv preprint arXiv:2504.07148, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Yijian Wang, Qingsen Yan, Jiantao Zhou, Duwei Dai, and Wei Dong. Paagent: Portrait-aware image restoration agent via subjective-objective reinforcement learning.arXiv preprint arXiv:2603.17055, 2026
-
[37]
Hybrid agents for image restoration.arXiv preprint arXiv:2503.10120, 2025
Bingchen Li, Xin Li, Yiting Lu, and Zhibo Chen. Hybrid agents for image restoration.arXiv preprint arXiv:2503.10120, 2025
-
[38]
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji- Rong Wen. A survey on the memory mechanism of large language model-based agents.ACM Transactions on Information Systems, 43(6):1–47, 2025
work page 2025
-
[39]
Wei-Chieh Huang, Weizhi Zhang, Yueqing Liang, Yuanchen Bei, Yankai Chen, Tao Feng, Xinyu Pan, Zhen Tan, Yu Wang, Tianxin Wei, et al. Rethinking memory mechanisms of foundation agents in the second half.arXiv preprint arXiv:2602.06052, 2026
-
[40]
Zidi Xiong, Yuping Lin, Wenya Xie, Pengfei He, Zirui Liu, Jiliang Tang, Himabindu Lakkaraju, and Zhen Xiang. How memory management impacts llm agents: An empirical study of experience-following behavior.arXiv preprint arXiv:2505.16067, 2025
-
[41]
From experience to strategy: Empowering llm agents with trainable graph memory
Siyu Xia, Zekun Xu, Jiajun Chai, Wentian Fan, Yan Song, Xiaohan Wang, Guojun Yin, Wei Lin, Haifeng Zhang, and Jun Wang. From experience to strategy: Empowering llm agents with trainable graph memory. arXiv preprint arXiv:2511.07800, 2025
-
[42]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Qirui Mi, Zhijian Ma, Mengyue Yang, Haoxuan Li, Yisen Wang, Haifeng Zhang, and Jun Wang. Procmem: Learning reusable procedural memory from experience via non-parametric ppo for llm agents.arXiv preprint arXiv:2602.01869, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution.arXiv preprint arXiv:2512.10696, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Zhicheng Cai, Xinyuan Guo, Yu Pei, Jiangtao Feng, Jinsong Su, Jiangjie Chen, Ya-Qin Zhang, Wei-Ying Ma, Mingxuan Wang, and Hao Zhou. Flex: Continuous agent evolution via forward learning from experience.arXiv preprint arXiv:2511.06449, 2025
-
[45]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553, 2026
work page internal anchor Pith review arXiv 2026
-
[46]
Roger R Davidson. On extending the bradley-terry model to accommodate ties in paired comparison experiments.Journal of the American Statistical Association, 65(329):317–328, 1970
work page 1970
-
[47]
Abraham Wald. Tests of statistical hypotheses concerning several parameters when the number of observations is large.Transactions of the American Mathematical society, 54(3):426–482, 1943
work page 1943
-
[48]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. InThe Twelfth International Conference on Learning Representations
-
[49]
Should we be going mad? a look at multi-agent debate strategies for llms
Andries Petrus Smit, Nathan Grinsztajn, Paul Duckworth, Thomas D Barrett, and Arnu Pretorius. Should we be going mad? a look at multi-agent debate strategies for llms. InInternational Conference on Machine Learning, pages 45883–45905. PMLR, 2024
work page 2024
-
[50]
Bdi agents: from theory to practice
Anand S Rao, Michael P Georgeff, et al. Bdi agents: from theory to practice. InIcmas, volume 95, pages 312–319, 1995
work page 1995
-
[51]
The proof and measurement of association between two things. 1961
work page 1961
-
[52]
Foundir: Unleashing million-scale training data to advance foundation models for image restoration
Hao Li, Xiang Chen, Jiangxin Dong, Jinhui Tang, and Jinshan Pan. Foundir: Unleashing million-scale training data to advance foundation models for image restoration. InProceedings of the IEEE/CVF international conference on computer vision, pages 12626–12636, 2025
work page 2025
-
[53]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
work page 2004
-
[54]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 12
work page 2018
-
[55]
Maniqa: Multi-dimension attention network for no-reference image quality assessment
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. Maniqa: Multi-dimension attention network for no-reference image quality assessment. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1191–1200, 2022
work page 2022
-
[56]
Exploring clip for assessing the look and feel of images
Jianyi Wang, Kelvin CK Chan, and Chen Change Loy. Exploring clip for assessing the look and feel of images. InProceedings of the AAAI conference on artificial intelligence, volume 37, pages 2555–2563, 2023
work page 2023
-
[57]
Musiq: Multi-scale image quality transformer
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. Musiq: Multi-scale image quality transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 5148–5157, 2021
work page 2021
-
[58]
Depicting beyond scores: Advancing image quality assessment through multi-modal language models
Zhiyuan You, Zheyuan Li, Jinjin Gu, Zhenfei Yin, Tianfan Xue, and Chao Dong. Depicting beyond scores: Advancing image quality assessment through multi-modal language models. InEuropean Conference on Computer Vision, pages 259–276. Springer, 2024
work page 2024
-
[59]
Q-align: teaching lmms for visual scoring via discrete text-defined levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: teaching lmms for visual scoring via discrete text-defined levels. InProceedings of the 41st International Conference on Machine Learning, pages 54015–54029, 2024
work page 2024
-
[60]
Ali M Reza. Realization of the contrast limited adaptive histogram equalization (clahe) for real-time image enhancement.Journal of VLSI signal processing systems for signal, image and video technology, 38(1): 35–44, 2004
work page 2004
-
[61]
Learning to deblur using light field generated and real defocus images
Lingyan Ruan, Bin Chen, Jizhou Li, and Miuling Lam. Learning to deblur using light field generated and real defocus images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16304–16313, 2022
work page 2022
-
[62]
Iterative filter adaptive network for single image defocus deblurring
Junyong Lee, Hyeongseok Son, Jaesung Rim, Sunghyun Cho, and Seungyong Lee. Iterative filter adaptive network for single image defocus deblurring. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2034–2042, 2021
work page 2034
-
[63]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5728–5739, 2022
work page 2022
-
[64]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 1833–1844, 2021
work page 2021
-
[65]
Towards flexible blind jpeg artifacts removal
Jiaxi Jiang, Kai Zhang, and Radu Timofte. Towards flexible blind jpeg artifacts removal. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4997–5006, 2021
work page 2021
-
[66]
Maxim: Multi-axis mlp for image processing
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. Maxim: Multi-axis mlp for image processing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5769–5780, 2022
work page 2022
-
[67]
Multi-stage progressive image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming-Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14821–14831, 2021
work page 2021
-
[68]
A comparative study of image restoration networks for general backbone network design
Xiangyu Chen, Zheyuan Li, Yuandong Pu, Yihao Liu, Jiantao Zhou, Yu Qiao, and Chao Dong. A comparative study of image restoration networks for general backbone network design. InEuropean Conference on Computer Vision, pages 74–91. Springer, 2024
work page 2024
-
[69]
Ridcp: Revitalizing real image dehazing via high-quality codebook priors
Rui-Qi Wu, Zheng-Peng Duan, Chun-Le Guo, Zhi Chai, and Chongyi Li. Ridcp: Revitalizing real image dehazing via high-quality codebook priors. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22282–22291, 2023
work page 2023
-
[70]
Yuda Song, Zhuqing He, Hui Qian, and Xin Du. Vision transformers for single image dehazing.IEEE Transactions on Image Processing, 32:1927–1941, 2023
work page 1927
-
[71]
Diffbir: Toward blind image restoration with generative diffusion prior
Xinqi Lin, Jingwen He, Ziyan Chen, Zhaoyang Lyu, Bo Dai, Fanghua Yu, Yu Qiao, Wanli Ouyang, and Chao Dong. Diffbir: Toward blind image restoration with generative diffusion prior. InEuropean conference on computer vision, pages 430–448. Springer, 2024. 13
work page 2024
-
[72]
Xiangyu Chen, Xintao Wang, Wenlong Zhang, Xiangtao Kong, Yu Qiao, Jiantao Zhou, and Chao Dong. Hat: Hybrid attention transformer for image restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
work page 2025
-
[73]
Diff-plugin: Revitalizing details for diffusion-based low-level tasks
Yuhao Liu, Zhanghan Ke, Fang Liu, Nanxuan Zhao, and Rynson WH Lau. Diff-plugin: Revitalizing details for diffusion-based low-level tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4197–4208, 2024
work page 2024
-
[74]
Fourier priors-guided diffusion for zero-shot joint low-light enhancement and deblurring
Xiaoqian Lv, Shengping Zhang, Chenyang Wang, Yichen Zheng, Bineng Zhong, Chongyi Li, and Liqiang Nie. Fourier priors-guided diffusion for zero-shot joint low-light enhancement and deblurring. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25378–25388, 2024
work page 2024
-
[75]
Yuning Cui, Wenqi Ren, Xiaochun Cao, and Alois Knoll. Revitalizing convolutional network for image restoration.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):9423–9438, 2024
work page 2024
-
[76]
Omni-kernel network for image restoration
Yuning Cui, Wenqi Ren, and Alois Knoll. Omni-kernel network for image restoration. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 1426–1434, 2024
work page 2024
-
[77]
Simple baselines for image restoration
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restoration. In European conference on computer vision, pages 17–33. Springer, 2022
work page 2022
-
[78]
Efficient visual state space model for image deblurring
Lingshun Kong, Jiangxin Dong, Jinhui Tang, Ming-Hsuan Yang, and Jinshan Pan. Efficient visual state space model for image deblurring. InProceedings of the computer vision and pattern recognition conference, pages 12710–12719, 2025
work page 2025
-
[79]
Drct: Saving image super-resolution away from information bottleneck
Chih-Chung Hsu, Chia-Ming Lee, and Yi-Shiuan Chou. Drct: Saving image super-resolution away from information bottleneck. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6133–6142, 2024
work page 2024
-
[80]
Hmanet: Hybrid multi-axis aggregation network for image super-resolution
Shu-Chuan Chu, Zhi-Chao Dou, Jeng-Shyang Pan, Shaowei Weng, and Junbao Li. Hmanet: Hybrid multi-axis aggregation network for image super-resolution. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6257–6266, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.