S2ED: From Story to Executable Descriptions for Consistency-Aware Story Illustration
Pith reviewed 2026-05-22 04:52 UTC · model grok-4.3
The pith
S2ED turns full stories into sequences of executable descriptions that carry character identity and state across illustrated frames without retraining the generator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
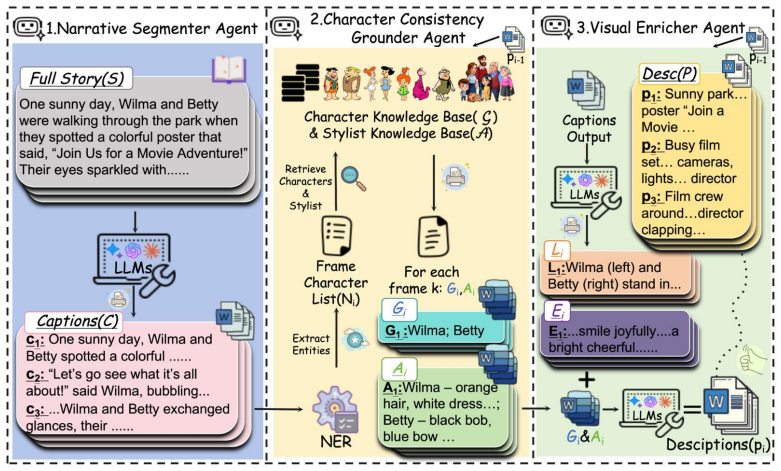
S2ED coordinates three agents to segment the narrative, ground canonical character attributes, and enrich spatial and affective cues, producing a sequence of explicit, editable executable descriptions that support prompt-carried state propagation and local drift repair for consistent multi-frame story illustration.
What carries the argument
Story-to-Executable Descriptions (S2ED), a prompt-layer framework with three agents that segment stories, ground character traits, and enrich cues to enable state propagation and local prompt edits across generated frames.
If this is right
- Sequence-level consistency and character fidelity improve over strong prompting, large-model planning, and training-based methods on Flintstones and Shakoo Maku under automatic metrics and human judgments.
- Prompt-carried state propagation combined with local edits allows repair of inconsistencies without retraining the underlying image generator.
- The resulting executable descriptions support deployment in end-to-end story-to-storybook pipelines for children's illustrated stories.
Where Pith is reading between the lines
- The modular agent approach could extend to video generation where temporal consistency across many frames is required.
- Local editability might lower the cost of adapting story illustration systems to new styles or domains without full retraining.
- Similar decomposition into executable state descriptions could apply to other multi-step creative tasks such as script-to-animation pipelines.
Load-bearing premise
The three agents accurately segment narratives, ground character attributes, and enrich cues so that prompt-carried state maintains persistent identity, layout, and affect without significant unrepairable drift.
What would settle it
Generate images from S2ED descriptions on a new story with complex interactions and measure whether character appearance or spatial layout drifts in ways that local prompt edits cannot restore to match the canonical attributes.
Figures




read the original abstract
Multi-frame story illustration requires long-horizon coherence beyond single-image text-to-image generation, including narrative decomposition and persistent character identity, layout, and affect across frames. We propose Story-to-Executable Descriptions (S2ED), a training-free, model-agnostic, prompt-layer framework that converts a full story into a sequence of explicit, editable executable descriptions for more consistent rendering. S2ED coordinates three agents to segment the narrative, ground canonical character attributes, and enrich spatial and affective cues, enabling interpretable prompt-carried state propagation and local edits to repair drift without retraining the generator. Experiments on Flintstones and Shakoo Maku show that S2ED improves sequence-level consistency and character fidelity over strong prompting, large-model planning, and a reference training-based method, under both automatic metrics and human judgments. We also deploy S2ED in an end-to-end story-to-storybook system for children's illustrated stories, with a supplementary video.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Story-to-Executable Descriptions (S2ED), a training-free and model-agnostic prompt-layer framework that decomposes a story into a sequence of explicit executable descriptions via three coordinated LLM agents: one for narrative segmentation, one for grounding canonical character attributes, and one for enriching spatial and affective cues. These descriptions enable prompt-carried state propagation with local edits to maintain consistency in character identity, layout, and affect across multiple frames. Experiments on the Flintstones and Shakoo Maku datasets report improvements in sequence-level consistency and character fidelity over strong prompting baselines, large-model planning approaches, and a reference training-based method, as measured by automatic metrics and human judgments; the framework is also deployed in an end-to-end story-to-storybook system.
Significance. If the empirical claims hold under rigorous verification, S2ED would offer a practical, interpretable alternative to retraining-based methods for long-horizon story illustration, emphasizing editable state propagation rather than end-to-end fine-tuning. The training-free and model-agnostic design could broaden applicability to various generators, and the explicit agent decomposition provides a clear mechanism for drift repair. However, the absence of agent-level quantitative metrics and ablations in the current presentation limits the ability to assess whether gains derive specifically from the proposed decomposition or from more structured prompting in general.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the headline claim of improvements 'under both automatic metrics and human judgments' is load-bearing for the central contribution, yet the manuscript supplies no definitions of the automatic metrics, no error bars or statistical significance tests, no exclusion criteria for test stories, and no details on how human judgments were collected or scored. This prevents verification that the reported gains are robust rather than artifacts of metric choice or evaluation protocol.
- [Method / §3] Method description (three-agent pipeline): the framework's success is predicated on the accuracy of the narrative segmentation, canonical attribute grounding, and cue enrichment agents in producing drift-resistant state. No quantitative agent-level metrics (e.g., segmentation F1, attribute grounding error rate, inter-agent consistency) or ablations isolating each agent's contribution are reported. Without these, it remains possible that observed gains stem primarily from longer, more structured prompts rather than the specific executable-description mechanism.
- [Experiments] §4 (or equivalent experimental results): the comparison to 'a reference training-based method' lacks details on the training data, model size, fine-tuning procedure, and whether the baseline was given equivalent access to the same story-level information. This makes it difficult to determine whether S2ED's advantages are due to its training-free nature or to differences in information access and prompt engineering.
minor comments (2)
- [Abstract / Conclusion] The supplementary video is referenced but not described in the main text; a brief summary of its content and how it illustrates the local-edit repair process would improve accessibility.
- [Method] Notation for the executable descriptions (e.g., how state is encoded and propagated between frames) should be formalized with a small example in the method section to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The points raised highlight important areas for improving the clarity and rigor of our experimental reporting. We address each major comment below and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the headline claim of improvements 'under both automatic metrics and human judgments' is load-bearing for the central contribution, yet the manuscript supplies no definitions of the automatic metrics, no error bars or statistical significance tests, no exclusion criteria for test stories, and no details on how human judgments were collected or scored. This prevents verification that the reported gains are robust rather than artifacts of metric choice or evaluation protocol.
Authors: We agree that the current presentation lacks sufficient detail on the evaluation protocol, which is necessary for independent verification. In the revised manuscript we will add explicit definitions and formulas for all automatic metrics, report standard deviations or error bars along with statistical significance tests (e.g., paired t-tests or Wilcoxon tests), state any exclusion criteria applied to the test stories, and provide a complete description of the human evaluation setup including participant count, scoring rubric, interface, and inter-rater agreement statistics. revision: yes
-
Referee: [Method / §3] Method description (three-agent pipeline): the framework's success is predicated on the accuracy of the narrative segmentation, canonical attribute grounding, and cue enrichment agents in producing drift-resistant state. No quantitative agent-level metrics (e.g., segmentation F1, attribute grounding error rate, inter-agent consistency) or ablations isolating each agent's contribution are reported. Without these, it remains possible that observed gains stem primarily from longer, more structured prompts rather than the specific executable-description mechanism.
Authors: The referee is correct that agent-level diagnostics would strengthen the causal link between the three-agent decomposition and the observed gains. We will add quantitative agent-level metrics obtained via manual annotation of a held-out subset (segmentation F1, attribute grounding precision/recall, and inter-agent consistency scores) together with ablation experiments that successively disable or simplify each agent while keeping prompt length comparable. These additions will appear in a new subsection of the experiments. revision: yes
-
Referee: [Experiments] §4 (or equivalent experimental results): the comparison to 'a reference training-based method' lacks details on the training data, model size, fine-tuning procedure, and whether the baseline was given equivalent access to the same story-level information. This makes it difficult to determine whether S2ED's advantages are due to its training-free nature or to differences in information access and prompt engineering.
Authors: We will expand the baseline description to include the exact training corpus, model architecture and parameter count, fine-tuning schedule and hyperparameters, and explicit confirmation that the training-based method received the full story text (identical to the input given to S2ED). This will allow readers to assess whether the performance difference is attributable to the training-free design or to unequal information access. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes a training-free framework S2ED that uses three external LLM agents to convert stories into executable descriptions for consistent illustration. Claims of improved sequence-level consistency and character fidelity rest on experimental comparisons against prompting baselines, large-model planning, and a training-based reference method on the Flintstones and Shakoo Maku datasets, using both automatic metrics and human judgments. No equations, fitted parameters, self-referential definitions, or load-bearing self-citations appear in the provided abstract or method outline. The derivation chain is self-contained because results are obtained via external evaluation rather than by construction from inputs defined inside the work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Storydiffusion: Consistent self-attention for long-range image and video generation,
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou, “Storydiffusion: Consistent self-attention for long-range image and video generation,” inNeurIPS, 2024
work page 2024
-
[2]
Storydiffusion: How to support ux storyboarding with generative ai,
Zhaohui Liang, Xiaoyu Zhang, Kevin Ma, Zhao Liu, Xipei Ren, Kosa Goucher-Lambert, and Can Liu, “Storydiffusion: How to support ux storyboarding with generative ai,” inICMI, 2025
work page 2025
-
[3]
Dreambooth: Fine-tuning text-to-image diffusion models for subject-driven generation,
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman, “Dreambooth: Fine-tuning text-to-image diffusion models for subject-driven generation,” inCVPR, 2023
work page 2023
-
[4]
Lora: Low-rank adaptation of large language models,
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen, “Lora: Low-rank adaptation of large language models,” inICLR, 2022
work page 2022
-
[5]
An image is worth one word: Personalizing text-to-image generation using textual inversion,
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or, “An image is worth one word: Personalizing text-to-image generation using textual inversion,” inICLR, 2023
work page 2023
-
[6]
Instructpix2pix: Learning to follow image editing instructions,
Tim Brooks, Aleksander Holynski, and Alexei A Efros, “Instructpix2pix: Learning to follow image editing instructions,” inCVPR, 2023
work page 2023
-
[7]
Dreamstory: Open-domain story visualization by llm-guided multi- subject consistent diffusion,
Huiguo He, Huan Yang, Zixi Tuo, Yuan Zhou, Qiuyue Wang, Yuhang Zhang, Zeyu Liu, Wenhao Huang, Hongyang Chao, and Jian Yin, “Dreamstory: Open-domain story visualization by llm-guided multi- subject consistent diffusion,”IEEE TPAMI, 2025
work page 2025
-
[8]
Flamingo: A visual language model for few-shot learning,
Jean-Baptiste Alayrac et al., “Flamingo: A visual language model for few-shot learning,” inNeurIPS, 2022
work page 2022
-
[9]
Characterfactory: Sampling consistent characters with gans for diffusion models,
Qinghe Wang, Baolu Li, Xiaomin Li, Bing Cao, Liqian Ma, Huchuan Lu, and Xu Jia, “Characterfactory: Sampling consistent characters with gans for diffusion models,”IEEE TIP, 2025
work page 2025
-
[10]
Infinite-story: A training-free consistent text-to-image generation,
Jihun Park, Kyoungmin Lee, Jongmin Gim, Hyeonseo Jo, Minseok Oh, Wonhyeok Choi, Kyumin Hwang, Jaeyeul Kim, Minwoo Choi, and Sunghoon Im, “Infinite-story: A training-free consistent text-to-image generation,”arXiv, 2025
work page 2025
-
[11]
One-prompt-one-story: Free-lunch consistent text-to-image generation using a single prompt,
Tao Liu, Kai Wang, Senmao Li, Joost van de Weijer, Fahad Shahbaz Khan, Shiqi Yang, Yaxing Wang, Jian Yang, and Ming-Ming Cheng, “One-prompt-one-story: Free-lunch consistent text-to-image generation using a single prompt,”arXiv, 2025
work page 2025
-
[12]
React: Synergizing reasoning and acting in language models,
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao, “React: Synergizing reasoning and acting in language models,” inICLR, 2023
work page 2023
-
[13]
Clipscore: A reference-free evaluation metric for image captioning,
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi, “Clipscore: A reference-free evaluation metric for image captioning,” inEMNLP, 2021
work page 2021
-
[14]
Make-a-story: Visual memory conditioned consistent story generation,
Tanzila Rahman, Hsin-Ying Lee, Jian Ren, Sergey Tulyakov, Shweta Mahajan, and Leonid Sigal, “Make-a-story: Visual memory conditioned consistent story generation,” inCVPR, 2023
work page 2023
-
[15]
Storydall-e: Adapting pretrained text-to-image transformers for story continuation,
Adyasha Maharana, Darryl Hannan, and Mohit Bansal, “Storydall-e: Adapting pretrained text-to-image transformers for story continuation,” inECCV, 2022
work page 2022
-
[16]
Microsoft coco: Common objects in context,
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Per- ona, Deva Ramanan, Piotr Doll ´ar, and C Lawrence Zitnick, “Microsoft coco: Common objects in context,” inECCV, 2014
work page 2014
-
[17]
Grounded language-image pretraining,
et al. Li, Liunian Harold, “Grounded language-image pretraining,” in CVPR, 2022
work page 2022
-
[18]
Gligen: Open-set grounded text-to-image generation,
Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jianwei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee, “Gligen: Open-set grounded text-to-image generation,” inCVPR, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.