Online LLM Selection via Constrained Bandits with Time-Varying Demand
Pith reviewed 2026-06-27 01:51 UTC · model grok-4.3
The pith
A constrained stochastic bandit algorithm selects LLMs online with sublinear regret and sublinear constraint violations despite unknown distributions and time-varying demand.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate the LLM selection problem as a constrained stochastic bandit learning task with packing-type and covering-type constraints under time-varying task demand. We develop a novel online learning algorithm that leverages confidence-bound estimates and demand predictions to balance reward maximization with long-term constraint satisfaction. We provide theoretical guarantees showing sublinear regret and sublinear covering constraint violations compared to an offline benchmark with full information.
What carries the argument
The online algorithm that uses confidence-bound estimates together with demand predictions to enforce long-term satisfaction of both packing and covering constraints while maximizing cumulative reward in a stochastic bandit with partial feedback.
If this is right
- The algorithm simultaneously respects hard resource budgets and soft service-level requirements over long sequences of tasks.
- Performance guarantees hold without knowledge of the underlying reward, cost, or latency distributions.
- Partial feedback from each selected model is sufficient for the confidence bounds to drive sublinear growth in violations.
- Demand predictions allow the method to adapt selection policies as task workloads shift over time.
Where Pith is reading between the lines
- The same structure could be tested on other sequential resource-allocation tasks that mix hard budgets with soft quality targets.
- Accurate short-term demand forecasting becomes a practical lever for tightening the achieved regret and violation bounds.
- The framework suggests examining whether similar confidence-bound techniques extend to settings with multiple simultaneous covering constraints.
Load-bearing premise
The approach depends on the availability of demand predictions to handle time-varying task demand.
What would settle it
An experiment that measures linear growth in either regret or covering violations when demand predictions are removed or when the algorithm is run on real heterogeneous LLM performance traces would falsify the sublinear guarantees.
Figures

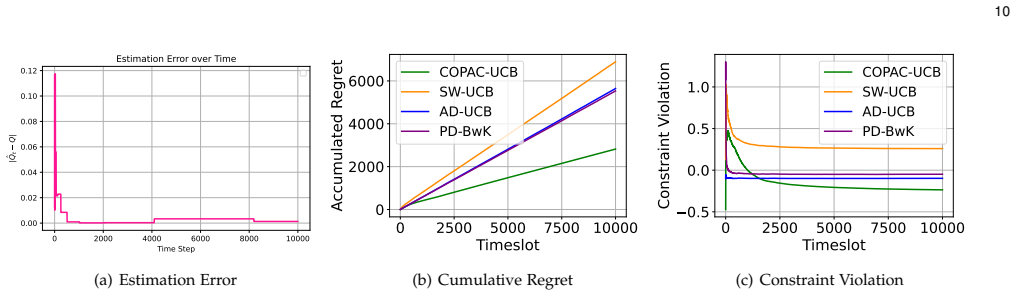
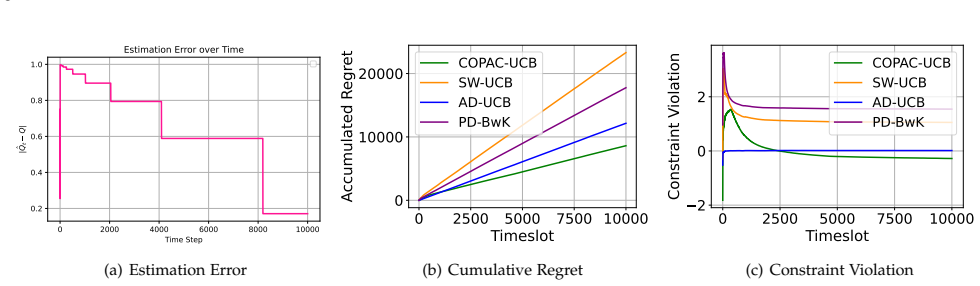
read the original abstract
Large Language Models (LLMs) are increasingly deployed in edge-cloud inference systems to handle diverse user tasks with heterogeneous accuracy, latency, and cost profiles. Selecting the appropriate LLM for each incoming task is critical for ensuring service quality and efficient resource utilization. However, model heterogeneity, stochastic and unknown performance characteristics, and time-varying task demands make static selection strategies inadequate. Real-world deployments often impose hard resource budgets such as monetary expenditure limits, along with soft service-level requirements such as latency guarantees. These constraints introduce additional challenges for online decision-making. We formulate this problem as a constrained stochastic bandit learning task, where the learner sequentially selects models under both packing-type (hard) and covering-type (soft) constraints, while adapting to time-varying task demand. The learner operates without access to the underlying reward, cost, or latency distributions and must rely on partial feedback. We develop a novel online learning algorithm that leverages confidence-bound estimates and demand predictions to balance reward maximization with long-term constraint satisfaction. We provide theoretical guarantees showing sublinear regret and sublinear covering constraint violations compared to an offline benchmark with full information. Experimental results on synthetic workloads demonstrate the effectiveness and robustness of our approach in dynamic, resource-constrained environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formulates LLM selection for edge-cloud inference as a constrained stochastic bandit problem with packing (hard resource budgets) and covering (soft latency) constraints under time-varying task demand. The learner has no access to reward/cost distributions and uses partial feedback. The proposed algorithm combines confidence-bound estimates with demand predictions to achieve sublinear regret and sublinear covering-constraint violations relative to an offline full-information benchmark; synthetic experiments are provided to illustrate performance.
Significance. If the analysis supplies a precise, quantitative assumption on demand-prediction error that justifies the comparison to the true-demand offline optimum, the result would supply a concrete algorithmic template for constrained online allocation in heterogeneous LLM systems, extending classical constrained bandits to time-varying demand with both hard and soft constraints.
major comments (2)
- [Abstract / §1] Abstract and §1: the claimed sublinear regret and covering-violation bounds are stated relative to an offline benchmark that knows the true demand process, yet no assumption quantifying the cumulative or per-step error of the supplied demand predictions appears. Without such a condition (e.g., cumulative prediction error o(T) or decaying as O(√T)), the stated comparison is not internally justified and the bounds hold only conditionally on unstated prediction quality.
- [§3 / §4] §3 (algorithm description) and §4 (analysis): the regret and violation proofs must explicitly incorporate the prediction-error term; if the analysis treats predictions as exact or absorbs their error without an explicit bound, the sublinear claims relative to the true-demand benchmark do not follow.
minor comments (2)
- [§2] Notation for the covering constraint (latency) and its violation measure should be introduced with an explicit mathematical definition before the algorithm statement.
- [§5] The experimental section would benefit from an ablation that varies the quality of the demand predictor to illustrate sensitivity to the (unstated) prediction-error assumption.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify that the current manuscript does not explicitly quantify the demand-prediction error when comparing to the true-demand offline benchmark. We will revise the paper to address both points.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and §1: the claimed sublinear regret and covering-violation bounds are stated relative to an offline benchmark that knows the true demand process, yet no assumption quantifying the cumulative or per-step error of the supplied demand predictions appears. Without such a condition (e.g., cumulative prediction error o(T) or decaying as O(√T)), the stated comparison is not internally justified and the bounds hold only conditionally on unstated prediction quality.
Authors: We agree that the manuscript as written does not state a quantitative assumption on prediction error, which is required to justify the comparison to the true-demand benchmark. In the revision we will add an explicit assumption (e.g., cumulative prediction error o(T)) in §1 and the abstract, and state that all bounds are conditional on this assumption. revision: yes
-
Referee: [§3 / §4] §3 (algorithm description) and §4 (analysis): the regret and violation proofs must explicitly incorporate the prediction-error term; if the analysis treats predictions as exact or absorbs their error without an explicit bound, the sublinear claims relative to the true-demand benchmark do not follow.
Authors: We will revise the analysis in §4 (and the algorithm description in §3 where relevant) to explicitly carry the prediction-error term through the regret and violation decompositions. The final bounds will be expressed in terms of both the usual bandit terms and the cumulative prediction error, thereby making the sublinear claims conditional on the assumption introduced above. revision: yes
Circularity Check
No significant circularity; claims rest on external offline benchmark and standard analysis
full rationale
The derivation compares an online algorithm (using confidence bounds and demand predictions) against an offline full-information benchmark. No quoted step reduces a claimed prediction or guarantee to a fitted parameter or self-citation by construction. The central regret and violation bounds are defined relative to an independent external benchmark rather than internally forced quantities. This is the normal case of a self-contained analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard stochastic bandit assumptions such as bounded rewards and sub-Gaussian noise for confidence bounds.
Reference graph
Works this paper leans on
-
[1]
Koya: A recommender system for large language model selection,
A. T. Owodunni and C. C. Emezue, “Koya: A recommender system for large language model selection,” in4th Workshop on African Natural Language Processing, 2023
2023
-
[2]
B. Peng, M. Galley, P . He, H. Cheng, Y. Xie, Y. Hu, Q. Huang, L. Liden, Z. Yu, W. Chenet al., “Check your facts and try again: Improving large language models with external knowledge and automated feedback,”arXiv preprint arXiv:2302.12813, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
L. Chen, M. Zaharia, and J. Zou, “Frugalgpt: How to use large lan- guage models while reducing cost and improving performance,” arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Ekya: Continuous learning of video analytics models on edge compute servers,
R. Bhardwaj, Z. Xia, G. Ananthanarayanan, J. Jiang, Y. Shu, N. Karianakis, K. Hsieh, P . Bahl, and I. Stoica, “Ekya: Continuous learning of video analytics models on edge compute servers,” in 19th USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI 22), 2022, pp. 119–135
2022
-
[5]
Which llm to play? convergence-aware online model selection with time- increasing bandits,
Y. Xia, F. Kong, T. Yu, L. Guo, R. A. Rossi, S. Kim, and S. Li, “Which llm to play? convergence-aware online model selection with time- increasing bandits,” inProceedings of the ACM Web Conference 2024, 2024, pp. 4059–4070. 11
2024
-
[6]
Combinatorial sleeping bandits with fairness constraints,
F. Li, J. Liu, and B. Ji, “Combinatorial sleeping bandits with fairness constraints,”IEEE Transactions on Network Science and Engineering, vol. 7, no. 3, pp. 1799–1813, 2019
2019
-
[7]
Contextual ban- dits with packing and covering constraints: A modular lagrangian approach via regression,
A. Slivkins, K. A. Sankararaman, and D. J. Foster, “Contextual ban- dits with packing and covering constraints: A modular lagrangian approach via regression,” inThe Thirty Sixth Annual Conference on Learning Theory. PMLR, 2023, pp. 4633–4656
2023
-
[8]
Invisible tokens, visible bills: The urgent need to audit hidden operations in opaque llm services,
G. Sun, Z. Wang, X. Zhao, B. Tian, Z. Shen, Y. He, J. Xing, and A. Li, “Invisible tokens, visible bills: The urgent need to audit hidden operations in opaque llm services,”arXiv preprint arXiv:2505.18471, 2025
-
[9]
E. J. Husom, A. Goknil, M. Astekin, L. K. Shar, A. K ˚asen, S. Sen, B. A. Mithassel, and A. Soylu, “Sustainable llm inference for edge ai: Evaluating quantized llms for energy efficiency, output accuracy, and inference latency,”arXiv preprint arXiv:2504.03360, 2025
-
[10]
Deterministic latency/jitter-aware service function chaining over beyond 5g edge fabric,
H. Yu, T. Taleb, and J. Zhang, “Deterministic latency/jitter-aware service function chaining over beyond 5g edge fabric,”IEEE Transactions on Network and Service Management, vol. 19, no. 3, pp. 2148–2162, 2022
2022
-
[11]
Online resource allocation under horizon uncertainty,
S. Balseiro, C. Kroer, and R. Kumar, “Online resource allocation under horizon uncertainty,” inAbstract Proceedings of the 2023 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Systems, 2023, pp. 63–64
2023
-
[12]
Masked language model scoring,
J. Salazar, D. Liang, T. Q. Nguyen, and K. Kirchhoff, “Masked language model scoring,”arXiv preprint arXiv:1910.14659, 2019
-
[13]
Thriftllm: On cost-effective selection of large language models for classification queries,
K. Huang, Y. Shi, D. Ding, Y. Li, Y. Fei, L. Lakshmanan, and X. Xiao, “Thriftllm: On cost-effective selection of large language models for classification queries,”arXiv preprint arXiv:2501.04901, 2025
-
[14]
Resource allocation for stable llm training in mobile edge computing,
C. Liu and J. Zhao, “Resource allocation for stable llm training in mobile edge computing,” inProceedings of the Twenty-fifth Inter- national Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, 2024, pp. 81–90
2024
-
[15]
Regret bounds for online learning for hierarchical inference,
G. Al-Atat, P . Datta, S. Moharir, and J. P . Champati, “Regret bounds for online learning for hierarchical inference,” inProceed- ings of the Twenty-fifth International Symposium on Theory, Algorith- mic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, 2024, pp. 281–290
2024
-
[16]
Local-cloud inference offloading for llms in multi-modal, multi-task, multi- dialogue settings,
L. Yuan, D.-J. Han, S. Wang, and C. G. Brinton, “Local-cloud inference offloading for llms in multi-modal, multi-task, multi- dialogue settings,”arXiv preprint arXiv:2502.11007, 2025
-
[17]
Cost-effective online multi-llm selection with versatile reward models,
X. Dai, J. Li, X. Liu, A. Yu, and J. Lui, “Cost-effective online multi-llm selection with versatile reward models,”arXiv preprint arXiv:2405.16587, 2024
-
[18]
A multi-agent drl-based computation offloading and resource allocation method with attention mechanism in mec-enabled iiot,
C. Ling, K. Peng, S. Wang, X. Xu, and V . C. Leung, “A multi-agent drl-based computation offloading and resource allocation method with attention mechanism in mec-enabled iiot,”IEEE Transactions on Services Computing, 2024
2024
-
[19]
Generalizable pareto- optimal offloading with reinforcement learning in mobile edge computing,
N. Yang, J. Wen, M. Zhang, and M. Tang, “Generalizable pareto- optimal offloading with reinforcement learning in mobile edge computing,”IEEE Transactions on Services Computing, 2025
2025
-
[20]
Offloading dependent tasks in edge computing with unknown system-side information,
X. Dai, Z. Xiao, H. Jiang, M. Lei, G. Min, J. Liu, and S. Dustdar, “Offloading dependent tasks in edge computing with unknown system-side information,”IEEE Transactions on Services Computing, vol. 16, no. 6, pp. 4345–4359, 2023
2023
-
[21]
Adversarial group linear bandits and its application to collaborative edge inference,
Y. Huang, L. Zhang, and J. Xu, “Adversarial group linear bandits and its application to collaborative edge inference,” inIEEE INFO- COM 2023-IEEE Conference on Computer Communications. IEEE, 2023, pp. 1–10
2023
-
[22]
Learning the optimal path and dnn partition for collabora- tive edge inference,
——, “Learning the optimal path and dnn partition for collabora- tive edge inference,”IEEE Transactions on Mobile Computing, 2025
2025
-
[23]
Bandits with knapsacks,
A. Badanidiyuru, R. Kleinberg, and A. Slivkins, “Bandits with knapsacks,”Journal of the ACM (JACM), vol. 65, no. 3, pp. 1–55, 2018
2018
-
[24]
Bandits with global convex constraints and objective,
S. Agrawal and N. R. Devanur, “Bandits with global convex constraints and objective,”Operations Research, vol. 67, no. 5, pp. 1486–1502, 2019
2019
-
[25]
Fairness in learning: Classic and contextual bandits,
M. Joseph, M. Kearns, J. H. Morgenstern, and A. Roth, “Fairness in learning: Classic and contextual bandits,”Advances in neural information processing systems, vol. 29, 2016
2016
-
[26]
Online learning with an unknown fairness metric,
S. Gillen, C. Jung, M. Kearns, and A. Roth, “Online learning with an unknown fairness metric,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[27]
Combinatorial multi-armed bandits with concave rewards and fairness constraints
H. Xu, Y. Liu, W. C. Lau, and R. Li, “Combinatorial multi-armed bandits with concave rewards and fairness constraints.” inIJCAI, 2020, pp. 2554–2560
2020
-
[28]
Adversarial bandits with knapsacks,
N. Immorlica, K. Sankararaman, R. Schapire, and A. Slivkins, “Adversarial bandits with knapsacks,”Journal of the ACM, vol. 69, no. 6, pp. 1–47, 2022
2022
-
[29]
Adversarial combinatorial bandits with switching cost and arm selection constraints,
Y. Huang, Q. Liu, and J. Xu, “Adversarial combinatorial bandits with switching cost and arm selection constraints,” inIEEE INFO- COM 2024-IEEE Conference on Computer Communications. IEEE, 2024, pp. 371–380
2024
-
[30]
Learning to optimize under non-stationarity,
W. C. Cheung, D. Simchi-Levi, and R. Zhu, “Learning to optimize under non-stationarity,” inThe 22nd International Conference on Artificial Intelligence and Statistics. PMLR, 2019, pp. 1079–1087
2019
-
[31]
Bandits with knapsacks: advice on time-varying demands,
L. Lyu and W. C. Cheung, “Bandits with knapsacks: advice on time-varying demands,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 23 212–23 238
2023
-
[32]
Quantum entanglement path se- lection and qubit allocation via adversarial group neural bandits,
Y. Huang, L. Wang, and J. Xu, “Quantum entanglement path se- lection and qubit allocation via adversarial group neural bandits,” IEEE Transactions on Networking, vol. 33, no. 2, pp. 583–594, 2024
2024
-
[33]
Competitive caching with ma- chine learned advice,
T. Lykouris and S. Vassilvitskii, “Competitive caching with ma- chine learned advice,”Journal of the ACM (JACM), vol. 68, no. 4, pp. 1–25, 2021
2021
-
[34]
Algorithms with predic- tions,
M. Mitzenmacher and S. Vassilvitskii, “Algorithms with predic- tions,”Communications of the ACM, vol. 65, no. 7, pp. 33–35, 2022
2022
-
[35]
Online scheduling via learned weights,
S. Lattanzi, T. Lavastida, B. Moseley, and S. Vassilvitskii, “Online scheduling via learned weights,” inProceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms. SIAM, 2020, pp. 1859–1877
2020
-
[36]
Improving online algo- rithms via ml predictions,
M. Purohit, Z. Svitkina, and R. Kumar, “Improving online algo- rithms via ml predictions,”Advances in Neural Information Process- ing Systems, vol. 31, 2018
2018
-
[37]
The primal-dual method for learning augmented algorithms,
E. Bamas, A. Maggiori, and O. Svensson, “The primal-dual method for learning augmented algorithms,”Advances in Neural Information Processing Systems, vol. 33, pp. 20 083–20 094, 2020
2020
-
[38]
Online facility location with multiple advice,
M. Almanza, F. Chierichetti, S. Lattanzi, A. Panconesi, and G. Re, “Online facility location with multiple advice,”Advances in neural information processing systems, vol. 34, pp. 4661–4673, 2021
2021
-
[39]
Secretary and online matching problems with machine learned advice,
A. Antoniadis, T. Gouleakis, P . Kleer, and P . Kolev, “Secretary and online matching problems with machine learned advice,” Advances in Neural Information Processing Systems, vol. 33, pp. 7933– 7944, 2020
2020
-
[40]
Online learning with predictable sequences,
A. Rakhlin and K. Sridharan, “Online learning with predictable sequences,” inConference on Learning Theory. PMLR, 2013, pp. 993–1019
2013
-
[41]
Optimization, learning, and games with predictable sequences,
S. Rakhlin and K. Sridharan, “Optimization, learning, and games with predictable sequences,”Advances in Neural Information Pro- cessing Systems, vol. 26, 2013
2013
-
[42]
Adaptivity and optimism: An im- proved exponentiated gradient algorithm,
J. Steinhardt and P . Liang, “Adaptivity and optimism: An im- proved exponentiated gradient algorithm,” inInternational confer- ence on machine learning. PMLR, 2014, pp. 1593–1601
2014
-
[43]
Online optimization: Competing with dynamic comparators,
A. Jadbabaie, A. Rakhlin, S. Shahrampour, and K. Sridharan, “Online optimization: Competing with dynamic comparators,” in Artificial Intelligence and Statistics. PMLR, 2015, pp. 398–406
2015
-
[44]
Dynamic pricing with limited supply,
M. Babaioff, S. Dughmi, R. Kleinberg, and A. Slivkins, “Dynamic pricing with limited supply,” 2015
2015
-
[45]
Bandits with concave rewards and convex knapsacks,
S. Agrawal and N. R. Devanur, “Bandits with concave rewards and convex knapsacks,” inProceedings of the fifteenth ACM confer- ence on Economics and computation, 2014, pp. 989–1006
2014
-
[46]
R. H. Shumway and D. S. Stoffer,Time Series Analysis and Its Applications. Springer, 2017
2017
-
[47]
R. J. Hyndman and G. Athanasopoulos,Forecasting: principles and practice. OTexts, 2021
2021
-
[48]
Time series forecasting with deep learning: A survey,
B. Lim and S. Zohren, “Time series forecasting with deep learning: A survey,” inPhilosophical Transactions of the Royal Society A, 2021
2021
-
[49]
Non-stationary bandits with knap- sacks,
S. Liu, J. Jiang, and X. Li, “Non-stationary bandits with knap- sacks,”Advances in Neural Information Processing Systems, vol. 35, pp. 16 522–16 532, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.