Two-Valued Symmetric Circulant Matrices: Applications in Deep Learning
Pith reviewed 2026-05-20 21:07 UTC · model grok-4.3
The pith
Restricting neural network weight matrices to two values arranged in a symmetric circulant pattern reduces parameters by more than 80 times while keeping classification accuracy near baseline levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a weight matrix restricted to exactly two distinct values and forced to remain both symmetric and circulant retains sufficient expressive power for standard image and signal classification tasks, thereby cutting storage from hundreds of thousands of parameters to a few thousand while accuracy stays within a few percentage points of the dense baseline.
What carries the argument
The Two-Valued Symmetric Circulant Matrix (TVSCM), a matrix whose entries take only two numerical values and obey both symmetry and circulant repetition, which collapses the storage cost of each fully connected layer to those two numbers.
If this is right
- Fully connected layers require only two stored numbers each, making total model size small enough for direct deployment on memory-constrained edge hardware.
- No post-training pruning or auxiliary approximation stages are needed to reach the reported sparsity.
- The same architecture supports low-power operation in IoMT and tiny-ML settings because arithmetic reduces to scaling by the two fixed values.
- Accuracy remains within roughly four percentage points of the dense network on both digit recognition and ECG arrhythmia classification.
Where Pith is reading between the lines
- The circulant symmetry might be relaxed or adapted for convolutional layers to compress vision backbones further.
- Because only two values are used, quantization-aware training or integer-only inference becomes trivial to add on top of the structure.
- Scaling the same pattern to transformer or recurrent layers could test whether the two-value limit remains viable for sequence tasks.
Load-bearing premise
That a weight matrix limited to exactly two distinct values in a symmetric circulant layout still supplies enough degrees of freedom to learn useful decision boundaries for the target tasks.
What would settle it
Training identical TVSCM networks on a harder benchmark such as CIFAR-10 and measuring whether top-1 accuracy falls more than ten points below the dense baseline while the dense model remains above 85 percent.
Figures


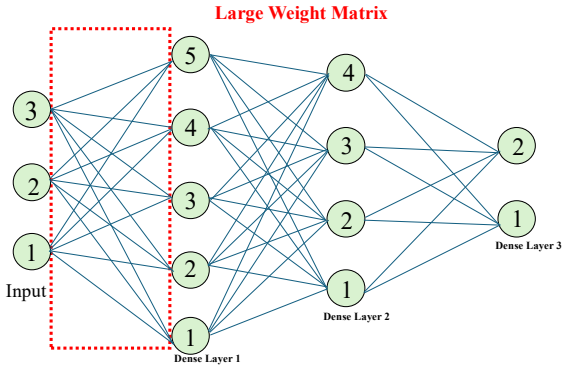














read the original abstract
Despite the success of deep neural networks in vision, medical diagnosis, and IoT scenarios, their deployment on resource-limited platforms poses serious challenges due to their high storage requirements, computational complexity, and large footprint. In particular, fully connected layers require a large number of weights, making it difficult for edge devices to accommodate them. To overcome these challenges associated with limited platforms, this paper proposes the Two-Valued Symmetric Circulant Matrix (TVSCM), a very sparse architecture that employs just two weights per layer to keep it circulant and symmetric. The extreme form of structured sparse architecture provides negligible storage costs compared to traditional full-weight storage. Instead of hardware and additional stages of other traditional sparse learning techniques, such as low-rank approximation and pruning approaches, this architecture provides an extreme form of sparsity, achieving very minimal storage requirements. The simulation study demonstrates more than 80$\times$ reduction in model parameters, reducing parameters from 623,290 to 7,852 on MNIST and from 24,709 to 942 on the MIT-BIH arrhythmia dataset, while maintaining comparable accuracy from 97.6% to 93.5% on MNIST and from 97.6% to 93.1% on MIT-BIH. Due to its minimal architectural requirements and very low power consumption, this architecture would be ideal for edge computing platforms, tiny-ML platforms, IoMT systems, and battery-powered systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Two-Valued Symmetric Circulant Matrix (TVSCM) as a replacement for fully-connected layers, restricting each layer to exactly two learnable scalar weights arranged according to symmetric circulant structure. It reports >80× parameter reduction (623290→7852 on MNIST; 24709→942 on MIT-BIH) with accuracy dropping only from 97.6% to 93.5% and 97.6% to 93.1% respectively, positioning the method as a hardware-free extreme-sparsity solution for edge and tiny-ML platforms.
Significance. If the empirical results are reproducible and the architecture generalizes, the approach would supply an unusually compact, training-compatible form of structured sparsity that removes the need for separate pruning or low-rank stages. The concrete parameter counts and accuracy numbers on two datasets constitute a clear, falsifiable claim; however, the absence of any rank, approximation, or capacity argument leaves open whether the 2-dimensional hypothesis class per layer can support the observed performance beyond these specific experiments.
major comments (3)
- Abstract: the headline claim that accuracy remains 'comparable' after an approximately 4-point drop is presented without error bars, multiple random seeds, or statistical significance tests. This directly affects whether the reported numbers support the central assertion of usable performance under extreme compression.
- No section supplies a rank bound, approximation guarantee, or capacity argument showing that the linear maps realizable by a symmetric circulant matrix with exactly two distinct values can separate the MNIST or MIT-BIH classes at the reported accuracy. The empirical results alone therefore leave the weakest assumption—that the 2-parameter family retains sufficient expressive power—untested and load-bearing for the parameter-reduction claim.
- The manuscript contains no ablation on the choice of the two scalar values, no description of how the circulant symmetry constraint is enforced (or relaxed) during back-propagation, and no head-to-head comparison against standard low-rank or pruning baselines on identical network depths and datasets. These omissions make it impossible to isolate the contribution of the TVSCM structure itself.
minor comments (2)
- The construction of the TVSCM (how the two values are assigned to the circulant diagonals while preserving symmetry) would benefit from an explicit matrix equation or small worked example in the methods section.
- Missing citations to prior literature on circulant neural-network layers and on two-value or binary-weight networks would help situate the novelty of the symmetric two-value restriction.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We appreciate the opportunity to clarify and strengthen our presentation of the TVSCM approach. Below, we address each major comment point by point. We will revise the manuscript to incorporate statistical analysis, additional experimental details, and comparisons as suggested, while preserving the core empirical contributions.
read point-by-point responses
-
Referee: Abstract: the headline claim that accuracy remains 'comparable' after an approximately 4-point drop is presented without error bars, multiple random seeds, or statistical significance tests. This directly affects whether the reported numbers support the central assertion of usable performance under extreme compression.
Authors: We agree with the referee that providing statistical support for the accuracy claims would strengthen the manuscript. In the revised version, we will report results averaged over multiple random seeds (e.g., 5 or 10 runs), include standard deviations or error bars, and conduct appropriate statistical tests (such as paired t-tests) to assess the significance of the observed accuracy differences. This will better substantiate the claim of comparable performance under the reported parameter reduction. revision: yes
-
Referee: No section supplies a rank bound, approximation guarantee, or capacity argument showing that the linear maps realizable by a symmetric circulant matrix with exactly two distinct values can separate the MNIST or MIT-BIH classes at the reported accuracy. The empirical results alone therefore leave the weakest assumption—that the 2-parameter family retains sufficient expressive power—untested and load-bearing for the parameter-reduction claim.
Authors: We acknowledge that the manuscript does not include a formal theoretical analysis of the expressive capacity of TVSCM layers. Our work is primarily empirical, demonstrating practical performance on standard benchmarks. In the revision, we will add a discussion on the properties of symmetric circulant matrices with two values, including their representation via Fourier transforms and the limited degrees of freedom. While we cannot provide a complete rank bound or approximation guarantee without further theoretical investigation, this addition will help contextualize the empirical success. revision: partial
-
Referee: The manuscript contains no ablation on the choice of the two scalar values, no description of how the circulant symmetry constraint is enforced (or relaxed) during back-propagation, and no head-to-head comparison against standard low-rank or pruning baselines on identical network depths and datasets. These omissions make it impossible to isolate the contribution of the TVSCM structure itself.
Authors: We agree that these elements are necessary to fully evaluate the method. We will revise the manuscript to include: an ablation study on the selection and sensitivity to the two scalar values; a clear description of how the TVSCM is implemented by parameterizing with two scalars and constructing the matrix to satisfy the symmetric circulant constraints before each forward pass, enabling standard gradient descent; and direct comparisons with low-rank factorization and pruning techniques on the same models and datasets, with metrics on accuracy and parameter efficiency. revision: yes
Circularity Check
No significant circularity in TVSCM architecture proposal
full rationale
The paper defines the TVSCM as a matrix constrained to exactly two distinct values while enforcing symmetric circulant structure, then reports empirical results after training the two scalars per layer on MNIST and MIT-BIH. No derivation, theorem, or first-principles claim is advanced whose output reduces to the input definition by construction. The parameter reduction follows directly from the explicit architectural choice (two scalars), and the accuracy figures are measured outcomes of standard optimization rather than any fitted prediction or self-referential step. The work is self-contained as an empirical demonstration of a restricted hypothesis class; no load-bearing self-citation, ansatz smuggling, or uniqueness theorem is invoked.
Axiom & Free-Parameter Ledger
free parameters (1)
- two distinct weight values per layer
axioms (1)
- domain assumption A symmetric circulant matrix generated from two scalar values is a valid and trainable replacement for a dense weight matrix in fully connected layers
invented entities (1)
-
Two-Valued Symmetric Circulant Matrix (TVSCM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Prabha Sundaravadivel, Elias Kougianos, Saraju P Mohanty, and Madhavi K Ganapathiraju. Everything You Wanted to Know about Smart Health Care: Evaluating the Different Technologies and Components of the Internet of Things for Better Health.IEEE Consumer Electronics Magazine, 7(1):18–28, 2017
work page 2017
-
[2]
LucaGreco,GennaroPercannella,PierluigiRitrovato,FrancescoTortorella,andMarioVento. TrendsinIoT-Based Solutions for Health Care: Moving AI to the Edge.Pattern Recognition Letters, 135:346–353, 2020
work page 2020
-
[3]
EdgeintelligenceandInternetofThingsinhealthcare: Asurvey.IEEE access, 9:45–59, 2020
SyedUmarAminandMShamimHossain. EdgeintelligenceandInternetofThingsinhealthcare: Asurvey.IEEE access, 9:45–59, 2020
work page 2020
-
[4]
Alexandru Rancea, Ionut Anghel, and Tudor Cioara. Edge Computing in Healthcare: Innovations, Opportunities, and Challenges.Future Internet, 16(9):329, 2024
work page 2024
-
[5]
Vahideh Hayyolalam, Moayad Aloqaily, Öznur Özkasap, and Mohsen Guizani. Edge Intelligence for Empowering IoT-Based Healthcare Systems.IEEE Wireless Communications, 28(3):6–14, 2021
work page 2021
-
[6]
George B. Moody and Roger G. Mark. Mit-bih arrhythmia database (version 1.0.0).https://physionet.org/ content/mitdb/1.0.0/, 2005. PhysioNet
work page 2005
-
[7]
Denis Serre. What Are Matrices. InMatrices: Theory and Applications, pages 15–30. Springer, 2010
work page 2010
-
[8]
Ivan Bioli, Daniel Kressner, and Leonardo Robol. Preconditioned Low-Rank Riemannian Optimization for SymmetricPositiveDefiniteLinearMatrixEquations.SIAMJournalonScientificComputing,47(2):A1091–A1116, 2025
work page 2025
-
[9]
Xiao Liu, Jianlin Xia, and Maarten V De Hoop. Parallel Randomized and Matrix-Free Direct Solvers for Large Structured Dense Linear Systems.SIAM Journal on Scientific Computing, 38(5):S508–S538, 2016
work page 2016
-
[10]
Pieter Coulier, Hadi Pouransari, and Eric Darve. The Inverse Fast Multipole Method: Using a Fast Approximate Direct Solver as a Preconditioner for Dense Linear Systems.SIAM Journal on Scientific Computing, 39(3):A761– A796, 2017
work page 2017
-
[11]
A Diagonal Form of an Implicit Approximate-Factorization Algorithm
Thomas H Pulliam and DS Chaussee. A Diagonal Form of an Implicit Approximate-Factorization Algorithm. Journal of Computational Physics, 39(2):347–363, 1981
work page 1981
-
[12]
Tuomo Rossi and Jari Toivanen. A Parallel Fast Direct Solver for Block Tridiagonal Systems with Separable Matrices of Arbitrary Dimension.SIAM Journal on Scientific Computing, 20(5):1778–1793, 1999
work page 1999
-
[13]
Robert M Gray et al. Toeplitz and Circulant Matrices: A Review.Foundations and Trends®in Communications and Information Theory, 2(3):155–239, 2006
work page 2006
-
[14]
Ke Ye and Lek-Heng Lim. Every Matrix Is a Product of Toeplitz Matrices.Foundations of Computational Mathematics, 16(3):577–598, 2016
work page 2016
-
[15]
CirCNN: Accelerating and Compressing Deep Neural Networks Using Block-Circulant Weight Matrices
Caiwen Ding, Siyu Liao, Yanzhi Wang, Zhe Li, Ning Liu, Youwei Zhuo, Chao Wang, Xuehai Qian, Yu Bai, Geng Yuan, et al. CirCNN: Accelerating and Compressing Deep Neural Networks Using Block-Circulant Weight Matrices. InProceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture, pages 395–408, 2017
work page 2017
-
[16]
PermDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices
Chunhua Deng, Siyu Liao, Yi Xie, Keshab K Parhi, Xuehai Qian, and Bo Yuan. PermDNN: Efficient Compressed DNN Architecture with Permuted Diagonal Matrices. In2018 51st Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 189–202. IEEE, 2018
work page 2018
-
[17]
Gorbett.Towards Fair and Efficient Distributed Intelligence
M. Gorbett.Towards Fair and Efficient Distributed Intelligence. PhD thesis, ProQuest Dissertations & Theses Global, 2024. Order No. 30993319
work page 2024
-
[18]
Richard Zhipeng Wang, James S Cummins, Marvin Syed, Nikita Stroev, George Pastras, Jason Sakellariou, Symeon Tsintzos, Alexis Askitopoulos, Daniele Veraldi, Marcello Calvanese Strinati, et al. Efficient Computation Using Spatial-Photonic Ising Machines with Low-Rank and Circulant Matrix Constraints.Communications Physics, 8(1):86, 2025
work page 2025
-
[19]
SimeonSpasov,LucaPassamonti,AndreaDuggento,PietroLio,NicolaToschi,Alzheimer’sDiseaseNeuroimaging Initiative, et al. A Parameter-Efficient Deep Learning Approach to Predict Conversion from Mild Cognitive Impairment to Alzheimer’s Disease.NeuroImage, 189:276–287, 2019
work page 2019
-
[20]
ImprovingDeepLearning-BasedImageClassificationThroughNoise Reduction and Feature Enhancement
Lavanya Dalavai, Naga MalleswaraRao Purimetla, Sai Srinivas Vellela, Thalakola SyamsundaraRao, Lak- shmaReddyVuyyuru,KKiranKumar,etal. ImprovingDeepLearning-BasedImageClassificationThroughNoise Reduction and Feature Enhancement. In2024 International Conference on Artificial Intelligence and Quantum Computation-Based Sensor Application (ICAIQSA), pages 1–7...
work page 2024
-
[21]
Nicola Franco, Andrea Manzoni, and Paolo Zunino. A Deep Learning Approach to Reduced Order Modelling of Parameter Dependent Partial Differential Equations.Mathematics of Computation, 92(340):483–524, 2023
work page 2023
-
[22]
MingliangWang,Han-XiongLi,XinChen,andYunChen. DeepLearning-BasedModelReductionforDistributed Parameter Systems.IEEE Transactions on Systems, Man, and Cybernetics: Systems, 46(12):1664–1674, 2016
work page 2016
-
[23]
Hongrong Cheng, Miao Zhang, and Javen Qinfeng Shi. A Survey on Deep Neural Network Pruning: Taxonomy, Comparison, and Recommendations.arXiv Preprint arXiv:2301.00278, 2023
-
[24]
Giosué Cataldo Marinó, Alessandro Petrini, Dario Malchiodi, and Marco Frasca. Deep Neural Networks Compression: A Comparative Survey and Choice Recommendations.Neurocomputing, 520:152–170, 2023
work page 2023
-
[25]
Davis Blalock, Jose Javier Gonzalez Ortiz, Jonathan Frankle, and John Guttag. What Is the State of Neural Network Pruning?Proceedings of Machine Learning and Systems, 2:129–146, 2020
work page 2020
-
[26]
Rethinking the Value of Network Pruning
Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the Value of Network Pruning.arXiv Preprint arXiv:1810.05270, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
PhD thesis, KIT-Bibliothek, 2024
Daniel Coquelin.Optimization of AI Methods on Distributed-Memory Computing Architectures. PhD thesis, KIT-Bibliothek, 2024
work page 2024
-
[28]
Quantization.IEEETransactionsonInformationTheory,44(6):2325–2383, 2002
RobertM.GrayandDavidL.Neuhoff. Quantization.IEEETransactionsonInformationTheory,44(6):2325–2383, 2002
work page 2002
-
[29]
Quantization.Mathematics of the USSR-Izvestiya, 8(5):1109, 1974
Felix A Berezin. Quantization.Mathematics of the USSR-Izvestiya, 8(5):1109, 1974
work page 1974
-
[30]
Low-Rank Compression of Neural Nets: Learning the Rank of Each Layer
Yerlan Idelbayev and Miguel A Carreira-Perpinán. Low-Rank Compression of Neural Nets: Learning the Rank of Each Layer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8049–8059, 2020
work page 2020
-
[31]
Trained Rank Pruning for Efficient Deep Neural Networks
Yuhui Xu, Yuxi Li, Shuai Zhang, Wei Wen, Botao Wang, Wenrui Dai, Yingyong Qi, Yiran Chen, Weiyao Lin, and Hongkai Xiong. Trained Rank Pruning for Efficient Deep Neural Networks. In2019 Fifth Workshop on Energy Efficient Machine Learning and Cognitive Computing (EMC2-NIPS), pages 14–17. IEEE, 2019
work page 2019
-
[32]
Low-Rank Matrix Factorization for Deep Neural Network Training with High-Dimensional Output Targets
Tara N Sainath, Brian Kingsbury, Vikas Sindhwani, Ebru Arisoy, and Bhuvana Ramabhadran. Low-Rank Matrix Factorization for Deep Neural Network Training with High-Dimensional Output Targets. In2013 IEEE International Conference on Acoustics, Speech and Signal Processing, pages 6655–6659. IEEE, 2013
work page 2013
-
[33]
Zaiwen Wen, Wotao Yin, and Yin Zhang. Solving a Low-Rank Factorization Model for Matrix Completion by a Nonlinear Successive Over-Relaxation Algorithm.Mathematical Programming Computation, 4(4):333–361, 2012
work page 2012
-
[34]
XitongZhang,IsmailRAlkhouri,andRongrongWang. Structure-PreservingNetworkCompressionviaLow-Rank Induced Training Through Linear Layers Composition.arXiv Preprint arXiv:2405.03089, 2024
-
[35]
JayaKrishna Amathi, TVN Prasanna, and AV Ramakrishna. A Note on Stability of Certain Discrete Linear Time Invariant Systems.International Journal of Mathematics & Computer Science, 20(4), 2025
work page 2025
-
[36]
Arthur R Bergen and David J Hill. A Structure Preserving Model for Power System Stability Analysis.IEEE Transactions on Power Apparatus and Systems, (1):25–35, 2007
work page 2007
-
[37]
Yu Ding, Lei Wang, Bin Liang, Shuming Liang, Yang Wang, and Fang Chen. Domain Generalization by Learning and Removing Domain-Specific Features.Advances in Neural Information Processing Systems, 35:24226–24239, 2022
work page 2022
-
[38]
Domain-Specific Risk Minimization for Domain Generalization
Yi-Fan Zhang, Jindong Wang, Jian Liang, Zhang Zhang, Baosheng Yu, Liang Wang, Dacheng Tao, and Xing Xie. Domain-Specific Risk Minimization for Domain Generalization. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3409–3421, 2023
work page 2023
-
[39]
Hari Gonaygunta, Mohan Harish Maturi, Geeta Sandeep Nadella, Karthik Meduri, and Snehal Satish. Quantum Machine Learning: Exploring Quantum Algorithms for Enhancing Deep Learning Models.International Journal of Advanced Engineering Research and Science, 11(05):35–41, 2024
work page 2024
-
[40]
Rishi Reddy Kothinti. Deep Learning in Healthcare: Transforming Disease Diagnosis, Personalized Treatment, and Clinical Decision-Making through AI-Driven Innovations.World Journal of Advanced Research and Reviews, 24(2):2841–2856, 2024
work page 2024
-
[41]
AsifaNazir,AhsanHussain,MandeepSingh,andAssifAssad. DeepLearninginMedicine: AdvancingHealthcare with Intelligent Solutions and the Future of Holography Imaging in Early Diagnosis.Multimedia Tools and Applications, 84(17):17677–17740, 2025
work page 2025
-
[42]
Anichur Rahman, Tanoy Debnath, Dipanjali Kundu, Md Saikat Islam Khan, Airin Afroj Aishi, Sadia Sazzad, Mohammad Sayduzzaman, and Shahab S Band. Machine Learning and Deep Learning-Based Approach in Smart Healthcare: Recent Advances, Applications, Challenges and Opportunities.AIMS Public Health, 11(1):58–109, 2024
work page 2024
-
[43]
Sujata Dash, Subhendu Kumar Pani, Joel J. P. C. Rodrigues, and Banshidhar Majhi, editors.Deep Learning, Machine Learning and IoT in Biomedical and Health Informatics: Techniques and Applications. CRC Press, 1st edition, 2022
work page 2022
-
[44]
Deep Learning in Diagnostics.Journal of Medical Discoveries, 2(1):1–6, 2025
Omid Panahi. Deep Learning in Diagnostics.Journal of Medical Discoveries, 2(1):1–6, 2025
work page 2025
-
[45]
Farah Magrabi, Elske Ammenwerth, Jytte Brender McNair, Nicolet F De Keizer, Hannele Hyppönen, Pirkko Nykänen, Michael Rigby, Philip J Scott, Tuulikki Vehko, Zoie Shui-Yee Wong, et al. Artificial Intelligence in Clinical Decision Support: Challenges for Evaluating AI and Practical Implications.Yearbook of Medical Informatics, 28(01):128–134, 2019
work page 2019
-
[46]
F John Dian, Reza Vahidnia, and Alireza Rahmati. Wearables and the Internet of Things (IoT), Applications, Opportunities, and Challenges: A Survey.IEEE Access, 8:69200–69211, 2020
work page 2020
-
[47]
Rayan H Assaad, Mohsen Mohammadi, and Oscar Poudel. Developing an Intelligent IoT-Enabled Wearable Multimodal Biosensing Device and Cloud-Based Digital Dashboard for Real-Time and Comprehensive Health, Physiological, Emotional, and Cognitive Monitoring Using Multi-Sensor Fusion Technologies.Sensors and Actuators A: Physical, 381:116074, 2025
work page 2025
-
[48]
Francisca Chibugo Udegbe, Ogochukwu Roseline Ebulue, Charles Chukwudalu Ebulue, and Chuk- wunonso Sylvester Ekesiobi. The Role of Artificial Intelligence in Healthcare: A Systematic Review of Applications and Challenges.International Medical Science Research Journal, 4(4):500–508, 2024
work page 2024
-
[49]
Betelhem Zewdu Wubineh, Fitsum Gizachew Deriba, and Michael Melese Woldeyohannis. Exploring the Opportunities and Challenges of Implementing Artificial Intelligence in Healthcare: A Systematic Literature Review.Urologic Oncology: Seminars and Original Investigations, 42(3):48–56, 2024
work page 2024
-
[50]
Tara Qian Sun and Rony Medaglia. Mapping the Challenges of Artificial Intelligence in the Public Sector: Evidence from Public Healthcare.Government Information Quarterly, 36(2):368–383, 2019
work page 2019
-
[51]
AbdullahAlanazi. UsingMachineLearningforHealthcareChallengesandOpportunities.InformaticsinMedicine Unlocked, 30:100924, 2022
work page 2022
-
[52]
RashidAmin,MohammedAAlGhamdi,SultanHAlmotiri,MeshrifAlruily,etal. HealthcareTechniquesthrough Deep Learning: Issues, Challenges and Opportunities.IEEE Access, 9:98523–98541, 2021
work page 2021
-
[53]
Ethical and Legal Challenges of Artificial Intelligence-Driven Healthcare
Sara Gerke, Timo Minssen, and Glenn Cohen. Ethical and Legal Challenges of Artificial Intelligence-Driven Healthcare. InArtificial Intelligence in Healthcare, pages 295–336. Elsevier, 2020
work page 2020
-
[54]
Tribikram Dhar, Nilanjan Dey, Surekha Borra, and R Simon Sherratt. Challenges of Deep Learning in Medical Image Analysis—Improving Explainability and Trust.IEEE Transactions on Technology and Society, 4(1):68–75, 2023
work page 2023
-
[55]
CircConv: A Structured Convolution with Low Complexity
Siyu Liao and Bo Yuan. CircConv: A Structured Convolution with Low Complexity. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 4287–4294, 2019
work page 2019
-
[56]
BlockGNN:TowardsEfficientGNN Acceleration Using Block-Circulant Weight Matrices
ZheZhou,BizhaoShi,ZheZhang,YijinGuan,GuangyuSun,andGuojieLuo. BlockGNN:TowardsEfficientGNN Acceleration Using Block-Circulant Weight Matrices. In2021 58th ACM/IEEE Design Automation Conference (DAC), pages 1009–1014. IEEE, 2021
work page 2021
-
[57]
Euis Asriani, Intan Muchtadi-Alamsyah, and Ayu Purwarianti. Real Block-Circulant Matrices and DCT-DST Algorithm for Transformer Neural Network.Frontiers in Applied Mathematics and Statistics, 9:1260187, 2023
work page 2023
-
[58]
Alexandre Araujo, Benjamin Negrevergne, Yann Chevaleyre, and Jamal Atif. Understanding and Training Deep Diagonal Circulant Neural Networks.arXiv Preprint arXiv:1901.10255, 2019
-
[59]
Structured Transforms for Small-Footprint Deep Learning
Vikas Sindhwani, Tara Sainath, and Sanjiv Kumar. Structured Transforms for Small-Footprint Deep Learning. Advances in Neural Information Processing Systems, 28, 2015
work page 2015
-
[60]
Block Circulant Adapter for Large Language Models
Xinyu Ding, Meiqi Wang, Siyu Liao, and Zhongfeng Wang. Block Circulant Adapter for Large Language Models. arXiv Preprint arXiv:2505.00582, 2025
-
[61]
Monarch: Expressive Structured Matrices for Efficient and Accurate Training
Tri Dao, Beidi Chen, Nimit S Sohoni, Arjun Desai, Michael Poli, Jessica Grogan, Alexander Liu, Aniruddh Rao, Atri Rudra, and Christopher Ré. Monarch: Expressive Structured Matrices for Efficient and Accurate Training. In International Conference on Machine Learning, pages 4690–4721. PMLR, 2022
work page 2022
-
[62]
Arijit Sehanobish, Kumar Avinava Dubey, Krzysztof M Choromanski, Somnath Basu Roy Chowdhury, Deepali Jain, Vikas Sindhwani, and Snigdha Chaturvedi. Structured Unrestricted-Rank Matrices for Parameter Efficient Finetuning.Advances in Neural Information Processing Systems, 37:78244–78277, 2024
work page 2024
-
[63]
Mukhammed Garifulla, Juncheol Shin, Chanho Kim, Won Hwa Kim, Hye Jung Kim, Jaeil Kim, and Seokin Hong. A Case Study of Quantizing Convolutional Neural Networks for Fast Disease Diagnosis on Portable Medical Devices.Sensors, 22(1):219, 2021
work page 2021
-
[64]
Beaudelaire Saha Tchinda and Daniel Tchiotsop. A Lightweight 1D Convolutional Neural Network Model for Arrhythmia Diagnosis from Electrocardiogram Signal.Physical and Engineering Sciences in Medicine, 48(2):577–589, 2025
work page 2025
-
[65]
Mojtaba Akbari, Majid Mohrekesh, Shima Rafiei, SM Reza Soroushmehr, Nader Karimi, Shadrokh Samavi, and Kayvan Najarian. Classification of Informative Frames in Colonoscopy Videos Using Convolutional Neural Networks with Binarized Weights. In2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 65–6...
work page 2018
-
[66]
Exploring Physical Unclonable Functions for Efficient Hardware Assisted Security in IoT,
Yunfei Wang, Rong Li, Zheng Wang, Zhixin Hua, Yitao Jiao, Yuanchao Duan, and Huaibo Song. E3D: An Efficient 3D CNN for the Recognition of Dairy Cow’s Basic Motion Behavior.Computers and Electronics in Agriculture, 205:107607, 2023. Authors’ Biographies Jayakrishna Amathireceived the Bachelor of Technology degree in Computer Science and Engineering from R....
work page 2023
-
[67]
He has delivered 31 keynotes and served on 15 panels at various International Conferences
He is a recipient of 21 best paper awards, Fulbright Specialist Award in 2021, IEEE Consumer Electronics Society Outstanding Service Award in 2020, the IEEE-CS-TCVLSI Distinguished Leadership Award in 2018, and the PROSE Award for Best Textbook in Physical Sciences and Mathematics category in 2016. He has delivered 31 keynotes and served on 15 panels at v...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.