Cluster-Specific Localized Drift Detection for Efficient Batch Model Adaptation under Controlled Distribution Shift
Pith reviewed 2026-06-26 11:47 UTC · model grok-4.3
The pith
A simulation framework converts static tabular datasets into controlled evolving data streams by perturbing clustered feature partitions to enable evaluation of drift adaptation strategies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
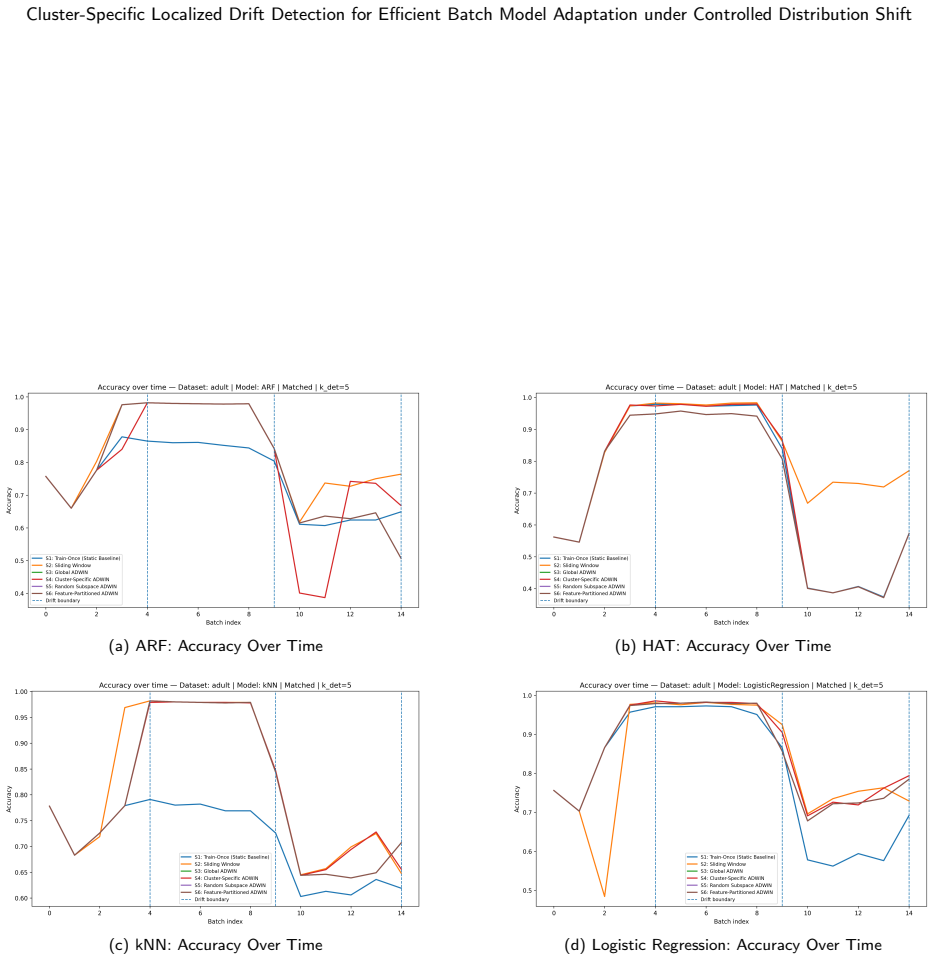
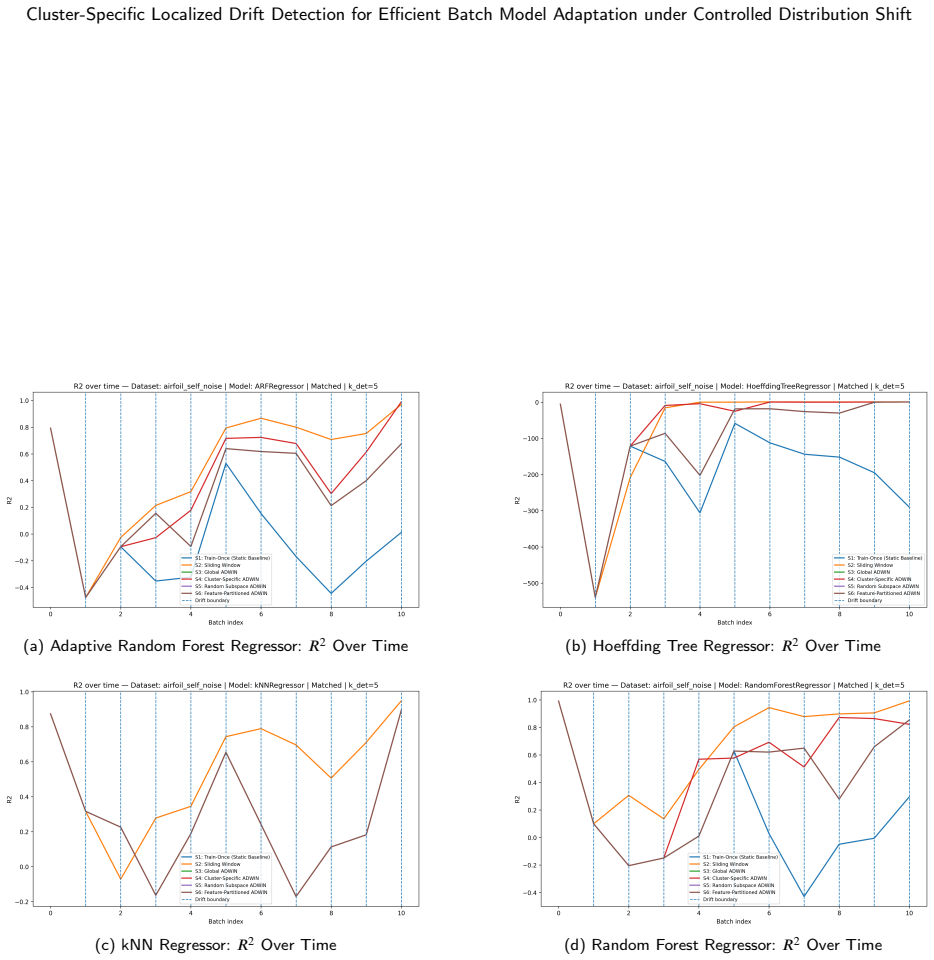
The paper establishes a cluster-induced distribution shift simulation framework that transforms static tabular datasets into controlled evolving data streams through structured perturbations across feature space partitions, which then supports the systematic evaluation of six adaptation strategies including static learning, sliding-window retraining, global and cluster-local ADWIN retraining, random subspace drift detection, and feature-partitioned drift detection on five benchmark datasets.
What carries the argument
The cluster-induced distribution shift simulation framework that identifies feature space partitions via clustering and applies structured perturbations to simulate controlled distribution shifts in the generated data streams.
If this is right
- Reproducible comparisons of adaptation strategies become possible on standard tabular benchmarks with known shift characteristics.
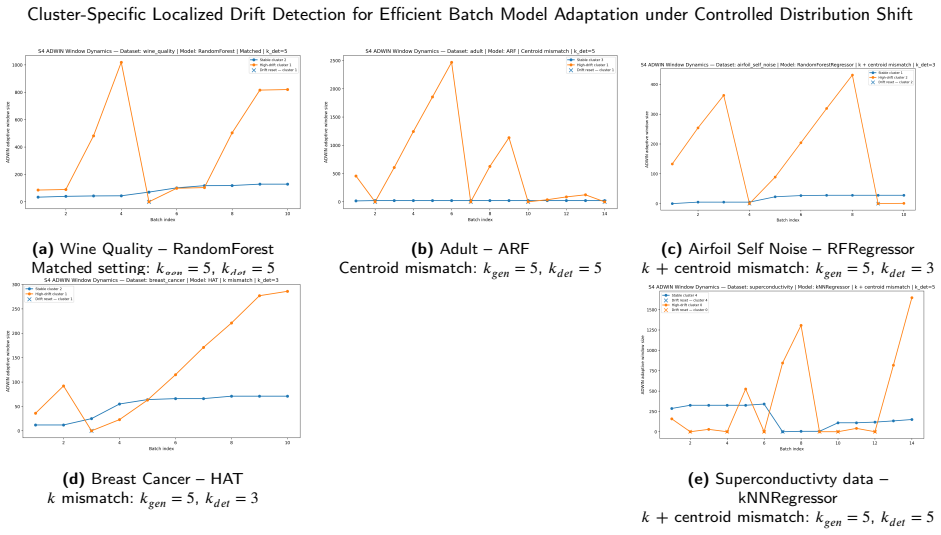
- Cluster-local ADWIN retraining and feature-partitioned drift detection can be assessed for efficiency in batch model adaptation.
- Performance of linear models, nearest neighbors, tree ensembles, boosting, and online learners can be tracked under the same simulated shifts.
- The framework distinguishes between global and localized detection approaches in terms of their response to partition-specific changes.
Where Pith is reading between the lines
- Such controlled simulations could help identify which adaptation methods scale best to different shift types before real deployment.
- Extending the perturbation approach to other dataset types might broaden its utility in streaming machine learning research.
- The emphasis on cluster-specific localization suggests potential efficiency gains in detecting and responding to localized drifts.
Load-bearing premise
The structured perturbations across feature space partitions produce distribution shifts that are controlled enough and representative enough to allow meaningful comparisons between adaptation strategies.
What would settle it
If experiments on real-world streaming datasets with natural temporal structure show that the relative performance of the six strategies reverses compared to the simulated streams, the framework's validity for guiding adaptation choices would be undermined.
Figures









read the original abstract
Machine learning systems deployed in dynamic environments frequently operate under nonstationary data distributions, where controlled distribution shift can progressively degrade predictive performance. However, many widely used tabular benchmark datasets lack explicit temporal structure, limiting reproducible evaluation of drift adaptation methods. This work proposes a cluster-induced distribution shift simulation framework that transforms static tabular datasets into controlled evolving data streams through structured perturbations across featurespace partitions. Using this framework, six adaptation strategies are systematically evaluated: static learning, sliding-window retraining, global ADWIN retraining, cluster-local ADWIN retraining, random subspace drift detection, and feature-partitioned drift detection. Experiments are conducted on five benchmark datasets covering both classification and regression tasks using diverse predictive model families, including linear models, k-Nearest Neighbours, tree ensembles, boosting methods, and adaptive online learners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a cluster-induced distribution shift simulation framework that transforms static tabular datasets into controlled evolving data streams through structured perturbations across feature-space partitions. Using this framework, it systematically evaluates six adaptation strategies—static learning, sliding-window retraining, global ADWIN retraining, cluster-local ADWIN retraining, random subspace drift detection, and feature-partitioned drift detection—on five benchmark datasets covering classification and regression tasks with diverse model families including linear models, kNN, tree ensembles, boosting methods, and adaptive online learners.
Significance. If the proposed simulation framework generates sufficiently controlled and representative distribution shifts, the work provides a valuable contribution by enabling reproducible evaluation of drift adaptation methods on otherwise static tabular benchmarks. The systematic comparison of localized versus global detection approaches could yield practical insights for efficient batch model adaptation under nonstationary conditions. The framework itself is a strength as an independent construction for generating evolving streams without relying on fitted parameters or circular assumptions.
minor comments (2)
- [Abstract] Abstract: the description of the framework and evaluation plan is clear at a high level, but the absence of any quantitative results, error bars, or verification details in the provided abstract makes it impossible to assess the central claims of efficiency and effectiveness; the full methods and results sections are needed to substantiate the comparisons.
- The weakest assumption noted—that the structured perturbations produce sufficiently controlled and representative shifts—is presented as the intended output of the framework rather than a hidden premise, which is appropriate, but the manuscript should explicitly state how reproducibility of the perturbation process is ensured (e.g., via fixed seeds or public code).
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the cluster-induced distribution shift framework and its potential value for reproducible evaluation of adaptation strategies. The recommendation for minor revision is noted. No specific major comments were provided in the report, so we have no point-by-point responses to address at this time. We will incorporate any minor editorial or presentation improvements in the revised manuscript.
Circularity Check
No significant circularity
full rationale
The paper proposes an explicit new framework for generating controlled distribution shifts via cluster-based perturbations on static tabular datasets, then applies it to evaluate six listed adaptation strategies on five benchmarks. No equations, fitted parameters, or derivations are described that reduce to self-definition or prior self-citations. The central construction (cluster-induced perturbations creating evolving streams) is presented as an independent methodological contribution rather than a result derived from its own outputs or unverified self-citations. The evaluation scope is external to the framework definition itself, satisfying the criteria for a self-contained proposal with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structured perturbations across feature space partitions can create controlled and reproducible distribution shifts suitable for evaluating adaptation methods.
invented entities (1)
-
Cluster-induced distribution shift simulation framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A framework for clustering evolving data streams, in: Data Streams: Models and Algorithms. Springer, pp. 81–92. doi:10.1016/B978-012722442-8/50016-1. Agrahari, S., Singh, A.K.,
-
[2]
Journal of King Saud University – Computer and Information Sciences 34, 9523–9540
Concept drift detection in data stream mining: A literature review. Journal of King Saud University – Computer and Information Sciences 34, 9523–9540. doi:10.1016/j.jksuci.2021.11.006. Aguiar,G.J.,Cano,A.,2023. Acomprehensiveanalysisofconceptdriftlocalityindatastreams. URL:https://arxiv.org/abs/2311.06396, arXiv:2311.06396. Baena-García, M., del Campo-Ávi...
-
[3]
Knowledge-Based Systems 245, 108632
From concept drift to model degradation: An overview on performance-aware drift detectors. Knowledge-Based Systems 245, 108632. doi:10.1016/j.knosys.2022.108632. :Preprint submitted to Elsevier Page 63 of 65 Cluster-Specific Localized Drift Detection for Efficient Batch Model Adaptation under Controlled Distribution Shift Becker, B., Kohavi, R.,
-
[4]
UCI Machine Learning Repository
Adult. UCI Machine Learning Repository. doi:10.24432/C5XW20. Bifet, A., Gavaldà, R.,
-
[5]
Learning from time-changing data with adaptive windowing, in: Proceedings of the 2007 SIAM International Conference on Data Mining, SIAM. pp. 443–448. doi:10.1137/1.9781611972771.42. Bifet, A., Gavaldà, R.,
-
[6]
Adaptive learning from evolving data streams, in: Advances in Intelligent Data Analysis VIII, Springer. pp. 249–260. doi:10.1007/978-3-642-03915-7\_22. Bifet, A., Holmes, G., Pfahringer, B., Kranen, P., Kremer, H., Jansen, T., Seidl, T.,
-
[7]
Random forests. Machine Learning 45, 5–32. doi:10.1023/A:1010933404324. Cabello-López, T., Cañizares-Juan, M., Carranza-García, M., Garcia-Gutiérrez, J., Riquelme, J.C.,
-
[8]
Concept drift detection to improve time series forecasting of wind energy generation, in: Lecture Notes in Computer Science, pp. 133–140. doi:10.1007/978-3-031-15471-3\_12. Chen, T., Guestrin, C.,
-
[9]
Xgboost: A scalable tree boosting system, in: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 785–794. doi:10.1145/2939672.2939785. Cortez,P.,Cerdeira,A.,Almeida,F.,Matos,T.,Reis,J.,2009.Modelingwinepreferencesbydataminingfromphysicochemicalproperties.Decision Support Systems 47, 547–553. doi:10.1016...
-
[10]
Nearest neighbor pattern classification. IEEE Transactions on Information Theory 13, 21–27. doi:10.1109/TIT. 1967.1053964. Ditzler,G.,Roveri,M.,Alippi,C.,Polikar,R.,2015. Learninginnonstationaryenvironments:Asurvey. IEEEComputationalIntelligenceMagazine 10, 12–25. doi:10.1109/MCI.2015.2471196. Domingos, P., Hulten, G.,
work page doi:10.1109/tit 1967
-
[11]
Mining high-speed data streams, in: Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM. pp. 71–80. doi:10.1145/347090.347107. Gama,J.,2010. KnowledgeDiscoveryfromDataStreams. 1ed.,ChapmanandHall/CRC,BocaRaton,FL. URL:https://doi.org/10.1201/ EBK1439826119, doi:10.1201/EBK1439826119. Gama, J., Medas, P....
-
[12]
Learning with drift detection, in: Advances in Artificial Intelligence – SBIA 2004, Springer. pp. 286–295. doi:10.1007/978-3-540-28645-5\_29. Gama, J., Žliobait˙e, I., Bifet, A., Pechenizkiy, M., Bouchachia, A.,
-
[13]
García-Teodoro, P., Díaz-Verdejo, J., Maciá-Fernández, G., & Vázquez, E
A survey on concept drift adaptation. ACM Computing Surveys 46, 44:1–44:37. doi:10.1145/2523813. Géron, A.,
-
[14]
Machine Learning 106, 1469–1495
Adaptive random forests for evolving data stream classification. Machine Learning 106, 1469–1495. doi:10.1007/s10994-017-5642-8. Hancock, J.T., Khoshgoftaar, T.M.,
-
[15]
Haque, A., Khan, L., Baron, M.,
URL:https://doi.org/ 10.1186/s40537-020-00305-w, doi:10.1186/s40537-020-00305-w. Haque, A., Khan, L., Baron, M.,
-
[16]
Hastie, T., Tibshirani, R., Friedman, J.,
doi:10.1609/aaai.v30i1.10283. Hastie, T., Tibshirani, R., Friedman, J.,
-
[17]
The Elements of Statistical Learning: Data Mining, Inference, and Prediction. 2 ed., Springer. doi:10.1007/978-0-387-21606-5. Hinder, F., Vaquet, V., Hammer, B.,
- [18]
-
[19]
Applied Logistic Regression. Wiley. doi:10.1002/0471722146. James, G., Witten, D., Hastie, T., Tibshirani, R.,
-
[20]
An Introduction to Statistical Learning: with Applications in R. Springer, New York. doi:10.1007/978-1-4614-7138-7. Kam Hamidieh,
-
[21]
On handling concept drift, calibration and explainability in non-stationary environments and resources limited contexts, in: Proceedings of the 16th International Conference on Agents and Artificial Intelligence, pp. 336–346. doi:10.5220/0012382200003636. Khannouz,M.,Glatard,T.,2020. Abenchmarkofdatastreamclassificationforhumanactivityrecognitiononconnect...
-
[22]
Statistical Analysis with Missing Data. 2 ed., Wiley. doi:10.1002/9781119013563. Liu, A., Lu, J., Zhang, G.,
-
[23]
IEEE Transactions on Cybernetics 51, 3198–3211
Concept drift detection via equal intensity k-means space partitioning. IEEE Transactions on Cybernetics 51, 3198–3211. doi:10.1109/TCYB.2020.2983962. Liu, A., Song, Y., Zhang, G., Lu, J.,
-
[24]
Regional concept drift detection and density synchronized drift adaptation. Proceedings of the Twenty- Sixth International Joint Conference on Artificial Intelligence , 2280–2286doi:10.24963/ijcai.2017/317. Losing, V., Hammer, B., Wersing, H.,
-
[25]
Incremental on-line learning: A review and comparison of the state of the art algorithms. Neurocomputing 275, 1261–1274. doi:10.1016/j.neucom.2017.06.084. Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., Zhang, G.,
-
[26]
IEEE Transactions on Knowledge and Data Engineering 31, 2346–2363
Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering 31, 2346–2363. doi:10.1109/TKDE.2018.2876857. :Preprint submitted to Elsevier Page 64 of 65 Cluster-Specific Localized Drift Detection for Efficient Batch Model Adaptation under Controlled Distribution Shift Mehmood,H.,Kostakos,P.,Cortes,M.,Anagnostopoulos,T.,Pirtt...
-
[27]
Online bagging and boosting, in: Proceedings of the IEEE International Conference on Systems, Man and Cybernetics, pp. 2340–2345. doi:10.1109/ICSMC.2005.1571498. Pesaranghader, A., Viktor, H.L., Paquet, E.,
-
[28]
McDiarmid drift detection methods for evolving data streams, in: 2018 International Joint Conference on Neural Networks (IJCNN), pp. 1–9. doi:10.1109/IJCNN.2018.8489260. Read, J., Bifet, A., Pfahringer, B., Holmes, G.,
-
[29]
Batch-incremental versus instance-incremental learning in dynamic and evolving data, in: Advances in Intelligent Data Analysis XI, Springer. pp. 313–323. doi:10.1007/978-3-642-34156-4\_29. Ross, G.J., Adams, N.M., Tasoulis, D.K., Hand, D.J.,
-
[30]
Exponentially weighted moving average charts for detecting concept drift
Exponentially weighted moving average charts for detecting concept drift. Pattern Recognition Letters 33, 191–198. doi:10.1016/j.patrec.2011.08.019. Schlimmer, J.C., Granger, R.H.,
-
[31]
Incremental learning from noisy data. Machine Learning 1, 317–354. doi:10.1007/BF00116895. Sethi, T.S., Kantardzic, M.,
-
[32]
Expert Systems with Applications 82, 77–99
On the reliable detection of concept drift from streaming unlabeled data. Expert Systems with Applications 82, 77–99. doi:10.1016/j.eswa.2017.04.008. Souza,V.M.A.,dosReis,D.M.,Maletzke,A.G.,Batista,G.E.A.P.A.,2020. Challengesinbenchmarkingstreamlearningalgorithmswithreal-world data. Data Mining and Knowledge Discovery 34, 1805–1858. doi:10.1007/s10618-020...
-
[33]
OLINDDA: A cluster-based approach for detecting novelty and concept drift in data streams, in: Proceedings of the 2007 ACM Symposium on Applied Computing, ACM. pp. 448–452. doi:10.1145/1244002.1244107. Street, W.N., Kim, Y.,
-
[34]
A streaming ensemble algorithm (SEA) for large-scale classification, in: Proceedings of the Seventh ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM. pp. 377–382. doi:10.1145/502512.502568. Street,W.N.,Wolberg,W.H.,Mangasarian,O.L.,1993. Nuclearfeatureextractionforbreasttumordiagnosis,in:BiomedicalImageProcessingand Biomedic...
-
[35]
URL:https://archive.ics.uci.edu/dataset/291, doi:10.24432/C5VW2C
Airfoil Self-Noise. URL:https://archive.ics.uci.edu/dataset/291, doi:10.24432/C5VW2C. Vinagre, J., Jorge, A.M., Gama, J.,
-
[36]
Evaluation of recommender systems in streaming environments, in: Proceedings of the 9th Workshop on Real-Time Business Intelligence and Analytics, pp. 1–8. doi:10.1145/2611286.2611299. Wang, H., Fan, W., Yu, P.S., Han, J.,
-
[37]
Mining concept-drifting data streams using ensemble classifiers, in: Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, ACM. pp. 226–235. doi:10.1145/956750.956778. Webb,G.I.,Hyde,R.,Cao,H.,Nguyen,H.L.,Petitjean,F.,2016. Characterizingconceptdrift. DataMiningandKnowledgeDiscovery30,964–994. doi:10.1007/s10...
-
[38]
Learning under Concept Drift: an Overview
Learning under concept drift: An overview. arXiv preprint arXiv:1010.4784. doi:10.48550/arXiv.1010.4784. Žliobait˙e, I., Bifet, A., Pfahringer, B., Holmes, G.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1010.4784
-
[39]
IEEE Transactions on Neural Networks and Learning Systems 25, 27–39
Active learning with drifting streaming data. IEEE Transactions on Neural Networks and Learning Systems 25, 27–39. doi:10.1109/TNNLS.2012.2236570. :Preprint submitted to Elsevier Page 65 of 65 Cluster-Specific Localized Drift Detection for Efficient Batch Model Adaptation under Controlled Distribution Shift Figure 10:Mean update training time across bench...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.