Direction-Magnitude Decomposition for Low-Rank Matrix Optimization: Faster Convergence and Saddle-to-saddle Dynamics
Pith reviewed 2026-07-01 05:00 UTC · model grok-4.3
The pith
Direction-magnitude decomposition speeds low-rank matrix optimization by splitting variables into direction and magnitude parts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
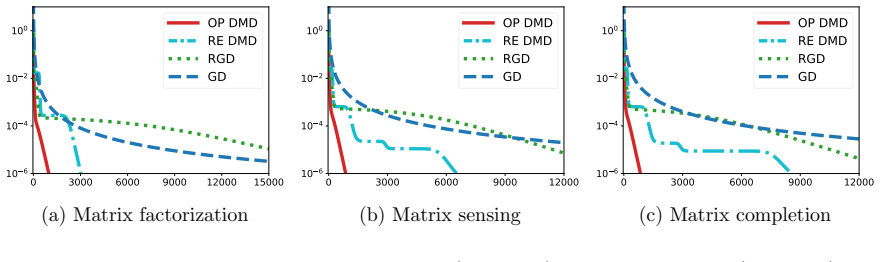
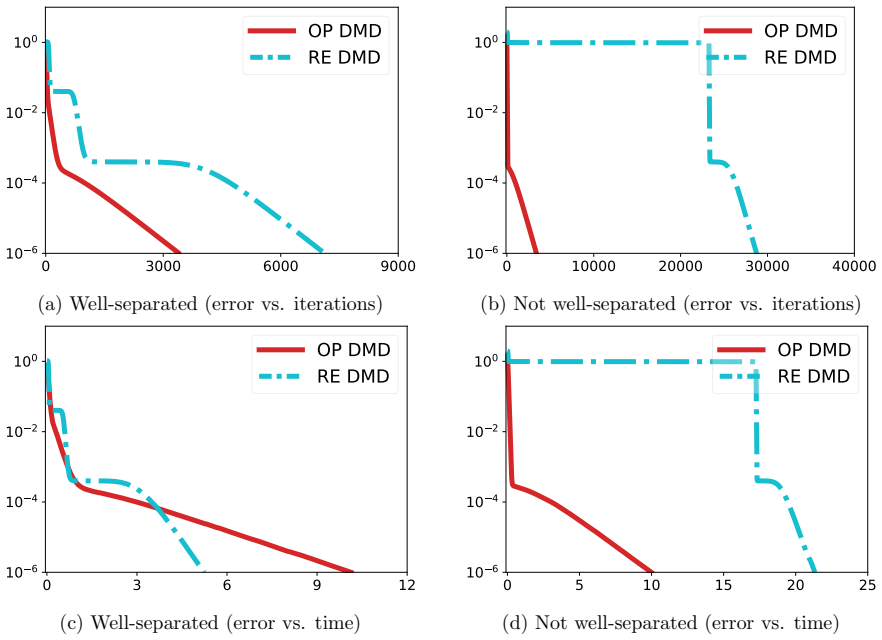
Direction-magnitude decomposition decomposes the optimization variable to improve optimization efficiency even when the target rank is unknown. The overparameterized version enjoys faster convergence as the factorization rank increases. The recursive version achieves lower memory and computational costs by following incremental eigenpair learning. Both are exponentially faster than gradient descent applied to the Burer-Monteiro formulation on matrix factorization.
What carries the argument
Direction-magnitude decomposition (DMD), a framework that splits each optimization variable into a direction component and a magnitude component.
If this is right
- Overparameterized DMD converges faster with increasing factorization rank.
- Recursive DMD reduces memory and per-iteration cost while retaining the same dynamics.
- Both variants apply directly to matrix sensing and completion tasks.
- The saddle-to-saddle trajectory explains the observed acceleration.
Where Pith is reading between the lines
- The same split could be tested on other non-convex factorized problems such as tensor decomposition.
- The incremental construction in recursive DMD may generalize to online or streaming low-rank settings.
- If the exponential speedup holds beyond matrix factorization, it would reduce the practical need for rank tuning in large-scale applications.
Load-bearing premise
The decomposition must preserve the critical points and overall convergence behavior of the original low-rank problem.
What would settle it
A matrix factorization instance where either DMD variant requires at least as many iterations as plain gradient descent on the Burer-Monteiro form to reach the same accuracy.
Figures


read the original abstract
Low-rank matrix optimization is often carried out via the Burer-Monteiro (BM) formulation, but choosing the factorization rank $r$ is delicate and can substantially slow optimization. We propose a unified framework, termed direction-magnitude decomposition (DMD), that decomposes the optimization variable to improve optimization efficiency even when the target rank is unknown. We develop two DMD-based approaches and establish their theoretical advantages on the canonical problem of matrix factorization. The first, overparameterized DMD, uses a rank $r$ larger than necessary and enjoys faster convergence as $r$ increases. The second, recursive DMD, is motivated by the incremental eigenpair learning, or saddle-to-saddle, behavior of overparameterized DMD. It achieves lower memory and computational costs, complementing overparameterized DMD. Both approaches are exponentially faster than gradient descent applied to the BM formulation. Numerical experiments on matrix factorization, sensing, and completion corroborate our theoretical findings and demonstrate the practical effectiveness of DMD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a direction-magnitude decomposition (DMD) framework for low-rank matrix optimization problems. It develops an overparameterized DMD variant that uses a factorization rank larger than the target and a recursive DMD variant motivated by saddle-to-saddle dynamics. Both are claimed to achieve exponentially faster convergence than gradient descent on the Burer-Monteiro (BM) factorization while solving the same underlying low-rank problem, with supporting numerical experiments on factorization, sensing, and completion tasks.
Significance. If the claimed invariance of critical points and saddle structure under DMD, together with the exponential rate improvements, are rigorously established, the work would offer a practically useful and theoretically grounded alternative to standard BM approaches for low-rank problems where rank selection is uncertain. The explicit treatment of saddle-to-saddle behavior and the recursive variant's memory savings are potential strengths.
major comments (2)
- [§3 (theoretical development of overparameterized DMD)] The central exponential-speedup claim relative to BM gradient descent rests on DMD preserving the critical-point set, stability, and local linearization (hence the rate) of the original problem. No explicit invariance argument, Hessian comparison, or proof that the direction-magnitude split introduces neither new stationary points nor altered negative-curvature directions is visible; without this, the rate comparison does not follow even if global minimizers coincide.
- [§4 (recursive DMD and saddle-to-saddle analysis)] The recursive DMD variant is motivated by the saddle-to-saddle trajectory of the overparameterized version, yet the manuscript supplies no quantitative comparison of the escape times or the linearization at saddles between the two DMD formulations and plain BM-GD. This gap directly affects whether the exponential improvement asserted in the abstract holds for the recursive case.
minor comments (2)
- [§2] Notation for the direction and magnitude variables is introduced without a consolidated table; readers must cross-reference multiple definitions when verifying the claimed equivalence to the original low-rank objective.
- [§5] The numerical experiments report wall-clock times and iteration counts but omit standard deviations or the number of random seeds; this weakens the corroboration of the theoretical exponential claims.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We appreciate the positive assessment of the potential contributions and address the major comments below. We agree that greater explicitness on invariance properties and quantitative comparisons would strengthen the paper and will revise accordingly.
read point-by-point responses
-
Referee: [§3 (theoretical development of overparameterized DMD)] The central exponential-speedup claim relative to BM gradient descent rests on DMD preserving the critical-point set, stability, and local linearization (hence the rate) of the original problem. No explicit invariance argument, Hessian comparison, or proof that the direction-magnitude split introduces neither new stationary points nor altered negative-curvature directions is visible; without this, the rate comparison does not follow even if global minimizers coincide.
Authors: We agree that an explicit invariance argument is needed to rigorously justify the rate claims. The DMD reparameterization is constructed so that the objective value is identical to the BM formulation for any choice of direction and magnitude variables, implying that global minimizers coincide and that stationary points map directly. However, we acknowledge that a self-contained proof comparing the Hessians and confirming that negative-curvature directions are preserved (up to positive scaling) is not isolated as a lemma. In the revision we will insert a new proposition in §3 that (i) shows the critical-point sets are in bijection, (ii) establishes that the Hessian of the DMD objective is congruent to that of BM via a block-diagonal positive-definite transformation, and (iii) verifies that the number and signs of negative eigenvalues at each saddle are identical. This will make the exponential-rate comparison immediate from the existing local linearization analysis. revision: yes
-
Referee: [§4 (recursive DMD and saddle-to-saddle analysis)] The recursive DMD variant is motivated by the saddle-to-saddle trajectory of the overparameterized version, yet the manuscript supplies no quantitative comparison of the escape times or the linearization at saddles between the two DMD formulations and plain BM-GD. This gap directly affects whether the exponential improvement asserted in the abstract holds for the recursive case.
Authors: We agree that quantitative escape-time bounds and explicit linearization comparisons for the recursive variant versus BM-GD would strengthen the claims. The current §4 derives the recursive scheme from the observed incremental eigenpair learning of the overparameterized flow and proves memory reduction, but does not supply explicit escape-time estimates. In the revision we will add (i) a corollary bounding the time to escape each saddle in the recursive DMD by the reciprocal of the smallest negative eigenvalue of the overparameterized linearization (which is already shown to be strictly larger in magnitude than the corresponding BM eigenvalue), and (ii) a short numerical subsection comparing measured escape times and overall convergence rates on the same test instances used for the overparameterized case. These additions will confirm that the exponential improvement carries over to the recursive formulation. revision: yes
Circularity Check
No circularity detected; derivation chain is self-contained
full rationale
The paper introduces DMD as a new decomposition, then analyzes two variants (overparameterized and recursive) to claim exponential speedup over BM-GD on matrix factorization. No quoted step reduces a prediction to a fitted input by construction, renames a known result, or relies on a load-bearing self-citation whose content is itself unverified. The preservation of critical points is asserted as part of the framework development rather than derived tautologically from the target rates. The analysis therefore stands as independent content relative to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Principal component analysis.Wiley interdisciplinary reviews: com- putational statistics, 2(4):433–459, 2010
Herv´ e Abdi and Lynne J Williams. Principal component analysis.Wiley interdisciplinary reviews: com- putational statistics, 2(4):433–459, 2010
2010
-
[2]
Prince- ton University Press, 2008
P-A Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization algorithms on matrix manifolds. Prince- ton University Press, 2008
2008
-
[3]
Tensor decom- positions for learning latent variable models.The Journal of Machine Learning Research, 15(1):2773–2832, 2014
Animashree Anandkumar, Rong Ge, Daniel Hsu, Sham M Kakade, and Matus Telgarsky. Tensor decom- positions for learning latent variable models.The Journal of Machine Learning Research, 15(1):2773–2832, 2014
2014
-
[4]
Streaming PCA and subspace tracking: The missing data case
Laura Balzano, Yuejie Chi, and Yue M Lu. Streaming PCA and subspace tracking: The missing data case. Proceedings of the IEEE, 106(8):1293–1310, 2018
2018
-
[5]
John Wiley & Sons, 2013
Harrison H Barrett and Kyle J Myers.Foundations of image science. John Wiley & Sons, 2013
2013
-
[6]
Numerical methods for computing angles between linear subspaces.Math- ematics of Computation, 27(123):579–594, 1973
˚Ake Bj¨ orck and Gene H Golub. Numerical methods for computing angles between linear subspaces.Math- ematics of Computation, 27(123):579–594, 1973
1973
-
[7]
Cambridge University Press, 2023
Nicolas Boumal.An introduction to optimization on smooth manifolds. Cambridge University Press, 2023
2023
-
[8]
A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization.Mathematical Programming, 95(2):329–357, 2003
Samuel Burer and Renato DC Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization.Mathematical Programming, 95(2):329–357, 2003
2003
-
[9]
Exact matrix completion via convex optimization.Communica- tions of the ACM, 55(6):111–119, 2012
Emmanuel Candes and Benjamin Recht. Exact matrix completion via convex optimization.Communica- tions of the ACM, 55(6):111–119, 2012
2012
-
[10]
Phaselift: Exact and stable signal recovery from magnitude measurements via convex programming.Communications on Pure and Applied Mathematics, 66(8):1241–1274, 2013
Emmanuel J Candes, Thomas Strohmer, and Vladislav Voroninski. Phaselift: Exact and stable signal recovery from magnitude measurements via convex programming.Communications on Pure and Applied Mathematics, 66(8):1241–1274, 2013
2013
-
[11]
Jian Cao, Chen Qian, Yihui Huang, Dicheng Chen, Yuncheng Gao, Jiyang Dong, Di Guo, and Xiaobo Qu. A dynamics theory of implicit regularization in deep low-rank matrix factorization.arXiv preprint arXiv:2212.14150, 2022
-
[12]
Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence
Vasileios Charisopoulos, Yudong Chen, Damek Davis, Mateo D´ ıaz, Lijun Ding, and Dmitriy Drusvy- atskiy. Low-rank matrix recovery with composite optimization: good conditioning and rapid convergence. Foundations of Computational Mathematics, 21(6):1505–1593, 2021. 15
2021
-
[13]
Decentralized Riemannian gra- dient descent on the Stiefel manifold
Shixiang Chen, Alfredo Garcia, Mingyi Hong, and Shahin Shahrampour. Decentralized Riemannian gra- dient descent on the Stiefel manifold. InInternational Conference on Machine Learning, pages 1594–1605. PMLR, 2021
2021
-
[14]
Nonconvex optimization meets low-rank matrix factorization: An overview.IEEE Transactions on Signal Processing, 67(20):5239–5269, 2019
Yuejie Chi, Yue M Lu, and Yuxin Chen. Nonconvex optimization meets low-rank matrix factorization: An overview.IEEE Transactions on Signal Processing, 67(20):5239–5269, 2019
2019
-
[15]
Springer Science & Business Media, 2012
Yasuko Chikuse.Statistics on Special Manifolds, volume 174. Springer Science & Business Media, 2012
2012
-
[16]
Flat minima generalize for low-rank matrix recovery.Information and Inference: A Journal of the IMA, 13(2):iaae009, 2024
Lijun Ding, Dmitriy Drusvyatskiy, Maryam Fazel, and Zaid Harchaoui. Flat minima generalize for low-rank matrix recovery.Information and Inference: A Journal of the IMA, 13(2):iaae009, 2024
2024
-
[17]
Conic descent and its application to memory- efficient optimization over positive semidefinite matrices.Advances in Neural Information Processing Sys- tems, 33:8308–8317, 2020
John C Duchi, Oliver Hinder, Andrew Naber, and Yinyu Ye. Conic descent and its application to memory- efficient optimization over positive semidefinite matrices.Advances in Neural Information Processing Sys- tems, 33:8308–8317, 2020
2020
-
[18]
High-rank matrix completion
Brian Eriksson, Laura Balzano, and Robert Nowak. High-rank matrix completion. InArtificial Intelligence and Statistics, pages 373–381. PMLR, 2012
2012
-
[19]
On a theorem of weyl concerning eigenvalues of linear transformations i.Proceedings of the National Academy of Sciences, 35(11):652–655, 1949
Ky Fan. On a theorem of weyl concerning eigenvalues of linear transformations i.Proceedings of the National Academy of Sciences, 35(11):652–655, 1949
1949
-
[20]
Courier Corporation, 2000
Joel N Franklin.Matrix theory. Courier Corporation, 2000
2000
-
[21]
Riemannian optimization on the symplectic Stiefel manifold.SIAM Journal on Optimization, 31(2):1546–1575, 2021
Bin Gao, Nguyen Thanh Son, P-A Absil, and Tatjana Stykel. Riemannian optimization on the symplectic Stiefel manifold.SIAM Journal on Optimization, 31(2):1546–1575, 2021
2021
-
[22]
No spurious local minima in nonconvex low rank problems: A unified geometric analysis
Rong Ge, Chi Jin, and Yi Zheng. No spurious local minima in nonconvex low rank problems: A unified geometric analysis. InInternational Conference on Machine Learning, pages 1233–1242. PMLR, 2017
2017
-
[23]
Understanding deflation process in over-parametrized tensor decomposition.Advances in Neural Information Processing Systems, 34:1299–1311, 2021
Rong Ge, Yunwei Ren, Xiang Wang, and Mo Zhou. Understanding deflation process in over-parametrized tensor decomposition.Advances in Neural Information Processing Systems, 34:1299–1311, 2021
2021
-
[24]
A generalization of the Eckart-Young-Mirsky matrix approximation theorem.Linear Algebra and its Applications, 88:317–327, 1987
Gene H Golub, Alan Hoffman, and Gilbert W Stewart. A generalization of the Eckart-Young-Mirsky matrix approximation theorem.Linear Algebra and its Applications, 88:317–327, 1987
1987
-
[25]
JHU press, 2013
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
2013
-
[26]
Principal component analysis.Nature Reviews Methods Primers, 2(1):100, 2022
Michael Greenacre, Patrick JF Groenen, Trevor Hastie, Alfonso Iodice d’Enza, Angelos Markos, and Elena Tuzhilina. Principal component analysis.Nature Reviews Methods Primers, 2(1):100, 2022
2022
-
[27]
SIAM, 2002
Philip Hartman.Ordinary differential equations. SIAM, 2002
2002
-
[28]
Neural collaborative filtering
Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neural collaborative filtering. InProceedings of the 26th International Conference on World Wide Web, pages 173–182, 2017
2017
-
[29]
Solving ptychography with a convex relaxation.New Journal of Physics, 17(5):053044, 2015
Roarke Horstmeyer, Richard Y Chen, Xiaoze Ou, Brendan Ames, Joel A Tropp, and Changhuei Yang. Solving ptychography with a convex relaxation.New Journal of Physics, 17(5):053044, 2015
2015
-
[30]
Analysis of asymptotic escape of strict saddle sets in manifold optimization.SIAM Journal on Mathematics of Data Science, 2(3):840–871, 2020
Thomas Y Hou, Zhenzhen Li, and Ziyun Zhang. Analysis of asymptotic escape of strict saddle sets in manifold optimization.SIAM Journal on Mathematics of Data Science, 2(3):840–871, 2020
2020
-
[31]
Lora: Low-rank adaptation of large language models.International Conference on Learning Representations, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.International Conference on Learning Representations, 1(2):3, 2022
2022
-
[32]
Algorithmic regularization in model-free overparametrized asymmetric matrix factorization.SIAM Journal on Mathematics of Data Science, 5(3):723–744, 2023
Liwei Jiang, Yudong Chen, and Lijun Ding. Algorithmic regularization in model-free overparametrized asymmetric matrix factorization.SIAM Journal on Mathematics of Data Science, 5(3):723–744, 2023
2023
-
[33]
Understanding incremental learning of gradient descent: A fine-grained analysis of matrix sensing
Jikai Jin, Zhiyuan Li, Kaifeng Lyu, Simon Shaolei Du, and Jason D Lee. Understanding incremental learning of gradient descent: A fine-grained analysis of matrix sensing. InInternational Conference on Machine Learning, pages 15200–15238. PMLR, 2023
2023
-
[34]
Matrix completion from a few entries
Raghunandan H Keshavan, Andrea Montanari, and Sewoong Oh. Matrix completion from a few entries. IEEE Transactions on Information Theory, 56(6):2980–2998, 2010
2010
-
[35]
Equivariant dimen- sionality reduction on Stiefel manifolds.SIAM Journal on Mathematics of Data Science, 7(2):410–437, 2025
Andrew Lee, Harlin Lee, Jose A Perea, Nikolas Schonsheck, and Madeleine Weinstein. Equivariant dimen- sionality reduction on Stiefel manifolds.SIAM Journal on Mathematics of Data Science, 7(2):410–437, 2025
2025
-
[36]
The effect of smooth parametrizations on nonconvex opti- mization landscapes.Mathematical Programming, 209(1):63–111, 2025
Eitan Levin, Joe Kileel, and Nicolas Boumal. The effect of smooth parametrizations on nonconvex opti- mization landscapes.Mathematical Programming, 209(1):63–111, 2025
2025
-
[37]
On the crucial role of initialization for matrix factorization
Bingcong Li, Liang Zhang, Aryan Mokhtari, and Niao He. On the crucial role of initialization for matrix factorization. InInternational Conference on Learning Representations, 2025
2025
-
[38]
Low-Rank Adaptation Redux for Large Models
Bingcong Li, Yilang Zhang, and Georgios B Giannakis. Low-rank adaptation redux for large models.arXiv preprint arXiv:2604.21905, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
The landscape of non-convex empirical risk with degen- erate population risk.Advances in Neural Information Processing Systems, 32, 2019
Shuang Li, Gongguo Tang, and Michael B Wakin. The landscape of non-convex empirical risk with degen- erate population risk.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[40]
Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations
Yuanzhi Li, Tengyu Ma, and Hongyang Zhang. Algorithmic regularization in over-parameterized matrix sensing and neural networks with quadratic activations. InConference on Learning Theory, pages 2–47. PMLR, 2018. 16
2018
-
[41]
Convergence and complexity of block majorization-minimization for constrained block-Riemannian optimization.Journal of Machine Learning Research, 27(42):1–77, 2026
Yuchen Li, Laura Balzano, Deanna Needell, and Hanbaek Lyu. Convergence and complexity of block majorization-minimization for constrained block-Riemannian optimization.Journal of Machine Learning Research, 27(42):1–77, 2026
2026
-
[42]
Zhiyuan Li, Yuping Luo, and Kaifeng Lyu. Towards resolving the implicit bias of gradient descent for matrix factorization: Greedy low-rank learning.arXiv preprint arXiv:2012.09839, 2020
-
[43]
Polar: Polar-decomposed low-rank adapter represen- tation
Kai Lion, Liang Zhang, Bingcong Li, and Niao He. Polar: Polar-decomposed low-rank adapter represen- tation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[44]
Online matrix factorization for markovian data and applications to network dictionary learning.Journal of Machine Learning Research, 21(251):1–49, 2020
Hanbaek Lyu, Deanna Needell, and Laura Balzano. Online matrix factorization for markovian data and applications to network dictionary learning.Journal of Machine Learning Research, 21(251):1–49, 2020
2020
-
[45]
Over-parametrization via lifting for low-rank matrix sensing: Conversion of spurious solutions to strict saddle points
Ziye Ma, Igor Molybog, Javad Lavaei, and Somayeh Sojoudi. Over-parametrization via lifting for low-rank matrix sensing: Conversion of spurious solutions to strict saddle points. InInternational Conference on Machine Learning, pages 23373–23387. PMLR, 2023
2023
-
[46]
A Riemannian geometry for low-rank matrix completion
Bamdev Mishra, K Adithya Apuroop, and Rodolphe Sepulchre. A Riemannian geometry for low-rank matrix completion.arXiv preprint arXiv:1211.1550, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[47]
John Wiley & Sons, 2009
Robb J Muirhead.Aspects of multivariate statistical theory. John Wiley & Sons, 2009
2009
-
[48]
Tensor methods for nonlinear matrix completion.SIAM Journal on Mathematics of Data Science, 3(1):253–279, 2021
Greg Ongie, Daniel Pimentel-Alarc´ on, Laura Balzano, Rebecca Willett, and Robert D Nowak. Tensor methods for nonlinear matrix completion.SIAM Journal on Mathematics of Data Science, 3(1):253–279, 2021
2021
-
[49]
Adaptive gradient descent on Riemannian manifolds and its applications to gaussian variational inference
Jiyoung Park, Jaewook J Suh, Bofan Wang, Anirban Bhattacharya, and Shiqian Ma. Adaptive gradient descent on Riemannian manifolds and its applications to gaussian variational inference. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[50]
A flexible growth function for empirical use.Journal of experimental Botany, 10(2):290– 301, 1959
Francis J Richards. A flexible growth function for empirical use.Journal of experimental Botany, 10(2):290– 301, 1959
1959
-
[51]
Mark Rudelson and Roman Vershynin. Smallest singular value of a random rectangular matrix.Commu- nications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences, 62(12):1707–1739, 2009
2009
-
[52]
Collaborative filtering recommender systems
J Ben Schafer, Dan Frankowski, Jon Herlocker, and Shilad Sen. Collaborative filtering recommender systems. InThe adaptive web: methods and strategies of web personalization, pages 291–324. Springer, 2007
2007
-
[53]
Mohamed El Amine Seddik, Mohammed Mahfoud, and Merouane Debbah. Optimizing orthogonalized tensor deflation via random tensor theory.arXiv preprint arXiv:2302.05798, 2023
-
[54]
Tianqi Shen, Jinji Yang, Junze He, Kunhan Gao, and Ziye Ma. Escaping local minima provably in non- convex matrix sensing: A deterministic framework via simulated lifting.arXiv preprint arXiv:2602.05887, 2026
-
[55]
Optimization Techniques on Riemannian Manifolds
Steven Thomas Smith. Optimization techniques on Riemannian manifolds.arXiv preprint arXiv:1407.5965, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[56]
Collaborative filtering in a non-uniform world: Learning with the weighted trace norm.Advances in Neural Information Processing Systems, 23, 2010
Nathan Srebro and Russ R Salakhutdinov. Collaborative filtering in a non-uniform world: Learning with the weighted trace norm.Advances in Neural Information Processing Systems, 23, 2010
2010
-
[57]
Dominik St¨ oger and Mahdi Soltanolkotabi. Small random initialization is akin to spectral learning: Op- timization and generalization guarantees for overparameterized low-rank matrix reconstruction.Advances in Neural Information Processing Systems, 34:23831–23843, 2021
2021
-
[58]
Notes on optimization on Stiefel manifolds.Yale University, New Haven, 2011
Hemant D Tagare. Notes on optimization on Stiefel manifolds.Yale University, New Haven, 2011
2011
-
[59]
Rank minimization over finite fields: Fundamental limits and coding-theoretic interpretations.IEEE Transactions on Information Theory, 58(4):2018–2039, 2011
Vincent YF Tan, Laura Balzano, and Stark C Draper. Rank minimization over finite fields: Fundamental limits and coding-theoretic interpretations.IEEE Transactions on Information Theory, 58(4):2018–2039, 2011
2018
-
[60]
Semidefinite optimization.Acta Numerica, 10:515–560, 2001
Michael J Todd. Semidefinite optimization.Acta Numerica, 10:515–560, 2001
2001
-
[61]
Accelerating ill-conditioned low-rank matrix estimation via scaled gradient descent.Journal of Machine Learning Research, 22(150):1–63, 2021
Tian Tong, Cong Ma, and Yuejie Chi. Accelerating ill-conditioned low-rank matrix estimation via scaled gradient descent.Journal of Machine Learning Research, 22(150):1–63, 2021
2021
-
[62]
Practical sketching algorithms for low-rank matrix approximation.SIAM Journal on Matrix Analysis and Applications, 38(4):1454–1485, 2017
Joel A Tropp, Alp Yurtsever, Madeleine Udell, and Volkan Cevher. Practical sketching algorithms for low-rank matrix approximation.SIAM Journal on Matrix Analysis and Applications, 38(4):1454–1485, 2017
2017
-
[63]
Why are big data matrices approximately low rank?SIAM Journal on Mathematics of Data Science, 1(1):144–160, 2019
Madeleine Udell and Alex Townsend. Why are big data matrices approximately low rank?SIAM Journal on Mathematics of Data Science, 1(1):144–160, 2019
2019
-
[64]
Semidefinite programming.SIAM review, 38(1):49–95, 1996
Lieven Vandenberghe and Stephen Boyd. Semidefinite programming.SIAM review, 38(1):49–95, 1996
1996
-
[65]
Introduction to the non-asymptotic analysis of random matrices
Roman Vershynin. Introduction to the non-asymptotic analysis of random matrices.arXiv preprint arXiv:1011.3027, 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[66]
Graph learning based recommender systems: A review.arXiv preprint arXiv:2105.06339, 2021
Shoujin Wang, Liang Hu, Yan Wang, Xiangnan He, Quan Z Sheng, Mehmet A Orgun, Longbing Cao, Francesco Ricci, and Philip S Yu. Graph learning based recommender systems: A review.arXiv preprint arXiv:2105.06339, 2021. 17
-
[67]
On the benefits of weight normalization for over- parameterized matrix sensing
Yudong Wei, Liang Zhang, Bingcong Li, and Niao He. On the benefits of weight normalization for over- parameterized matrix sensing. InInternational Conference on Learning Representations, 2025
2025
-
[68]
Graph learning: A survey.IEEE Transactions on Artificial Intelligence, 2(2):109–127, 2021
Feng Xia, Ke Sun, Shuo Yu, Abdul Aziz, Liangtian Wan, Shirui Pan, and Huan Liu. Graph learning: A survey.IEEE Transactions on Artificial Intelligence, 2(2):109–127, 2021
2021
-
[69]
How over-parameterization slows down gradient descent in matrix sensing: The curses of symmetry and initialization
Nuoya Xiong, Lijun Ding, and Simon Shaolei Du. How over-parameterization slows down gradient descent in matrix sensing: The curses of symmetry and initialization. InInternational Conference on Learning Representations, 2024
2024
-
[70]
The power of preconditioning in overparameterized low-rank matrix sensing
Xingyu Xu, Yandi Shen, Yuejie Chi, and Cong Ma. The power of preconditioning in overparameterized low-rank matrix sensing. InInternational Conference on Machine Learning, pages 38611–38654. PMLR, 2023
2023
-
[71]
Global convergence of gradient descent for asymmetric low-rank matrix factor- ization.Advances in Neural Information Processing Systems, 34:1429–1439, 2021
Tian Ye and Simon S Du. Global convergence of gradient descent for asymmetric low-rank matrix factor- ization.Advances in Neural Information Processing Systems, 34:1429–1439, 2021
2021
-
[72]
A useful variant of the davis–kahan theorem for statis- ticians.Biometrika, 102(2):315–323, 2015
Yi Yu, Tengyao Wang, and Richard J Samworth. A useful variant of the davis–kahan theorem for statis- ticians.Biometrika, 102(2):315–323, 2015
2015
-
[73]
Scalable semidefinite programming.SIAM Journal on Mathematics of Data Science, 3(1):171–200, 2021
Alp Yurtsever, Joel A Tropp, Olivier Fercoq, Madeleine Udell, and Volkan Cevher. Scalable semidefinite programming.SIAM Journal on Mathematics of Data Science, 3(1):171–200, 2021
2021
-
[74]
Yedi Zhang, Andrew Saxe, and Peter E Latham. Saddle-to-saddle dynamics explains a simplicity bias across neural network architectures.arXiv preprint arXiv:2512.20607, 2025
-
[75]
Matrix completion with quantified uncertainty through low rank gaussian copula.Advances in Neural Information Processing Systems, 33:20977–20988, 2020
Yuxuan Zhao and Madeleine Udell. Matrix completion with quantified uncertainty through low rank gaussian copula.Advances in Neural Information Processing Systems, 33:20977–20988, 2020
2020
-
[76]
Efficient matrix sensing using rank-1 Gaussian measure- ments
Kai Zhong, Prateek Jain, and Inderjit S Dhillon. Efficient matrix sensing using rank-1 Gaussian measure- ments. InInternational Conference on Algorithmic Learning Theory, pages 3–18. Springer, 2015
2015
-
[77]
On the computational and statisti- cal complexity of over-parameterized matrix sensing.Journal of Machine Learning Research, 25(169):1–47, 2024
Jiacheng Zhuo, Jeongyeol Kwon, Nhat Ho, and Constantine Caramanis. On the computational and statisti- cal complexity of over-parameterized matrix sensing.Journal of Machine Learning Research, 25(169):1–47, 2024. 18 Appendix A. Deferred proofs A.1. Proof of Theorem 1. Proof.For simplicity, we takeη= cη(r−rA)2 mrrAκ , wherec η = 1 8c1 is a universal constan...
2024
-
[78]
We can easily verify thatX ⊤ +X+ =I r and the distance is d((X +,Θ +),(X,Θ)) = q ∥X+ −X∥ 2 F +∥Θ + −Θ∥ 2 F = q ∥(k−1)x 1 +su 1∥2 +ν 2 1 = q (k−1) 2 +s 2 +ν 2 1 ≤ r ν2 2 + ν2 4 ≤ν. The value of the objective function is f(X +,Θ +) = 1 4 ∥X+Θ+X⊤ + −A∥ 2 F = 1 4 ∥ −ν 1 k2x1x⊤ 1 +s 2u1u⊤ 1 − rAX j=1 λjuju⊤ j ∥2 F = 1 4 ∥ν1k2x1x⊤ 1 +ν 1s2u1u⊤ 1 + rAX j=1 λjuju...
-
[79]
It can be verified thatX ⊤ −X− =I r, and the distance is d((X −,Θ −),(X,Θ)) = q ∥X− −X∥ 2 F +∥Θ − −Θ∥ 2 F = q ∥(k−1)x 1 +su 1∥2 +ν 2 2 = q (k−1) 2 +s 2 +ν 2 2 ≤ r ν2 2 + ν2 4 ≤ν. 25 The value of the objective function is f(X −,Θ −) = 1 4 ∥X−Θ−X⊤ − −A∥ 2 F = 1 4 ∥ν2 k2x1x⊤ 1 +s 2u1u⊤ 1 − rAX j=1 λjuju⊤ j ∥2 F = 1 4 ∥ν2k2x1x⊤ 1 +ν 2s2u1u⊤ 1 − rAX j=1 λjuju⊤...
-
[80]
FromX⊥Y, we can writeE(e λ(X−Y) ) asE(e λX)E(e−λY )
=P(e λ(X−Y) ≥1) (a) ≤E(e λ(X−Y) ), where (a) is by Markov’s inequality. FromX⊥Y, we can writeE(e λ(X−Y) ) asE(e λX)E(e−λY ). Therefore,P(X−Y≥0)≤E(e λX)E(e−λY ).□ Lemma 29.Assuming− 1 4 ≤x≤ 1 4, thenlog(1 +x)≥x−x 2. Proof.Definef(x) := log(1 +x)−x+x 2,x∈[− 1 4 , 1 4]. 41 The derivative off(x) isf ′(x) = 1 1+x −1 + 2x= x+2x2 1+x . Sincex+ 2x 2 ( <0, x∈[− 1 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.