EventDrive: Event Cameras for Vision-Language Driving Intelligence
Pith reviewed 2026-06-27 01:24 UTC · model grok-4.3
The pith
Event cameras integrated with vision-language models deliver gains in temporal precision, motion awareness, and robustness for driving tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EventDrive unifies event streams, RGB frames, and language supervision across Perception, Understanding, Prediction, and Planning with tasks including captions, structured QA, grounding, motion-state recognition, trajectory forecasting, and planning; the accompanying EventDrive-VLM uses a multi-horizon event pyramid and temporal-horizon mixture-of-experts module to adaptively encode and fuse asynchronous event information with frame-based data, yielding substantial gains in temporal precision, motion awareness, and robustness.
What carries the argument
The multi-horizon event pyramid together with the temporal-horizon mixture-of-experts module that adaptively encodes asynchronous event data and fuses it with RGB frames for downstream reasoning.
If this is right
- Event streams improve accuracy on motion-state recognition and trajectory forecasting through higher temporal resolution.
- The same fusion approach increases robustness on perception and grounding tasks when conventional frames suffer from blur or glare.
- Planning and prediction modules receive more reliable motion cues, reducing errors that arise from missed temporal structure in RGB data alone.
- Event sensing moves from an optional complement to a central component in vision-language driving systems.
Where Pith is reading between the lines
- Hybrid event-RGB models could be tested in existing simulation environments to measure end-to-end latency reductions before hardware deployment.
- The benchmark tasks could be extended to include multi-agent interactions or long-horizon route planning to check whether gains persist beyond single-vehicle perception.
- Manufacturers might evaluate whether the added temporal precision justifies the cost and calibration overhead of adding event cameras to production sensor suites.
Load-bearing premise
The chosen tasks and four dimensions are assumed to serve as a representative proxy for the complete driving decision loop.
What would settle it
A closed-loop vehicle test in which EventDrive-VLM planning outputs are compared against RGB-only baselines on collision rate and task completion under rapid motion and varying illumination; absence of measurable improvement would falsify the central claim.
Figures

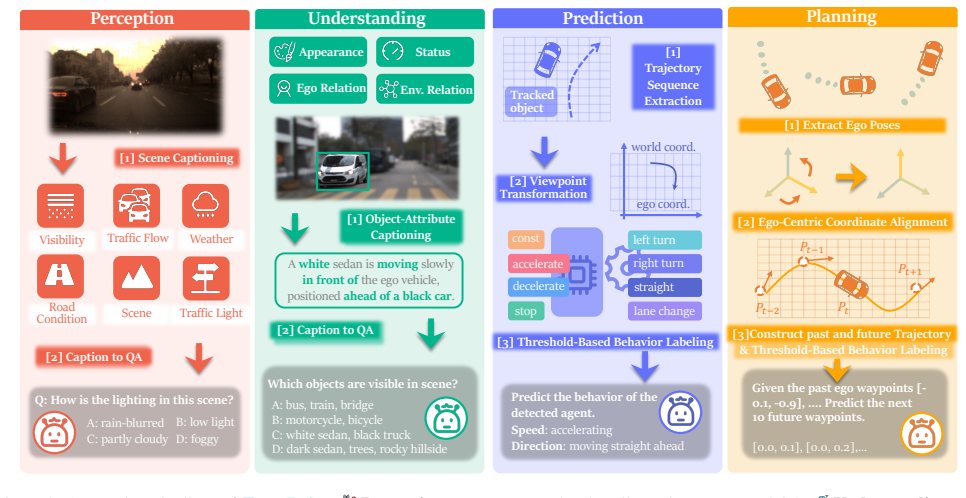
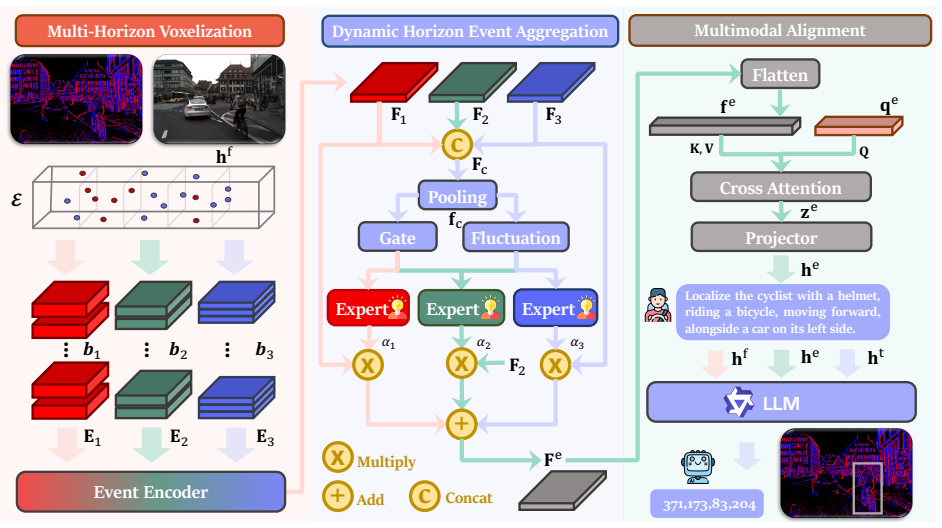










read the original abstract
Event cameras sense the world through asynchronous brightness changes with microsecond latency and high dynamic range, offering motion fidelity far beyond frame-based sensors and capturing temporal structure that conventional exposures often miss. These properties make events a powerful complement to RGB in autonomous driving, especially under blur, glare, and rapid motion, where frame-based perception can become unreliable. However, existing event-aware vision-language models remain limited to generic perception and do not reveal how event sensing contributes to reasoning and decision-making across the full driving loop. We present EventDrive, a large-scale benchmark and model suite that unifies event streams, RGB frames, and language supervision across four core dimensions: Perception, Understanding, Prediction, and Planning, covering captions, structured QA, grounding, motion-state recognition, trajectory forecasting, and planning tasks. Building on this foundation, EventDrive-VLM introduces a multi-horizon event pyramid and a temporal-horizon mixture-of-experts module to adaptively encode and fuse asynchronous and frame-based information for downstream reasoning. Comprehensive evaluation across diverse tasks shows that event streams provide substantial gains in temporal precision, motion awareness, and robustness, bringing event sensing into the center of driving intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EventDrive, a large-scale benchmark and model suite unifying event streams, RGB frames, and language supervision for autonomous driving across four dimensions (Perception, Understanding, Prediction, Planning) with tasks including captions, structured QA, grounding, motion-state recognition, trajectory forecasting, and planning. It proposes EventDrive-VLM featuring a multi-horizon event pyramid and temporal-horizon mixture-of-experts module for fusing asynchronous event data with frames, claiming that comprehensive evaluations demonstrate substantial gains from event streams in temporal precision, motion awareness, and robustness.
Significance. If the empirical gains hold under rigorous validation and the task suite adequately represents driving decision-making, the work could establish event cameras as a core modality in vision-language models for driving, extending their role from low-level perception to higher-level reasoning and planning under challenging conditions like blur and rapid motion.
major comments (1)
- [Abstract] Abstract and task selection section: the claim that event streams bring sensing 'into the center of driving intelligence' rests on the assumption that the four dimensions and six tasks (captions, QA, grounding, motion-state recognition, trajectory forecasting, planning) form a representative proxy for the full driving loop; however, these are open-loop proxies that omit closed-loop control, vehicle dynamics integration, and safety-critical decision metrics, so observed improvements in temporal precision do not establish the headline conclusion.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the scope of our benchmark. We agree that the evaluated tasks are open-loop proxies and will revise the abstract and task selection section to reflect this limitation more precisely while preserving the core contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract and task selection section: the claim that event streams bring sensing 'into the center of driving intelligence' rests on the assumption that the four dimensions and six tasks (captions, QA, grounding, motion-state recognition, trajectory forecasting, planning) form a representative proxy for the full driving loop; however, these are open-loop proxies that omit closed-loop control, vehicle dynamics integration, and safety-critical decision metrics, so observed improvements in temporal precision do not establish the headline conclusion.
Authors: We acknowledge the validity of this observation. Our benchmark explicitly frames the four dimensions (Perception, Understanding, Prediction, Planning) and six tasks as open-loop proxies that isolate the contribution of event data to temporal precision and motion reasoning without closed-loop simulation or vehicle dynamics. The headline phrasing in the abstract was intended to emphasize that event sensing enables higher-level reasoning within these core components of driving intelligence, which are necessary (though not sufficient) for the full loop. We agree the language risks overgeneralization. In revision we will (1) qualify the abstract claim to specify 'open-loop driving intelligence tasks' and (2) add a limitations paragraph clarifying the absence of closed-loop control and safety metrics. These changes preserve the empirical findings while aligning the narrative with the evaluated scope. revision: yes
Circularity Check
Empirical benchmark with no derivation chain or fitted predictions
full rationale
The paper introduces a benchmark and model suite (EventDrive) and reports empirical gains from evaluations on perception, understanding, prediction, and planning tasks. No equations, first-principles derivations, parameter fits, or predictions are described that could reduce to inputs by construction. Claims rest on observed performance differences across tasks rather than any self-referential or fitted structure. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, et al. LLaV A-OneVision- 1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Zheng Cai, Maosong Cao, Haojiong Chen, et al. InternLM2 technical report.arXiv preprint arXiv:2403.17297, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Hu Cao, Guang Chen, Zhijun Li, Yingbai Hu, and Alois Knoll. NeuroGrasp: multimodal neural network with euler region regression for neuromorphic vision-based grasp pose estimation.IEEE Transactions on Instrumentation and Mea- surement, 71:1–11, 2022
2022
-
[6]
Embracing events and frames with hierarchical feature refinement network for object detec- tion
Hu Cao, Zehua Zhang, Yan Xia, Xinyi Li, Jiahao Xia, Guang Chen, and Alois Knoll. Embracing events and frames with hierarchical feature refinement network for object detec- tion. InEuropean Conference on Computer Vision. Springer, 2024
2024
-
[7]
Recent event camera innovations: A survey
Bharatesh Chakravarthi, Aayush Atul Verma, Kostas Dani- ilidis, Cornelia Fermuller, and Yezhou Yang. Recent event camera innovations: A survey. InEuropean Conference on Computer Vision Workshops. Springer, 2024
2024
-
[8]
Ani Hsieh, Christopher Korpela, Vijay Ku- mar, Camillo J
Kenneth Chaney, Fernando Cladera, Ziyun Wang, Anthony Bisulco, M. Ani Hsieh, Christopher Korpela, Vijay Ku- mar, Camillo J. Taylor, and Kostas Daniilidis. M3ED: Multi-robot, multi-sensor, multi-environment event dataset. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 4016–4023, 2023
2023
-
[9]
Multi-cue event information fu- sion for pedestrian detection with neuromorphic vision sen- sors.Frontiers in Neurorobotics, 13:10, 2019
Guang Chen, Hu Cao, Canbo Ye, Zhenyan Zhang, Xingbo Liu, Xuhui Mo, Zhongnan Qu, J ¨org Conradt, Florian R¨ohrbein, and Alois Knoll. Multi-cue event information fu- sion for pedestrian detection with neuromorphic vision sen- sors.Frontiers in Neurorobotics, 13:10, 2019
2019
-
[10]
Pseudo-labels for supervised learning on dynamic vision sensor data, applied to object detection under ego-motion
Nicholas FY Chen. Pseudo-labels for supervised learning on dynamic vision sensor data, applied to object detection under ego-motion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 644–653, 2018
2018
-
[11]
CLIP2Scene: Towards label-efficient 3D scene under- standing by CLIP
Runnan Chen, Youquan Liu, Lingdong Kong, Xinge Zhu, Yuexin Ma, Yikang Li, Yuenan Hou, Yu Qiao, and Wenping Wang. CLIP2Scene: Towards label-efficient 3D scene under- standing by CLIP. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7020–7030, 2023
2023
-
[12]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to GPT-4V? closing the gap to commercial multimodal models with open-source suites.arXiv preprint arXiv:2404.16821, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
InternVL: Scaling up vision founda- tion models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. InternVL: Scaling up vision founda- tion models and aligning for generic visual-linguistic tasks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024
2024
-
[15]
Impromptu VLA: Open weights and open data for driving vision-language-action models
Haohan Chi, Huan ang Gao, Ziming Liu, Jianing Liu, Chenyu Liu, Jinwei Li, Kaisen Yang, Yangcheng Yu, Zeda Wang, Wenyi Li, Leichen Wang, Xingtao Hu, Hao Sun, Hang Zhao, and Hao Zhao. Impromptu VLA: Open weights and open data for driving vision-language-action models. arXiv preprint arXiv:2505.23757, 2025
-
[16]
Label-free event-based object recognition via joint learning with image reconstruction from events
Hoonhee Cho, Hyeonseong Kim, Yujeong Chae, and Kuk- Jin Yoon. Label-free event-based object recognition via joint learning with image reconstruction from events. In IEEE/CVF International Conference on Computer Vision, pages 19866–19877, 2023
2023
-
[17]
Ob- ject detection with spiking neural networks on automotive event data
Lo ¨ıc Cordone, Benoˆıt Miramond, and Philippe Thierion. Ob- ject detection with spiking neural networks on automotive event data. InInternational Joint Conference on Neural Net- works, pages 1–8, 2022
2022
-
[18]
Cottereau, Fran- cisco Barranco, and Timoth ´ee Masquelier
Javier Cuadrado, Ulysse Ranc ¸on, Benoit R. Cottereau, Fran- cisco Barranco, and Timoth ´ee Masquelier. Optical flow es- timation from event-based cameras and spiking neural net- works.Frontiers in Neuroscience, 17:1160034, 2023
2023
-
[19]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster attention with bet- ter parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Event-based vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(1):154–180, 2022
Guillermo Gallego, Tobi Delbr ¨uck, Garrick Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan Leutenegger, Andrew J Davison, J ¨org Conradt, Kostas Daniilidis, et al. Event-based vision: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(1):154–180, 2022
2022
-
[21]
arXiv preprint arXiv:2410.16261 (2024)
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. Mini-InternVL: A flexible-transfer pocket multimodal model with 5% parameters and 90% perfor- mance.arXiv preprint arXiv:2410.16261, 2024
-
[22]
Daniel Gehrig and Davide Scaramuzza. Pushing the limits of asynchronous graph-based object detection with event cam- eras.arXiv preprint arXiv:2211.12324, 2022
-
[23]
Low-latency auto- motive vision with event cameras.Nature, 629(8014):1034– 1040, 2024
Daniel Gehrig and Davide Scaramuzza. Low-latency auto- motive vision with event cameras.Nature, 629(8014):1034– 1040, 2024
2024
-
[24]
Derpa- nis, and Davide Scaramuzza
Daniel Gehrig, Antonio Loquercio, Konstantinos G. Derpa- nis, and Davide Scaramuzza. End-to-end learning of repre- sentations for asynchronous event-based data. InIEEE/CVF International Conference on Computer Vision, pages 5633– 5643, 2019
2019
-
[25]
EKLT: asynchronous photometric feature tracking using events and frames.International Journal of Computer Vision, 128(3):601–618, 2020
Daniel Gehrig, Henri Rebecq, Guillermo Gallego, and Da- vide Scaramuzza. EKLT: asynchronous photometric feature tracking using events and frames.International Journal of Computer Vision, 128(3):601–618, 2020
2020
-
[26]
Combining events and frames using recurrent asynchronous multimodal net- works for monocular depth prediction.IEEE Robotics and Automation Letters, 6(2):2822–2829, 2021
Daniel Gehrig, Michelle R ¨uegg, Mathias Gehrig, Javier Hidalgo-Carri´o, and Davide Scaramuzza. Combining events and frames using recurrent asynchronous multimodal net- works for monocular depth prediction.IEEE Robotics and Automation Letters, 6(2):2822–2829, 2021
2021
-
[27]
Recurrent vi- sion transformers for object detection with event cameras
Mathias Gehrig and Davide Scaramuzza. Recurrent vi- sion transformers for object detection with event cameras. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13884–13893, 2023
2023
-
[28]
DSEC: A stereo event camera dataset for driv- ing scenarios.IEEE Robotics and Automation Letters, 6(3): 4947–4954, 2021
Mathias Gehrig, Willem Aarents, Daniel Gehrig, and Davide Scaramuzza. DSEC: A stereo event camera dataset for driv- ing scenarios.IEEE Robotics and Automation Letters, 6(3): 4947–4954, 2021
2021
-
[29]
Hierarchical neural memory network for low latency event processing
Ryuhei Hamaguchi, Yasutaka Furukawa, Masaki Onishi, and Ken Sakurada. Hierarchical neural memory network for low latency event processing. InIEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 22867–22876, 2023
2023
-
[30]
Vision-language-action models for autonomous driving: Past, present, and future
Tianshuai Hu, Xiaolu Liu, Song Wang, Yiyao Zhu, Ao Liang, Lingdong Kong, Guoyang Zhao, Zeying Gong, Jun Cen, Zhiyu Huang, Xiaoshuai Hao, Linfeng Li, Hang Song, Xiangtai Li, Jun Ma, Shaojie Shen, Jianke Zhu, Dacheng Tao, Ziwei Liu, and Junwei Liang. Vision-language-action models for autonomous driving: Past, present, and future. arXiv preprint arXiv:2512.1...
-
[31]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wen- hai Wang, et al. Planning-oriented autonomous driving. InIEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[32]
Towards event-driven object detection with off-the-shelf deep learning
Massimiliano Iacono, Stefan Weber, Arren Glover, and Chiara Bartolozzi. Towards event-driven object detection with off-the-shelf deep learning. InIEEE/RSJ International Conference on Intelligent Robots and Systems, pages 1–9, 2018
2018
-
[33]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Men- sch, Chris Bamford, et al. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Mixed frame- /event-driven fast pedestrian detection
Zhuangyi Jiang, Pengfei Xia, Kai Huang, Walter Stechele, Guang Chen, Zhenshan Bing, and Alois Knoll. Mixed frame- /event-driven fast pedestrian detection. InIEEE Interna- tional Conference on Robotics and Automation, pages 8332– 8338, 2019
2019
-
[35]
HPL-ESS: Hybrid pseudo-labeling for unsupervised event-based semantic segmentation
Linglin Jing, Yiming Ding, Yunpeng Gao, Zhigang Wang, Xu Yan, Dong Wang, Gerald Schaefer, Hui Fang, Bin Zhao, and Xuelong Li. HPL-ESS: Hybrid pseudo-labeling for unsupervised event-based semantic segmentation. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23128–23137, 2024
2024
-
[36]
N-ImageNet: Towards robust, fine-grained object recognition with event cameras
Junho Kim, Jaehyeok Bae, Gangin Park, Dongsu Zhang, and Young Min Kim. N-ImageNet: Towards robust, fine-grained object recognition with event cameras. InIEEE/CVF Inter- national Conference on Computer Vision, pages 2146–2156, 2021
2021
-
[37]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInternational Conference for Learning Representations, 2015
2015
-
[38]
Cot- tereau, and Wei Tsang Ooi
Lingdong Kong, Youquan Liu, Lai Xing Ng, Benoit R. Cot- tereau, and Wei Tsang Ooi. OpenESS: Event-based semantic scene understanding with open vocabularies. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15686–15698, 2024
2024
-
[39]
Talk2Event: Grounded understanding of dynamic scenes from event cameras
Lingdong Kong, Dongyue Lu, Ao Liang, Rong Li, Yuhao Dong, Tianshuai Hu, Lai Xing Ng, Wei Tsang Ooi, and Benoit R Cottereau. Talk2Event: Grounded understanding of dynamic scenes from event cameras. InAdvances in Neu- ral Information Processing Systems, 2025
2025
-
[40]
Cottereau
Lingdong Kong, Dongyue Lu, Xiang Xu, Lai Xing Ng, Wei Tsang Ooi, and Benoit R. Cottereau. EventFly: Event camera perception from ground to the sky. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1472–1484, 2025
2025
-
[41]
Multi- modal data-efficient 3D scene understanding for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(5):3748–3765, 2025
Lingdong Kong, Xiang Xu, Jiawei Ren, Wenwei Zhang, Liang Pan, Kai Chen, Wei Tsang Ooi, and Ziwei Liu. Multi- modal data-efficient 3D scene understanding for autonomous driving.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(5):3748–3765, 2025
2025
-
[42]
SODFormer: Streaming object detection with transformer using events and frames.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):14020–14037, 2023
Dianze Li, Yonghong Tian, and Jianing Li. SODFormer: Streaming object detection with transformer using events and frames.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):14020–14037, 2023
2023
-
[43]
Event-based vision enhanced: A joint de- tection framework in autonomous driving
Jianing Li, Siwei Dong, Zhaofei Yu, Yonghong Tian, and Tiejun Huang. Event-based vision enhanced: A joint de- tection framework in autonomous driving. InIEEE Inter- national Conference on Multimedia and Expo, pages 1396– 1401, 2019
2019
-
[44]
Asynchronous spatio-temporal memory net- work for continuous event-based object detection.IEEE Transactions on Image Processing, 31:2975–2987, 2022
Jianing Li, Jia Li, Lin Zhu, Xijie Xiang, Tiejun Huang, and Yonghong Tian. Asynchronous spatio-temporal memory net- work for continuous event-based object detection.IEEE Transactions on Image Processing, 31:2975–2987, 2022
2022
-
[45]
BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InIn- ternational Conference on Machine Learning, pages 19730– 19742. PMLR, 2023
2023
-
[46]
Pengteng Li, Yunfan Lu, Pinghao Song, Wuyang Li, Huizai Yao, and Hui Xiong. EventVL: Understand event streams via multimodal large language model.arXiv preprint arXiv:2501.13707, 2025
-
[47]
SeeGround: See and ground for zero-shot open- vocabulary 3D visual grounding
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Jun- wei Liang. SeeGround: See and ground for zero-shot open- vocabulary 3D visual grounding. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3707– 3717, 2025
2025
-
[48]
3EED: Ground everything everywhere in 3D
Rong Li et al. 3EED: Ground everything everywhere in 3D. arXiv preprint arXiv:2511.01755, 2025
-
[49]
Perspective- invariant 3D object detection
Ao Liang, Lingdong Kong, Dongyue Lu, Youquan Liu, Jian Fang, Huaici Zhao, and Wei Tsang Ooi. Perspective- invariant 3D object detection. InIEEE/CVF International Conference on Computer Vision, pages 27725–27738, 2025
2025
-
[50]
Improved Baselines with Visual Instruction Tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning.arXiv preprint arXiv:2310.03744, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InAdvances in Neural Information Processing Systems, pages 34892–34916, 2023
2023
-
[52]
Shaoyu Liu, Jianing Li, Guanghui Zhao, Yunjian Zhang, Xin Meng, Fei Richard Yu, Xiangyang Ji, and Ming Li. Event- GPT: Event stream understanding with multimodal large lan- guage models.arXiv preprint arXiv:2412.00832, 2024
-
[53]
FlexEvent: Towards flexible event-frame object detection at varying operational frequen- cies
Dongyue Lu, Lingdong Kong, Gim Hee Lee, Camille Simon Chane, and Wei Tsang Ooi. FlexEvent: Towards flexible event-frame object detection at varying operational frequen- cies. InAdvances in Neural Information Processing Systems, 2025
2025
-
[54]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, Chengqi Deng, Hanwei Xu, Zhenda Xie, and Chong Ruan. DeepSeek-VL: Towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[55]
Event-based asynchronous sparse con- volutional networks
Nico Messikommer, Daniel Gehrig, Antonio Loquercio, and Davide Scaramuzza. Event-based asynchronous sparse con- volutional networks. InEuropean Conference on Computer Vision, pages 415–431. Springer, 2020
2020
-
[56]
Scene adaptive sparse transformer for event-based object detection
Yansong Peng, Hebei Li, Yueyi Zhang, Xiaoyan Sun, and Feng Wu. Scene adaptive sparse transformer for event-based object detection. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 16794–16804, 2024
2024
-
[57]
Learning to detect objects with a 1 megapixel event camera.Advances in Neural Information Processing Systems, 33:16639–16652, 2020
Etienne Perot, Pierre De Tournemire, Davide Nitti, Jonathan Masci, and Amos Sironi. Learning to detect objects with a 1 megapixel event camera.Advances in Neural Information Processing Systems, 33:16639–16652, 2020
2020
-
[58]
Qwen, An Yang, Baosong Yang, Beichen Zhang, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
AEGNN: Asynchronous event-based graph neural networks
Simon Schaefer, Daniel Gehrig, and Davide Scaramuzza. AEGNN: Asynchronous event-based graph neural networks. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12371–12381, 2022
2022
-
[60]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outra- geously large neural networks: The sparsely-gated mixture- of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[61]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron- LM: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[62]
Neuromor- phic stereo vision: A survey of bio-inspired sensors and al- gorithms.Frontiers in Neuroscience, 13:28, 2019
Lea Steffen, Daniel Reichard, Jakob Weinland, Jacques Kaiser, Arne Roennau, and R ¨udiger Dillmann. Neuromor- phic stereo vision: A survey of bio-inspired sensors and al- gorithms.Frontiers in Neuroscience, 13:28, 2019
2019
-
[63]
Event-based object detection using graph neural networks
Daobo Sun and Haibo Ji. Event-based object detection using graph neural networks. InIEEE Conference on Data Driven Control and Learning Systems, pages 1895–1900, 2023
1900
-
[64]
Event-based fusion for motion deblurring with cross-modal attention
Lei Sun, Christos Sakaridis, Jingyun Liang, Qi Jiang, Kailun Yang, Peng Sun, Yaozu Ye, Kaiwei Wang, and Luc Van Gool. Event-based fusion for motion deblurring with cross-modal attention. InEuropean Conference on Computer Vision, pages 412–428. Springer, 2022
2022
-
[65]
ESS: Learning event-based semantic seg- mentation from still images
Zhaoning Sun, Nico Messikommer, Daniel Gehrig, and Da- vide Scaramuzza. ESS: Learning event-based semantic seg- mentation from still images. InEuropean Conference on Computer Vision, pages 341–357. Springer, 2022
2022
-
[66]
Fusing event- based and RGB camera for robust object detection in adverse conditions
Abhishek Tomy, Anshul Paigwar, Khushdeep S Mann, Alessandro Renzaglia, and Christian Laugier. Fusing event- based and RGB camera for robust object detection in adverse conditions. InIEEE International Conference on Robotics and Automation, pages 933–939, 2022
2022
-
[67]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
PARA-Drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. PARA-Drive: Parallelized architecture for real-time autonomous driving. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449– 15458, 2024
2024
-
[69]
EventCLIP: Adapting CLIP for event-based object recognition.arXiv preprint arXiv:2306.06354, 2023
Ziyi Wu, Xudong Liu, and Igor Gilitschenski. EventCLIP: Adapting CLIP for event-based object recognition.arXiv preprint arXiv:2306.06354, 2023
-
[70]
LEOD: Label-efficient object detection for event cameras
Ziyi Wu, Mathias Gehrig, Qing Lyu, Xudong Liu, and Igor Gilitschenski. LEOD: Label-efficient object detection for event cameras. InIEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 16933–16943, 2024
2024
-
[71]
Spiking transformers for event-based single object tracking
Jiqing Zhang, Bo Dong, Haiwei Zhang, Jianchuan Ding, Fe- lix Heide, Baocai Yin, and Xin Yang. Spiking transformers for event-based single object tracking. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 8801–8810, 2022
2022
-
[72]
LLaFEA: Frame-event complementary fusion for fine-grained spatiotemporal un- derstanding in LMMs
Hanyu Zhou and Gim Hee Lee. LLaFEA: Frame-event complementary fusion for fine-grained spatiotemporal un- derstanding in LMMs. InIEEE/CVF International Confer- ence on Computer Vision, pages 22294–22304, 2025
2025
-
[73]
RGB-event fusion for moving object detection in autonomous driving
Zhuyun Zhou, Zongwei Wu, R ´emi Boutteau, Fan Yang, C´edric Demonceaux, and Dominique Ginhac. RGB-event fusion for moving object detection in autonomous driving. InIEEE International Conference on Robotics and Automa- tion, pages 7808–7815, 2023
2023
-
[74]
EV-FlowNet: Self- supervised optical flow estimation for event-based cameras
Alex Zihao Zhu and Liangzhe Yuan. EV-FlowNet: Self- supervised optical flow estimation for event-based cameras. InRobotics: Science and Systems, 2018
2018
-
[75]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.