Habituation at the Gate: Rising Approval and Declining Scrutiny in Human Review of AI Agent Code
Pith reviewed 2026-06-26 09:29 UTC · model grok-4.3
The pith
Reviewers approve more AI-generated code over time but comment less and wait longer, consistent with habituation under workload.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
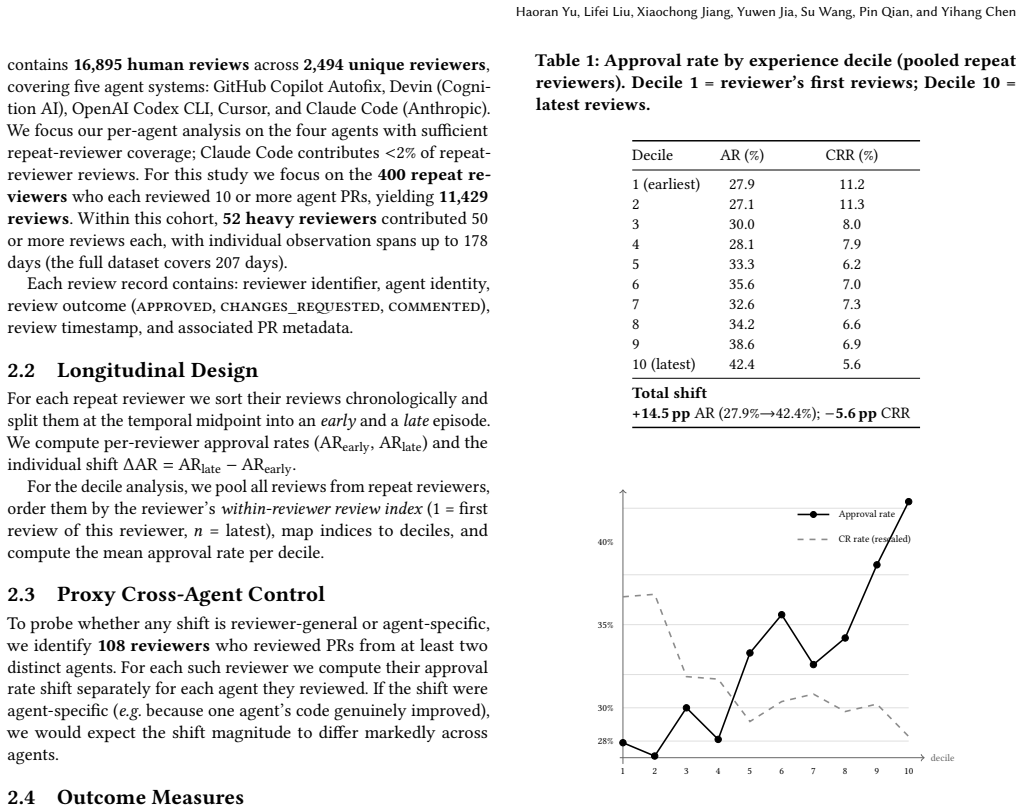
Approval rates for AI agent code increase with within-reviewer experience, reaching a +14.5 pp cumulative gap from first to tenth decile, while inline comments decline and queue times lengthen; the combination points to habituation rather than calibrated trust.
What carries the argument
Within-reviewer longitudinal comparison of early versus late review episodes for the same individuals, pooled by experience decile and controlled for calendar time, agent type, and PR size.
If this is right
- Approval rates for AI PRs rise with reviewer experience while rates for human PRs fall over the same period.
- Inline comment volume decreases 22% even as median review latency increases 3.5 times.
- The approval increase persists after controlling for calendar time and is not explained by changes in PR size.
- The observed pattern is interpreted as more consistent with reflexive habituation than with rational trust calibration.
Where Pith is reading between the lines
- Habituation could allow more low-quality AI code to enter open-source repositories if workload continues to grow.
- Platforms might test interventions such as periodic reviewer rotation or explicit scrutiny prompts to counteract the effect.
- Similar experience-driven drops in scrutiny may appear in other repeated human review tasks involving AI outputs, such as content moderation.
Load-bearing premise
The within-reviewer design and controls for calendar time, agent type, and PR size fully isolate experience-driven habituation from unmeasured shifts in reviewer behavior or PR characteristics.
What would settle it
A dataset tracking the same reviewers on AI PRs where approval rates stay flat or decline and comment volume remains constant despite rising workload.
Figures
read the original abstract
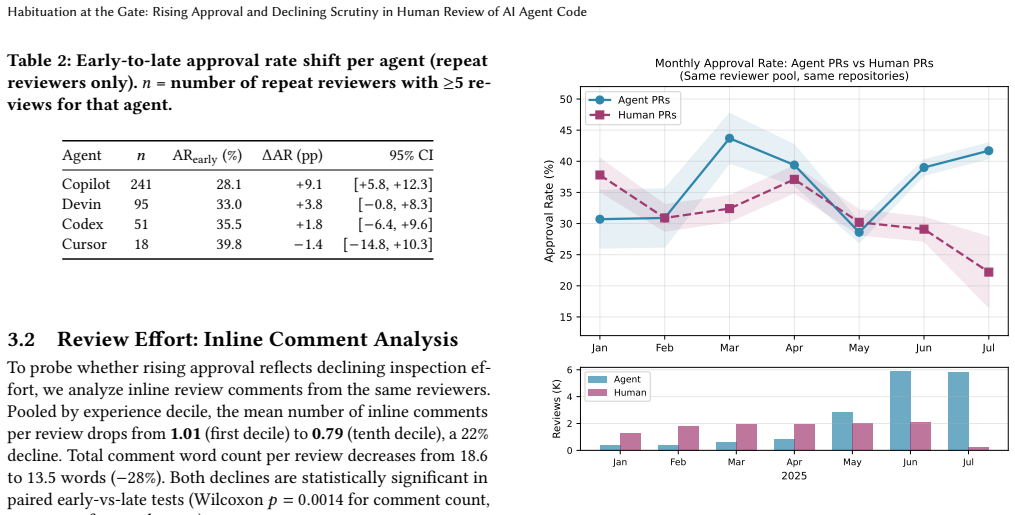
As AI coding agents (e.g., GitHub Copilot, Devin, OpenAI Codex, Cursor) submit pull requests to open-source repositories at scale, a key question arises: do human reviewers gradually lower their scrutiny for AI-generated code over time? We conduct a longitudinal within-reviewer analysis using the AIDev dataset, studying 400 repeat reviewers who collectively submitted 11,429 reviews over a seven-month observation period. Comparing each reviewer's early and late review episodes, we observe a population-level shift in approval rate from 30.1% to 36.8% (Wilcoxon signed-rank p < 10^{-6} on paired shifts). Pooled by within-reviewer experience decile, the cumulative gap reaches +14.5 pp from first to tenth decile. This shift is experience-driven (persists after controlling for calendar time), agent-specific (human PR approval rates decline over the same period), and not explained by PR difficulty (median PR size is flat). However, review latency increases rather than decreases (+3.5x), while inline comment volume decreases (-22%, p=0.0014), suggesting reviewers spend more time in queue but less time actively inspecting code. The combination of rising approval, declining comment effort, and increasing queue time is most consistent with reflexive habituation under growing workload rather than rational trust calibration alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a longitudinal within-reviewer analysis of 400 repeat reviewers and 11,429 reviews from the AIDev dataset over seven months. It reports a population-level rise in AI PR approval rates from 30.1% to 36.8% (Wilcoxon p < 10^{-6}), reaching a +14.5 pp cumulative gap across experience deciles. The shift is claimed to be experience-driven after calendar-time controls, agent-specific (human PR approvals fall), and independent of difficulty (median PR size flat). Review latency rises 3.5x while inline comments fall 22% (p=0.0014), interpreted as evidence of reflexive habituation under workload rather than rational trust calibration.
Significance. If the within-reviewer controls and robustness checks hold, the work supplies a large-scale observational benchmark on how human oversight of AI-generated code evolves in open-source settings. The paired early/late design, agent-specific contrast, and combination of approval, comment, and latency metrics are strengths that could inform software-engineering practice and AI deployment policies. The observational framing limits strong causal claims, but the pattern is falsifiable with the reported dataset.
major comments (2)
- [Methods / statistical model] Methods / statistical model: The abstract states that the +14.5 pp approval rise 'persists after controlling for calendar time' and is 'not explained by PR difficulty (median PR size is flat),' yet supplies no regression specification, fixed-effect structure (e.g., reviewer FE, time FE, or interaction terms), covariate list, or robustness table. Without these details it is impossible to verify whether the experience-driven claim survives plausible alternative specifications such as finer-grained time trends or additional difficulty proxies.
- [Results, experience-decile analysis] Results, experience-decile analysis: The claim that the approval increase is independent of difficulty rests on median PR size being flat, but size is only one proxy; if later PRs differ systematically in language, complexity, or submitter experience (unmeasured in the reported controls), the within-reviewer design alone does not close this channel. A table showing coefficient stability across alternative difficulty measures would be required to support the central interpretation.
minor comments (2)
- [Abstract] Abstract: The phrase 'pooled by within-reviewer experience decile' should be clarified with the exact decile construction and whether deciles are reviewer-specific or global.
- [Abstract] The Wilcoxon signed-rank test is reported on paired shifts; the exact pairing (reviewer-level early vs. late) and handling of ties or missing data should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major point below and will revise the paper accordingly where feasible.
read point-by-point responses
-
Referee: [Methods / statistical model] Methods / statistical model: The abstract states that the +14.5 pp approval rise 'persists after controlling for calendar time' and is 'not explained by PR difficulty (median PR size is flat),' yet supplies no regression specification, fixed-effect structure (e.g., reviewer FE, time FE, or interaction terms), covariate list, or robustness table. Without these details it is impossible to verify whether the experience-driven claim survives plausible alternative specifications such as finer-grained time trends or additional difficulty proxies.
Authors: The referee is correct that the main text does not present the explicit regression equation, fixed-effects structure, or robustness table. The reported analysis relies on a within-reviewer paired comparison (early vs. late reviews per reviewer) with calendar-time controls, but these details are only summarized. We will revise the Methods section to include the full specification (e.g., approval rate modeled with reviewer fixed effects, calendar time fixed effects or trends, and experience decile as the key predictor), list all covariates, and add an appendix table with coefficient stability under alternative time-trend specifications (linear, quadratic, and month fixed effects). revision: yes
-
Referee: [Results, experience-decile analysis] Results, experience-decile analysis: The claim that the approval increase is independent of difficulty rests on median PR size being flat, but size is only one proxy; if later PRs differ systematically in language, complexity, or submitter experience (unmeasured in the reported controls), the within-reviewer design alone does not close this channel. A table showing coefficient stability across alternative difficulty measures would be required to support the central interpretation.
Authors: We agree that median PR size is only one proxy and that unmeasured shifts in complexity, language, or submitter experience could remain. The within-reviewer design eliminates reviewer-specific time-invariant confounders and the agent-specific contrast (declining human-PR approvals over the same window) provides indirect support against a general difficulty increase. However, the AIDev dataset does not contain additional difficulty proxies such as cyclomatic complexity, language-specific metrics, or submitter experience for the full sample. We will therefore expand the Limitations section to discuss this gap explicitly but cannot produce the requested coefficient-stability table across alternative measures. revision: partial
- Request for a table of coefficient stability across alternative difficulty measures (language, complexity, submitter experience), as these variables are unavailable in the AIDev dataset.
Circularity Check
No circularity: purely observational analysis of external dataset
full rationale
The paper conducts a longitudinal within-reviewer statistical comparison on the AIDev dataset using paired tests (Wilcoxon signed-rank) and controls for calendar time, agent type, and PR size. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or derivations appear in the provided text. All reported shifts (approval rates, comment volume, latency) are direct empirical observations, making the analysis self-contained against external data without reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Wilcoxon signed-rank test is appropriate for paired within-reviewer approval rate shifts
Reference graph
Works this paper leans on
-
[1]
Alberto Bacchelli and Christian Bird. 2013. Expectations, Outcomes, and Chal- lenges of Modern Code Review. InProceedings of the 35th International Conference on Software Engineering (ICSE ’13). IEEE Press, 712–721. doi:10.1109/ICSE.2013. 6606617
-
[2]
Nathan Cassee, Bogdan Vasilescu, and Alexander Serebrenik. 2020. The Silent Helper: The Impact of Continuous Integration on Code Reviews. InProceedings of the 27th IEEE International Conference on Software Analysis, Evolution and Reengi- neering (SANER ’20). IEEE, 423–434. doi:10.1109/SANER48275.2020.9054818
-
[3]
In: Proceedings of the 11th Working Conference on Mining Software Repositories
Eirini Kalliamvakou, Georgios Gousios, Kelly Blincoe, Leif Singer, Daniel M. German, and Daniela Damian. 2014. The Promises and Perils of Mining GitHub. InProceedings of the 11th Working Conference on Mining Software Repositories (MSR ’14). ACM, 92–101. doi:10.1145/2597073.2597074
-
[4]
Oleksii Kononenko, Olga Baysal, Latifa Guerrouj, Yaxin Cao, and Michael W. Godfrey. 2015. Investigating Code Review Quality: Do People and Participation Matter?. InProceedings of the 31st IEEE International Conference on Software Maintenance and Evolution (ICSME ’15). IEEE, 111–120. doi:10.1109/ICSM.2015. 7332457
-
[5]
Hao Li, Haoxiang Zhang, and Ahmed E. Hassan. 2025. The Rise of AI Team- mates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Software Engineering. arXiv:2507.15003 [cs.SE] https://arxiv.org/ abs/2507.15003
Pith/arXiv arXiv 2025
-
[6]
Zhiyu Li, Shuai Lu, Daya Guo, Nan Duan, Shailesh Jannu, Grant Jenks, Deep Majumder, Jared Green, Alexey Svyatkovskiy, Shengyu Fu, and Neel Sundare- san. 2022. Automating Code Review Activities by Large-Scale Pre-training. In Proceedings of the 30th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering ...
-
[7]
Shane McIntosh, Yasutaka Kamei, Bram Adams, and Ahmed E. Hassan. 2016. An Empirical Study of the Impact of Modern Code Review Practices on Software Quality.Empirical Software Engineering21, 5 (2016), 2146–2189. doi:10.1007/ s10664-015-9381-9
2016
-
[8]
Sida Peng, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. 2023. The Impact of AI on Developer Productivity: Evidence from GitHub Copilot.arXiv preprint arXiv:2302.06590(2023)
Pith/arXiv arXiv 2023
-
[9]
Peter C. Rigby and Christian Bird. 2013. Convergent Contemporary Software Peer Review Practices. InProceedings of the 9th Joint Meeting on Foundations of Software Engineering (ESEC/FSE ’13). ACM, 202–212. doi:10.1145/2491411.2491444
-
[10]
Xunzhu Tang, Kisub Kim, Yewei Song, Cedric Lothritz, Bei Li, Saad Ezzini, Haoye Tian, Jacques Klein, and Tegawendé F. Bissyandé. 2024. CodeAgent: Autonomous Communicative Agents for Code Review. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP ’24). 11279–11313. doi:10.18653/v1/2024.emnlp-main.632
-
[11]
Mairieli Wessel, Alexander Serebrenik, Igor Wiese, Igor Steinmacher, and Marco Aurélio Gerosa. 2020. Effects of Adopting Code Review Bots on Pull Requests to OSS Projects. InProceedings of the IEEE International Conference on Software Maintenance and Evolution (ICSME ’20). IEEE, 1–11. doi:10.1109/ ICSME46990.2020.00011 2https://anonymous.4open.science/r/r...
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.