SierpinskiCam: Camera-Controlled Video Retaking with Sierpinski Triangle Pattern Cues
Pith reviewed 2026-06-27 03:17 UTC · model grok-4.3
The pith
SierpinskiCam augments geometry guidance with Sierpinski dome texture cues to maintain camera control during large viewpoint shifts in video retaking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
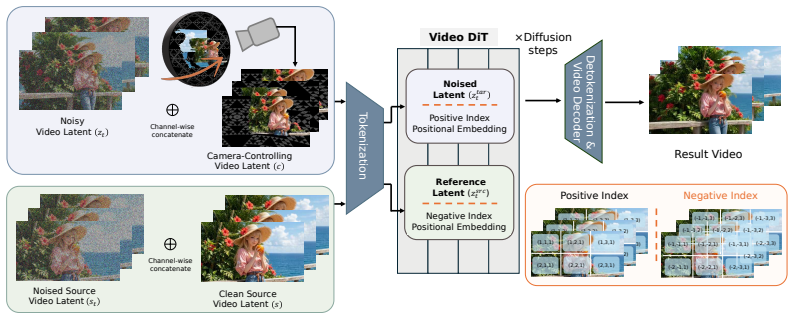
SierpinskiCam augments geometry-based guidance with Sierpinski dome texture cues that contain rich trackable features even under large viewpoint changes. It introduces a reference video conditioning mechanism that appends source-video tokens to the target-token sequence and separates the two streams with negative RoPE indices, enabling appearance grounding without architectural modification or per-video adaptation. Extensive experiments show that SierpinskiCam achieves significant gains in camera controllability, geometric consistency, and video quality across diverse and challenging retaking scenarios.
What carries the argument
Sierpinski dome texture cues that supply persistent trackable features, combined with negative-RoPE separation of source and target video token streams for reference conditioning.
If this is right
- Target camera paths can deviate substantially farther from the source trajectory while retaining usable guidance.
- Newly revealed scene regions stay geometrically consistent because the added cues remain trackable.
- Appearance grounding succeeds without any per-video adaptation or architecture changes to the underlying diffusion model.
- The same gains appear across diverse and challenging retaking scenarios without task-specific retraining.
Where Pith is reading between the lines
- The same fractal-pattern cue idea could be tested in other diffusion pipelines that need viewpoint-robust conditioning, such as novel-view video synthesis.
- Negative-RoPE stream separation might reduce interference in any token-based reference conditioning setup inside diffusion transformers.
- Replacing the fixed Sierpinski pattern with an optimized or scene-adaptive texture could further increase feature density in low-texture regions.
Load-bearing premise
Sierpinski dome texture cues will reliably contain rich trackable features even under large viewpoint changes.
What would settle it
Run the method on a source video whose target trajectory produces large viewpoint changes that render the projected Sierpinski pattern features untrackable; if retaking quality then matches or falls below the geometry-only baseline, the central claim is false.
Figures












read the original abstract
Generating novel renderings of a scene along user-defined camera trajectories from a single monocular video, dubbed video retaking, is a compelling but difficult problem in content creation and visual effects. Existing geometry-guided approaches reconstruct a 4D representation from the source video and render it along the target trajectory to condition video diffusion models. However, this guidance degrades as the target camera departs from the source trajectory, leaving newly revealed regions sparse or entirely missing. We propose SierpinskiCam, which addresses this limitation by augmenting geometry-based guidance with Sierpinski dome texture cues that contains rich trackable features even under large viewpoint changes. We further introduce a reference video conditioning mechanism that appends source-video tokens to the target-token sequence and separates the two streams with negative RoPE indices, enabling appearance grounding without architectural modification or per-video adaptation. Extensive experiments show that SierpinskiCam achieves significant gains in camera controllability, geometric consistency, and video quality across diverse and challenging retaking scenarios. Project page: https://hyelinnam.github.io/SierpinskiCam/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SierpinskiCam for video retaking from a single monocular video along user-specified camera trajectories. It augments standard geometry-based guidance (which degrades for out-of-trajectory viewpoints) with Sierpinski dome texture cues asserted to supply rich trackable features even under large viewpoint changes, and adds a reference conditioning scheme that appends source-video tokens with negative RoPE indices to ground appearance without architectural changes or per-video fine-tuning. The authors state that extensive experiments demonstrate significant gains in camera controllability, geometric consistency, and video quality.
Significance. If the reported gains are reproducible and the Sierpinski pattern's contribution can be isolated, the method would offer a lightweight, additive improvement to existing geometry-guided video diffusion pipelines for handling novel viewpoints. The negative-RoPE conditioning trick is a practical engineering contribution that avoids model surgery. These elements could be useful in VFX and content creation, but the significance hinges on whether the empirical claims are supported by properly controlled experiments.
major comments (2)
- [Abstract] Abstract: the claim of 'significant gains' in controllability, consistency, and quality is asserted without any quantitative metrics, ablation tables, or error analysis, so it is impossible to determine whether the experiments actually support the central claims or contain post-hoc choices.
- [Method] Method / Experiments: the central claim requires that the Sierpinski dome texture cues reliably supply rich trackable features when target cameras depart far from the source trajectory (where geometry guidance becomes sparse). No ablation or isolated analysis is described that separates the fractal pattern's contribution from the rest of the pipeline or from the negative-RoPE conditioning.
minor comments (1)
- [Abstract] Abstract: grammatical error ('cues that contains' should be 'contain').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify opportunities to strengthen the presentation of our experimental results. We address each point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significant gains' in controllability, consistency, and quality is asserted without any quantitative metrics, ablation tables, or error analysis, so it is impossible to determine whether the experiments actually support the central claims or contain post-hoc choices.
Authors: The abstract is a high-level summary, but the referee is correct that it would benefit from explicit quantitative support. The main manuscript contains tables with metrics (camera pose error, geometric consistency scores, and perceptual quality) and ablation results. We will revise the abstract to include the key numerical improvements reported in Section 4. revision: yes
-
Referee: [Method] Method / Experiments: the central claim requires that the Sierpinski dome texture cues reliably supply rich trackable features when target cameras depart far from the source trajectory (where geometry guidance becomes sparse). No ablation or isolated analysis is described that separates the fractal pattern's contribution from the rest of the pipeline or from the negative-RoPE conditioning.
Authors: We agree that an explicit isolation of the Sierpinski dome contribution is necessary to substantiate the central claim. The current manuscript contains comparative experiments, but does not include a dedicated ablation that holds the negative-RoPE component fixed while varying only the texture cues. We will add this analysis, including feature-tracking visualizations for large viewpoint deviations. revision: yes
Circularity Check
No significant circularity; method is an empirical augmentation without self-referential derivations
full rationale
The paper proposes SierpinskiCam as an additive technique (Sierpinski dome texture cues plus negative-RoPE reference conditioning) layered on existing geometry-guided video diffusion pipelines. No equations, first-principles derivations, or predictions appear that reduce by construction to fitted inputs, self-definitions, or self-citation chains. The central claims rest on experimental outcomes across retaking scenarios rather than on any load-bearing uniqueness theorem or ansatz smuggled via prior self-work. The fractal cue choice is presented as a design decision justified by known self-similarity properties, not as a result derived from the target metrics. This is a standard self-contained engineering contribution with independent empirical content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Met3r: Measuring multi-view consistency in generated images
Mohammad Asim, Christopher Wewer, Thomas Wimmer, Bernt Schiele, and Jan Eric Lenssen. Met3r: Measuring multi-view consistency in generated images. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6034–6044, 2025
2025
-
[2]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. arXiv preprint arXiv:2503.11647, 2025
arXiv 2025
-
[3]
Wei Cao, Hao Zhang, Fengrui Tian, Yulun Wu, Yingying Li, Shenlong Wang, Ning Yu, and Yaoyao Liu. Freeorbit4d: Training-free arbitrary camera redirection for monocular videos via geometry-complete 4d reconstruction.arXiv preprint arXiv:2601.18993, 2026
Pith/arXiv arXiv 2026
-
[4]
Kaihua Chen, Tarasha Khurana, and Deva Ramanan. Reconstruct, inpaint, finetune: Dynamic novel-view synthesis from monocular videos.arXiv preprint arXiv:2507.12646, 2025
arXiv 2025
-
[5]
Unreal engine
Epic Games. Unreal engine. URLhttps://www.unrealengine.com
-
[6]
Martin A. Fischler and Robert C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography.Communications of the ACM, 24(6):381–395, June 1981. doi: 10.1145/358669.358692
-
[7]
Google DeepMind. Veo 3. https://deepmind.google/models/veo/, 2025. Model card, accessed 25/Jul/2025
2025
-
[8]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[9]
Hyeonho Jeong, Suhyeon Lee, and Jong Chul Ye. Reangle-a-video: 4d video generation as video-to-video translation.arXiv preprint arXiv:2503.09151, 2025
arXiv 2025
-
[10]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
Pith/arXiv arXiv 2024
-
[11]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
Pith/arXiv arXiv 2025
-
[12]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[13]
Vista4d: Video reshooting with 4d point clouds.arXiv preprint arXiv:2604.21915, 2026
Kuan Heng Lin, Zhizheng Liu, Pablo Salamanca, Yash Kant, Ryan Burgert, Yuancheng Xu, Koichi Namekata, Yiwei Zhao, Bolei Zhou, Micah Goldblum, et al. Vista4d: Video reshooting with 4d point clouds.arXiv preprint arXiv:2604.21915, 2026
Pith/arXiv arXiv 2026
-
[14]
David G. Lowe. Distinctive image features from scale-invariant keypoints.International Journal of Computer Vision, 60(2):91–110, 2004. doi: 10.1023/B:VISI.0000029664.99615.94
-
[15]
Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[16]
Steerx: Creating any camera-free 3d and 4d scenes with geometric steering
Byeongjun Park, Hyojun Go, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, and Changick Kim. Steerx: Creating any camera-free 3d and 4d scenes with geometric steering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27326–27337, 2025
2025
-
[17]
Byeongjun Park, Byung-Hoon Kim, Hyungjin Chung, and Jong Chul Ye. Redirector: Creating any-length video retakes with rotary camera encoding.arXiv preprint arXiv:2511.19827, 2025
arXiv 2025
-
[18]
Jangho Park, Taesung Kwon, and Jong Chul Ye. Zero4d: Training-free 4d video generation from single video using off-the-shelf video diffusion.arXiv preprint arXiv:2503.22622, 2025
arXiv 2025
-
[19]
The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 10
Pith/arXiv arXiv 2017
-
[20]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[21]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[22]
Generative camera dolly: Extreme monocular dynamic novel view synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. InEuropean Conference on Computer Vision, pages 313–331. Springer, 2024
2024
-
[23]
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[24]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 5294–5306, 2025
2025
-
[25]
Scale independent tracking pattern
Kevin Wooley and Ronald Mallet. Scale independent tracking pattern. U.S. Patent US9672417B2, June 2017. URL https://patents.google.com/patent/US9672417B2/en. Assigned to Lucasfilm Entertainment Co. Ltd
2017
-
[26]
Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
Yuxi Xiao, Jianyuan Wang, Nan Xue, Nikita Karaev, Yuri Makarov, Bingyi Kang, Xing Zhu, Hujun Bao, Yujun Shen, and Xiaowei Zhou. Spatialtrackerv2: 3d point tracking made easy.arXiv preprint arXiv:2507.12462, 2025
arXiv 2025
-
[27]
Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
Zeqi Xiao, Wenqi Ouyang, Yifan Zhou, Shuai Yang, Lei Yang, Jianlou Si, and Xingang Pan. Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
arXiv 2024
-
[28]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
Pith/arXiv arXiv 2024
-
[29]
Mark YU, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models.arXiv preprint arXiv:2503.05638, 2025
arXiv 2025
-
[30]
Recapture: Generative video camera controls for user-provided videos using masked video fine-tuning
David Junhao Zhang, Roni Paiss, Shiran Zada, Nikhil Karnad, David E Jacobs, Yael Pritch, Inbar Mosseri, Mike Zheng Shou, Neal Wadhwa, and Nataniel Ruiz. Recapture: Generative video camera controls for user-provided videos using masked video fine-tuning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2050–2062, 2025
2050
-
[31]
A flexible new technique for camera calibration.IEEE Transactions on pattern analysis and machine intelligence, 22(11):1330–1334, 2000
Zhengyou Zhang. A flexible new technique for camera calibration.IEEE Transactions on pattern analysis and machine intelligence, 22(11):1330–1334, 2000
2000
-
[32]
Stereo magnification: Learning view synthesis using multiplane images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images. InSIGGRAPH, 2018. 11 A Motivation Figure 6:Failure cases of TrajectoryCrafter.When the target camera moves beyond the original scene coverage, it may hallucinate content or fail to follow the camera pose, especia...
2018
-
[33]
Overall preference Please rate each result based on your overall preference, considering visual quality, realism, temporal coherence, and similarity to the source video
-
[34]
Camera motion accuracy Please rate each result based on how well its camera motion follows the target trajectory described in the question
-
[35]
A higher score means less flickering, fewer unexpected changes in the subject/background, and better preservation of the source identity and geometry
Stability & source consistency Please rate each result based on temporal stability and consistency with the source video. A higher score means less flickering, fewer unexpected changes in the subject/background, and better preservation of the source identity and geometry. Table 4: Instructions used for the user study. Figure 9: Screenshot of the user stud...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.