Analyzing and Encoding the Al-Mawrid Arabic-English Dictionary with the ISO Language Markup Framework and TEI Lex-0
Pith reviewed 2026-06-27 01:09 UTC · model grok-4.3
The pith
The Al-Mawrid Arabic-English dictionary is encoded into LMF and TEI Lex-0 with 91% structural parsing accuracy on a sample.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
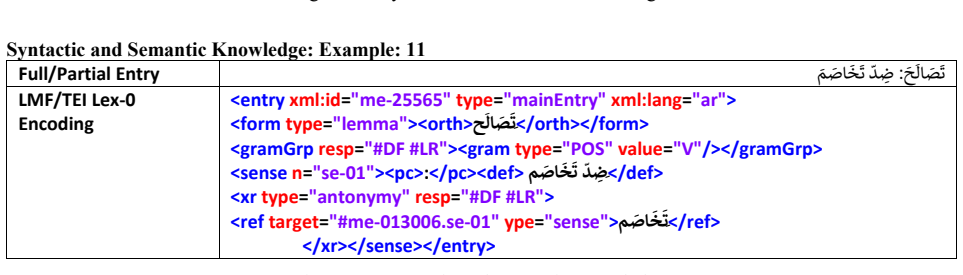
By applying an editorial view to the dictionary's macro- and microstructure, the study resolves structural ambiguities and punctuation inconsistencies. On the letter Ayn sample that makes up 4.6 percent of the volume, information extraction rules reach 91 percent structural parsing accuracy, 85 percent precision and 98 percent recall for synonyms, and 88 percent precision for other morpho-semantic features. The paper compares the result to existing Arabic resources, notes limits of TEI Lex-0 for certain Arabic phenomena, and introduces a prefix-based referencing system to support integration into Linguistic Linked Open Data.
What carries the argument
The dual-standard encoding that aligns ISO LMF with TEI Lex-0 guidelines, backed by empirical analysis of lexical knowledge density and rule-based information extraction.
If this is right
- The resulting resource is interoperable and machine-tractable for computational use.
- A scalable prefix-based referencing system allows inclusion in the semantic web.
- The workflow offers a reproducible method for retro-digitization of other complex bilingual lexicons.
- The approach reveals specific limits of TEI Lex-0 in modeling implicit semantic relations and scattered morphological cues in Arabic.
Where Pith is reading between the lines
- If the accuracy holds on the full dictionary, the encoded version could support new Arabic NLP tools that rely on synonym and feature data.
- The prefix-based system could connect this lexicon to other lexical resources beyond those discussed in the paper.
- Limitations noted for Arabic phenomena might prompt targeted extensions to TEI Lex-0 or LMF in future work.
Load-bearing premise
That the sample consisting of the letter Ayn is representative of the full dictionary and that the extraction rules will maintain similar accuracy when applied to the entire resource.
What would settle it
Running the same extraction rules on a second letter such as Ba and checking whether structural parsing accuracy stays near 91 percent and synonym precision near 85 percent.
Figures
























































read the original abstract
This paper presents a robust methodology for the systematic digitization and encoding of the Al-Mawrid Arabic-English dictionary, transforming it from a legacy print resource into a standardized computational lexicon. Addressing a significant gap in Arabic lexical infrastructure, the study adopts a dual-standard framing that aligns the ISO Lexical Markup Framework (LMF) with the Text Encoding Initiative TEI Lex-0 guidelines. By applying an editorial view to the dictionary's macro- and microstructure, the research resolves the structural ambiguities and punctuation inconsistencies typical of 20th-century bilingual dictionaries. The methodology is grounded in an empirical analysis of the dictionary's lexical knowledge density. Drawing on a representative sample (the letter Ayn, comprising 4.6% of the total volume), the study provides scientific weight to the encoding process, demonstrating a structural parsing accuracy of 91%. Quantitative evaluation of the information extraction rules reveals high performance, with 85% precision and 98% recall for synonyms, and 88% precision for other morpho-semantic features. Beyond technical description, the paper provides a critical comparison with existing Arabic lexical resources and discusses the limitations of TEI Lex-0 when modelling specific Arabic phenomena, such as implicit "open set" semantic relations and scattered morphological cues. Furthermore, the study explores the potential for Linguistic Linked Open Data (LLOD) integration by establishing a scalable prefix-based referencing system that facilitates the resource's inclusion in the semantic web. The result is an interoperable, machine-tractable resource that provides a reproducible workflow for the retro-digitization of complex legacy bilingual lexicons within the Arabic NLP and Digital Humanities communities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a methodology for the systematic digitization and encoding of the Al-Mawrid Arabic-English dictionary using the ISO Lexical Markup Framework (LMF) aligned with TEI Lex-0 guidelines. It resolves structural ambiguities in the print resource via an editorial view of macro- and microstructure, evaluates information extraction rules on a sample from the letter Ayn (4.6% of volume) reporting 91% structural parsing accuracy, 85% precision/98% recall for synonyms and 88% precision for morpho-semantic features, compares the result to existing Arabic lexical resources, discusses TEI Lex-0 limitations for Arabic phenomena such as implicit semantic relations, and proposes a prefix-based system for Linguistic Linked Open Data (LLOD) integration.
Significance. If the encoding workflow proves robust and the performance metrics generalize, the work supplies a much-needed interoperable computational lexicon for Arabic NLP, fills a documented gap in standardized Arabic lexical infrastructure, and offers a reproducible retro-digitization pipeline for other complex legacy bilingual dictionaries in the Digital Humanities.
major comments (1)
- [Evaluation / quantitative results (abstract and corresponding section)] The central empirical claims rest on a single contiguous sample from the letter Ayn. The manuscript asserts representativeness solely on the basis of volume share (4.6%) without reporting any cross-letter statistics on entry complexity, punctuation density, frequency of implicit relations, or morphological cue distribution. Because Arabic root-based dictionaries commonly exhibit letter-specific microstructural variation, the reported 91% parsing accuracy and extraction metrics (85% precision/98% recall for synonyms; 88% precision for other features) cannot be taken as evidence that the rules will transfer at the claimed rates to the full dictionary.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's comments. We address the major comment on the evaluation sample below.
read point-by-point responses
-
Referee: The central empirical claims rest on a single contiguous sample from the letter Ayn. The manuscript asserts representativeness solely on the basis of volume share (4.6%) without reporting any cross-letter statistics on entry complexity, punctuation density, frequency of implicit relations, or morphological cue distribution. Because Arabic root-based dictionaries commonly exhibit letter-specific microstructural variation, the reported 91% parsing accuracy and extraction metrics (85% precision/98% recall for synonyms; 88% precision for other features) cannot be taken as evidence that the rules will transfer at the claimed rates to the full dictionary.
Authors: We acknowledge the validity of this observation. Our sample selection was based on the letter's proportional volume and its inclusion of varied entry structures, but we did not conduct or report cross-letter analyses. Consequently, the performance figures should be viewed as preliminary indicators of the method's viability rather than validated generalization rates. In the revised manuscript, we will revise the abstract, introduction, and evaluation sections to more clearly delimit the scope of the reported metrics and add a limitations subsection discussing potential letter-specific variations in Arabic dictionaries. We will also propose this as an area for future work. This revision addresses the concern without altering the described methodology or the value of the encoding approach for the sampled data. revision: partial
Circularity Check
No circularity: empirical encoding and evaluation with no derivations or self-referential predictions
full rationale
The paper reports an applied digitization workflow for a legacy dictionary, using LMF/TEI standards and direct quantitative evaluation (91% parsing accuracy, precision/recall on synonyms and features) on a single contiguous sample (letter Ayn). No equations, fitted parameters renamed as predictions, self-definitional steps, or load-bearing self-citations appear in the described methodology. Performance figures are straightforward measurements on the chosen sample rather than outputs forced by construction from inputs. Representativeness of the 4.6% sample is an external validity assumption, not a circular reduction. The work is self-contained as an empirical project.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ISO LMF and TEI Lex-0 frameworks are appropriate for modeling the macro- and microstructure of bilingual Arabic-English dictionaries
Reference graph
Works this paper leans on
-
[1]
Deep learning for Arabic NLP: A survey
Al-Ayyoub, M., A. Nuseir, K. Alsmearat, Y. Jararweh and B. Gupta (2018). "Deep learning for Arabic NLP: A survey." Journal of computational science 26: 522-531. Alghamdi, A. A. O. (2018). A Computational Lexicon and Representational Model for Arabic Multiword Expressions, University of Leeds. Alsharhan, E., A. Ramsay and Evaluation (2020). "Investigating ...
2018
-
[2]
TEI Lite: Encoding for Interchange: an introduc -tion to the TEI Final revised edition for TEI P5
Amar, F. B. B., B. Gargouri and A. B. Hamadou (2010). Towards Generation of Domain Ontology from LMF Standardized Dictionaries. SEKE: 515-520. Amar, F. B. B., A. Khemakhem, B. Gargouri, K. Haddar and A. B. Hamadou (2008). LMF Standardized Model for the Editorial Electronic Dictionaries of Arabic. NLPCS. Attia, M., L. Tounsi and J. van Genabith (2010). Aut...
2010
-
[3]
9.5 Typographic and Lexical Information in Dictionary Data
Consortium, T. (2022 ). "9.5 Typographic and Lexical Information in Dictionary Data" TEI P5: Guidelines for Electronic Text Encoding and Interchange. [Version 4.4.0.].[Last updated on 19th April 2022].[Revision ff9cc28b0]. Costa, R., Roche, C., & Salgado, A. (2022). Standards for representing lexicographic data: An overview . DARIAH-Campus. Elleuch, I., B...
2022
-
[4]
Multiword expressions: between lexicography and NLP
Gantar, P., L. Colman, C. Parra Escartín and H. Martínez Alonso (2019). "Multiword expressions: between lexicography and NLP." 32(2): 138-162. Graff, D. and M. Maamouri (2012). Developing LMF-XML Bilingual Dictionaries for Colloquial Arabic Dialects. LREC
2019
-
[5]
A Prototype for Projecting HPSG Syntactic Lexica Towards LMF
Haddar, K., H. Fehri and L. Romary (2012). "A Prototype for Projecting HPSG Syntactic Lexica Towards LMF." arXiv preprint arXiv:1207.5328 1(27): 21-46. Hawwari, A., M. Attia and M. Diab (2014). A framework for the classification and annotation of multiword expressions in dialectal arabic . Proceedings of the EMNLP 2014 Workshop on Arabic Natural Language ...
Pith/arXiv arXiv 2012
-
[6]
Krauwer, K
Maegaard, B., S. Krauwer, K. Choukri and L. D. Jørgensen (2006). The BLARK concept and BLARK for Arabic. LREC. Maks, I., T. Carole and V. V. Remco (2008). Standardising Bilingual Lexical Resources According to the Lexicon Markup Framework. LREC
2006
-
[7]
Mörth, K
Marrakech, Morocco. Mörth, K. (2017). Arabic lexicography in the internet era. The Routledge Handbook of Lexicography , Routledge: 503-517. Moussa, N. K. E. B. and A. M. Alimi (2015). Construction d’un Wordnet standard pour l’Arabe tunisien. The second Colloquium for Researcher Students in Natural Language Processing and its Applications (CEC-TAL 2015). N...
2017
-
[8]
State of the art in MWE processing
Ramisch, C. (2015a). Multiword Expressions Acquisition: A Generic and Open Framework . London, Springer. Ramisch, C. J. M. E. A. (2015b). "State of the art in MWE processing." 53-102. Rebdawi, G., S. Desouki and N. Ghneim (2013). "The Interactive Arabic Dictionary: Another Collaboratively Constructed Language Resource." Journal of Computer Sciences and Ap...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.