First Proof Second Batch
Pith reviewed 2026-06-27 01:05 UTC · model grok-4.3
The pith
AI systems were tested on ten research-level mathematics problems that arose in actual research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
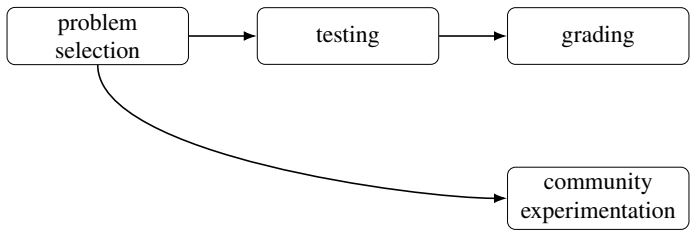
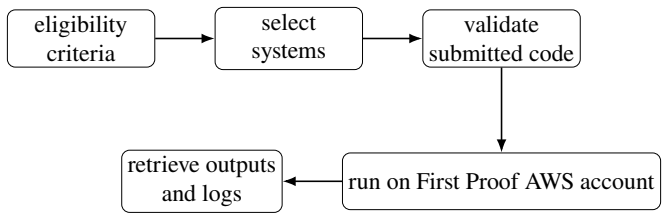
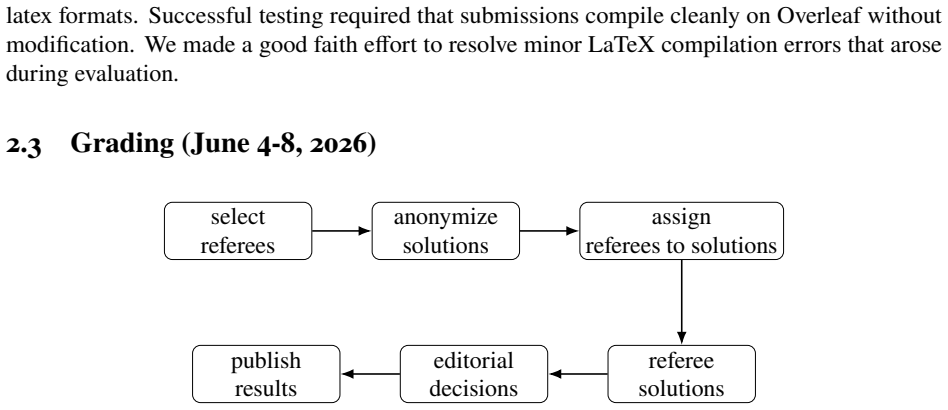
We assembled ten problems contributed by ten groups of mathematicians working in topology, combinatorics, probability, geometry, and related areas; we presented these problems to multiple AI systems under a uniform protocol; and we collected the generated solutions together with expert referee reports that document success or failure on each item.
What carries the argument
The collection of ten contributed research problems together with the fixed testing protocol and subsequent referee evaluation.
If this is right
- The reported results supply a public benchmark against which future AI models can be compared on research-style mathematics.
- The referee reports identify concrete patterns of success and failure that can guide targeted improvements in AI mathematical reasoning.
- The same contributed-problem format offers a template that other fields could adopt for realistic capability testing.
- The accompanying human solutions and logs create a reusable dataset for studying how AI outputs compare with expert reasoning on the same items.
Where Pith is reading between the lines
- Releasing the full set of problems and logs publicly could allow independent groups to run additional models or refine the evaluation criteria.
- If the same problems are reused over time, performance trends could track genuine progress in AI mathematical ability rather than benchmark overfitting.
- Extending the approach to problems that require extended computation or multi-step proofs might reveal different capability profiles than short-answer items.
Load-bearing premise
The ten problems are representative of the difficulty and structure of open research mathematics and the testing protocol does not systematically favor or disfavor the AI systems.
What would settle it
A repeat of the experiment on a fresh collection of ten research problems drawn the same way, or with modest changes to prompt wording or allowed tools, that produces substantially different overall success rates would undermine the headline assessment of AI capability.
Figures


read the original abstract
To assess the ability of current AI systems to correctly solve research-level mathematics problems, we tested several AI systems on a set of ten problems in a broad range of mathematical fields; these problems arose naturally in the research process of the contributors. This document includes the problems, our methodology, and the results of our testing. We provide links to supplementary documents including the human solutions, the AI-generated solutions, and the referee reports and logs for the AI-generated solutions. The ten problems were contributed by the following mathematicians: (1) Dariusz Kaloci\'nski and Theodore A. Slaman, (2) Richard Schwartz, (3) Aleksa Milojevic and Benny Sudakov, (4) Larry Guth, (5) Oleg Butkovsky, Jonathan Mattingly, and Lorenzo Zambotti, (6) Joshua Evan Greene and Duncan McCoy, (7) Sucharit Sarkar, (8) Sam Payne and Jidong (Jayden) Wang, (9) Sylvie Corteel and John Lentfer, (10) Srivatsav Kunnawalkam Elayavalli.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from testing multiple AI systems on a set of ten research-level mathematics problems contributed by working mathematicians across diverse fields. The problems are presented as having arisen naturally in the contributors' research; the paper describes the testing methodology, provides the problems and AI outputs, and links to human solutions plus referee reports and logs.
Significance. If the ten problems are representative in difficulty and structure of typical open research questions and if the evaluation protocol was applied uniformly without post-hoc adjustments, the study would supply useful empirical data on current AI performance on genuine research mathematics. The provision of raw AI outputs and referee logs is a positive transparency feature.
major comments (2)
- [Methodology] Methodology section: the claim that the ten problems 'arose naturally in the research process of the contributors' and therefore constitute a meaningful test of research-level mathematics is not supported by any quantitative comparison of problem difficulty, field distribution, or structural features against a reference corpus (e.g., recent arXiv math submissions or MathOverflow questions). Without such a comparison, the observed success rates cannot be generalized beyond this specific curated set.
- [Methodology] Methodology section: the description of the testing protocol (prompt templates, number of attempts allowed, tool access, and correctness criteria) does not include an explicit audit or statement confirming that the protocol was applied identically to all systems and without post-selection adjustments. This is load-bearing for any comparative performance claims.
minor comments (1)
- [Abstract] The abstract lists ten contributors but does not state how many distinct AI systems were evaluated or the exact success/failure counts; adding a concise summary table in the main text would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below.
read point-by-point responses
-
Referee: [Methodology] Methodology section: the claim that the ten problems 'arose naturally in the research process of the contributors' and therefore constitute a meaningful test of research-level mathematics is not supported by any quantitative comparison of problem difficulty, field distribution, or structural features against a reference corpus (e.g., recent arXiv math submissions or MathOverflow questions). Without such a comparison, the observed success rates cannot be generalized beyond this specific curated set.
Authors: The manuscript does not contain a quantitative comparison against a reference corpus such as recent arXiv submissions. The problems were obtained by inviting active researchers to contribute questions that had arisen in their own ongoing work, with the intent of capturing authentic research-level mathematics rather than engineered benchmarks. The paper does not claim statistical representativeness or generalizability of the observed rates to the broader space of open problems; the results are presented as empirical observations on this specific collection. We will revise the methodology section to state explicitly that the selection prioritizes natural occurrence and field diversity over statistical sampling, and that no generalization beyond the tested instances is asserted. revision: yes
-
Referee: [Methodology] Methodology section: the description of the testing protocol (prompt templates, number of attempts allowed, tool access, and correctness criteria) does not include an explicit audit or statement confirming that the protocol was applied identically to all systems and without post-selection adjustments. This is load-bearing for any comparative performance claims.
Authors: We agree that an explicit confirmation strengthens the manuscript. The protocol (including prompt templates, attempt limits, tool access, and referee-determined correctness criteria) was defined in advance and applied uniformly to every system, with all interactions recorded in the provided logs and no post-hoc changes to testing conditions. We will add a concise statement in the methodology section affirming uniform application across systems and directing readers to the supplementary logs for verification. revision: yes
Circularity Check
Empirical report of AI testing on math problems shows no circularity
full rationale
The paper is an empirical report documenting test outcomes of AI systems on ten contributed research-level math problems. No derivation chain, equations, fitted parameters, predictions, or ansatzes are present. The central claim rests on the representativeness of the problem set and protocol neutrality, which are stated as assumptions without any self-referential reduction or self-citation load-bearing. This matches the default case of a self-contained empirical study with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Schmitt, Johannes and B. I
-
[2]
Zhang, Jie and Petrui, Cezara and Nikoli. Real
-
[3]
First Proof , author =. 2026 , month =. 2602.05192 , archivePrefix=
-
[4]
On proof and progress in mathematics , author=
-
[5]
The Optimal Paper Moebius Band , author=
-
[6]
Area-expanding embeddings of rectangles , author=
-
[7]
Transactions of the American Mathematical Society , volume=
Inverting a cylinder through isometric immersions and isometric embeddings , author=. Transactions of the American Mathematical Society , volume=
-
[8]
Wunderlich, Walter , journal=
-
[9]
Ein elementarer Beweis f
Sadowsky, Michael , journal=. Ein elementarer Beweis f
-
[10]
Algebraic Topology , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.