Decision-Aware Memory Cards: Counterfactual-Inspired Context Selection and Compression for Tool-Using LLM Agents
Pith reviewed 2026-06-27 19:45 UTC · model grok-4.3
The pith
Decision-aware memory cards lift retrieval hit@1 from 0.58 to 0.78 on SWE-bench file tasks by scoring evidence on action shift and necessity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
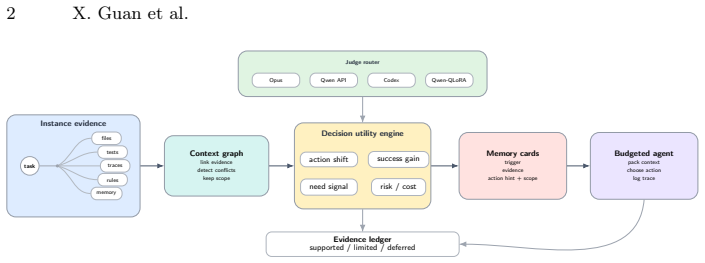
CICL is a decision-aware context layer that converts instance evidence into a context graph, obtains deterministic judgments through an eight-field schema, scores units by action shift, outcome uplift, necessity, and negative-transfer risk, and packs the highest-utility evidence as typed memory cards for budgeted agents. The same protocol produces measurable retrieval gains on SWE-bench while allowing frontier, local, and lightweight rankers to be compared directly.
What carries the argument
Eight-field schema and four scoring dimensions that isolate action-critical evidence for packing into typed memory cards.
If this is right
- Different judge models become directly comparable under one auditable protocol.
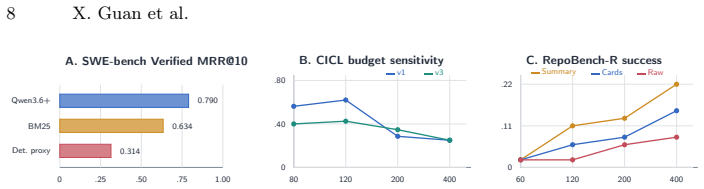
- At budget 120 the method reaches F1 0.620 on v1 and 0.425 on v3.
- Removing the single top-utility semantic unit on v3 collapses F1 to 0.000.
- Compact rankers still underperform the heuristic selection on the tested instances.
- RepoBench-R summaries continue to outperform the generated memory cards.
Where Pith is reading between the lines
- The same scoring layer could be applied to non-coding tool-use tasks where context volume limits decision quality.
- Collecting many scored judgments might supply training data that lets small rankers eventually match the current heuristic.
- The separation of decision signal from model suggests a route to track how context quality changes as base models evolve.
Load-bearing premise
The eight-field schema and four scoring dimensions reliably isolate decisive evidence rather than reflecting artifacts of the judge models or the chosen benchmark instances.
What would settle it
A controlled run on the same fifty instances where memory cards built from the scored units produce no lift over plain BM25 top-50 retrieval.
Figures
read the original abstract
Tool-using LLM agents often fail not because relevant text is absent, but because decisive evidence is not selected, compressed, or surfaced at action time. We present CICL, a decision-aware context layer that turns instance evidence into a context graph, routes deterministic, Opus-assisted, Qwen, Codex/GPT-5.5, and Qwen-QLoRA judgments through a shared eight-field schema, scores units by action shift, outcome uplift, necessity, and negative-transfer risk, and packs high-utility evidence as typed memory cards for a budgeted agent. The design separates the measured decision signal from the judge model, so frontier annotation, local surrogates, and lightweight rankers can be compared under one auditable protocol. Empirically, CICL yields a concrete open-benchmark gain while exposing its limits. On 50 SWE-bench Verified file-retrieval instances, direct Qwen3.6-plus reranking of BM25 top-50 candidates raises hit@1 from 0.58 to 0.78 and MRR@10 from 0.634 to 0.790, with all 2,500 judgments parseable. Controlled diagnostics show action-criticality: at budget 120, CICL reaches F1 0.620 on v1 and 0.425 on v3, and removing the top-utility semantic v3 unit collapses F1 to 0.000. Supplementary checks add Qwen-QLoRA agreement over 710 candidates, a small 200-label real-code Opus-assisted signal, and a three-instance patch smoke validating retrieval-to-patch plumbing without claiming official SWE-bench success. RepoBench-R summaries still beat cards, and compact rankers do not yet replace the heuristic. CICL contributes a reproducible measurement and selection layer for decision-critical context, not an end-to-end coding-agent repair claim.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CICL, a decision-aware context layer for tool-using LLM agents. Instance evidence is turned into a context graph, routed through deterministic judgments (Opus-assisted, Qwen, Codex/GPT-5.5, Qwen-QLoRA) via a shared eight-field schema, scored on action shift, outcome uplift, necessity, and negative-transfer risk, then packed as typed memory cards for budgeted agents. The design aims to separate measured decision signal from the judge model. Empirically, on 50 SWE-bench Verified file-retrieval instances, direct Qwen3.6-plus reranking of BM25 top-50 candidates raises hit@1 from 0.58 to 0.78 and MRR@10 from 0.634 to 0.790 (all 2,500 judgments parseable). Controlled diagnostics report F1 of 0.620 (v1) and 0.425 (v3) at budget 120, with removal of the top-utility v3 unit collapsing F1 to 0.000. Supplementary checks include Qwen-QLoRA agreement and a small Opus-assisted signal.
Significance. If the reported gains prove reproducible and the four scoring dimensions can be shown to isolate decision-critical evidence independently of judge-model artifacts, CICL would supply a reusable, auditable protocol for context selection and compression. The explicit separation of annotation from ranking and the F1-collapse diagnostic are strengths that could support downstream work on agent memory.
major comments (2)
- [Abstract] Abstract: The central empirical claim (hit@1 0.58→0.78, MRR@10 0.634→0.790 on 50 SWE-bench instances) rests on unverified numeric results. No details are supplied on instance-selection criteria for the 50 cases, the precise prompting templates that instantiate the eight-field schema, or any measure of cross-judge agreement on the four numeric dimensions (action shift, outcome uplift, necessity, negative-transfer risk). Without these, it cannot be established that the reranking improvement reflects decision-aware selection rather than Qwen3.6-plus stylistic preferences or SWE-bench-specific phrasing.
- [Abstract] Abstract: The controlled diagnostic that removing the top-utility semantic v3 unit collapses F1 to 0.000 is presented as evidence of action-criticality, yet no ablation replaces the schema with generic relevance labels, no correlation between schema scores and downstream agent success on held-out instances is reported, and no variance or statistical significance for the F1 values (0.620 / 0.425) is given. These omissions are load-bearing for the claim that the schema isolates decisive evidence.
minor comments (1)
- [Abstract] Abstract: The list of judge models (“Opus-assisted, Qwen, Codex/GPT-5.5, and Qwen-QLoRA”) is introduced without clarifying how their outputs are aggregated or compared under the shared schema.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on transparency and robustness of the empirical claims. We address each point below and will incorporate clarifications and additional details in a revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim (hit@1 0.58→0.78, MRR@10 0.634→0.790 on 50 SWE-bench instances) rests on unverified numeric results. No details are supplied on instance-selection criteria for the 50 cases, the precise prompting templates that instantiate the eight-field schema, or any measure of cross-judge agreement on the four numeric dimensions (action shift, outcome uplift, necessity, negative-transfer risk). Without these, it cannot be established that the reranking improvement reflects decision-aware selection rather than Qwen3.6-plus stylistic preferences or SWE-bench-specific phrasing.
Authors: We agree these details are necessary for full verification and reproducibility. The 50 instances were drawn from SWE-bench Verified file-retrieval tasks; we will specify the exact selection criteria (e.g., task filtering rules) in the revised methods section. The eight-field schema prompting templates will be included verbatim in a new appendix. While the manuscript already notes that all 2,500 judgments were parseable and reports Qwen-QLoRA agreement over 710 candidates plus a 200-label Opus-assisted signal, we will add quantitative cross-judge agreement metrics (e.g., pairwise correlations or agreement rates) specifically on the four numeric scoring dimensions. These additions will help substantiate that gains arise from decision-aware scoring rather than judge-specific effects. revision: yes
-
Referee: [Abstract] Abstract: The controlled diagnostic that removing the top-utility semantic v3 unit collapses F1 to 0.000 is presented as evidence of action-criticality, yet no ablation replaces the schema with generic relevance labels, no correlation between schema scores and downstream agent success on held-out instances is reported, and no variance or statistical significance for the F1 values (0.620 / 0.425) is given. These omissions are load-bearing for the claim that the schema isolates decisive evidence.
Authors: The F1-collapse result is presented as a targeted sensitivity check on the selected high-utility unit rather than a comprehensive proof of isolation. We acknowledge that the diagnostic would be strengthened by an ablation substituting generic relevance labels and by explicit correlations between schema scores and held-out agent performance. We will add variance estimates or bootstrap confidence intervals for the reported F1 values (0.620 on v1, 0.425 on v3) and any applicable statistical tests in the revision. A full generic-label ablation and held-out correlation analysis may require additional experiments beyond the current 50-instance controlled diagnostics; the revised text will clarify the scope and limitations of the existing diagnostic while incorporating feasible extensions. revision: partial
Circularity Check
No circularity; empirical reranking results are direct measurements, not derived by construction.
full rationale
The paper reports concrete benchmark numbers (hit@1 0.58→0.78, MRR@10 0.634→0.790) obtained by routing BM25 candidates through an eight-field schema and four scoring dimensions, then measuring retrieval metrics on 50 SWE-bench instances. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the provided text. The central claims rest on parseable judgments and controlled diagnostics rather than any reduction of outputs to inputs by definition. This is the standard case of an empirical measurement protocol whose validity is open to external verification.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: International Conference on Learning Representations (2023), https://openreview
Yao, S., et al.: React: Synergizing reasoning and acting in language models. In: International Conference on Learning Representations (2023), https://openreview. net/forum?id=WE_vluYUL-X 14 X. Guan et al
2023
-
[2]
In: Advances in Neural Information Processing Systems (2023), https://arxiv.org/ abs/2302.04761
Schick, T., et al.: Toolformer: Language models can teach themselves to use tools. In: Advances in Neural Information Processing Systems (2023), https://arxiv.org/ abs/2302.04761
Pith/arXiv arXiv 2023
-
[3]
In: Advances in Neural Information Processing Systems (2023), https://arxiv.org/abs/2303.11366
Shinn,N.,Cassano,F.,Gopinath,A.,Narasimhan,K.,Yao,S.:Reflexion:Language agents with verbal reinforcement learning. In: Advances in Neural Information Processing Systems (2023), https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[4]
Wang, G., et al.: Voyager: An open-ended embodied agent with large language models (2023), https://arxiv.org/abs/2305.16291
Pith/arXiv arXiv 2023
-
[5]
Yang, J., et al.: SWE-agent: Agent-computer interfaces enable automated software engineering (2024), https://arxiv.org/abs/2405.15793
Pith/arXiv arXiv 2024
-
[6]
Li, H., et al.: Contextbench: A benchmark for context retrieval in coding agents (2026), https://arxiv.org/abs/2602.05892
arXiv 2026
-
[7]
Zhu, J., et al.: Swe context bench: A benchmark for context learning in coding (2026), https://arxiv.org/abs/2602.08316
Pith/arXiv arXiv 2026
-
[8]
Wu, Q., et al.: Autogen: Enabling next-gen llm applications via multi-agent con- versation (2023), https://arxiv.org/abs/2308.08155
Pith/arXiv arXiv 2023
-
[9]
Qian, C., et al.: Communicative agents for software development (2023), https: //arxiv.org/abs/2307.07924
Pith/arXiv arXiv 2023
-
[10]
He, Z., et al.: Memoryarena: Benchmarking agent memory in interdependent multi- session agentic tasks (2026), https://arxiv.org/abs/2602.16313
arXiv 2026
-
[11]
Hu, Y., Wang, Y., McAuley, J.: Evaluating memory in llm agents via incremental multi-turn interactions (2025), https://arxiv.org/abs/2507.05257
Pith/arXiv arXiv 2025
-
[12]
Wang, Y., et al.: Evomembench: Benchmarking agent memory from a self-evolving perspective (2026), https://arxiv.org/abs/2605.18421
Pith/arXiv arXiv 2026
-
[13]
Xia, C.S., Deng, Y., Dunn, S., Zhang, L.: Agentless: Demystifying llm-based soft- ware engineering agents (2024), https://arxiv.org/abs/2407.01489
Pith/arXiv arXiv 2024
-
[14]
Wang, X., et al.: Openhands: An open platform for ai software developers as gen- eralist agents (2024), https://arxiv.org/abs/2407.16741
Pith/arXiv arXiv 2024
-
[15]
In: Transactions on Machine Learning Research (2022), https://arxiv.org/abs/ 2112.09118
Izacard, G., et al.: Unsupervised dense information retrieval with contrastive learn- ing. In: Transactions on Machine Learning Research (2022), https://arxiv.org/abs/ 2112.09118
Pith/arXiv arXiv 2022
-
[16]
IEEE Transactions on Big Data (2019), https://arxiv.org/abs/1702.08734
Johnson, J., Douze, M., Jégou, H.: Billion-scale similarity search with gpus. IEEE Transactions on Big Data (2019), https://arxiv.org/abs/1702.08734
Pith/arXiv arXiv 2019
-
[17]
In: Advances in Neural Information Processing Systems (2020), https://arxiv.org/ abs/2005.11401
Lewis, P., et al.: Retrieval-augmented generation for knowledge-intensive nlp tasks. In: Advances in Neural Information Processing Systems (2020), https://arxiv.org/ abs/2005.11401
Pith/arXiv arXiv 2020
-
[18]
In: International Conference on Learning Representations (2023), https://arxiv
Izacard, G., et al.: Few-shot learning with retrieval augmented language models. In: International Conference on Learning Representations (2023), https://arxiv. org/abs/2208.03299
Pith/arXiv arXiv 2023
-
[19]
Gao, L., Ma, X., Lin, J., Callan, J.: Precise zero-shot dense retrieval without rele- vance labels. In: Annual Meeting of the Association for Computational Linguistics (2023), https://arxiv.org/abs/2212.10496
arXiv 2023
-
[20]
In: International Conference on Learning Representations (2024), https: //arxiv.org/abs/2310.11511
Asai, A., et al.: Self-rag: Learning to retrieve, generate, and critique through self- reflection. In: International Conference on Learning Representations (2024), https: //arxiv.org/abs/2310.11511
Pith/arXiv arXiv 2024
-
[21]
Liu, N.F., et al.: Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics (2024), https:// arxiv.org/abs/2307.03172
Pith/arXiv arXiv 2024
-
[22]
Bai, Y., et al.: Longbench: A bilingual, multitask benchmark for long context understanding (2023), https://arxiv.org/abs/2308.14508 Decision-Aware Memory Cards for LLM Agents 15
Pith/arXiv arXiv 2023
-
[23]
Cai, K., et al.: Autocontext: Instance-level context learning for llm agents (2025), https://arxiv.org/abs/2510.02369
arXiv 2025
-
[24]
Zhang, Q., et al.: Agentic context engineering: Evolving contexts for self-improving language models (2025), https://arxiv.org/abs/2510.04618
Pith/arXiv arXiv 2025
-
[25]
Kang, M., et al.: Acon: Optimizing context compression for long-horizon llm agents (2025), https://arxiv.org/abs/2510.00615
Pith/arXiv arXiv 2025
-
[26]
Srivastava, S.S.: Causal intervention-based memory selection for long-horizon llm agents (2026), https://arxiv.org/abs/2605.17641
Pith/arXiv arXiv 2026
-
[27]
Huo,Y.,etal.:Reposhapley:Shapley-enhancedcontextfilteringforrepository-level code completion (2026), https://arxiv.org/abs/2601.03378
Pith/arXiv arXiv 2026
-
[28]
Robertson, S., Zaragoza, H.: The probabilistic relevance framework: BM25 and beyond. In: Foundations and Trends in Information Retrieval. Now Publishers (2009), https://doi.org/10.1561/1500000019
-
[29]
In: Empirical Methods in Natural Language Processing (2020), https://arxiv.org/ abs/2004.04906
Karpukhin, V., et al.: Dense passage retrieval for open-domain question answering. In: Empirical Methods in Natural Language Processing (2020), https://arxiv.org/ abs/2004.04906
Pith/arXiv arXiv 2020
-
[30]
In: SIGIR (2020), https://arxiv.org/ abs/2004.12832
Khattab, O., Zaharia, M.: ColBERT: Efficient and effective passage search via contextualized late interaction over BERT. In: SIGIR (2020), https://arxiv.org/ abs/2004.12832
arXiv 2020
-
[31]
In: Empirical Methods in Natural Language Processing (2023), https://arxiv.org/abs/2310.05736
Jiang, H., et al.: LLMLingua: Compressing prompts for accelerated inference of large language models. In: Empirical Methods in Natural Language Processing (2023), https://arxiv.org/abs/2310.05736
arXiv 2023
-
[32]
Jiang, H., et al.: Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. In: Annual Meeting of the Association for Com- putational Linguistics (2024), https://arxiv.org/abs/2310.06839
arXiv 2024
-
[33]
Li, Y., Dong, B., Lin, C., Guerin, F.: Selective context: Efficient and context-aware prompt compression (2023), https://arxiv.org/abs/2304.12102
arXiv 2023
-
[34]
In: Advances in Neural Information Processing Systems (2022), https: //arxiv.org/abs/2203.02155
Ouyang, L., et al.: Training language models to follow instructions with human feedback. In: Advances in Neural Information Processing Systems (2022), https: //arxiv.org/abs/2203.02155
Pith/arXiv arXiv 2022
-
[35]
In: Advances in Neural Information Processing Systems (2020), https://arxiv.org/abs/2009.01325
Stiennon, N., et al.: Learning to summarize with human feedback. In: Advances in Neural Information Processing Systems (2020), https://arxiv.org/abs/2009.01325
Pith/arXiv arXiv 2020
-
[36]
In: Inter- national Conference on Learning Representations (2022), https://arxiv.org/abs/ 2106.09685
Hu, E.J., et al.: LoRA: Low-rank adaptation of large language models. In: Inter- national Conference on Learning Representations (2022), https://arxiv.org/abs/ 2106.09685
Pith/arXiv arXiv 2022
-
[37]
In: Advances in Neural Information Processing Systems (2023), https://arxiv.org/abs/2305.14314
Dettmers, T., Pagnoni, A., Holtzman, A., Zettlemoyer, L.: QLoRA: Efficient fine- tuning of quantized llms. In: Advances in Neural Information Processing Systems (2023), https://arxiv.org/abs/2305.14314
Pith/arXiv arXiv 2023
-
[38]
Jimenez, C.E., et al.: SWE-bench: Can language models resolve real-world github issues? In: International Conference on Learning Representations (2024), https: //arxiv.org/abs/2310.06770
Pith/arXiv arXiv 2024
-
[39]
Liu,T.,Xu,C.,McAuley,J.:Repobench:Benchmarkingrepository-levelcodeauto- completion systems (2023), https://arxiv.org/abs/2306.03091
Pith/arXiv arXiv 2023
-
[40]
Husain, H., et al.: Codesearchnet challenge: Evaluating the state of semantic code search. In: NeurIPS Workshop on Machine Learning for Software Engineering (2019), https://arxiv.org/abs/1909.09436
Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.