Gradient-Based Join Ordering
Pith reviewed 2026-05-21 18:55 UTC · model grok-4.3
The pith
Join ordering can be reframed as gradient descent over a continuous relaxation of plans when the cost model is differentiable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the cost model is differentiable, query plans can be continuously relaxed into a soft adjacency matrix that represents a superposition of plans. This continuous relaxation, combined with differentiable constraints that enforce plan validity, enables a gradient-based search for low-cost plans within this relaxed space.
What carries the argument
Soft adjacency matrix that encodes a continuous superposition of binary join trees, optimized by gradient descent under differentiable validity constraints.
If this is right
- Gradient search guided by a GNN cost model produces plans whose execution costs are comparable to or lower than those found by dynamic programming or other discrete methods on the tested graph datasets.
- Runtime of the gradient procedure grows more slowly than discrete enumeration as query size increases.
- The same continuous relaxation can be reused with any differentiable cost model, opening the door to joint optimization of ordering and other query parameters.
Where Pith is reading between the lines
- The approach could be combined with learned cost models that are already being trained end-to-end for other database tasks.
- It may extend naturally to join ordering under uncertainty, where the cost surface is stochastic rather than deterministic.
- Similar continuous relaxations might apply to other combinatorial choices in query optimization such as predicate push-down or index selection.
Load-bearing premise
Local minima of the relaxed objective under the differentiable cost model correspond to valid, low-cost query plans.
What would settle it
On a benchmark query whose optimal plan cost is known exactly, run the gradient procedure from multiple random starts and check whether any recovered plan has cost equal to or lower than the known optimum.
Figures



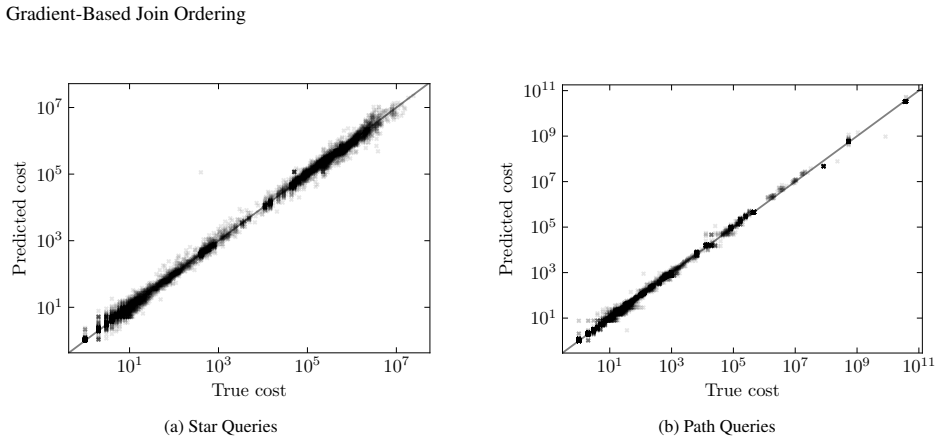




read the original abstract
Join ordering is the NP-hard problem of selecting the most efficient order in which to evaluate joins (conjunctive, binary operators) in a database query. Because query execution performance critically depends on this choice, join ordering lies at the core of query optimization. Traditional approaches cast this problem as a discrete combinatorial search over binary trees guided by a cost model, but they have trade-offs between effectiveness and efficiency. We show that when the cost model is differentiable, query plans can be continuously relaxed into a soft adjacency matrix that represents a superposition of plans. This continuous relaxation, combined with differentiable constraints that enforce plan validity, enables a gradient-based search for low-cost plans within this relaxed space. Using a Graph Neural Network as the cost model, we demonstrate that this gradient-based approach can find comparable and even lower-cost plans compared to traditional discrete search methods on two different graph datasets. Furthermore, we empirically show that the runtime of this approach scales better than discrete search algorithms. We believe this first step towards gradient-based join ordering can lead to more effective and efficient query optimizers in the future.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes relaxing the NP-hard join ordering problem into a continuous optimization task by representing query plans as a soft adjacency matrix over tables. This relaxation is optimized via gradient descent using a differentiable Graph Neural Network (GNN) cost model together with differentiable validity constraints that enforce plan validity. On two graph datasets the method is reported to produce plans whose costs are comparable to or lower than those found by traditional discrete search algorithms, while also exhibiting better runtime scaling.
Significance. If the central empirical claims hold after addressing validity enforcement and experimental rigor, the work would open a new direction for query optimization that integrates continuous relaxation, gradient-based search, and learned differentiable cost models. The approach could improve scalability for complex queries where discrete enumeration becomes intractable, and the use of GNNs as cost models is a concrete strength that enables end-to-end differentiability.
major comments (3)
- [§3] §3 (Method, validity constraints): The paper describes differentiable validity terms but does not specify whether these are implemented as hard differentiable projections onto the space of binary trees or as soft Lagrangian penalties. Without an explicit operator or post-hoc validity rate after rounding/argmax, it is unclear whether converged points decode to executable plans with exactly n-1 binary joins, no cycles, and a single root; this directly affects whether the reported lower-cost plans are genuine or artifacts of incomplete enforcement.
- [Experimental evaluation] Experimental evaluation (results on two graph datasets): The abstract and results section report comparable or lower costs and better scaling but supply no error bars, exact baseline implementations, dataset cardinalities, number of queries, or ablation studies on the validity mechanism. This leaves the headline claim that the gradient-based method outperforms or matches discrete search on a preliminary footing.
- [§4] §4 (Empirical results): The claim that local minima in the relaxed space correspond to valid low-cost plans relies on the unstated assumption that the continuous relaxation plus validity terms produce a search landscape whose optima are decodable to tree-structured plans; no supporting analysis or counter-example checks are provided.
minor comments (2)
- [Abstract] The abstract would benefit from naming the two graph datasets and briefly indicating their sizes or characteristics.
- [§3] Notation for the soft adjacency matrix and the decoding step (rounding or argmax) should be introduced with a small illustrative example for a 3- or 4-table query.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each of the major comments below and will make revisions to improve clarity and rigor as suggested.
read point-by-point responses
-
Referee: [§3] §3 (Method, validity constraints): The paper describes differentiable validity terms but does not specify whether these are implemented as hard differentiable projections onto the space of binary trees or as soft Lagrangian penalties. Without an explicit operator or post-hoc validity rate after rounding/argmax, it is unclear whether converged points decode to executable plans with exactly n-1 binary joins, no cycles, and a single root; this directly affects whether the reported lower-cost plans are genuine or artifacts of incomplete enforcement.
Authors: We implemented the validity constraints as soft Lagrangian penalties to preserve end-to-end differentiability throughout the optimization process. In the revised manuscript, we will explicitly describe the penalty formulation, the operator used for decoding, and include a post-hoc validity rate measured after applying argmax to the soft adjacency matrix. This will confirm that the optimized plans decode to valid tree-structured join orders with the required properties. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation (results on two graph datasets): The abstract and results section report comparable or lower costs and better scaling but supply no error bars, exact baseline implementations, dataset cardinalities, number of queries, or ablation studies on the validity mechanism. This leaves the headline claim that the gradient-based method outperforms or matches discrete search on a preliminary footing.
Authors: We agree that additional experimental details are necessary for reproducibility and to strengthen the claims. In the revision, we will add error bars to the reported costs, provide exact descriptions of the baseline implementations, specify dataset cardinalities and the number of queries evaluated, and include ablation studies isolating the effect of the validity mechanism. These additions will place the empirical results on a firmer footing. revision: yes
-
Referee: [§4] §4 (Empirical results): The claim that local minima in the relaxed space correspond to valid low-cost plans relies on the unstated assumption that the continuous relaxation plus validity terms produce a search landscape whose optima are decodable to tree-structured plans; no supporting analysis or counter-example checks are provided.
Authors: To address this, we will include in the revised manuscript an analysis of the optimization landscape, such as the frequency with which local minima decode to valid plans, along with checks for counter-examples where invalid structures arise. This will support the correspondence between continuous optima and valid low-cost plans. revision: yes
Circularity Check
No circularity: derivation relies on external GNN cost model and empirical comparison to discrete baselines
full rationale
The paper relaxes join ordering to a soft adjacency matrix optimized via gradients from a GNN cost model plus differentiable validity terms. No equation or step in the provided abstract or description reduces a reported performance number to a quantity defined by parameters fitted inside the same paper. The GNN is treated as an external learned component, results are benchmarked against traditional discrete search methods on separate graph datasets, and no self-citation chain or self-definitional construction is present. The central claim therefore remains independent of its own fitted inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The cost model is differentiable.
- domain assumption Differentiable constraints can enforce plan validity inside the continuous relaxation.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
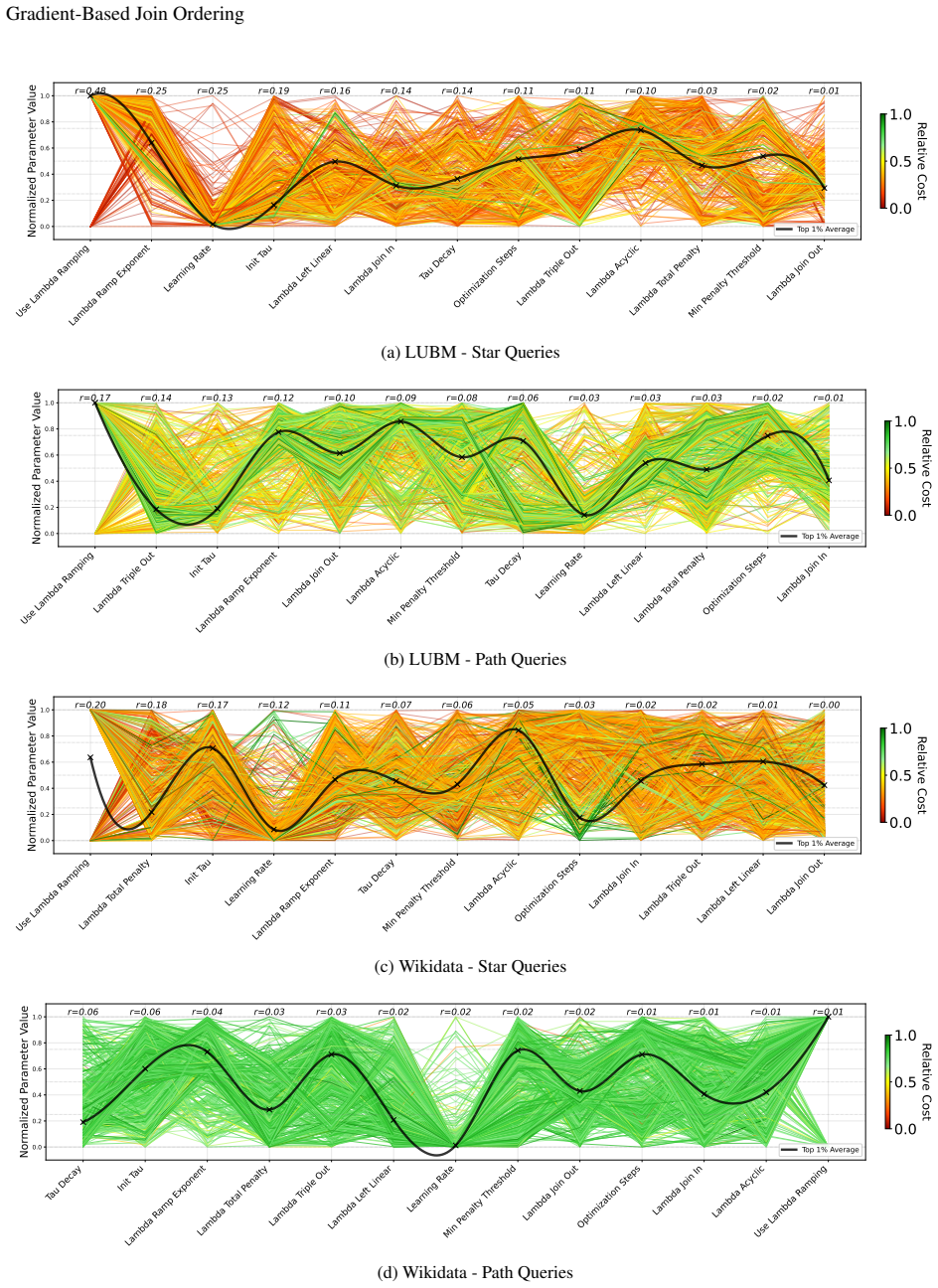
We relax the binary adjacency matrix A ∈ {0,1}^{N×N} by introducing a real-valued logit matrix L … A_soft = softmax((L+G)/τ) … P_STRUCT = λ_TO P_TO + … + λ_ACYC tr(e^{A_soft}) − N … L_t = Ĉ_θ(X, A_soft) + λ(t) P_STRUCT
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a Graph Neural Network as the cost model … gradient-based search … scales linearly with query size
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
On the complexity of generating optimal left-deep processing trees with cross products
Sophie Cluet and Guido Moerkotte. On the complexity of generating optimal left-deep processing trees with cross products. In Georg Gottlob and Moshe Y . Vardi, editors,Database Theory - ICDT’95, 5th International Conference, Prague, Czech Republic, January 11-13, 1995, Proceedings, volume 893 ofLecture Notes in Computer Science, pages 54–67. Springer, 1995
work page 1995
-
[2]
Patricia G. Selinger, Morton M. Astrahan, Donald D. Chamberlin, Raymond A. Lorie, and Thomas G. Price. Access path selection in a relational database management system. In Philip A. Bernstein, editor,Proceedings of the 1979 ACM SIGMOD International Conference on Management of Data, Boston, Massachusetts, USA, May 30 - June 1, pages 23–34. ACM, 1979
work page 1979
-
[3]
Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter A. Boncz, and Alfons Kemper. Learned cardinalities: Estimating correlated joins with deep learning. In9th Biennial Conference on Innovative Data Systems Research, CIDR 2019, Asilomar, CA, USA, January 13-16, 2019, Online Proceedings. www.cidrdb.org, 2019
work page 2019
-
[4]
An end-to-end learning-based cost estimator.Proc
Ji Sun and Guoliang Li. An end-to-end learning-based cost estimator.Proc. VLDB Endow., 13(3):307–319, 2019
work page 2019
-
[5]
Queryformer: A tree transformer model for query plan representation.Proc
Yue Zhao, Gao Cong, Jiachen Shi, and Chunyan Miao. Queryformer: A tree transformer model for query plan representation.Proc. VLDB Endow., 15(8):1658–1670, 2022
work page 2022
-
[6]
Cardinality estimation over knowledge graphs with embeddings and graph neural networks.Proc
Tim Schwabe and Maribel Acosta. Cardinality estimation over knowledge graphs with embeddings and graph neural networks.Proc. ACM Manag. Data, 2(1):44:1–44:26, 2024
work page 2024
-
[7]
A learned sketch for subgraph counting
Kangfei Zhao, Jeffrey Xu Yu, Hao Zhang, Qiyan Li, and Yu Rong. A learned sketch for subgraph counting. In Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava, editors,SIGMOD ’21: International Conference on Management of Data, Virtual Event, China, June 20-25, 2021, pages 2142–2155. ACM, 2021
work page 2021
-
[8]
Mehmet Aytimur, Theodoros Chondrogiannis, and Michael Grossniklaus. Space: Cardinality estimation for path queries using cardinality-aware sequence-based learning.Proceedings of the ACM on Management of Data, 3(3):1–26, 2025
work page 2025
-
[9]
Sparql query execution time prediction using deep learning
Daniel Casals, Carlos Buil-Aranda, and Carlos Valle. Sparql query execution time prediction using deep learning. 2023
work page 2023
-
[10]
Planrgcn: Predicting sparql query performance
Abiram Mohanaraj, Matteo Lissandrini, Katja Hose, et al. Planrgcn: Predicting sparql query performance. PROCEEDINGS OF THE VLDB ENDOWMENT, 18(6):1621–1634, 2025
work page 2025
-
[11]
Deep reinforcement learning for join order enumeration
Ryan Marcus and Olga Papaemmanouil. Deep reinforcement learning for join order enumeration. In Rajesh Bordawekar and Oded Shmueli, editors,Proceedings of the First International Workshop on Exploiting Artificial Intelligence Techniques for Data Management, aiDM@SIGMOD 2018, Houston, TX, USA, June 10, 2018, pages 3:1–3:4. ACM, 2018
work page 2018
-
[12]
Efficient join order selection learning with graph-based representation
Jin Chen, Guanyu Ye, Yan Zhao, Shuncheng Liu, Liwei Deng, Xu Chen, Rui Zhou, and Kai Zheng. Efficient join order selection learning with graph-based representation. In Aidong Zhang and Huzefa Rangwala, editors, KDD ’22: The 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, August 14 - 18, 2022, pages 97–107. ACM, 2022
work page 2022
-
[13]
Reinforcement learning with tree-lstm for join order selection
Xiang Yu, Guoliang Li, Chengliang Chai, and Nan Tang. Reinforcement learning with tree-lstm for join order selection. In36th IEEE International Conference on Data Engineering, ICDE 2020, Dallas, TX, USA, April 20-24, 2020, pages 1297–1308. IEEE, 2020
work page 2020
-
[14]
Neo: A learned query optimizer.Proc
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime Tatbul. Neo: A learned query optimizer.Proc. VLDB Endow., 12(11):1705–1718, 2019
work page 2019
-
[15]
LOGER: A learned optimizer towards generating efficient and robust query execution plans.Proc
Tianyi Chen, Jun Gao, Hedui Chen, and Yaofeng Tu. LOGER: A learned optimizer towards generating efficient and robust query execution plans.Proc. VLDB Endow., 16(7):1777–1789, 2023
work page 2023
-
[16]
Zhengtong Yan, Valter Uotila, and Jiaheng Lu. Join order selection with deep reinforcement learning: Fundamen- tals, techniques, and challenges.Proc. VLDB Endow., 16(12):3882–3885, 2023
work page 2023
-
[17]
Learned query optimizer: What is new and what is next
Rong Zhu, Lianggui Weng, Bolin Ding, and Jingren Zhou. Learned query optimizer: What is new and what is next. In Pablo Barceló, Nayat Sánchez-Pi, Alexandra Meliou, and S. Sudarshan, editors,Companion of the 2024 International Conference on Management of Data, SIGMOD/PODS 2024, Santiago, Chile, June 9-15, 2024, pages 561–569. ACM, 2024
work page 2024
-
[18]
Maribel Acosta, Chang Qin, and Tim Schwabe.Neuro-Symbolic Query Optimization in Knowledge Graphs. IOS Press, March 2025. 12 Gradient-Based Join Ordering
work page 2025
-
[19]
DARTS: differentiable architecture search
Hanxiao Liu, Karen Simonyan, and Yiming Yang. DARTS: differentiable architecture search. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
work page 2019
-
[20]
SNAS: stochastic neural architecture search
Sirui Xie, Hehui Zheng, Chunxiao Liu, and Liang Lin. SNAS: stochastic neural architecture search. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
work page 2019
-
[21]
Differentiable synthesis of program architectures
Guofeng Cui and He Zhu. Differentiable synthesis of program architectures. In Marc’Aurelio Ranzato, Alina Beygelzimer, Yann N. Dauphin, Percy Liang, and Jennifer Wortman Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 1...
work page 2021
-
[22]
Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard S
Thomas N. Kipf, Ethan Fetaya, Kuan-Chieh Wang, Max Welling, and Richard S. Zemel. Neural relational inference for interacting systems. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 ofProceedings of Machine Learn...
work page 2018
-
[23]
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing. Dags with NO TEARS: continuous optimization for structure learning. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa- Bianchi, and Roman Garnett, editors,Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Syste...
work page 2018
-
[24]
On the role of sparsity and DAG constraints for learning linear dags
Ignavier Ng, AmirEmad Ghassami, and Kun Zhang. On the role of sparsity and DAG constraints for learning linear dags. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria-Florina Balcan, and Hsuan-Tien Lin, editors,Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, D...
work page 2020
-
[25]
V owels, Necati Cihan Camgöz, and Richard Bowden
Matthew J. V owels, Necati Cihan Camgöz, and Richard Bowden. D’ya like dags? A survey on structure learning and causal discovery.ACM Comput. Surv., 55(4):82:1–82:36, 2023
work page 2023
-
[26]
Seo, Y ., Sferrazza, C., Chen, J., Shi, G., Duan, R., and Abbeel, P
Jyothir S. V , Siddhartha Jalagam, Yann LeCun, and Vlad Sobal. Gradient-based planning with world models. CoRR, abs/2312.17227, 2023
-
[27]
Categorical reparameterization with gumbel-softmax
Eric Jang, Shixiang Gu, and Ben Poole. Categorical reparameterization with gumbel-softmax. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017
work page 2017
-
[28]
Maddison, Andriy Mnih, and Yee Whye Teh
Chris J. Maddison, Andriy Mnih, and Yee Whye Teh. The concrete distribution: A continuous relaxation of discrete random variables. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017
work page 2017
-
[29]
Jing Liu, Fei Gao, and Jiang Zhang. Gumbel-softmax optimization: A simple general framework for combinatorial optimization problems on graphs. In Hocine Cherifi, Sabrina Gaito, José Fernendo Mendes, Esteban Moro, and Luis Mateus Rocha, editors,Complex Networks and Their Applications VIII - Volume 1 Proceedings of the Eighth International Conference on Com...
work page 2019
-
[30]
Stochastic optimization of sorting networks via continuous relaxations
Aditya Grover, Eric Wang, Aaron Zweig, and Stefano Ermon. Stochastic optimization of sorting networks via continuous relaxations. In7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
work page 2019
-
[31]
Sparql-to-text question generation for knowledge-based conversational applications
Gwénolé Lecorvé, Morgan Veyret, Quentin Brabant, and Lina Maria Rojas-Barahona. Sparql-to-text question generation for knowledge-based conversational applications. In Yulan He, Heng Ji, Yang Liu, Sujian Li, Chia-Hui Chang, Soujanya Poria, Chenghua Lin, Wray L. Buntine, Maria Liakata, Hanqi Yan, Zonghan Yan, Sebastian Ruder, Xiaojun Wan, Miguel Arana-Catan...
work page 2022
-
[32]
Softsort: A continuous relaxation for the argsort operator
Sebastian Prillo and Julian Martin Eisenschlos. Softsort: A continuous relaxation for the argsort operator. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event, volume 119 ofProceedings of Machine Learning Research, pages 7793–7802. PMLR, 2020
work page 2020
-
[33]
LUBM: A benchmark for OWL knowledge base systems.J
Yuanbo Guo, Zhengxiang Pan, and Jeff Heflin. LUBM: A benchmark for OWL knowledge base systems.J. Web Semant., 3(2-3):158–182, 2005. 13 Gradient-Based Join Ordering
work page 2005
-
[34]
KEPLER: A unified model for knowledge embedding and pre-trained language representation.Trans
Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, Zhengyan Zhang, Zhiyuan Liu, Juanzi Li, and Jian Tang. KEPLER: A unified model for knowledge embedding and pre-trained language representation.Trans. Assoc. Comput. Linguistics, 9:176–194, 2021
work page 2021
-
[35]
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019
work page 2019
-
[36]
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought.CoRR, abs/2505.12514, 2025
-
[37]
Rdf2vec: RDF graph embeddings for data mining
Petar Ristoski and Heiko Paulheim. Rdf2vec: RDF graph embeddings for data mining. In Paul Groth, Elena Simperl, Alasdair J. G. Gray, Marta Sabou, Markus Krötzsch, Freddy Lécué, Fabian Flöck, and Yolanda Gil, editors,The Semantic Web - ISWC 2016 - 15th International Semantic Web Conference, Kobe, Japan, October 17-21, 2016, Proceedings, Part I, volume 9981...
work page 2016
-
[38]
Tune: A Research Platform for Distributed Model Selection and Training
Richard Liaw, Eric Liang, Robert Nishihara, Philipp Moritz, Joseph E Gonzalez, and Ion Stoica. Tune: A research platform for distributed model selection and training.arXiv preprint arXiv:1807.05118, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[39]
Optuna: A next-generation hyperparameter optimization framework
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. Optuna: A next-generation hyperparameter optimization framework. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2019. 14 Gradient-Based Join Ordering A Cost Model Details A.1 Join and Triple Pattern Representation We repre...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.