OmniTryOn: Video Try-On Anything at Once!
Pith reviewed 2026-06-27 18:59 UTC · model grok-4.3
The pith
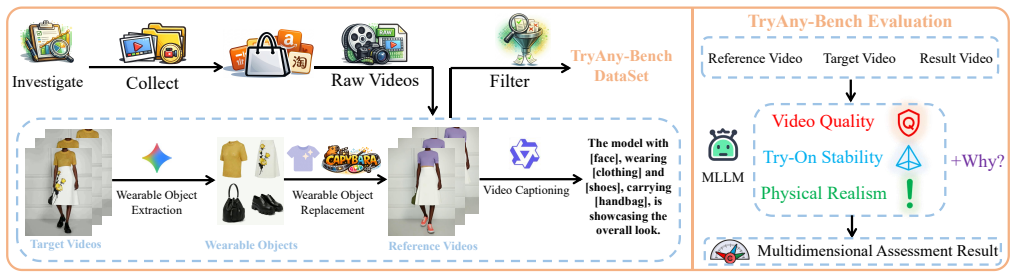
OmniTryOn enables simultaneous transfer of diverse wearable objects onto video subjects in one pass without external priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
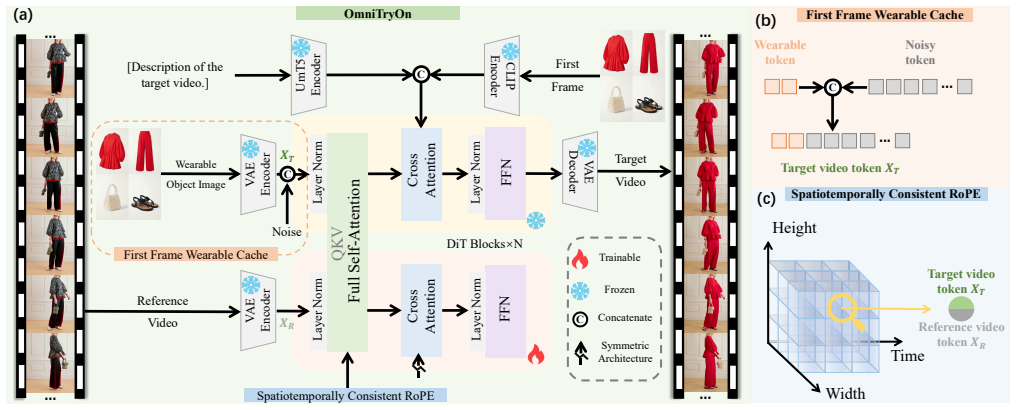
OmniTryOn is an external-prior-free generative framework that employs the First Frame Wearable Cache strategy to supply diverse wearable objects directly from the initial video frame and the Spatiotemporally Consistent RoPE (STC-RoPE) to establish robust spatiotemporal anchors preserving complex human motions and background dynamics, optimized by the Gradual Try-On (GTO) training strategy to master multi-object synthesis.
What carries the argument
First Frame Wearable Cache strategy together with Spatiotemporally Consistent RoPE (STC-RoPE), which supplies objects from the first frame and maintains spatiotemporal consistency.
If this is right
- Simultaneous multi-object try-on becomes feasible in a single inference without separate mask preparation.
- Physical dynamics remain intact because explicit external priors are not required.
- The TryAny-Bench benchmark provides a standardized way to compare methods on this new task.
- Gradual Try-On training progressively improves the model's ability to synthesize multiple objects together.
Where Pith is reading between the lines
- The same first-frame caching idea could be tested on other video object-insertion problems such as accessory or background element transfer.
- The benchmark may push future models to handle longer sequences or higher object counts while keeping the no-prior constraint.
- Real-time applications could become viable if the inference cost of the cache and RoPE modifications is further reduced.
Load-bearing premise
That caching objects from the first frame and applying STC-RoPE can deliver diverse items while preserving motion and background dynamics without any external masks or priors.
What would settle it
Test videos containing rapid pose changes or overlapping wearables in which the output shows drifting object identity, broken motion continuity, or visible artifacts relative to the input sequence.
Figures




read the original abstract
Although video virtual try-on (VVT) has achieved significant progress, existing methods still exhibit two fundamental limitations: first, they are restricted to single-garment transfer, rendering simultaneous multi-object try-on highly impractical; second, their heavy reliance on explicit external priors (e.g., garment masks) inevitably destroys crucial physical dynamics and degrades visual quality. To bridge this gap, this paper proposes the novel Try-On Anything task, which aims to simultaneously transfer diverse wearable objects onto a person in a video in a single inference pass. To support and standardize this paradigm, we introduce TryAny-Bench, a comprehensive benchmark encompassing a paired video dataset alongside a tailored evaluation protocol. Furthermore, we present OmniTryOn, an external-prior-free generative framework designed to tackle this task. Specifically, OmniTryOn employs a First Frame Wearable Cache strategy, which directly provides diverse wearable objects for the generation process through the initial video frame. To maintain consistency, we propose the Spatiotemporally Consistent RoPE (STC-RoPE), which inherently establishes robust spatiotemporal anchors to strictly preserve complex human motions and background dynamics. Optimized by the proposed Gradual Try-On (GTO) training strategy, our model progressively masters robust multi-object synthesis. Extensive experiments on TryAny-Bench demonstrate that OmniTryOn significantly outperforms existing specialized video virtual try-on models and general video editing baselines, establishing a powerful new standard for the Try-On Anything task. Our dataset, code, and models are available at https://github.com/xcltql666/OminTryOn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Try-On Anything task for simultaneous multi-object wearable transfer in a single video inference pass without external priors such as garment masks. It defines TryAny-Bench as a paired video dataset with a tailored evaluation protocol, and proposes OmniTryOn, which uses a First Frame Wearable Cache to supply objects, Spatiotemporally Consistent RoPE (STC-RoPE) for motion and background preservation, and Gradual Try-On (GTO) training. The central claim is that OmniTryOn significantly outperforms specialized video virtual try-on models and general video editing baselines on TryAny-Bench.
Significance. If the results hold, the work is significant for defining a new multi-object video try-on paradigm that avoids external priors known to degrade physical dynamics. The open release of the benchmark dataset, code, and models is a clear strength that supports reproducibility and future work. The approach could set a new standard if the proposed components demonstrably maintain spatiotemporal consistency across diverse objects.
major comments (1)
- Abstract: the claim that OmniTryOn 'significantly outperforms' existing models is presented without any quantitative metrics, tables, error bars, dataset statistics, or ablation results, which is load-bearing for the central experimental claim and prevents verification of the data-to-claim link.
minor comments (1)
- Abstract, GitHub link: the URL contains a typographical error ('OminTryOn' instead of 'OmniTryOn').
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address the concern below and will make the requested revision to strengthen the presentation of our central claim.
read point-by-point responses
-
Referee: [—] Abstract: the claim that OmniTryOn 'significantly outperforms' existing models is presented without any quantitative metrics, tables, error bars, dataset statistics, or ablation results, which is load-bearing for the central experimental claim and prevents verification of the data-to-claim link.
Authors: We agree that the abstract's claim would be more verifiable if supported by key quantitative results. While the full manuscript provides detailed tables, error bars, dataset statistics, and ablations in the experiments section, we will revise the abstract to concisely include representative metrics demonstrating outperformance on TryAny-Bench (e.g., improvements over baselines in the primary evaluation metrics). This will make the abstract self-contained without exceeding typical length constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces the Try-On Anything task, TryAny-Bench benchmark, and OmniTryOn framework (First Frame Wearable Cache + STC-RoPE + GTO) as new contributions without any self-definitional equations, fitted inputs renamed as predictions, or load-bearing self-citations. No derivation chain reduces to its own inputs by construction; performance claims rest on external comparison to prior specialized models on the newly defined benchmark.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, et al. 2023. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 2023. Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22563–22575. 8
2023
-
[4]
Ryan Burgert, Yuancheng Xu, Wenqi Xian, Oliver Pilarski, Pascal Clausen, Ming- ming He, Li Ma, Yitong Deng, Lingxiao Li, Mohsen Mousavi, et al. 2025. Go-with- the-flow: Motion-controllable video diffusion models using real-time warped noise. InProceedings of the Computer Vision and Pattern Recognition Conference. 13–23
2025
-
[5]
Joao Carreira and Andrew Zisserman. 2017. Quo vadis, action recognition? a new model and the kinetics dataset. Inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6299–6308
2017
- [6]
- [7]
- [8]
-
[9]
Haoye Dong, Xiaodan Liang, Xiaohui Shen, Bowen Wu, Bing-Cheng Chen, and Jian Yin. 2019. Fw-gan: Flow-navigated warping gan for video virtual try-on. In Proceedings of the IEEE/CVF international conference on computer vision. 1161– 1170
2019
- [10]
-
[11]
Qihang Ge, Wei Sun, Yu Zhang, Yunhao Li, Zhongpeng Ji, Fengyu Sun, Shangling Jui, Xiongkuo Min, and Guangtao Zhai. 2025. Lmm-vqa: Advancing video quality assessment with large multimodal models.IEEE Transactions on Circuits and Systems for Video Technology(2025)
2025
-
[12]
Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. 2024. Factorizing text-to-video generation by explicit image conditioning. InEuropean Conference on Computer Vision. Springer, 205–224
2024
-
[13]
Google DeepMind. 2026. Gemini 3 Flash Preview. https://ai.google.dev/gemini- api/docs/models/gemini-3-flash-preview. Accessed: 2026-03-22
2026
-
[14]
Google DeepMind. 2026. Gemini 3.1 Flash Image (Nano Banana 2). https:// aistudio.google.com/models/gemini-3-1-flash-image. Accessed: 2026-03-13
2026
-
[15]
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. 2023. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. 2024. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Qingdong He, Xueqin Chen, Yanjie Pan, Peng Tang, Pengcheng Xu, Zhenye Gan, Chengjie Wang, Xiaobin Hu, Jiangning Zhang, and Yabiao Wang. 2025. The devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection.arXiv preprint arXiv:2512.20340(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [18]
- [19]
-
[20]
Yuyang Huang, Yabo Chen, Li Ding, Xiaopeng Zhang, Wenrui Dai, Junni Zou, Hongkai Xiong, and Qi Tian. 2025. Im-zero: Instance-level motion controllable video generation in a zero-shot manner. InProceedings of the Computer Vision and Pattern Recognition Conference. 7265–7275
2025
-
[21]
Ziheng Jia, Zicheng Zhang, Jiaying Qian, Haoning Wu, Wei Sun, Chunyi Li, Xiaohong Liu, Weisi Lin, Guangtao Zhai, and Xiongkuo Min. 2025. Vqa2: visual question answering for video quality assessment. InProceedings of the 33rd ACM International Conference on Multimedia. 6751–6760
2025
-
[22]
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu
-
[23]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vision. 17191–17202
-
[24]
Johanna Karras, Aleksander Holynski, Ting-Chun Wang, and Ira Kemelmacher- Shlizerman. 2023. Dreampose: Fashion video synthesis with stable diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22680– 22690
2023
-
[25]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. 2024. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Guojun Lei, Chi Wang, Rong Zhang, Yikai Wang, Hong Li, and Weiwei Xu. 2025. Animateanything: Consistent and controllable animation for video generation. InProceedings of the Computer Vision and Pattern Recognition Conference. 27946– 27956
2025
- [27]
-
[28]
Peike Li, Yunqiu Xu, Yunchao Wei, and Yi Yang. 2020. Self-correction for human parsing.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 6 (2020), 3260–3271
2020
- [29]
-
[30]
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le
-
[31]
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Xingchao Liu, Xiwen Zhang, Jianzhu Ma, Jian Peng, et al. 2023. Instaflow: One step is enough for high-quality diffusion-based text-to-image generation. InThe Twelfth International Conference on Learning Representations
2023
-
[33]
Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Zhenglin Pan. 2025. AniLines - Anime Lineart Extractor. https://github.com/ zhenglinpan/AniLines-Anime-Lineart-Extractor
2025
-
[35]
William Peebles and Saining Xie. 2023. Scalable diffusion models with transform- ers. InProceedings of the IEEE/CVF international conference on computer vision. 4195–4205
2023
-
[36]
Yanyun Pu, Kehan Li, Zeyi Huang, Zhijie Zhong, and Kaixiang Yang. 2025. MVQA- 68K: A Multi-dimensional and Causally-annotated Dataset with Quality Inter- pretability for Video Assessment. InProceedings of the 33rd ACM International Conference on Multimedia. 11189–11198
2025
-
[37]
Zhefan Rao, Haoxuan Che, Ziwen Hu, Bin Zou, Yaofang Liu, Xuanhua He, Chong- Hou Choi, Yuyang He, Haoyu Chen, Jingran Su, Yanheng Li, Meng Chu, Chenyang Lei, Guanhua Zhao, Zhaoqing Li, Xichen Zhang, Anping Li, Lin Liu, Dandan Tu, and Rui Liu. 2026. Capybara: A Unified Visual Creation Model
2026
-
[38]
Yixuan Ren, Yang Zhou, Jimei Yang, Jing Shi, Difan Liu, Feng Liu, Mingi Kwon, and Abhinav Shrivastava. 2024. Customize-a-video: One-shot motion customization of text-to-video diffusion models. InEuropean Conference on Computer Vision. Springer, 332–349
2024
-
[39]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention. Springer, 234–241
2015
-
[40]
Henry Ruhs et al. 2023. FaceFusion: Next generation face swapper and enhancer. https://github.com/facefusion/facefusion
2023
-
[41]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. 2024. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing568 (2024), 127063
2024
-
[42]
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang
-
[43]
In Proceedings of the IEEE/CVF International Conference on Computer Vision
Ominicontrol: Minimal and universal control for diffusion transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 14940– 14950
-
[44]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. 2018. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.203143, 4 (2025), 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing13, 4 (2004), 600–612
2004
-
[49]
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. 2025. Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He
-
[51]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Less-to-more generalization: Unlocking more controllability by in-context generation. InProceedings of the IEEE/CVF International Conference on Computer Vision. 18682–18692
-
[52]
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick
-
[53]
https://github.com/facebookresearch/detectron2
Detectron2. https://github.com/facebookresearch/detectron2
-
[54]
Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. 2017. Aggregated residual transformations for deep neural networks. InProceedings of the IEEE conference on computer vision and pattern recognition. 1492–1500. 9
2017
-
[55]
Zhengze Xu, Mengting Chen, Zhao Wang, Linyu Xing, Zhonghua Zhai, Nong Sang, Jinsong Lan, Shuai Xiao, and Changxin Gao. 2024. Tunnel try-on: Ex- cavating spatial-temporal tunnels for high-quality virtual try-on in videos. In Proceedings of the 32nd ACM International Conference on Multimedia. 3199–3208
2024
-
[56]
Xiangpeng Yang, Ji Xie, Yiyuan Yang, Yan Huang, Min Xu, and Qiang Wu. 2025. Unified Video Editing with Temporal Reasoner.arXiv preprint arXiv:2512.07469 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al . 2024. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Zixuan Ye, Xuanhua He, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di ZHANG, Kun Gai, Qifeng Chen, and Wenhan Luo. [n. d.]. Unified In-Context Video Editing. InThe Fourteenth International Conference on Learning Representa- tions
-
[59]
Jianhao Zeng, Yancheng Bai, Ruidong Chen, Xuanpu Zhang, Lei Sun, Dongyang Jin, Ryan Xu, Nannan Zhang, Dan Song, and Xiangxiang Chu. 2025. Eevee: Towards Close-up High-resolution Video-based Virtual Try-on.arXiv preprint arXiv:2511.18957(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[61]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
- [62]
-
[63]
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. 2024. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[64]
Tongchun Zuo, Zaiyu Huang, Shuliang Ning, Ente Lin, Chao Liang, Zerong Zheng, Jianwen Jiang, Yuan Zhang, Mingyuan Gao, and Xin Dong. 2025. Dreamvvt: Mastering realistic video virtual try-on in the wild via a stage-wise diffusion transformer framework.arXiv preprint arXiv:2508.02807(2025). 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.