TSQAgent: Rating Time Series Data Quality via Dedicated Agentic Reasoning
Pith reviewed 2026-06-28 09:49 UTC · model grok-4.3
The pith
A three-role agentic framework lets LLMs identify relevant time series quality dimensions and perform quantitative comparisons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
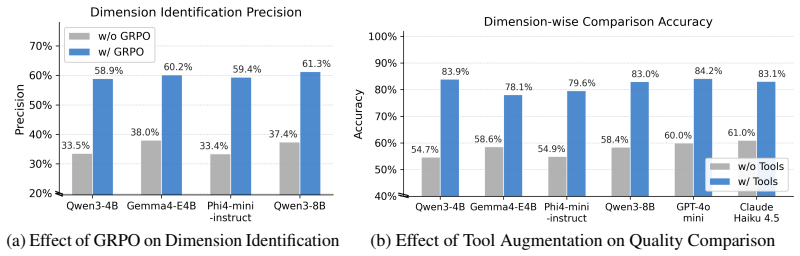
TSQAgent consists of Perceiver for focused dimension selection, Inspector for dimension-wise quantitative analysis, and Adjudicator that aggregates and refines judgments; the agentic reasoning strategy plus external analytical tools enable precise quality rating by addressing gaps in dimension identification and grounded comparison.
What carries the argument
Three-role agentic workflow (Perceiver, Inspector, Adjudicator) equipped with external analytical tools for dimension selection and quantitative comparison.
If this is right
- LLMs achieve higher accuracy in selecting high-quality time series subsets for model training.
- Downstream task performance rises while requiring fewer data samples.
- Quality assessment no longer depends on manually predefined dimensions.
- Data efficiency improves across multiple real-world time series applications.
Where Pith is reading between the lines
- The same role-based structure could apply to quality assessment in other sequential data types such as audio or sensor streams.
- TSQBench could become a reusable testbed for comparing future agentic or tool-augmented quality methods.
- Adding more specialized external tools might further reduce errors in quantitative scoring.
Load-bearing premise
The agentic reasoning strategy successfully instills the ability to identify and prioritize the most relevant quality dimensions, and the workflow equipped with external analytical tools enables precise quantitative comparisons over selected dimensions.
What would settle it
An evaluation on TSQBench where TSQAgent shows no improvement over standard LLM prompting in accuracy of relevant dimension identification or in matching human quantitative quality rankings.
Figures

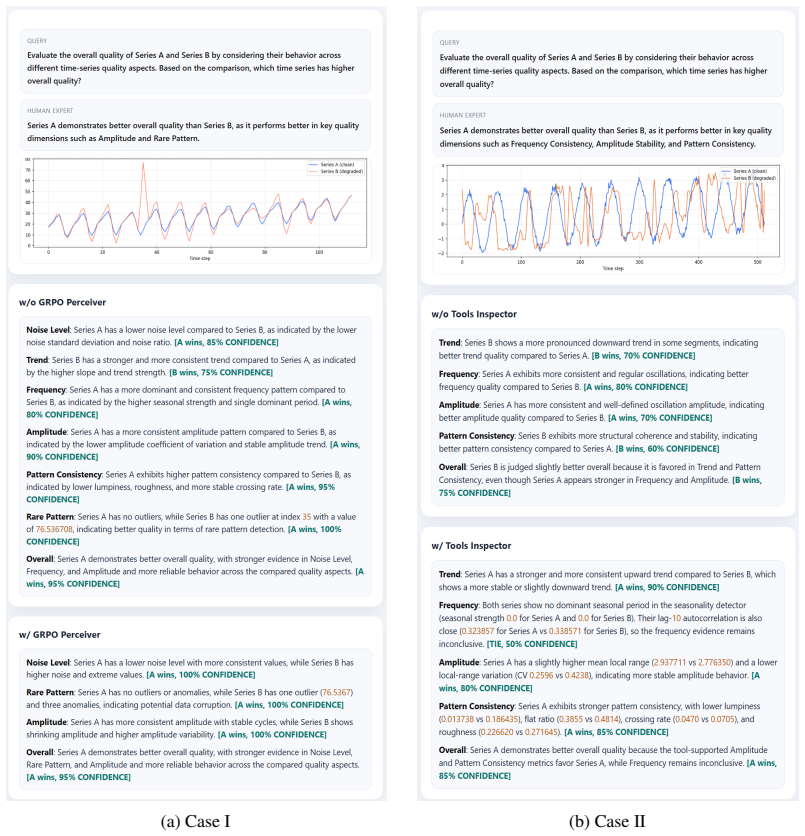
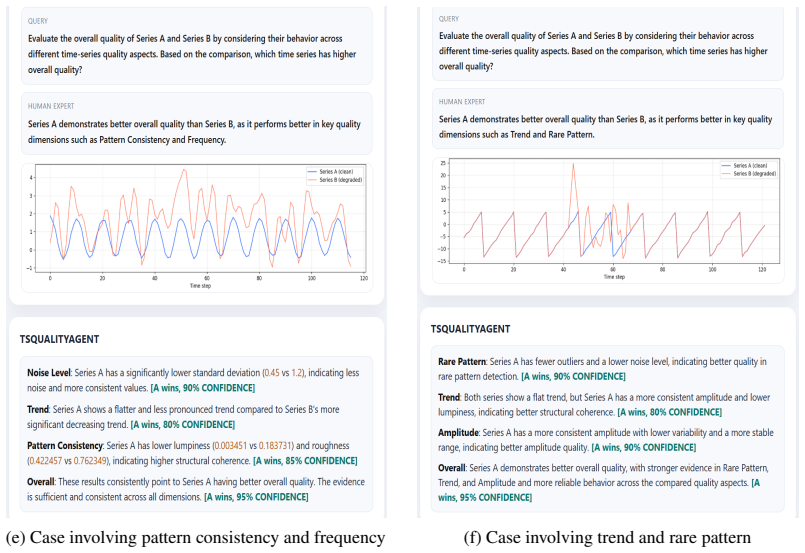
read the original abstract
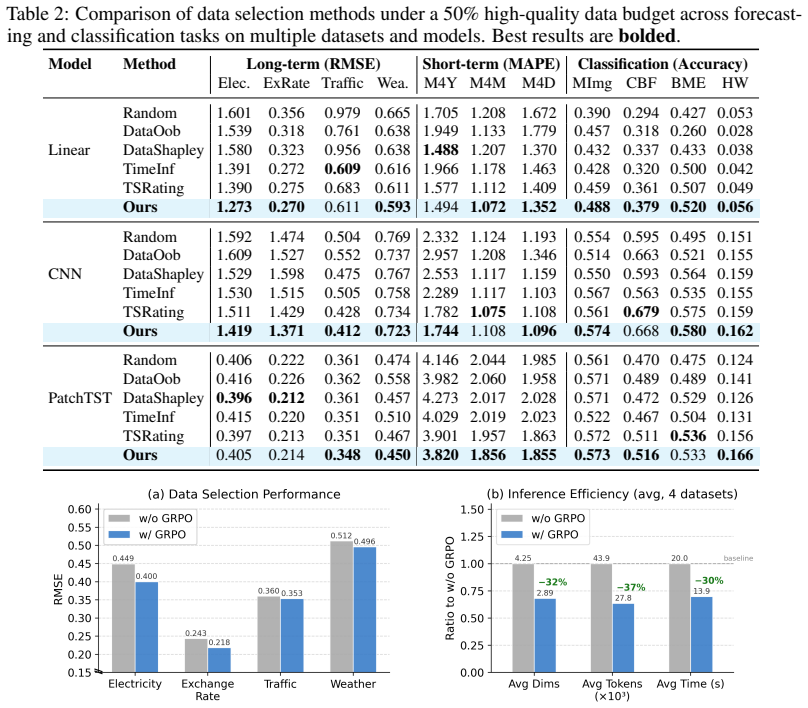
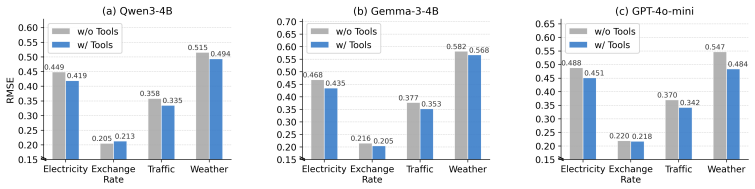
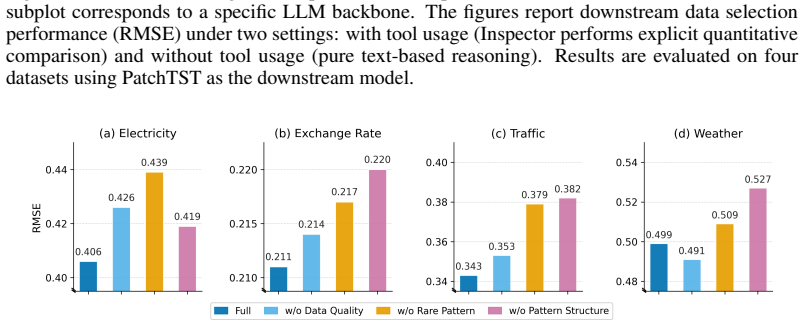
Assessing the quality of time series (TS) data is fundamental yet inherently challenging due to the multifaceted nature of quality dimensions. Recently, large language models (LLMs) have emerged as a promising paradigm for TS quality assessment via pairwise comparison and per-dimension evaluation. However, existing approaches rely on manually predefined quality dimensions and purely text-based reasoning, leaving it unknown whether LLMs can identify truly relevant quality dimensions or perform grounded and quantitative quality comparisons. To investigate this, we construct TSQBench, a dedicated benchmark for evaluating LLMs on two progressive capabilities: (i) understanding and identifying relevant quality dimensions, and (ii) performing quality comparison under specific dimensions. Our analysis reveals that current LLMs consistently struggle with both dimension identification and evidence-grounded quality comparison. To address these limitations, we propose TSQAgent, a novel agentic reasoning framework for TS quality rating consisting of three collaborative roles: Perceiver for focused dimension selection, Inspector for dimension-wise quantitative analysis, and Adjudicator that aggregates and refines the final judgment. In particular, we introduce an agentic reasoning strategy that instills the ability to identify and prioritize the most relevant quality dimensions, and further propose an agent workflow equipped with external analytical tools to enable precise quantitative comparisons over selected dimensions. Experiments on both the proposed benchmark and eleven real-world datasets demonstrate that our framework not only substantially improves LLMs' capabilities in quality understanding and quantitative comparison but also effectively translates these improvements into better quality-aware data selection, leading to enhanced downstream performance and data efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper constructs TSQBench to evaluate LLMs on two capabilities: identifying relevant time-series quality dimensions and performing evidence-grounded quantitative comparisons under those dimensions. It reports that standard LLMs struggle on both. It then introduces TSQAgent, an agentic framework with three roles (Perceiver for dimension selection, Inspector for tool-assisted quantitative analysis per dimension, and Adjudicator for aggregation), and claims that this framework yields substantial gains on TSQBench plus improved quality-aware data selection and downstream task performance on eleven real-world datasets.
Significance. If the reported gains are reproducible, the work supplies both a needed benchmark for LLM time-series quality reasoning and a concrete multi-role agent design that couples dimension prioritization with external analytical tools. The benchmark itself is a clear positive contribution; the translation from improved quality ratings to measurable downstream data-efficiency gains would be of practical interest to the time-series ML community.
major comments (3)
- [§5] §5 (Experiments): the central quantitative claims of 'substantial improvements' on TSQBench and the eleven real-world datasets are presented without error bars, number of runs, or statistical significance tests. Given the stochastic nature of LLM outputs and the agent workflow, this information is load-bearing for assessing whether the observed deltas are reliable.
- [§4.2] §4.2 (Inspector role): the description states that external analytical tools enable 'precise quantitative comparisons,' yet neither the concrete tools (e.g., specific statistical functions, distance metrics, or libraries) nor their exact integration into the Inspector prompt are specified. This detail is required to verify the claim that the workflow moves beyond text-based reasoning.
- [§3] §3 (TSQBench construction): while the benchmark is presented as independently constructed, the paper does not report inter-annotator agreement, the exact procedure for generating dimension labels and pairwise ground truth, or the size and diversity of the test cases. These omissions affect the strength of the claim that current LLMs 'consistently struggle' on the two targeted capabilities.
minor comments (2)
- [§5] The abstract and §5 refer to 'eleven real-world datasets' without naming them or providing summary statistics; a table listing dataset names, lengths, and domains would improve clarity.
- Notation for the three agent roles (Perceiver, Inspector, Adjudicator) is introduced without a compact diagram or pseudocode; adding a single workflow figure would aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to enhance reproducibility, clarity, and transparency.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): the central quantitative claims of 'substantial improvements' on TSQBench and the eleven real-world datasets are presented without error bars, number of runs, or statistical significance tests. Given the stochastic nature of LLM outputs and the agent workflow, this information is load-bearing for assessing whether the observed deltas are reliable.
Authors: We agree that the stochastic nature of LLMs and agent workflows requires explicit reporting of variability and significance testing. In the revised manuscript, we will rerun all experiments across multiple independent runs (minimum of 3 seeds), report means with standard deviations or error bars in tables and figures, and include statistical significance tests (e.g., paired t-tests with p-values) for the key performance deltas on TSQBench and downstream tasks. revision: yes
-
Referee: [§4.2] §4.2 (Inspector role): the description states that external analytical tools enable 'precise quantitative comparisons,' yet neither the concrete tools (e.g., specific statistical functions, distance metrics, or libraries) nor their exact integration into the Inspector prompt are specified. This detail is required to verify the claim that the workflow moves beyond text-based reasoning.
Authors: We acknowledge that the specific tools and their prompt integration were described at a high level but not enumerated in detail. We will revise §4.2 to explicitly list the concrete tools (e.g., statistical functions such as mean/variance/autocorrelation from NumPy/SciPy, stationarity tests via statsmodels, and distance metrics including DTW from tslearn), the libraries, and provide example prompt templates showing how tool outputs are fed back into the Inspector agent's reasoning. revision: yes
-
Referee: [§3] §3 (TSQBench construction): while the benchmark is presented as independently constructed, the paper does not report inter-annotator agreement, the exact procedure for generating dimension labels and pairwise ground truth, or the size and diversity of the test cases. These omissions affect the strength of the claim that current LLMs 'consistently struggle' on the two targeted capabilities.
Authors: We agree that additional details on benchmark construction would strengthen the claims. We will expand §3 to report inter-annotator agreement (e.g., Cohen's kappa), provide the exact annotation procedure for dimension labels and pairwise ground truth, and include statistics on test case size and diversity (domains, lengths, and sources) to better substantiate the evaluation of LLM struggles. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on constructing an independent benchmark (TSQBench) to diagnose LLM limitations in dimension identification and quantitative comparison, then proposing and empirically testing the TSQAgent framework (with Perceiver/Inspector/Adjudicator roles plus external tools) on that benchmark plus eleven separate real-world datasets for both quality rating and downstream selection gains. No load-bearing step reduces by definition, fitted-parameter renaming, or self-citation chain to its own inputs; the derivation is self-contained against external benchmarks and datasets rather than internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can be effectively prompted and tool-augmented to perform grounded quantitative analysis on time series quality dimensions
invented entities (3)
-
Perceiver
no independent evidence
-
Inspector
no independent evidence
-
Adjudicator
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Fourteenth International Conference on Learning Representations , year=
Rating Quality of Diverse Time Series Data by Meta-learning from LLM Judgment , author=. The Fourteenth International Conference on Learning Representations , year=
-
[2]
Proceedings of the 41st International Conference on Machine Learning , pages=
MOMENT: a family of open time-series foundation models , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[3]
UCI Machine Learning Repository , volume=
ElectricityLoadDiagrams20112014 , author=. UCI Machine Learning Repository , volume=
-
[4]
The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
Modeling long-and short-term temporal patterns with deep neural networks , author=. The 41st international ACM SIGIR conference on research & development in information retrieval , pages=
-
[5]
International Journal of forecasting , volume=
The M4 Competition: Results, findings, conclusion and way forward , author=. International Journal of forecasting , volume=. 2018 , publisher=
2018
-
[6]
Data mining and knowledge discovery , volume=
Deep learning for time series classification: a review , author=. Data mining and knowledge discovery , volume=. 2019 , publisher=
2019
-
[7]
Traffic dataset , howpublished =
-
[8]
Weather dataset , howpublished =
-
[9]
UCR/UEA Time Series Classification Archive , howpublished =
-
[10]
International conference on machine learning , pages=
Data shapley: Equitable valuation of data for machine learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[11]
The Twelfth International Conference on Learning Representations , year=
DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[12]
The Thirteenth International Conference on Learning Representations , year=
TimeInf: Time Series Data Contribution via Influence Functions , author=. The Thirteenth International Conference on Learning Representations , year=
-
[13]
The Eleventh International Conference on Learning Representations , year=
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers , author=. The Eleventh International Conference on Learning Representations , year=
-
[14]
arXiv preprint arXiv:2603.04791 , year=
Timer-S1: A Billion-Scale Time Series Foundation Model with Serial Scaling , author=. arXiv preprint arXiv:2603.04791 , year=
-
[15]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[16]
ArXiv , year=
Gemma 3 Technical Report , author=. ArXiv , year=
-
[17]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[18]
Proceedings of the 41st International Conference on Machine Learning , pages=
BayOTIDE: Bayesian online multivariate time series imputation with functional decomposition , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[19]
Forty-first International Conference on Machine Learning , year=
Irregular multivariate time series forecasting: A transformable patching graph neural networks approach , author=. Forty-first International Conference on Machine Learning , year=
-
[20]
Proceedings of the 41st International Conference on Machine Learning , pages=
Time-series forecasting for out-of-distribution generalization using invariant learning , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[21]
IEEE Data Eng
Data cleaning: Problems and current approaches , author=. IEEE Data Eng. Bull. , volume=
-
[22]
Sensors , volume=
Correlation-based anomaly detection in industrial control systems , author=. Sensors , volume=. 2023 , publisher=
2023
-
[23]
Journal of the american statistical association , volume=
The influence curve and its role in robust estimation , author=. Journal of the american statistical association , volume=. 1974 , publisher=
1974
-
[24]
Contribution to the Theory of Games , volume=
A value for n-person games , author=. Contribution to the Theory of Games , volume=
-
[25]
Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
Timeshap: Explaining recurrent models through sequence perturbations , author=. Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining , pages=
-
[26]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Lstprompt: Large language models as zero-shot time series forecasters by long-short-term prompting , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[27]
Advances in Neural Information Processing Systems , volume=
Large language models are zero-shot time series forecasters , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the VLDB Endowment , volume=
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning , author=. Proceedings of the VLDB Endowment , volume=. 2025 , publisher=
2025
-
[29]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Time-mqa: Time series multi-task question answering with context enhancement , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
arXiv preprint arXiv:2509.24803 , year=
Timeomni-1: Incentivizing complex reasoning with time series in large language models , author=. arXiv preprint arXiv:2509.24803 , year=
-
[31]
arXiv preprint arXiv:2410.14752 , year=
Timeseriesexam: A time series understanding exam , author=. arXiv preprint arXiv:2410.14752 , year=
-
[32]
arXiv preprint arXiv:2509.24378 , year=
AXIS: Explainable Time Series Anomaly Detection with Large Language Models , author=. arXiv preprint arXiv:2509.24378 , year=
-
[33]
The method of paired comparisons , author=
Rank analysis of incomplete block designs: I. The method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[34]
arXiv preprint arXiv:2510.02410 , year=
Opentslm: Time-series language models for reasoning over multivariate medical text-and time-series data , author=. arXiv preprint arXiv:2510.02410 , year=
-
[35]
arXiv preprint arXiv:2604.09443 , year=
Many-Tier Instruction Hierarchy in LLM Agents , author=. arXiv preprint arXiv:2604.09443 , year=
-
[36]
arXiv preprint arXiv:2601.13653 , year=
TimeART: Towards Agentic Time Series Reasoning via Tool-Augmentation , author=. arXiv preprint arXiv:2601.13653 , year=
-
[37]
11th International Conference on Learning Representations, ICLR 2023 , year=
REACT: SYNERGIZING REASONING AND ACTING IN LANGUAGE MODELS , author=. 11th International Conference on Learning Representations, ICLR 2023 , year=
2023
-
[38]
Proceedings of the 7th ACM Conference on Conversational User Interfaces , pages=
PITCH: designing agentic conversational support for planning and self-reflection , author=. Proceedings of the 7th ACM Conference on Conversational User Interfaces , pages=
-
[39]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[40]
arXiv preprint arXiv:2603.09843 , year=
RecThinker: An Agentic Framework for Tool-Augmented Reasoning in Recommendation , author=. arXiv preprint arXiv:2603.09843 , year=
-
[41]
arXiv preprint arXiv:2601.12538 , year=
Agentic reasoning for large language models , author=. arXiv preprint arXiv:2601.12538 , year=
-
[42]
The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025 , year=
In-the-Flow Agentic System Optimization for Effective Planning and Tool Use , author=. The 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025 , year=
2025
-
[43]
2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA) , pages=
Adaptive threshold for outlier detection on data streams , author=. 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA) , pages=. 2018 , organization=
2018
-
[44]
2017 , publisher=
Time series analysis: Nonstationary and noninvertible distribution theory , author=. 2017 , publisher=
2017
-
[45]
Ieee Access , volume=
Time series data cleaning: A survey , author=. Ieee Access , volume=. 2019 , publisher=
2019
-
[46]
arXiv preprint arXiv:2408.14763 , year=
Channel-wise Influence: Estimating Data Influence for Multivariate Time Series , author=. arXiv preprint arXiv:2408.14763 , year=
-
[47]
Journal of biomedical informatics , volume=
WindowSHAP: An efficient framework for explaining time-series classifiers based on Shapley values , author=. Journal of biomedical informatics , volume=. 2023 , publisher=
2023
-
[48]
2025 21st IEEE International Colloquium on Signal Processing & Its Applications (CSPA) , pages=
Unifying prediction and explanation in time-series transformers via shapley-based pretraining , author=. 2025 21st IEEE International Colloquium on Signal Processing & Its Applications (CSPA) , pages=. 2025 , organization=
2025
-
[49]
arXiv preprint arXiv:2602.01776 , year=
Position: Beyond Model-Centric Prediction--Agentic Time Series Forecasting , author=. arXiv preprint arXiv:2602.01776 , year=
-
[50]
arXiv preprint arXiv:2510.01538 , year=
Timeseriesscientist: A general-purpose ai agent for time series analysis , author=. arXiv preprint arXiv:2510.01538 , year=
-
[51]
arXiv preprint arXiv:2509.00616 , year=
TimeCopilot , author=. arXiv preprint arXiv:2509.00616 , year=
-
[52]
AD-AGENT: A Multi-agent Framework for End-to-end Anomaly Detection , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[53]
arXiv preprint arXiv:2511.08947 , year=
AlphaCast: A Human Wisdom-LLM Intelligence Co-Reasoning Framework for Interactive Time Series Forecasting , author=. arXiv preprint arXiv:2511.08947 , year=
-
[54]
arXiv preprint arXiv:2503.01013 , year=
Timexl: Explainable multi-modal time series prediction with llm-in-the-loop , author=. arXiv preprint arXiv:2503.01013 , year=
-
[55]
arXiv preprint arXiv:2510.07432 , year=
TS-Agent: A Time Series Reasoning Agent with Iterative Statistical Insight Gathering , author=. arXiv preprint arXiv:2510.07432 , year=
-
[56]
arXiv preprint arXiv:2602.13802 , year=
Cast-R1: Learning Tool-Augmented Sequential Decision Policies for Time Series Forecasting , author=. arXiv preprint arXiv:2602.13802 , year=
-
[57]
STL: A seasonal-trend decomposition , author=. J. off. Stat , volume=
-
[58]
2018 , publisher=
Forecasting: principles and practice , author=. 2018 , publisher=
2018
-
[59]
arXiv preprint arXiv:1907.05321 , year=
Time2vec: Learning a vector representation of time , author=. arXiv preprint arXiv:1907.05321 , year=
Pith/arXiv arXiv 1907
-
[60]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
SMART: Self-aware agent for tool overuse mitigation , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[61]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agentic reward modeling: Integrating human preferences with verifiable correctness signals for reliable reward systems , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[62]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[63]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[64]
arXiv preprint arXiv:2412.08905 , year=
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.