Geometric Foundation Model Distillation for Efficient Lunar 3D Reconstruction
Pith reviewed 2026-07-03 16:20 UTC · model grok-4.3
The pith
Distilling a 688M-parameter 3D model produces students up to seven times smaller that retain lunar stereo accuracy and beat sparse baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
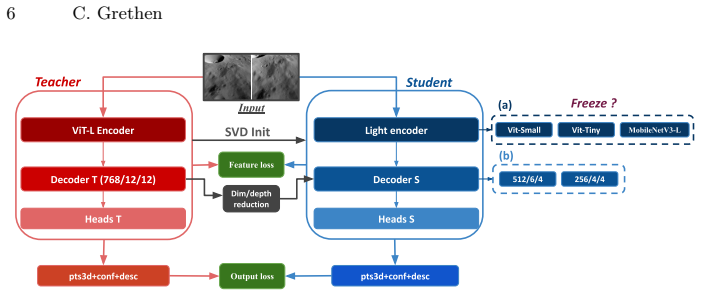
Starting from a 688M-parameter MASt3R teacher fine-tuned on lunar imagery, distilling its dense geometric predictions into a family of lightweight students via structured SVD-based initialization yields models up to seven times smaller that retain most of the teacher's reconstruction accuracy and outperform baselines trained with sparse ground-truth annotations.
What carries the argument
structured SVD-based initialization that projects the teacher's decoder weights into the student's smaller latent space to provide a warm start for distillation
If this is right
- Feature-level distillation consistently outperforms output-only supervision.
- Preserving encoder capacity matters more than maintaining a large decoder.
- A convolutional encoder underperforms transformer-based alternatives under the same distillation regime.
- SVD-based initialization improves optimisation stability and final performance.
Where Pith is reading between the lines
- The same distillation recipe could be tested on other resource-limited stereo tasks such as drone navigation or satellite mapping.
- Real hardware profiling on target flight processors would reveal whether the reported size reductions translate to usable frame rates in orbit.
- The observed priority of encoder capacity suggests future geometric foundation models should allocate parameters differently when compression is anticipated.
Load-bearing premise
The lunar imagery dataset used for fine-tuning and evaluation is representative enough that the reported accuracy retention will hold under actual planetary deployment hardware constraints.
What would settle it
A student model produced by the distillation procedure shows substantially lower reconstruction accuracy than the teacher on a new set of lunar stereo pairs never seen during training or evaluation.
Figures




read the original abstract
Large 3D foundation models such as MASt3R achieve state-of-the-art stereo reconstruction but are computationally demanding for deployment under strict hardware constraints -- a critical limitation in domains such as planetary exploration, where onboard computing is severely restricted. We study how far such models can be compressed through knowledge distillation, using lunar stereo reconstruction as a challenging and practically relevant case study. Starting from a 688M-parameter MASt3R teacher fine-tuned on lunar imagery, we distill its dense geometric predictions into a family of lightweight students spanning different encoder types (CNN vs ViT), decoder widths and depths, and training strategies. To bridge the dimensional mismatch between teacher and student, we propose a structured SVD-based initialization that projects the teacher's decoder weights into the student's smaller latent space, yielding a warm start that significantly improves convergence and final performance. Based on our results on lunar data, we can obtain a distilled student that retains most of teacher's reconstruction accuracy while reducing the model size up to 7 times, and even outperforms a baseline trained directly with sparse ground-truth annotations. Beyond compression, our study highlights both principles and practical insights for distilling geometric foundation models: a convolutional encoder underperforms transformer-based alternatives (though pretraining availability remains a confounding factor), preserving encoder capacity is more critical than maintaining a large decoder, feature-level distillation consistently outperforms output-only supervision, and SVD-based initialization improves optimisation stability. These findings provide practical guidelines for deploying 3D reconstruction models in resource-constrained environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies knowledge distillation to compress the 688M-parameter MASt3R teacher (fine-tuned on lunar imagery) into smaller student models for stereo 3D reconstruction. It introduces an SVD-based decoder initialization to address latent-space mismatch, compares CNN vs. ViT encoders, feature-level vs. output-level distillation, and varying decoder widths/depths. On the lunar dataset the best students retain most of the teacher's accuracy at up to 7× smaller size and outperform a sparse ground-truth baseline; the study also reports practical guidelines (encoder capacity matters more than decoder size, feature distillation is preferable, SVD warm-start aids convergence).
Significance. If the reported retention of accuracy and outperformance of the sparse baseline hold under the stated protocol, the work supplies concrete, actionable guidance for deploying geometric foundation models under the severe compute limits of planetary missions. The SVD initialization technique and the controlled architecture/distillation ablations are reusable contributions beyond the lunar case. The manuscript does not claim parameter-free derivations or machine-checked proofs, but the explicit baseline comparisons and architecture sweeps strengthen its empirical value.
minor comments (3)
- [Abstract / Results] Abstract and results paragraph state quantitative gains and the 7× compression claim but do not report exact metrics, error bars, or data-split details; these should be added to the main results section (or a table) so readers can verify the retention and outperformance statements.
- [Results] The claim that the distilled student 'outperforms a baseline trained directly with sparse ground-truth annotations' is central; the manuscript should clarify whether the sparse baseline used identical training data volume, augmentation, and optimization budget as the distillation runs.
- [Discussion] The discussion of CNN vs. ViT encoders notes pretraining availability as a confounding factor; a short additional experiment or explicit statement on whether both encoder families started from the same pretraining regime would remove ambiguity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, detailed summary, and recommendation for minor revision. The report contains no enumerated major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical distillation study that fine-tunes a MASt3R teacher on lunar imagery then trains a family of smaller student models using explicit protocols (SVD-based decoder initialization, feature-level vs. output-level distillation, CNN vs. ViT encoders) and reports accuracy/size results against concrete baselines. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain; all central claims rest on experimental comparisons on the chosen dataset rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- student encoder/decoder widths and depths
axioms (1)
- domain assumption The teacher model's dense geometric predictions on lunar imagery constitute high-quality supervision suitable for distillation
Reference graph
Works this paper leans on
-
[1]
In: ECCV (2022)
Arnold, E., Wynn, J., Vicente, S., Garcia-Hernando, G., Monszpart, Á., Prisacariu, V.A., Turmukhambetov, D., Brachmann, E.: Map-free visual relocalization: Metric pose relative to a single image. In: ECCV (2022)
2022
-
[2]
In: European Conference on Computer Vision
Baradel, F., Armando, M., Galaaoui, S., Brégier, R., Weinzaepfel, P., Rogez, G., Lucas, T.: Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. In: European Conference on Computer Vision. pp. 202–218. Springer (2024)
2024
-
[3]
Belhumeur, P.N., Kriegman, D.J., Yuille, A.L.: The bas-relief ambiguity. Interna- tional Journal of Computer Vision35(1), 33–44 (Nov 1999).https://doi.org/ 10.1023/a:1008154927611
-
[4]
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale (2021), https://arxiv.org/abs/2010.11929
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [5]
-
[6]
Psychometrika1(3), 211–218 (1936)
Eckart, C., Young, G.: The approximation of one matrix by another of lower rank. Psychometrika1(3), 211–218 (1936)
1936
-
[7]
Getchius, J., Renshaw, D., Posada, D., Henderson, T., Hong, L., Ge, S., Molina, G.: Hazard Detection and Avoidance for the Nova-C Lander, p. 921–943. Springer International Publishing (2024).https://doi.org/10.1007/978-3-031-51928- 4_53
-
[8]
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: A survey. In- ternational Journal of Computer Vision129(6), 1789–1819 (Mar 2021).https: //doi.org/10.1007/s11263-021-01453-z
-
[9]
In: iccvw
Grethen, C., Gasparini, S., Morin, G., Lebreton, J., Marti, L., Sanchez-Gestido, M.: Adapting stereo vision from objects to 3d lunar surface reconstruction with the stereolunar dataset. In: iccvw. pp. 3751–3760 (2025)
2025
- [10]
-
[11]
Cam- bridge University Press, ISBN: 0521540518, second edn
Hartley, R.I., Zisserman, A.: Multiple View Geometry in Computer Vision. Cam- bridge University Press, ISBN: 0521540518, second edn. (2004)
2004
-
[12]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015) Geometric Foundation Model Distillation 21
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
Howard, A., Sandler, M., Chu, G., Chen, L.C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., Le, Q.V., Adam, H.: Searching for mobilenetv3. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) (October 2019)
2019
-
[14]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
- [15]
-
[16]
Leblanc, B., Poullis, C.: Distill3r: A pipeline for democratizing 3d foundation mod- els on commodity hardware (2026)
2026
-
[17]
In: ECCV (2024)
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with MASt3R. In: ECCV (2024)
2024
-
[18]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
in international conference on learning representations (2015)
Romero, A., Ballas, N., Kahou, S., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: Hints for thin deep nets. in international conference on learning representations (2015)
2015
-
[20]
Sanh, V., Debut, L., Chaumond, J., Wolf, T.: Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter (2020),https://arxiv.org/abs/1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Sarıyıldız, M.B., Weinzaepfel, P., Lucas, T., De Jorge, P., Larlus, D., Kalantidis, Y.: Dune: Distilling a universal encoder from heterogeneous 2d and 3d teachers. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 30084–30094 (2025)
2025
-
[22]
In: AIAA SCITECH 2023 Forum
Steffes, S.R., DeTrempe, P., Barton, G., Woffinden, D.: Hazard boresight relative navigation for safe lunar landing. In: AIAA SCITECH 2023 Forum. American Institute of Aeronautics and Astronautics (Jan 2023).https://doi.org/10.2514/ 6.2023-0691
2023
-
[23]
arXiv preprint arXiv:2412.16719 (2024)
Sy, Y., Cerisara, C., Illina, I.: Lillama: Large language models compression via low-rank feature distillation. arXiv preprint arXiv:2412.16719 (2024)
-
[24]
In: International conference on machine learning
Touvron, H., Cord, M., Douze, M., Massa, F., Sablayrolles, A., Jégou, H.: Training data-efficient image transformers & distillation through attention. In: International conference on machine learning. pp. 10347–10357. PMLR (2021)
2021
-
[25]
Proceedings of the Royal Society of London
Ullman, S.: The interpretation of structure from motion. Proceedings of the Royal Society of London. Series B. Biological Sciences203(1153), 405–426 (Jan 1979). https://doi.org/10.1098/rspb.1979.0006
-
[26]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
- [27]
-
[28]
In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (2025)
2025
-
[29]
arXiv preprint arXiv:2310.02328 (2023)
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. arXiv preprint arXiv:2310.02328 (2023)
-
[30]
Advances in Neural Information Process- ing Systems35, 3502–3516 (2022) 22 C
Weinzaepfel, P., Leroy, V., Lucas, T., Brégier, R., Cabon, Y., Arora, V., Antsfeld, L., Chidlovskii, B., Csurka, G., Revaud, J.: Croco: Self-supervised pre-training for 3d vision tasks by cross-view completion. Advances in Neural Information Process- ing Systems35, 3502–3516 (2022) 22 C. Grethen
2022
-
[31]
The International Archives of the Photogrammetry, Remote Sensing and Spatial Information SciencesXLI-B4, 521–527 (Jun 2016).https://doi.org/10
Wu,B.,Liu,W.C.,Grumpe,A.,Wöhler,C.:Shapeandalbedofromshading(SAfS) forpixel-leveldemgenerationfrommonocularimagesconstrainedbylow-resolution dem. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information SciencesXLI-B4, 521–527 (Jun 2016).https://doi.org/10. 5194/isprs-archives-xli-b4-521-2016
2016
-
[32]
Wu, K., Zhang, J., Peng, H., Liu, M., Xiao, B., Fu, J., Yuan, L.: Tinyvit: Fast pretrainingdistillationforsmallvisiontransformers.In:ECCV.pp.68–85.Springer (2022)
2022
-
[33]
A Survey on Knowledge Distillation of Large Language Models
Xu, X., Li, M., Tao, C., Shen, T., Cheng, R., Li, J., Xu, C., Tao, D., Zhou, T.: A survey on knowledge distillation of large language models (2024),https://arxiv. org/abs/2402.13116
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
In: CVPR (2024)
Yang, L., Kang, B., Huang, Z., Xu, X., Feng, J., Zhao, H.: Depth anything: Un- leashing the power of large-scale unlabeled data. In: CVPR (2024)
2024
-
[35]
Yu, Z., Wen, Y., Mou, L.: Revisiting intermediate-layer matching in knowledge distillation: Layer-selection strategy doesn’t matter (much). In: Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Lin- guistics. pp. 1686–1694 (2025)
2025
-
[36]
Streaming 4D Visual Geometry Transformer
Zhuo, D., Zheng, W., Guo, J., Wu, Y., Zhou, J., Lu, J.: Streaming 4d visual geometry transformer. arXiv preprint arXiv:2507.11539 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.