Learning Cross-view Correspondences for Geo-localization on Planetary Surfaces
Pith reviewed 2026-06-30 06:58 UTC · model grok-4.3
The pith
Learning-based cross-view localization methods succeed on planetary surfaces with a new lunar benchmark dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
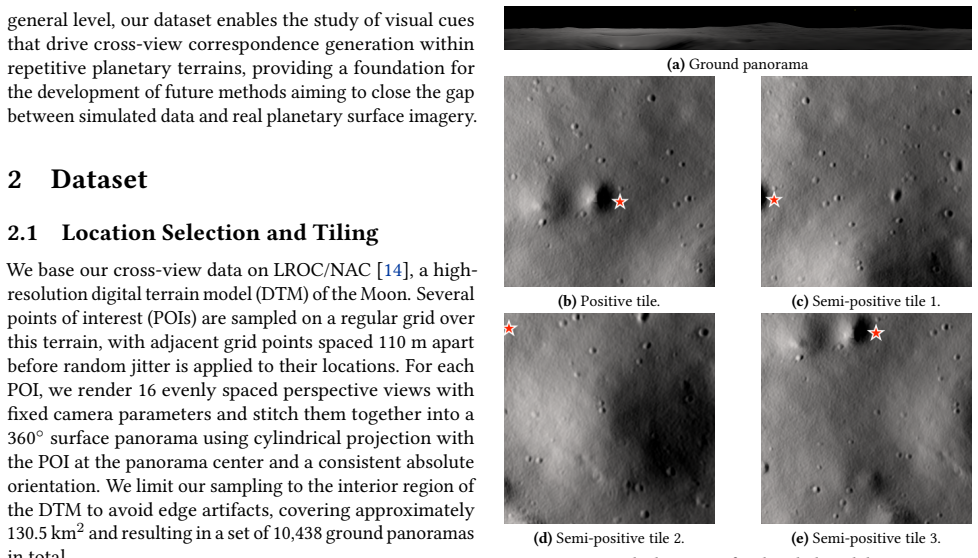
We introduce a new cross-view geo-localization benchmark built from physically rendered surface panoramas and overhead tiles derived from a high-resolution lunar terrain model. Our dataset contains 10438 ground views rendered as 360° surface panoramas with matching overhead images precisely centered at the same location. Additionally, a set of overlapping tiles is provided to study off-center localization with multiple plausible candidates per panorama. We study the performance of a state-of-the-art transformer-based geo-localization method on our data, by training it from scratch and reporting retrieval accuracy. Our results demonstrate that learning-based cross-view localization methods ca
What carries the argument
The benchmark dataset of matched 360° surface panoramas and overhead tiles from a lunar terrain model, which supports training and accuracy evaluation of cross-view retrieval models.
If this is right
- Learning-based methods can serve as a vision-based alternative to unavailable global navigation satellite systems for planetary surface exploration.
- Training a transformer model from scratch on the lunar dataset yields usable retrieval accuracy despite viewpoint and appearance differences.
- The dataset enables study of off-center localization using overlapping overhead tiles with multiple candidate matches per panorama.
- The approach addresses core challenges of low texture, repetitive terrain, and drastic illumination changes in cross-view matching.
Where Pith is reading between the lines
- The same benchmark construction approach could be repeated for other bodies with terrain models, such as Mars.
- Real spacecraft imagery would be needed to test whether performance transfers from rendered data.
- The localization output could be fused with odometry to limit drift over long surface traverses.
- Other model architectures could be benchmarked on the same data to compare suitability for low-texture planetary scenes.
Load-bearing premise
The physically rendered panoramas and overhead tiles accurately represent the viewpoint, illumination, and texture challenges that would appear in real planetary imagery captured by actual spacecraft cameras.
What would settle it
Testing the trained transformer model on actual images from a lunar rover or lander and finding retrieval accuracy substantially lower than the levels achieved on the rendered benchmark.
Figures

read the original abstract
Maintaining global position awareness is a fundamental challenge for planetary surface exploration, since satellite-based positioning systems are unavailable and onboard odometry drifts over time. Although orbital mapping products, such as overhead imagery and terrain-derived maps, provide global context, aligning them with surface observations is challenging due to large viewpoint differences, low texture, repetitive terrain, and drastic changes in appearance caused by varying illumination and topography. We introduce a new cross-view geo-localization benchmark built from physically rendered surface panoramas and overhead tiles derived from a high-resolution lunar terrain model. Our dataset contains 10438 ground views rendered as 360$^\circ$ surface panoramas with matching overhead images precisely centered at the same location. Additionally, a set of overlapping tiles is provided to study off-center localization with multiple plausible candidates per panorama. We study the performance of a state-of-the-art transformer-based geo-localization method on our data, by training it from scratch and reporting retrieval accuracy. Our results demonstrate that learning-based cross-view localization methods can be successfully applied to the domain of planetary surfaces, providing a vision-based alternative to global navigation satellite systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a new benchmark dataset consisting of 10438 physically rendered 360° surface panoramas and precisely centered overhead tiles derived from a high-resolution lunar terrain model. It evaluates a state-of-the-art transformer-based cross-view geo-localization method trained from scratch on this data, reports retrieval accuracy, and concludes that learning-based methods can be successfully applied to planetary surfaces as a vision-based alternative to GNSS.
Significance. The construction of a controlled, precisely aligned synthetic benchmark for cross-view matching under extreme viewpoint and illumination variation is a useful contribution to the field. If the reported accuracies prove robust and the method transfers to real imagery, the work could support vision-based navigation for planetary rovers where GNSS is unavailable. The provision of an off-center localization subset with multiple candidate tiles is a practical addition for studying robustness.
major comments (2)
- [Abstract] Abstract: the claim that the approach 'can be successfully applied to the domain of planetary surfaces, providing a vision-based alternative to global navigation satellite systems' is load-bearing yet unsupported, as all quantitative results are confined to synthetic renders with no experiments, ablation, or discussion addressing the domain gap to actual spacecraft camera data (sensor noise, calibration errors, unmodeled photometric effects).
- [Experiments] Experiments section: no comparison to non-learning baselines (e.g., SIFT or template matching) or error analysis on failure modes is reported, making it impossible to determine whether the transformer provides a genuine advance over classical methods on this dataset and weakening the evaluation of the central claim.
minor comments (2)
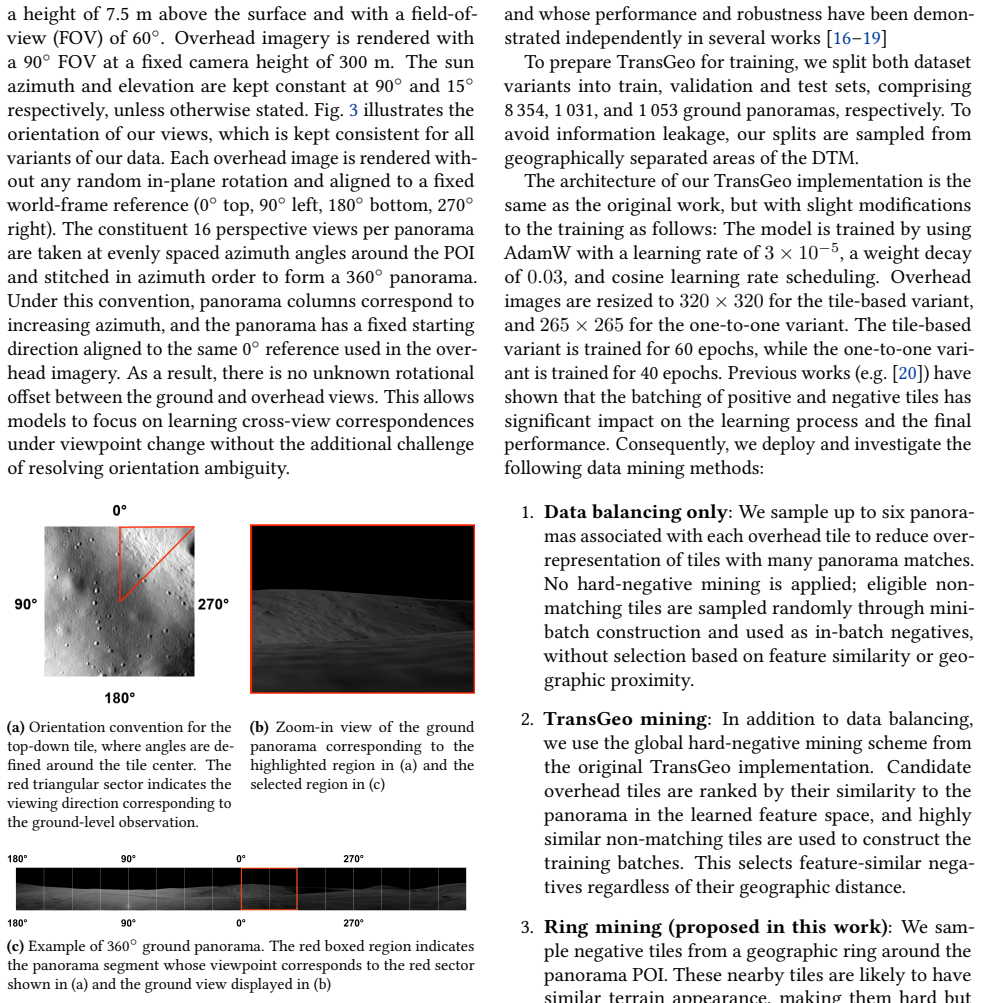
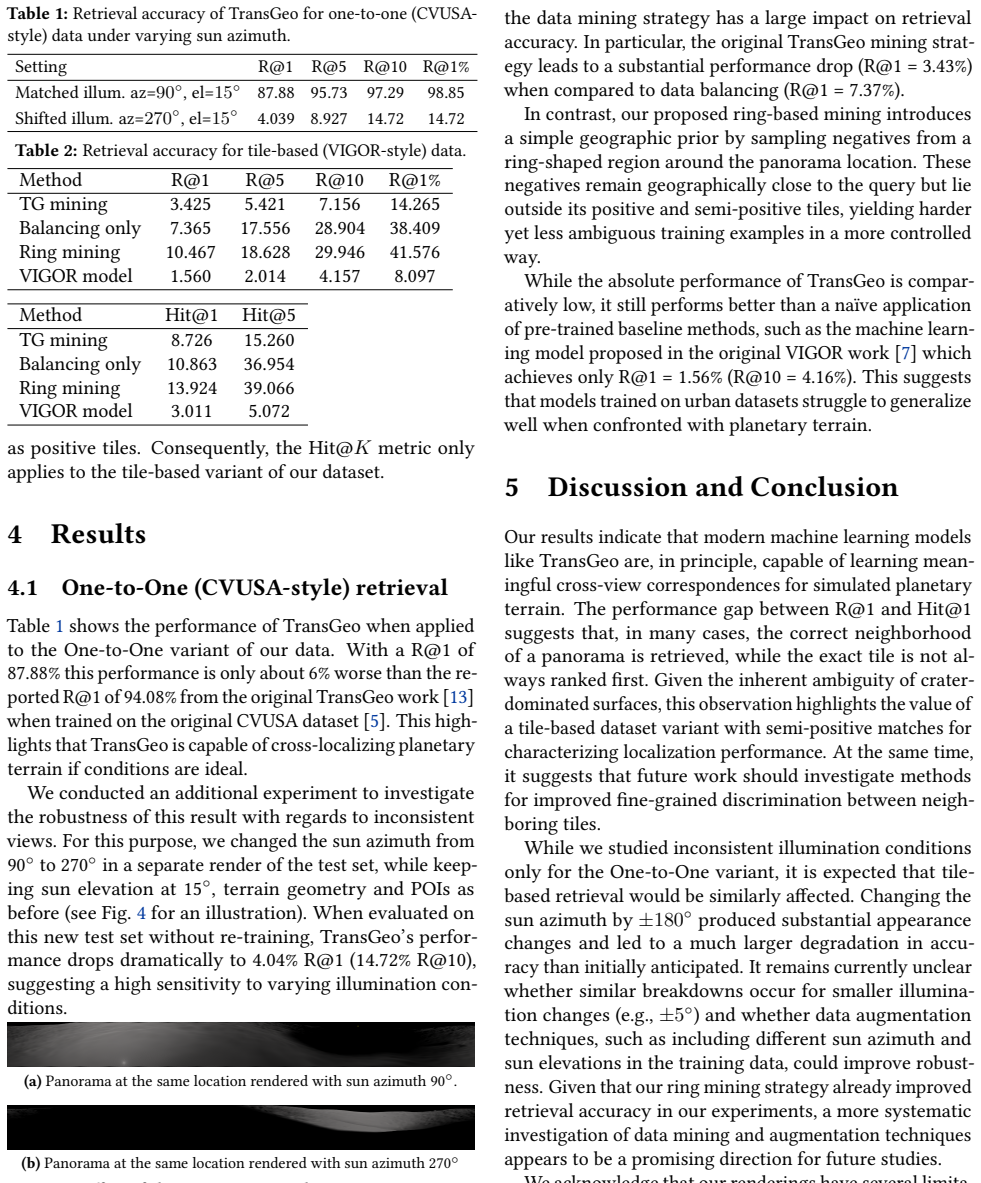
- [§3] Dataset construction: the precise camera intrinsics, illumination model parameters, and rendering pipeline details used to generate the panoramas should be stated explicitly to support reproducibility and future domain-gap studies.
- [Figures] Figure captions: examples of rendered panoramas and tiles would benefit from explicit annotations highlighting the scale of viewpoint difference and illumination variation to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the utility of the controlled synthetic benchmark. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the approach 'can be successfully applied to the domain of planetary surfaces, providing a vision-based alternative to global navigation satellite systems' is load-bearing yet unsupported, as all quantitative results are confined to synthetic renders with no experiments, ablation, or discussion addressing the domain gap to actual spacecraft camera data (sensor noise, calibration errors, unmodeled photometric effects).
Authors: We agree that the abstract claim is phrased too broadly given the exclusive use of synthetic data. The manuscript positions the work as the introduction of a precisely aligned benchmark that isolates extreme viewpoint and illumination challenges representative of planetary surfaces. In revision we will moderate the abstract to state that the results show learning-based methods can be trained successfully on this synthetic benchmark as an initial demonstration, and we will insert a dedicated limitations paragraph that explicitly discusses the sim-to-real gap, including unmodeled effects such as sensor noise and photometric variations. revision: yes
-
Referee: [Experiments] Experiments section: no comparison to non-learning baselines (e.g., SIFT or template matching) or error analysis on failure modes is reported, making it impossible to determine whether the transformer provides a genuine advance over classical methods on this dataset and weakening the evaluation of the central claim.
Authors: The evaluation centers on training and testing a transformer-based retrieval method from scratch on the new benchmark; classical baselines were omitted because the 360° ground-to-overhead viewpoint shift and low-texture repetitive terrain render direct application of SIFT or template matching impractical without extensive preprocessing that falls outside the paper's scope. We will add a concise discussion paragraph noting these expected limitations of classical methods and expand the existing qualitative analysis of observed failure cases (e.g., confusion among visually similar terrain patches) to provide a basic error characterization. revision: partial
Circularity Check
No circularity: empirical evaluation on new synthetic benchmark is self-contained
full rationale
The paper constructs a new lunar terrain-derived synthetic dataset of 10438 panorama-overhead pairs and trains a transformer-based geo-localization model from scratch, reporting retrieval accuracy. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain. The central claim rests on direct experimental results rather than any reduction to prior inputs by construction. This is the standard case of an honest empirical contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rendered images from the lunar terrain model capture the essential viewpoint, illumination, and texture variations present in real planetary imagery.
Reference graph
Works this paper leans on
-
[1]
https: //doi.org/10.1007/s44267-024-00045-y(Apr
Chen, Z.et al.Metric localization for lunar rovers via cross-view image matching.Visual Intelligence2,12.issn: 2731-9008. https: //doi.org/10.1007/s44267-024-00045-y(Apr. 2024)
-
[2]
E.et al.Initial observations from the Lunar Orbiter Laser Altimeter (LOLA).Geophysical Research Letters37.eprint: https: / / agupubs
Smith, D. E.et al.Initial observations from the Lunar Orbiter Laser Altimeter (LOLA).Geophysical Research Letters37.eprint: https: / / agupubs . onlinelibrary . wiley . com / doi / pdf / 10 . 1029/2010GL043751
-
[3]
https : / / www
Gläser, P.et al.Illumination conditions at the lunar south pole using high resolution Digital Terrain Models from LOLA.Icarus 243,78–90.issn: 0019-1035. https : / / www . sciencedirect . com/science/article/pii/S0019103514004278(2014)
2014
-
[4]
Shi, Y. & Li, H.Beyond Cross-view Image Retrieval: Highly Accurate Vehicle Localization Using Satellite Imagein2022 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR)(2022), 16989–16999. https://doi.org/10.1109/CVPR52688.2022. 01650
-
[5]
Workman, S., Souvenir, R. & Jacobs, N.Wide-Area Image Geolo- calization with Aerial Reference Imageryin2015 IEEE International Conference on Computer Vision (ICCV)(2015), 3961–3969. https: //doi.org/10.1109/ICCV.2015.451
-
[6]
Liu, L. & Li, H.Lending Orientation to Neural Networks for Cross- View Geo-Localizationin2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2019), 5617–5626. https: //doi.org/10.1109/CVPR.2019.00577
-
[7]
Zhu, S., Yang, T. & Chen, C.VIGOR: Cross-View Image Geo- localization beyond One-to-one Retrievalin2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2021), 5316– 5325.https://doi.org/10.1109/CVPR46437.2021.00364
-
[8]
Robbins, S. J., Kirchoff, M. R. & Ostrach, L. R. Crater Detection De- pendence on Resolution, Incidence Angle, Emission Angle, and Phase Angle.Geophysical Research Letters52,e2024GL110570. eprint: https://agupubs.onlinelibrary.wiley.com/doi/ pdf/10.1029/2024GL110570(2025). 4https://zenodo.org
-
[9]
Daftry, S.et al. LunarNav: Crater-based localization for long-range autonomous lunar rover navigationin2023 IEEE Aerospace Conference (2023), 1–15. https://doi.org/10.1109/AERO55745.2023. 10115640
-
[10]
Zhao, X., Cui, L., Wei, X., Liu, C. & Yin, J. Lunar Rover Cross-View Localization Through Integration of Rover and Orbital Images.IEEE Transactions on Geoscience and Remote Sensing62,1–14. https: //doi.org/10.1109/TGRS.2024.3462487(2024)
-
[11]
Artemis: An Overview of NASA’s Activities to Re- turn Humans to the Moon,
Matthies, L.et al. Lunar Rover Localization Using Craters as Land- marksin2022 IEEE Aerospace Conference (AERO)(2022), 1–17. https://doi.org/10.1109/AERO53065.2022.9843714
-
[12]
& Gestido, M
Martin, I., Dunstan, M. & Gestido, M. S.Planetary surface image generation for testing future space missions with PANGUin2nd RPI Space Imaging Workshop(2019)
2019
-
[13]
Zhu, S., Shah, M. & Chen, C.TransGeo: Transformer Is All You Need for Cross-view Image Geo-localizationin2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)(2022), 1152– 1161.https://doi.org/10.1109/CVPR52688.2022.00123
-
[14]
Robinson, M. S.et al.Lunar Reconnaissance Orbiter Camera (LROC) Instrument Overview.Space Science Reviews150,81–124. https: //doi.org/10.1007/s11214-010-9634-2(2010)
-
[15]
& Sato, H
Hapke, B. & Sato, H. The porosity of the upper lunar regolith.Icarus 273,75–83.issn: 0019-1035. https : / / www . sciencedirect . com/science/article/pii/S0019103515005114(2016)
2016
-
[17]
Zhang, Q. & Zhu, Y.Benchmarking the Robustness of Cross-View Geo- Localization ModelsinComputer Vision – ECCV 2024(eds Leonardis, A.et al.) (Springer Nature Switzerland, 2025), 36–53.isbn: 978-3-031- 73021-4. https://doi.org/10.1007/978- 3- 031- 73021- 4_3
-
[18]
Durgam, A., Paheding, S., Dhiman, V. & Devabhaktuni, V. Cross- View Geo-Localization: A Survey.IEEE Access12,192028–192050. https://doi.org/10.1109/ACCESS.2024.3507280(2024)
-
[19]
S., Rizve, M
Pillai, M. S., Rizve, M. N. & Shah, M.GAReT: Cross-View Video Geolo- calization with Adapters and Auto-Regressive TransformersinCom- puter Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXI(eds Leonardis, A.et al.)15119(Springer, 2024), 466–483. https://doi.org/10. 1007/978-3-031-73030-6%5C_26
2024
-
[20]
Deuser, F., Habel, K. & Oswald, N.Sample4Geo: Hard Negative Sam- pling For Cross-View Geo-Localisationin2023 IEEE/CVF International Conference on Computer Vision (ICCV)(2023), 16801–16810. https: //doi.org/10.1109/ICCV51070.2023.01545. 3rd Conference on AI in and for Space (SPAICE 2026) ©2026 H. M. Nguyen, M. Märtens and TJ Chin, licenced via CC BY 4.0
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.