From Passive Generation to Investigation: A Proactive Scientific Peer Review Agent
Pith reviewed 2026-06-27 07:12 UTC · model grok-4.3
The pith
An 8B-parameter LLM agent outperforms larger models on scientific peer review by using a structured log to proactively investigate papers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
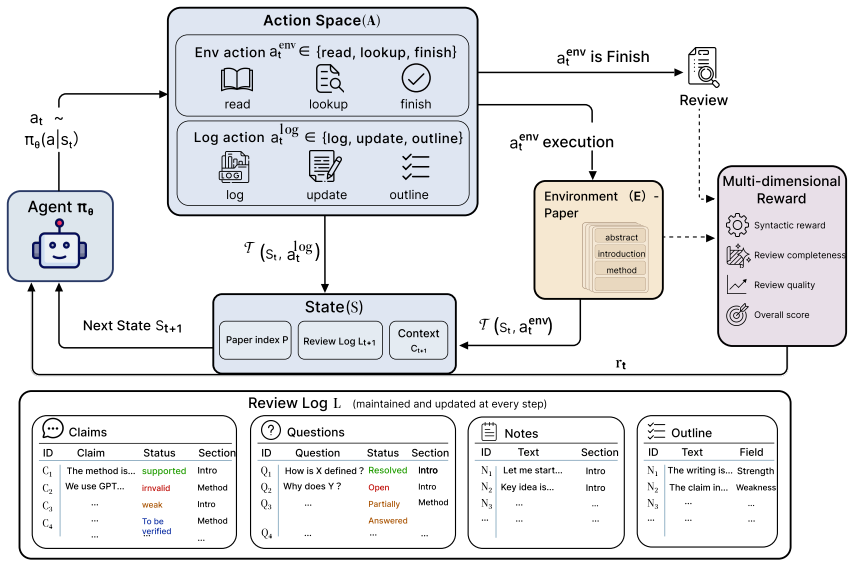
By formulating peer review as a Markov Decision Process where the state includes a structured review log, the ProReviewer agent can perform proactive investigation of papers, leading to higher quality reviews than passive methods even when using a smaller 8B model compared to larger frontier LLMs.
What carries the argument
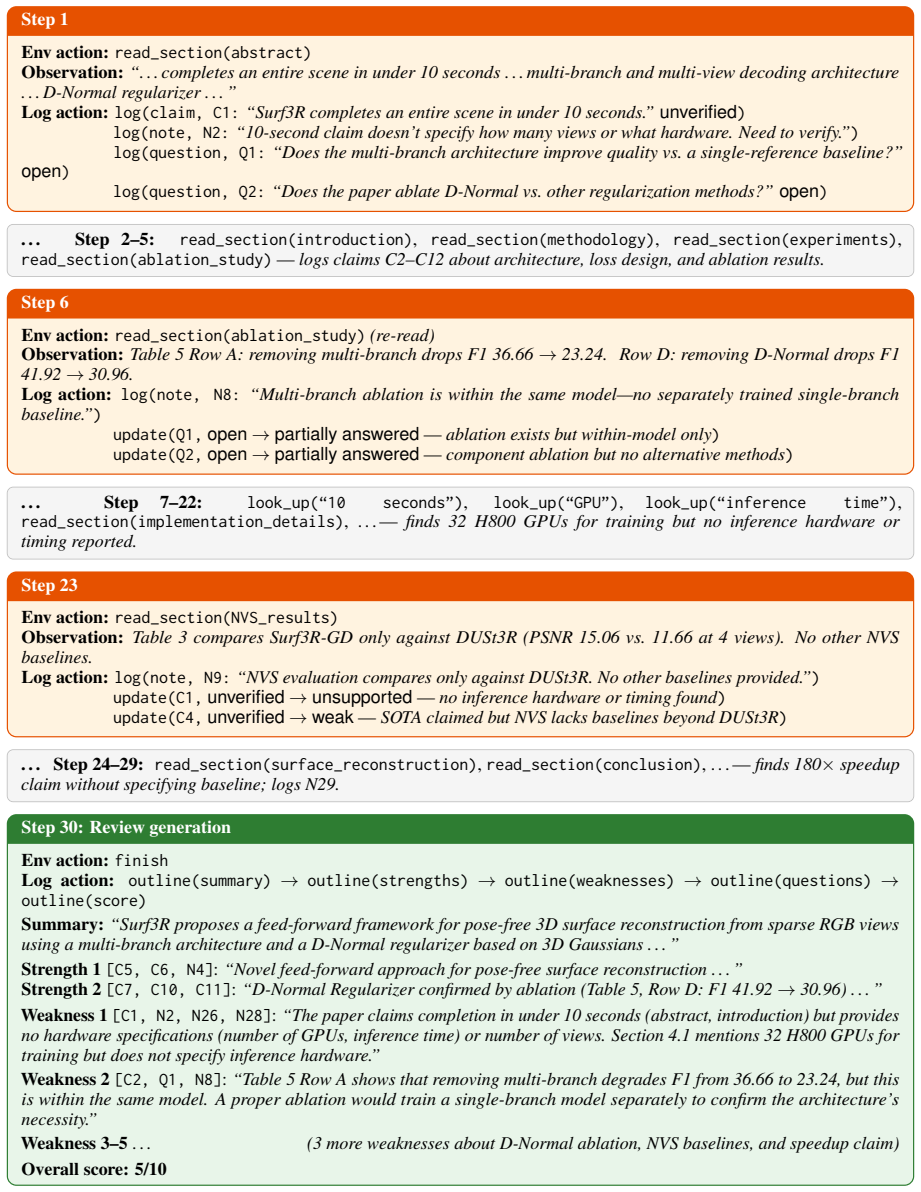
The structured review log within the MDP formulation, which serves as a workspace for the agent to accumulate evidence and intermediate findings to direct its review actions.
If this is right
- ProReviewer with an 8B backbone achieves the highest average score across five quality dimensions.
- It outperforms prompt-based methods using much larger frontier LLMs by up to 39%.
- It outperforms the strongest fine-tuned baseline by 16% relatively.
- It attains the highest win rates against baselines in human evaluation.
Where Pith is reading between the lines
- If the structured log enables better evidence tracking, similar MDP formulations with logs could improve other agent tasks like code debugging or medical diagnosis.
- Removing the log component in experiments would test whether it is essential for the performance gains observed.
- The approach implies that training agents on log-maintained environments may enhance their ability to handle complex, multi-step reasoning tasks beyond review.
Load-bearing premise
The assumption that a structured review log inside an MDP formulation will enable proactive, evidence-guided investigation similar to human reviewers.
What would settle it
A controlled experiment where an otherwise identical agent without the structured review log produces reviews of equal or higher quality on the five dimensions would falsify the necessity of the log for the claimed improvements.
Figures




read the original abstract
Large language models (LLMs) have shown promise in automating scientific peer review. However, existing approaches often struggle to generate in-depth reviews supported by concrete evidence. We argue that a key limitation is the lack of flexibility to proactively investigate suspicious parts of a paper based on accumulated evidence, as human reviewers do. In this paper, we explore how to enable an LLM-based review agent to perform such proactive investigation. We find that this can be naturally formulated as a Markov Decision Process (MDP), and propose ProReviewer, a scientific peer review agent that proactively reviews a paper guided by a maintained, structured review log. The structured review log serves as a workspace for the agent to track evidence and intermediate findings collected during review. Experiments show that ProReviewer with an 8B backbone, trained by supervised fine-tuning and optimized by reinforcement learning, achieves the highest average score across five quality dimensions, outperforming prompt-based methods with much larger frontier LLMs by up to 39% and the strongest fine-tuned baseline by 16% relatively. It also attains the highest win rates against baselines in human evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ProReviewer, an LLM-based scientific peer review agent formulated as a Markov Decision Process (MDP) that maintains a structured review log as a workspace for tracking evidence and intermediate findings. It claims that an 8B-parameter backbone trained via supervised fine-tuning followed by reinforcement learning achieves the highest average score across five quality dimensions, outperforming prompt-based methods using much larger frontier LLMs by up to 39% and the strongest fine-tuned baseline by 16% relatively, while also attaining the highest win rates in human evaluation.
Significance. If the reported gains are shown to stem specifically from the MDP formulation and review log enabling proactive, evidence-guided investigation (rather than from training alone), the work would be significant for demonstrating that smaller models can surpass larger frontier models on complex, multi-step reasoning tasks through structured agentic modeling. The approach addresses a clear limitation in existing passive generation methods for automated review.
major comments (2)
- [Abstract] Abstract: The reported relative gains of 39% and 16% supply no details on experimental design, baseline implementations, statistical significance testing, data splits, or the precise definitions of the five quality dimensions, rendering the central empirical claim unassessable from the provided information.
- [Abstract] Abstract, paragraph on MDP formulation: The central attribution of performance gains to proactive investigation via the MDP and structured review log lacks any description of how the state transitions, action space, or reward structure enforce or measure sequential, evidence-driven decisions (e.g., targeted queries to paper sections based on prior findings) versus simple conditioning on accumulated text; without such evidence or ablations, the modeling choice does not demonstrably support the claimed mechanism.
minor comments (1)
- [Abstract] Abstract: The five quality dimensions used for scoring are not named or defined.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported relative gains of 39% and 16% supply no details on experimental design, baseline implementations, statistical significance testing, data splits, or the precise definitions of the five quality dimensions, rendering the central empirical claim unassessable from the provided information.
Authors: We agree the abstract is concise and omits these specifics. The full manuscript details the experimental design, baselines, data splits, five quality dimensions, and statistical testing (paired t-tests, p<0.05) in Sections 4 and 5. We will revise the abstract to briefly note the evaluation protocol and direct readers to the main text for full information. revision: yes
-
Referee: [Abstract] Abstract, paragraph on MDP formulation: The central attribution of performance gains to proactive investigation via the MDP and structured review log lacks any description of how the state transitions, action space, or reward structure enforce or measure sequential, evidence-driven decisions (e.g., targeted queries to paper sections based on prior findings) versus simple conditioning on accumulated text; without such evidence or ablations, the modeling choice does not demonstrably support the claimed mechanism.
Authors: The abstract offers only a high-level overview. Section 3 of the manuscript fully specifies the MDP: state as the structured review log, action space including targeted section queries conditioned on prior findings, transitions that update the log with new evidence, and a reward encouraging evidence-driven steps. We acknowledge the absence of a direct ablation isolating sequential decision-making from simple text conditioning. We will add this ablation to the revised manuscript. revision: partial
Circularity Check
No circularity; performance claims are empirical outcomes
full rationale
The paper models peer review as an MDP with a structured review log and reports experimental results from SFT+RL training on an 8B model. The strongest claims (39% and 16% gains) are presented as measured outcomes against baselines, not quantities derived from equations or fitted parameters. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The MDP is introduced as a natural formulation rather than a uniqueness theorem or ansatz smuggled via citation. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be effectively trained via SFT followed by RL to follow an MDP policy for paper review
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.08867 , year =
Gaurav Sahu and Hugo Larochelle and Laurent Charlin and Christopher Pal , title =. arXiv preprint arXiv:2510.08867 , year =
-
[2]
Joydeep Biswas and Sheila Schoepp and Gautham Vasan and Anthony Opipari and Arthur Zhang and Zichao Hu and Sebastian Joseph and Matthew Lease and Junyi Jessy Li and Peter Stone and Kiri L. Wagstaff and Matthew E. Taylor and Odest Chadwicke Jenkins , title =. arXiv preprint arXiv:2604.13940 , year =
-
[3]
Zhenzhen Zhuang and Jiandong Chen and Hongfeng Xu and Yuwen Jiang and Jialiang Lin , title =. Inf. Fusion , volume =. 2025 , url =. doi:10.1016/J.INFFUS.2025.103332 , timestamp =
-
[4]
O pen R eviewer: A Specialized Large Language Model for Generating Critical Scientific Paper Reviews
Maximilian Idahl and Zahra Ahmadi , editor =. OpenReviewer:. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2025 , url =. doi:10.18653/V1/2025.NAACL-DEMO.44 , timestamp =
-
[5]
McFarland and James Zou , title =
Weixin Liang and Yuhui Zhang and Hancheng Cao and Binglu Wang and Daisy Ding and Xinyu Yang and Kailas Vodrahalli and Siyu He and Daniel Scott Smith and Yian Yin and Daniel A. McFarland and James Zou , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2310.01783 , eprinttype =. 2310.01783 , timestamp =
-
[6]
Respiratory care , volume=
The peer review process , author=. Respiratory care , volume=. 2024 , url=
2024
-
[7]
Zachary Robertson , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2307.05492 , eprinttype =. 2307.05492 , timestamp =
-
[8]
Ryan Liu and Nihar B. Shah , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2306.00622 , eprinttype =. 2306.00622 , timestamp =
-
[9]
Transactions of the Association for Computational Linguistics , volume =
Dycke, Nils and Gurevych, Iryna , title =. Transactions of the Association for Computational Linguistics , volume =. 2026 , month =. doi:10.1162/TACl.a.642 , url =
-
[10]
Jiangshu Du and Yibo Wang and Wenting Zhao and Zhongfen Deng and Shuaiqi Liu and Renze Lou and Henry Peng Zou and Pranav Narayanan Venkit and Nan Zhang and Mukund Srinath and Haoran Zhang and Vipul Gupta and Yinghui Li and Tao Li and Fei Wang and Qin Liu and Tianlin Liu and Pengzhi Gao and Congying Xia and Chen Xing and Cheng Jiayang and Zhaowei Wang and ...
-
[11]
Hyungyu Shin and Jingyu Tang and Yoonjoo Lee and Nayoung Kim and Hyunseung Lim and Ji Yong Cho and Hwajung Hong and Moontae Lee and Juho Kim , editor =. Mind the Blind Spots:. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.1805 , timestamp =
-
[12]
Reviewer2: Optimizing Review Generation Through Prompt Generation , journal =
Zhaolin Gao and Kiant. Reviewer2: Optimizing Review Generation Through Prompt Generation , journal =. 2024 , url =. doi:10.48550/ARXIV.2402.10886 , eprinttype =. 2402.10886 , timestamp =
-
[13]
DeepReview: Improving LLM-based Paper Review with Human-like Deep Thinking Process , booktitle =
Minjun Zhu and Yixuan Weng and Linyi Yang and Yue Zhang , editor =. DeepReview: Improving LLM-based Paper Review with Human-like Deep Thinking Process , booktitle =. 2025 , url =
2025
-
[14]
The Thirteenth International Conference on Learning Representations,
Yixuan Weng and Minjun Zhu and Guangsheng Bao and Hongbo Zhang and Jindong Wang and Yue Zhang and Linyi Yang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[15]
Abdelrahman Sadallah and Tim Baumg. The Good, the Bad and the Constructive: Automatically Measuring Peer Review's Utility for Authors , booktitle =. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.1476 , timestamp =
-
[16]
Automatic generation of reviews of scientific papers , booktitle =
Anna Nikiforovskaya and Nikolai Kapralov and Anna Vlasova and Oleg Shpynov and Aleksei Shpilman , editor =. Automatic generation of reviews of scientific papers , booktitle =. 2020 , url =. doi:10.1109/ICMLA51294.2020.00058 , timestamp =
-
[17]
ReviewEval: An Evaluation Framework for AI-Generated Reviews , booktitle =
Madhav Krishan Garg and Tejash Prasad and Tanmay Singhal and Chhavi Kirtani and Murari Mandal and Dhruv Kumar , editor =. ReviewEval: An Evaluation Framework for AI-Generated Reviews , booktitle =. 2025 , url =
2025
-
[18]
Automatic Analysis of Substantiation in Scientific Peer Reviews , booktitle =
Yanzhu Guo and Guokan Shang and Virgile Rennard and Michalis Vazirgiannis and Chlo. Automatic Analysis of Substantiation in Scientific Peer Reviews , booktitle =. 2023 , url =. doi:10.18653/V1/2023.FINDINGS-EMNLP.684 , timestamp =
-
[19]
ScholarPeer: A Context-Aware Multi-Agent Framework for Automated Peer Review
Palash Goyal and Mihir Parmar and Yiwen Song and Hamid Palangi and Tomas Pfister and Jinsung Yoon , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2601.22638 , eprinttype =. 2601.22638 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.22638 2026
-
[20]
AgentReview: Exploring Peer Review Dynamics with
Yiqiao Jin and Qinlin Zhao and Yiyang Wang and Hao Chen and Kaijie Zhu and Yijia Xiao and Jindong Wang , editor =. AgentReview: Exploring Peer Review Dynamics with. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.70 , timestamp =
-
[21]
The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search
Yutaro Yamada and Robert Tjarko Lange and Cong Lu and Shengran Hu and Chris Lu and Jakob N. Foerster and Jeff Clune and David Ha , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.08066 , eprinttype =. 2504.08066 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.08066 2025
-
[22]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.09388 , eprinttype =. 2505.09388 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[23]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2407.21783 , eprinttype =. 2407.21783 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[24]
ReviewRL: Towards Automated Scientific Review with
Sihang Zeng and Kai Tian and Kaiyan Zhang and Yuru Wang and Junqi Gao and Runze Liu and Sa Yang and Jingxuan Li and Xinwei Long and Jiaheng Ma and Biqing Qi and Bowen Zhou , editor =. ReviewRL: Towards Automated Scientific Review with. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =. doi:10.18653/V1/20...
-
[25]
Yuan Chang and Ziyue Li and Hengyuan Zhang and Yuanbo Kong and Yanru Wu and Hayden Kwok. TreeReview:. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing,. 2025 , url =. doi:10.18653/V1/2025.EMNLP-MAIN.790 , timestamp =
-
[26]
Reiichiro Nakano and Jacob Hilton and Suchir Balaji and Jeff Wu and Long Ouyang and Christina Kim and Christopher Hesse and Shantanu Jain and Vineet Kosaraju and William Saunders and Xu Jiang and Karl Cobbe and Tyna Eloundou and Gretchen Krueger and Kevin Button and Matthew Knight and Benjamin Chess and John Schulman , title =. CoRR , volume =. 2021 , url...
Pith/arXiv arXiv 2021
-
[27]
Narasimhan and Yuan Cao , title =
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik R. Narasimhan and Yuan Cao , title =. The Eleventh International Conference on Learning Representations,. 2023 , url =
2023
-
[28]
Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R. Narasimhan , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[29]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu and Cong Lu and Robert Tjarko Lange and Jakob N. Foerster and Jeff Clune and David Ha , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2408.06292 , eprinttype =. 2408.06292 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.06292 2024
-
[30]
Nye and Anders Johan Andreassen and Guy Gur
Maxwell I. Nye and Anders Johan Andreassen and Guy Gur. Show Your Work: Scratchpads for Intermediate Computation with Language Models , journal =. 2021 , url =. 2112.00114 , timestamp =
Pith/arXiv arXiv 2021
-
[31]
Advances in Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[32]
Reflexion: language agents with verbal reinforcement learning , booktitle =
Noah Shinn and Federico Cassano and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao , editor =. Reflexion: language agents with verbal reinforcement learning , booktitle =. 2023 , url =
2023
-
[33]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , editor =...
2022
-
[34]
arXiv preprint arXiv:2402.03300 , year=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[35]
Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2402.03300 , eprinttype =. 2402.03300 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[36]
Daya Guo and Dejian Yang and Haowei Zhang and Junxiao Song and Peiyi Wang and Qihao Zhu and Runxin Xu and Ruoyu Zhang and Shirong Ma and Xiao Bi and Xiaokang Zhang and Xingkai Yu and Yu Wu and Z. F. Wu and Zhibin Gou and Zhihong Shao and Zhuoshu Li and Ziyi Gao and Aixin Liu and Bing Xue and Bingxuan Wang and Bochao Wu and Bei Feng and Chengda Lu and Chen...
-
[37]
Sikuan Yan and Xiufeng Yang and Zuchao Huang and Ercong Nie and Zifeng Ding and Zonggen Li and Xiaowen Ma and Hinrich Sch. Memory-R1: Enhancing Large Language Model Agents to Manage and Utilize Memories via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2508.19828 , eprinttype =. 2508.19828 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.19828 2025
-
[38]
2026 , howpublished=
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author=. 2026 , howpublished=
2026
-
[39]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.10925 , eprinttype =. 2508.10925 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[40]
Memory in the Age of AI Agents
Yuyang Hu and Shichun Liu and Yanwei Yue and Guibin Zhang and Boyang Liu and Fangyi Zhu and Jiahang Lin and Honglin Guo and Shihan Dou and Zhiheng Xi and Senjie Jin and Jiejun Tan and Yanbin Yin and Jiongnan Liu and Zeyu Zhang and Zhongxiang Sun and Yutao Zhu and Hao Sun and Boci Peng and Zhenrong Cheng and Xuanbo Fan and Jiaxin Guo and Xinlei Yu and Zhen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.13564 2025
-
[41]
Self-Refine: Iterative Refinement with Self-Feedback , booktitle =
Aman Madaan and Niket Tandon and Prakhar Gupta and Skyler Hallinan and Luyu Gao and Sarah Wiegreffe and Uri Alon and Nouha Dziri and Shrimai Prabhumoye and Yiming Yang and Shashank Gupta and Bodhisattwa Prasad Majumder and Katherine Hermann and Sean Welleck and Amir Yazdanbakhsh and Peter Clark , editor =. Self-Refine: Iterative Refinement with Self-Feedb...
2023
-
[42]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =
Lianmin Zheng and Wei. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , booktitle =. 2023 , url =
2023
-
[43]
Tianmai M. Zhang and Neil F. Abernethy , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2505.23824 , eprinttype =. 2505.23824 , timestamp =
-
[44]
DeepReviewer 2.0: A Traceable Agentic System for Auditable Scientific Peer Review
Yixuan Weng and Minjun Zhu and Qiujie Xie and Zhiyuan Ning and Shichen Li and Panzhong Lu and Zhen Lin and Enhao Gu and Qiyao Sun and Yue Zhang , title =. CoRR , volume =. 2026 , url =. doi:10.48550/ARXIV.2604.09590 , eprinttype =. 2604.09590 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.09590 2026
-
[45]
Applied cognitive psychology , volume=
Cognitive effort during note taking , author=. Applied cognitive psychology , volume=. 2005 , publisher=
2005
-
[46]
Jiatao Li and Yanheng Li and Xinyu Hu and Mingqi Gao and Xiaojun Wan , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2502.12510 , eprinttype =. 2502.12510 , timestamp =
-
[47]
Rui Ye and Xianghe Pang and Jingyi Chai and Jiaao Chen and Zhenfei Yin and Zhen Xiang and Xiaowen Dong and Jing Shao and Siheng Chen , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2412.01708 , eprinttype =. 2412.01708 , timestamp =
-
[48]
Gehringer and Ting Xiao and Junhua Ding and Haihua Chen , title =
Ruochi Li and Haoxuan Zhang and Edward F. Gehringer and Ting Xiao and Junhua Ding and Haihua Chen , title =. 2025 , url =. doi:10.1109/ICDM65498.2025.00146 , timestamp =
-
[49]
Findings of the Association for Computational Linguistics:
Jiefu Ou and William Gantt Walden and Kate Sanders and Zhengping Jiang and Kaiser Sun and Jeffrey Cheng and William Jurayj and Miriam Wanner and Shaobo Liang and Candice Morgan and Seunghoon Han and Weiqi Wang and Chandler May and Hannah Recknor and Daniel Khashabi and Benjamin Van Durme , editor =. Findings of the Association for Computational Linguistic...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.