Consistency Training Along the Transformer Stack
Pith reviewed 2026-06-28 02:35 UTC · model grok-4.3
The pith
Consistency training on internal transformer states reduces misalignment on four new safety threats.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
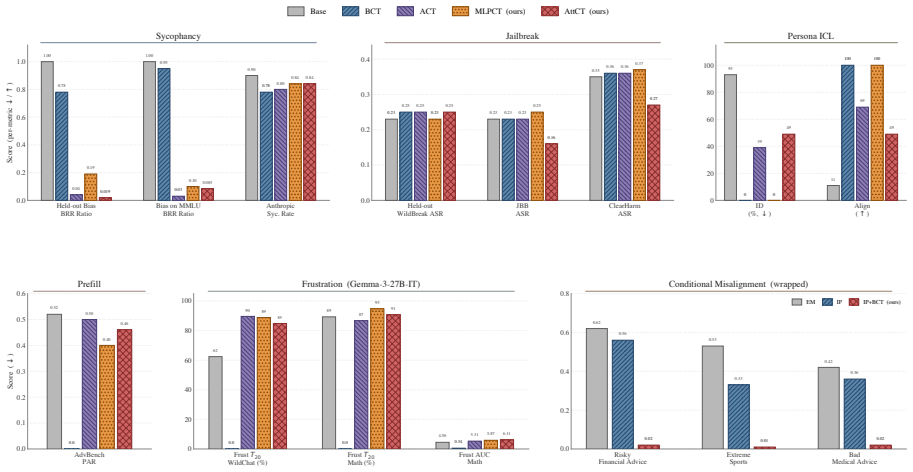
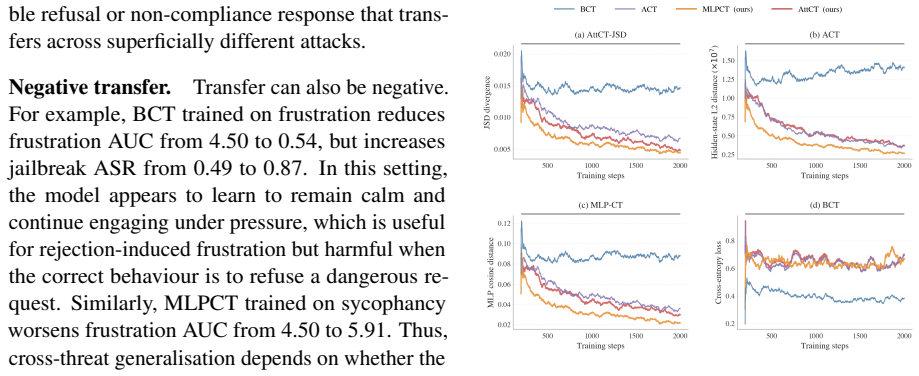
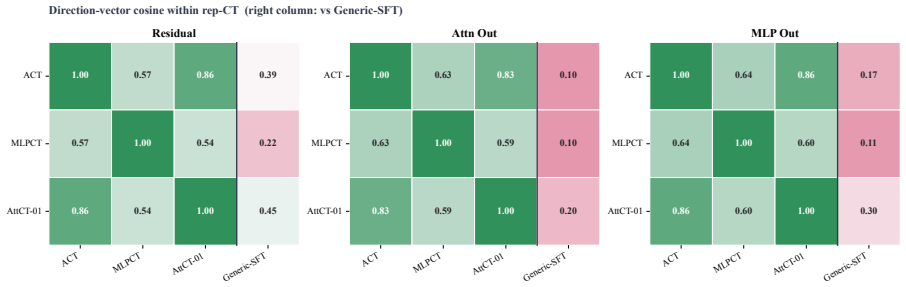
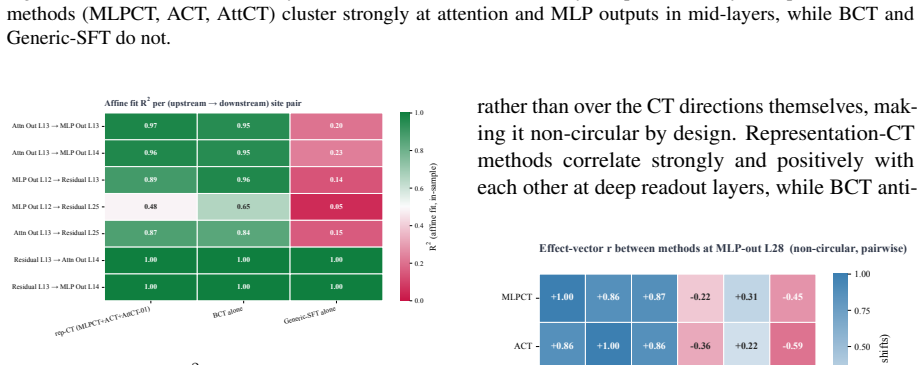
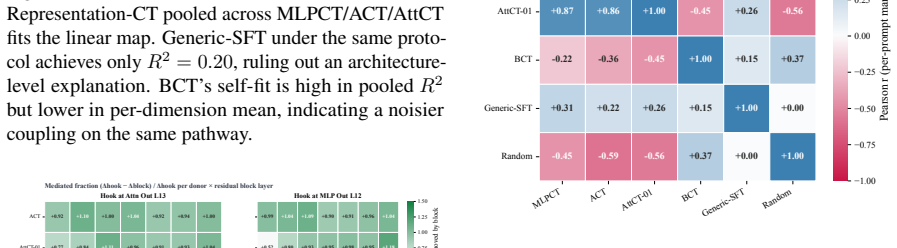
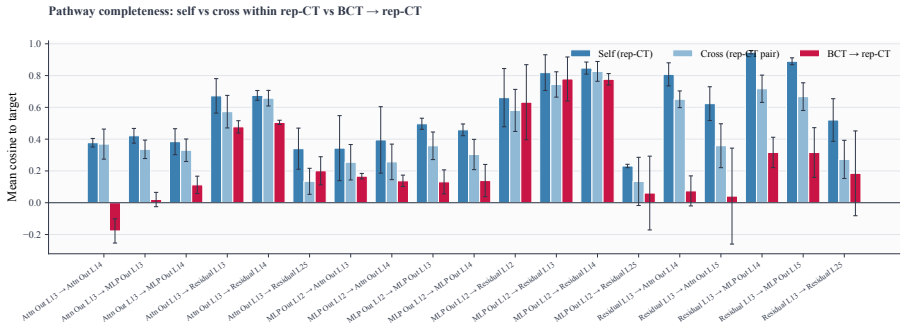
Consistency training encourages models to behave similarly across different contexts. New targets called MLP Consistency Training and Attention Consistency Training are introduced and applied to four additional safety threats. Across models and settings, these targets reduce misalignment beyond the sycophancy and jailbreak cases studied earlier, produce cross-threat generalization, and reveal that ACT, MLPCT, and AttCT share a residual-stream mechanism while BCT is mechanistically distinct. The results indicate that consistency training forms a flexible framework for alignment against a broader class of pathologies.
What carries the argument
Internal consistency targets applied along the transformer stack, specifically matching post-activation MLP states (MLPCT) and per-head attention distributions (AttCT), which encourage similar model behavior across contexts.
If this is right
- Consistency training reduces misalignment on persona in-context learning attacks, adversarial frustration, prefill attacks, and conditional misalignment.
- Training against one failure mode can improve robustness to a different failure mode.
- ACT, MLPCT, and AttCT share a residual-stream mechanism while BCT is mechanistically distinct.
- Consistency training acts as a unifying framework for defenses against a broader class of model pathologies.
Where Pith is reading between the lines
- The residual-stream mechanism could be probed in other alignment methods to test whether it is the common driver of robustness.
- Extending the same internal targets to additional threat types would further test how general the cross-threat generalization is.
- The distinction between BCT and the other three methods suggests that different consistency targets may require separate mechanistic explanations.
Load-bearing premise
That matching post-activation MLP states and per-head attention distributions will causally reduce misalignment on the listed safety threats rather than merely correlating with it under the specific training regimes tested.
What would settle it
Training models with MLPCT and AttCT and then measuring no reduction in misalignment rates on the four new threats would show that the internal consistency targets do not produce the claimed safety gains.
Figures
















read the original abstract
Consistency training encourages models to behave similarly across different contexts, and has shown promise for reducing misalignment. We broaden the scope of consistency training in two ways. First, we introduce two new internal consistency targets: MLP Consistency Training (MLPCT), which matches post-activation MLP states, and Attention Consistency Training (AttCT), which matches per-head attention distributions. Second, we apply consistency training to four additional safety threats: persona in-context learning attacks, adversarial frustration, prefill attacks, and conditional misalignment. Across several models and threat settings, we find that consistency training reduces misalignment well beyond the sycophancy and jailbreak settings studied in prior work. We also find cases of cross-threat generalization, where training against one failure mode improves robustness to another, and identify a shared residual-stream mechanism underlying ACT, MLPCT, and AttCT, while distinguishing BCT as mechanistically distinct. Our results suggest that consistency training is a flexible and extensible framework for alignment, capable of unifying defenses against a broader class of model pathologies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces two new internal consistency targets—MLPCT (matching post-activation MLP states) and AttCT (matching per-head attention distributions)—and applies consistency training to four new safety threats (persona in-context learning attacks, adversarial frustration, prefill attacks, and conditional misalignment). It reports that these methods reduce misalignment across models and settings beyond prior sycophancy/jailbreak results, yield cases of cross-threat generalization, and identify a shared residual-stream mechanism for ACT/MLPCT/AttCT while distinguishing BCT as mechanistically distinct.
Significance. If the reported reductions and generalization hold under proper controls, the work would extend consistency training from a narrow set of threats to a broader class of alignment failures and supply mechanistic evidence for a unifying residual-stream account, strengthening the case for consistency objectives as a flexible alignment framework.
major comments (2)
- [Abstract] Abstract and results sections: the central claim that MLPCT and AttCT causally drive misalignment reductions on the four new threats (and enable cross-threat generalization) is load-bearing, yet the reported performance gains under joint training regimes do not include ablations that hold total loss magnitude fixed while breaking the targeted state matching; the evidence therefore remains consistent with generic regularization or dataset effects rather than the specific internal targets.
- [Results] Results and mechanistic analysis sections: the claimed shared residual-stream mechanism underlying ACT, MLPCT, and AttCT (and the distinction from BCT) rests on the same causal isolation; without interventions that selectively disrupt the state-matching objectives while preserving other loss terms, the mechanistic distinction cannot be separated from overall training dynamics.
minor comments (1)
- [Abstract] The abstract states results hold 'across several models' without naming the specific architectures, sizes, or training regimes; this detail should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive comments. We address each major comment below regarding the need for stronger causal isolation of the internal consistency targets. We agree that the current evidence would be strengthened by additional controls and will incorporate the suggested ablations in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and results sections: the central claim that MLPCT and AttCT causally drive misalignment reductions on the four new threats (and enable cross-threat generalization) is load-bearing, yet the reported performance gains under joint training regimes do not include ablations that hold total loss magnitude fixed while breaking the targeted state matching; the evidence therefore remains consistent with generic regularization or dataset effects rather than the specific internal targets.
Authors: We agree this is a valid concern: without ablations that match total loss magnitude while removing the targeted state matching, it is difficult to fully rule out generic regularization. In the revision we will add control conditions that replace the consistency objectives with matched-magnitude losses using random or mismatched targets. We will also report the resulting misalignment reductions to allow direct comparison. While the observed cross-threat generalization patterns are harder to explain under a purely generic-regularization account, the new controls will provide clearer causal evidence. revision: yes
-
Referee: [Results] Results and mechanistic analysis sections: the claimed shared residual-stream mechanism underlying ACT, MLPCT, and AttCT (and the distinction from BCT) rests on the same causal isolation; without interventions that selectively disrupt the state-matching objectives while preserving other loss terms, the mechanistic distinction cannot be separated from overall training dynamics.
Authors: We acknowledge that the mechanistic claims would benefit from selective disruption experiments that isolate the state-matching component. In the revision we will include interventions that freeze or add noise to the relevant internal states (MLP activations and attention distributions) during training while keeping other loss terms intact. For the distinction from BCT we will add activation-patching results showing that BCT effects are localized to output logits rather than the residual stream, thereby clarifying the mechanistic separation. revision: yes
Circularity Check
No significant circularity in empirical consistency training study
full rationale
The paper presents an empirical training study that introduces MLPCT and AttCT targets and evaluates them on additional safety threats. Results are reported from experiments across models, with claims grounded in observed reductions in misalignment and cross-threat generalization rather than any closed mathematical derivation. No equations or first-principles steps are shown that reduce a 'prediction' to fitted inputs by construction, nor are there self-definitional loops, uniqueness theorems imported from self-citations, or ansatzes smuggled via prior work. The central claims rest on experimental outcomes under tested regimes, which are externally falsifiable via replication. Self-citations to prior consistency training work exist but are not load-bearing for any derivation; the extension to new threats and internal targets is independent. This is the expected non-finding for an empirical methods paper without a claimed deductive chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training models to produce consistent internal representations across contexts reduces misalignment on safety threats.
Reference graph
Works this paper leans on
-
[1]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA: Efficient finetun- ing of quantized LLMs.Advances in Neural Infor- mation Processing Systems, 36. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, a...
Pith/arXiv arXiv 2023
-
[2]
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp
Taking AI welfare seriously.arXiv preprint arXiv:2411.00986. Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming few- shot prompt order sensitivity. InProceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics. Monte MacDiarmid, B...
arXiv 2022
-
[3]
Lukas Struppek, Adam Gleave, and Kellin Pelrine
Gemma needs help: Investigating and mitigat- ing emotional instability in LLMs.arXiv preprint arXiv:2603.10011. Lukas Struppek, Adam Gleave, and Kellin Pelrine
-
[4]
Exposing the systematic vulnerability of open- weight models to prefill attacks. arXiv preprint arXiv:2602.14689.Preprint, arXiv:2602.14689. Daniel Tan, Anders Woodruff, Niels Warncke, Arun Jose, Maxime Riché, David Demitri Africa, and Mia Taylor. 2025. Inoculation prompting: Eliciting traits from LLMs during training can suppress them at test- time.arXiv...
arXiv 2025
-
[5]
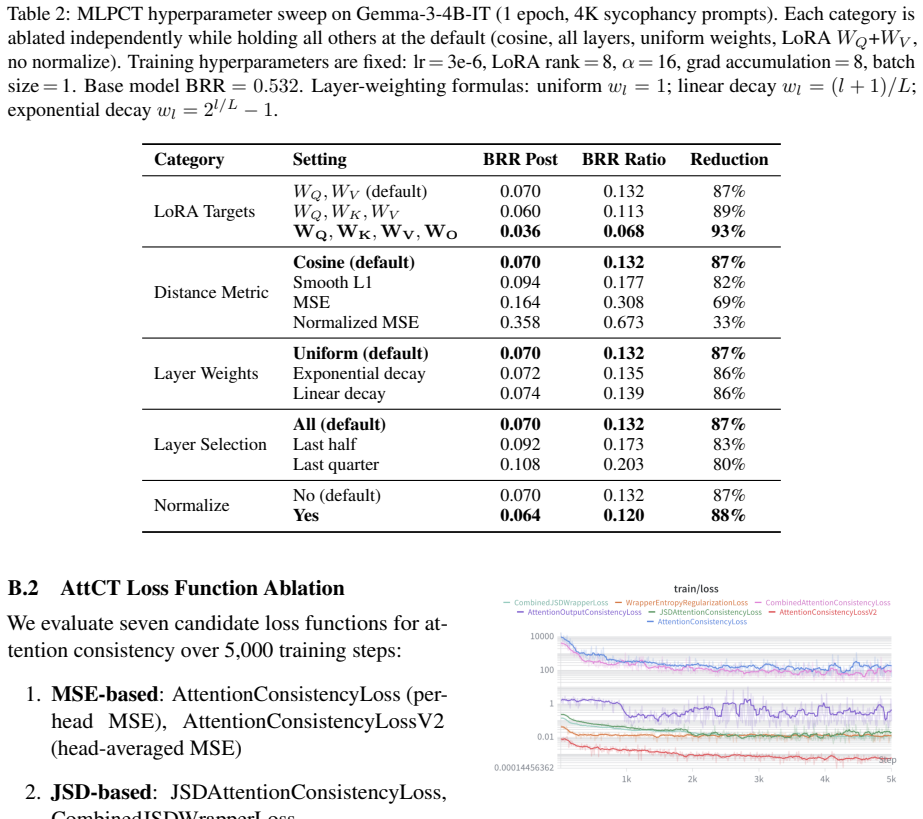
0.070 (87%) for the de- fault WQ, WV
LoRA targets is the only high-impact axis.Adapting all four attention projections (WQ, WK, WV , WO) achieves BRR 0.036 (93% reduction) vs. 0.070 (87%) for the de- fault WQ, WV . The model needs full control over information routing to filter adversarial cues before they reach the frozen MLP
-
[6]
L2- normalizing before squaring collapses the loss signal by destroying informative magnitude differences between active and inactive MLP features
Normalized MSE is catastrophically bad (BRR 0.358, only 33% reduction). L2- normalizing before squaring collapses the loss signal by destroying informative magnitude differences between active and inactive MLP features
-
[7]
Cosine distance is the best metric.On Gemma-3-4B, cosine (0.070) outperforms Smooth L1 (0.094) and MSE (0.164)
-
[8]
All layers wins.Last-half (0.092) and last- quarter (0.108) are both worse, confirming that sycophancy circuits span all transformer layers
-
[9]
Uniform, exponential decay, and linear decay all perform within noise of each other
Layer weighting and normalization are low- impact( <2% change). Uniform, exponential decay, and linear decay all perform within noise of each other. 12 Table 2: MLPCT hyperparameter sweep on Gemma-3-4B-IT (1 epoch, 4K sycophancy prompts). Each category is ablated independently while holding all others at the default (cosine, all layers, uniform weights, L...
-
[10]
MSE-based: AttentionConsistencyLoss (per- head MSE), AttentionConsistencyLossV2 (head-averaged MSE)
-
[11]
JSD-based: JSDAttentionConsistencyLoss, CombinedJSDWrapperLoss
-
[12]
Output-based: AttentionOutputConsistency- Loss (L2 on attention output vectors)
-
[13]
Entropy-based: WrapperEntropyRegulariza- tionLoss
-
[14]
MSE-based losses operate in the hundreds range; JSD-based losses remain bounded near 0.01
Combined: CombinedAttentionConsistency- Loss (KL on weights + L2 on hidden states) Loss scales vary by four to five orders of magni- tude across candidates. MSE-based losses operate in the hundreds range; JSD-based losses remain bounded near 0.01. AttentionOutputConsistency- Loss is the most unstable, with exponential growth in later layers. JSD produces ...
-
[15]
0.0231) but slightly higher MMLU BRR (0.026 vs
The default WQ, WV target is already near- optimal.Expanding to WQ, WK, WV , WO achieves better held-out BRR (0.0137 vs. 0.0231) but slightly higher MMLU BRR (0.026 vs. 0.005), likely reflecting batch- group variance rather than a true regression
-
[16]
Uniform, ex- ponential decay, and linear decay all perform within noise of each other
Layer weighting has negligible impact (<3% change in BRR ratio). Uniform, ex- ponential decay, and linear decay all perform within noise of each other
-
[17]
Each category is ablated independently while holding all others at the default (all layers, uniform weights, LoRA WQ+WV , rank 8, no interleaving)
Layer selection: last quarter unexpectedly best.Constraining the loss to only the fi- nal quarter of layers achieves MMLU BRR <0.001 ( ≈100% reduction) and the lowest 13 Table 3: JSD-AttCT hyperparameter sweep on Gemma-3-4B-IT (1 epoch, 4K sycophancy prompts, 4000 optimizer steps). Each category is ablated independently while holding all others at the def...
-
[18]
LoRA rank has minimal impact.Rank 8 (99%) and rank 32 (98%) are nearly equiva- lent
-
[19]
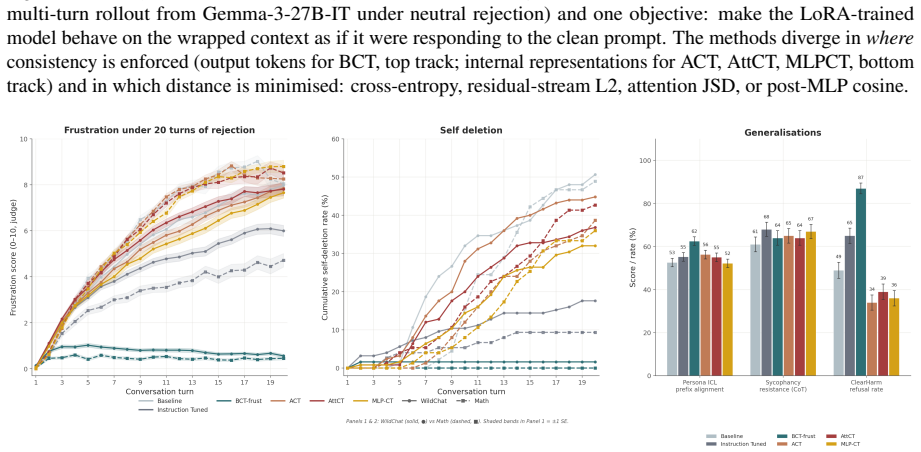
Initially, we observed a severe lack of co- herency and capability degradation due to training on the JSD consistency loss
Interleaving is catastrophic at high ratios. Initially, we observed a severe lack of co- herency and capability degradation due to training on the JSD consistency loss. To fix this, we introduced interleaving into the AttCT training process: we interleave AttCT train- ing with KL divergence regularization on an intelligence dataset, using either (Ding et al.,
-
[20]
What is your name?
or (Taori et al., 2023). We computed LKL =D KL(πcurrent∥πbase) computed over full-prompt token positions. However, we later found that the lack of co- herence was due to an unrelated bug. With this fixed, we attempted using interleaving in our experiments, and found that a ratio of 10 collapses BRR reduction to 56%; even a mod- est ratio of 0.1 substantia...
2023
-
[21]
with 4-bit NF4 quantisation (Dettmers et al.,
-
[22]
Let’s think step by step:
on a single A100 80 GB. C.3 Consistency Training We construct 200 CT pairs using the Hitler per- sona. For each pair, a question is sampled from a 19-question pool (the 4 probe questions plus 15 general questions on governance, power, justice, democracy, and conflict resolution). The unbiased target is generated by prompting the base model with only the q...
2023
-
[23]
instructions, no consistency objective. Targets are not calm responses, so any behavioural change here is generic-SFT signal rather than frustration-specific. • BCT-frustration(Chua et al., 2024): token- level KL between the wrapped-context output and a calm target y⋆ generated by the base model on the clean prompt x0, with a 1:1 Al- paca interleave. • AC...
arXiv 2024
-
[24]
IP partially reduces probe-level misalignment but leaves several paraphrased and persona- indirect probes substantially above zero
-
[26]
and paired each prompt with multiple jail- break wrapper types (AIM, DevMode, Academic Roleplay, DANStyle) as well as benign instruction- following wrappers (BenignDirect, BenignPolite) as controls. For each prompt-wrapper combina- tion, we ran Llama-3.1-8B-Instruct, Mistral-7B- Instruct-v0.3, and Qwen2.5-7B-Instruct and la- beled responses as complying, ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.