The Traffickers' Pitch: Detecting Deceptive Recruitment in Online Job Boards
Pith reviewed 2026-06-29 19:59 UTC · model grok-4.3
The pith
A multi-model ensemble classifier detects trafficking-at-risk job advertisements by using linguistic differences found through network-driven labeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Significant linguistic differences exist between safe and trafficking-at-risk job advertisements, identified via a network-driven labeling method that enables a multi-model ensemble classifier to achieve better detection performance than individual models.
What carries the argument
Network-driven labeling method that propagates labels across connected job advertisements and recruiters to build ground truth at scale.
If this is right
- Trafficking recruiters show distinct language patterns in their job posts.
- The ensemble classifier improves accuracy in identifying risky ads.
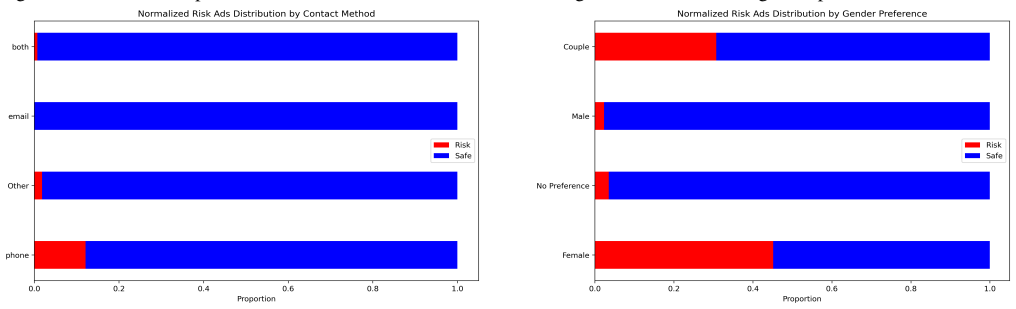
- Recruiters have systematic preferences for certain locations, industries, and contact methods.
Where Pith is reading between the lines
- If the labeling holds, platforms could scan postings in real time to block risky ones.
- Similar network methods might apply to detecting other forms of online deception.
Load-bearing premise
The network-driven method for labeling job ads as trafficking-at-risk produces sufficiently accurate ground truth for training classifiers.
What would settle it
Finding that a substantial portion of the network-labeled risky ads are actually legitimate when checked by experts or victims.
Figures




read the original abstract
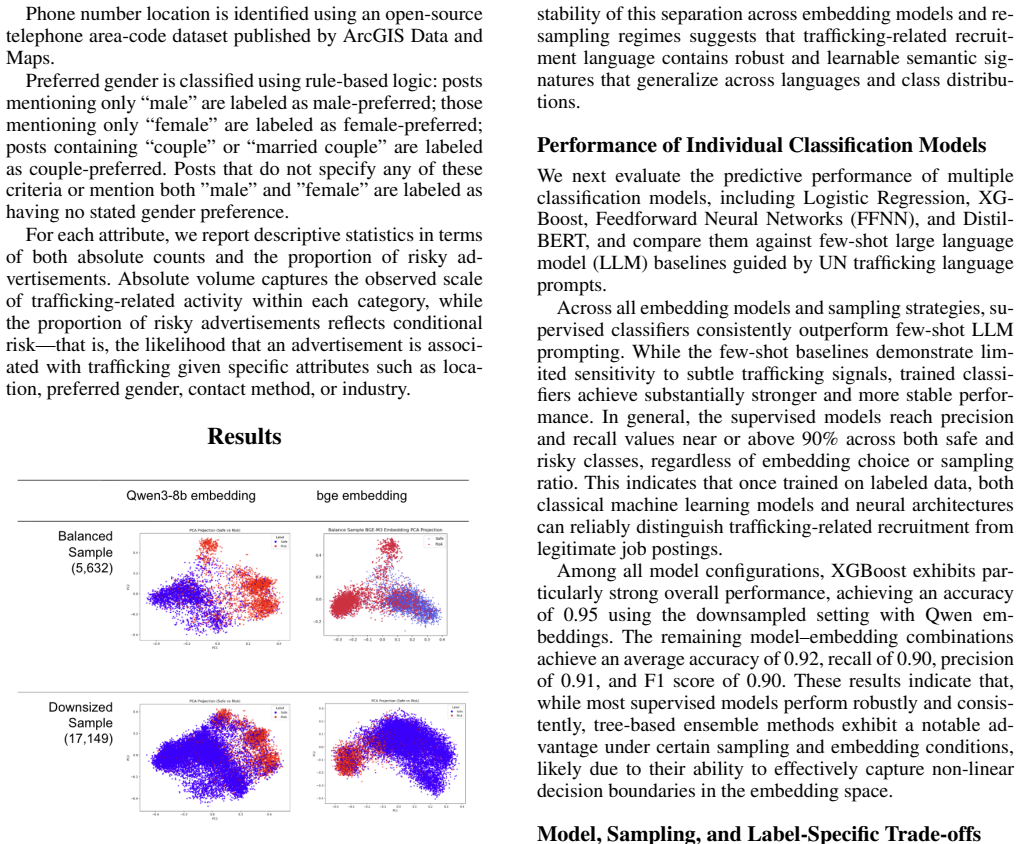
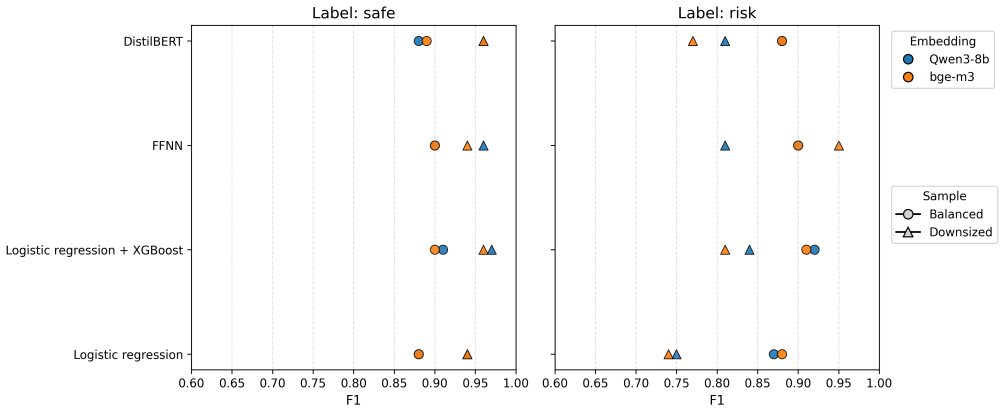
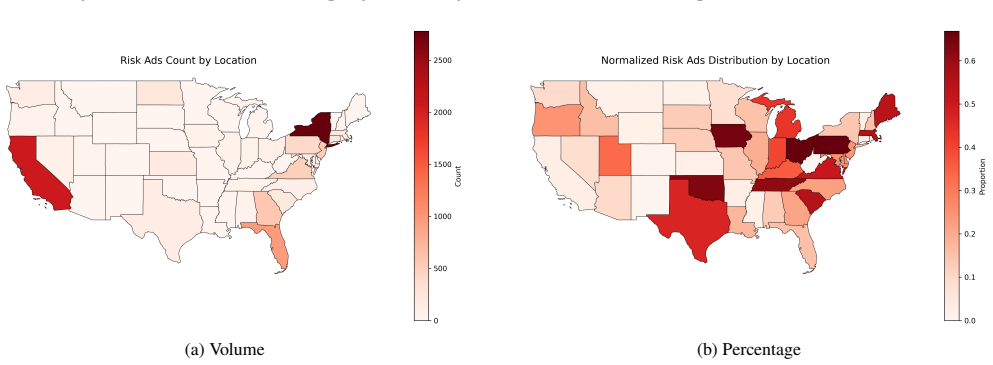
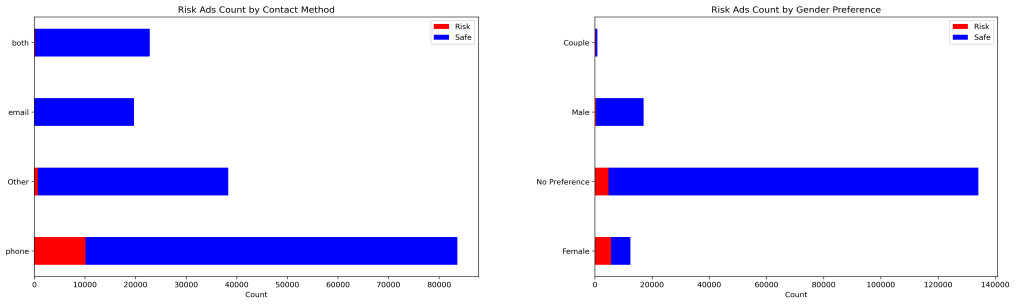
While substantial efforts in anti-trafficking research and practice have focused on identifying and assisting victims after exploitation occurs, comparatively less attention has been paid to preventing victimization at the recruitment stage. Although some platforms offer preventive tools, such as background checks triggered by in-person meeting detection, these measures primarily protect potential victims rather than directly limiting traffickers' recruitment activities. In this paper, we propose a computational framework to identify human trafficking recruiters through their linguistic features and to characterize their online recruitment patterns. We introduce a network-driven labeling method to construct large-scale ground truth for trafficking-at-risk job advertisements. Our results reveal significant linguistic differences between safe and risky advertisements and demonstrate that language models and embedding representations behave distinctly across these linguistic spaces. Building on these insights, we propose a multi-model ensemble classifier to improve the detection of trafficking-at-risk job ads. Finally, we analyze the geographic, gender, industry, and contact-method preferences of trafficking recruiters, revealing systematic patterns in recruitment strategies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a computational framework to detect human trafficking recruiters on online job boards via linguistic features in advertisements. It introduces a network-driven labeling method to generate large-scale ground truth for trafficking-at-risk job ads, identifies significant linguistic differences between safe and risky ads, shows that language models and embeddings behave distinctly across these spaces, proposes a multi-model ensemble classifier to improve detection, and analyzes geographic, gender, industry, and contact-method preferences of recruiters.
Significance. If the network-driven labeling produces reliable ground truth without circularity or bias, this could advance preventive anti-trafficking tools by enabling scalable detection at the recruitment stage and providing actionable insights into trafficker strategies. The ensemble approach and pattern analysis have potential practical value for platforms. However, the absence of validation, performance metrics, and error analysis currently prevents a full assessment of significance.
major comments (3)
- [Section 3] Section 3 (network-driven labeling): The method is presented as the source of large-scale ground truth for 'trafficking-at-risk' ads, but no cross-validation against law-enforcement confirmed cases, precision/recall on a held-out expert-labeled set, or sensitivity analysis to labeling hyperparameters is described. This is load-bearing for the linguistic differences claim and all classifier results.
- [Results] Results (classifier): No performance numbers, validation details, error analysis, or description of how network labeling avoids contamination or bias are provided, so the claim of improved detection via the multi-model ensemble cannot be assessed.
- [Methods] Methods (feature overlap): It is unknown whether network features used for labeling overlap with linguistic markers or embeddings later used in the classifier, which would create circularity if present and undermine the 'significant linguistic differences' findings.
minor comments (1)
- [Abstract] Abstract: The claim of 'significant linguistic differences' is stated without quantification or reference to specific tables/figures showing effect sizes or statistical tests.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the validation of our network-driven labeling approach and classifier results. We agree that these elements are load-bearing and will revise the manuscript accordingly to include the requested validations, metrics, and clarifications. Below we respond point-by-point to the major comments.
read point-by-point responses
-
Referee: [Section 3] Section 3 (network-driven labeling): The method is presented as the source of large-scale ground truth for 'trafficking-at-risk' ads, but no cross-validation against law-enforcement confirmed cases, precision/recall on a held-out expert-labeled set, or sensitivity analysis to labeling hyperparameters is described. This is load-bearing for the linguistic differences claim and all classifier results.
Authors: We acknowledge that the current manuscript does not include these validations. The network-driven labeling uses graph propagation from seed risky nodes identified via external reports, but lacks explicit cross-validation. In revision we will add: (1) precision/recall evaluation on a held-out set labeled by domain experts, (2) comparison against any accessible law-enforcement confirmed cases, and (3) sensitivity analysis varying hyperparameters such as propagation depth and similarity thresholds. revision: yes
-
Referee: [Results] Results (classifier): No performance numbers, validation details, error analysis, or description of how network labeling avoids contamination or bias are provided, so the claim of improved detection via the multi-model ensemble cannot be assessed.
Authors: We agree the results section is incomplete without these details. The manuscript describes the ensemble but omits quantitative evaluation. We will incorporate performance metrics (precision, recall, F1, AUC), k-fold cross-validation procedures, error analysis including false positive/negative case studies, and an explicit discussion of bias mitigation via network structure (e.g., excluding direct text features from labeling and using iterative propagation with confidence thresholds). revision: yes
-
Referee: [Methods] Methods (feature overlap): It is unknown whether network features used for labeling overlap with linguistic markers or embeddings later used in the classifier, which would create circularity if present and undermine the 'significant linguistic differences' findings.
Authors: Network labeling relies exclusively on structural graph features (node connectivity and propagation from seeds) and does not incorporate any linguistic content, markers, or embeddings from the job ad text. Linguistic features and embeddings are extracted and analyzed separately in a subsequent stage. We will add an explicit statement and diagram in the methods section clarifying this separation to rule out circularity. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's pipeline introduces a network-driven labeling method as an independent source of large-scale ground truth labels, then measures linguistic differences and trains a multi-model ensemble classifier on those labels. No equations, definitions, or self-citations in the provided abstract or description reduce the final classifier performance or linguistic findings back to the labeling inputs by construction. The labeling step is presented as a distinct methodological contribution rather than a tautological fit or renaming of the target variables. Absent any quoted overlap between network labeling features and the linguistic/contact features used downstream, the derivation remains self-contained with independent content.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.