SiamCTC: Learning Speech Representations through Monotonic Temporal Alignment
Pith reviewed 2026-06-28 12:50 UTC · model grok-4.3
The pith
SiamCTC replaces frame-wise matching with CTC-based monotonic alignments to learn speech representations robust to speed changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By training Siamese networks with CTC loss rather than strict frame-level alignment, SiamCTC produces speech representations that accommodate temporal augmentations such as speed changes while maintaining temporal coherence and linguistic invariance.
What carries the argument
CTC loss applied between the two branches of a Siamese network to compute monotonic alignments between temporally differing realizations of the same utterance.
If this is right
- Representations become more adaptable to speed perturbations without explicit frame correspondence.
- Temporal coherence is retained while frame-wise constraints are relaxed.
- Downstream performance improves specifically on tasks with diverse speaking rates.
Where Pith is reading between the lines
- The same CTC-Siamese pattern could be tested on other ordered data such as video frames or sensor streams where timing varies.
- It may reduce reliance on carefully tuned speed-augmentation schedules during pretraining.
- Systems using these representations might require less speaker-specific fine-tuning for rate variation.
Load-bearing premise
The monotonic alignments found by CTC will keep enough linguistic content the same across speaking styles without adding alignment mistakes that harm the learned representations.
What would settle it
A controlled test in which SiamCTC representations yield lower accuracy than strict frame-aligned Siamese baselines on a speaking-rate-varied downstream task would contradict the central claim.
Figures

read the original abstract
Self-supervised speech representation learning has made significant progress through Siamese networks, which leverage different views of the same input. However, existing methods often require frame-wise alignment between these views, overlooking the broader linguistic context invariance across different speaking styles. We introduce SiamCTC, a framework that integrates Siamese networks with Connectionist Temporal Classification (CTC) to learn speech representations without strict frame-level correspondence. By employing CTC loss to establish flexible, monotonic alignments between differing temporal realizations of the same content, SiamCTC accommodates speed perturbations and other temporal augmentations. This design relaxes frame-wise constraints while preserving temporal coherence and enhancing robustness to speaking-rate variations in downstream tasks. Our experiments demonstrate that SiamCTC leads to more adaptable speech representations, particularly at diverse speaking rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SiamCTC, a Siamese-network framework that replaces frame-wise alignment with CTC loss to establish flexible monotonic alignments between temporally augmented views of the same utterance. The central claim is that this design accommodates speed perturbations while preserving temporal coherence and yielding more robust speech representations for downstream tasks at varying speaking rates.
Significance. If the claimed alignment mechanism can be shown to avoid injecting alignment errors that degrade linguistic invariance, the approach would offer a concrete relaxation of the strict temporal correspondence assumption common in current contrastive speech SSL methods, with potential gains in robustness to rate variation.
major comments (2)
- Abstract (and entire provided text): no formulation is given for how CTC loss is computed between the two Siamese branches in the absence of external labels. It is therefore impossible to determine whether one view is treated as a pseudo-label sequence, how blank tokens are handled, or whether an auxiliary term is used to prevent collapse; without these details the central claim that the resulting alignments remain content-preserving cannot be evaluated.
- Abstract: the assertion that CTC alignments 'preserve temporal coherence' while accommodating speed perturbations is stated without any derivation, loss equation, or ablation that would demonstrate the alignments remain monotonic and linguistically faithful rather than latching onto spurious temporal patterns under realistic rate changes.
Simulated Author's Rebuttal
Thank you for the review and the constructive feedback on SiamCTC. We address each major comment below and will revise the manuscript to improve clarity and provide the requested details.
read point-by-point responses
-
Referee: Abstract (and entire provided text): no formulation is given for how CTC loss is computed between the two Siamese branches in the absence of external labels. It is therefore impossible to determine whether one view is treated as a pseudo-label sequence, how blank tokens are handled, or whether an auxiliary term is used to prevent collapse; without these details the central claim that the resulting alignments remain content-preserving cannot be evaluated.
Authors: We agree that an explicit formulation of the inter-branch CTC loss is essential for evaluating the method. In the revised manuscript we will add a dedicated subsection with the full loss equation, showing that the output sequence from one branch is used as the target for CTC alignment on the other branch (no external labels), standard blank-token handling per the CTC forward algorithm, and no auxiliary collapse-prevention term. The monotonicity of CTC is relied upon to keep alignments content-preserving. revision: yes
-
Referee: Abstract: the assertion that CTC alignments 'preserve temporal coherence' while accommodating speed perturbations is stated without any derivation, loss equation, or ablation that would demonstrate the alignments remain monotonic and linguistically faithful rather than latching onto spurious temporal patterns under realistic rate changes.
Authors: The manuscript already contains empirical results on downstream ASR performance across multiple speaking rates that support robustness. However, we acknowledge the absence of an explicit derivation or dedicated ablation on alignment fidelity. In the revision we will insert a short theoretical paragraph deriving monotonicity from the CTC dynamic-programming recursion and add an ablation that measures alignment error under controlled speed perturbations. revision: yes
Circularity Check
No circularity: design choice presented without derivation or fitted predictions
full rationale
The paper introduces SiamCTC as a framework that integrates Siamese networks with CTC loss to enable flexible monotonic alignments for speech representations under temporal augmentations. No equations, derivation steps, or quantitative predictions are shown in the abstract or description. The central claim is a methodological assertion about relaxing frame-wise constraints while preserving coherence, not a result derived from inputs by construction or self-citation. No load-bearing steps reduce to fitted parameters renamed as predictions or self-referential definitions. The derivation chain is absent, rendering circularity assessment inapplicable; the work is self-contained as an empirical design proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CTC loss produces alignments that preserve linguistic content invariance across temporal augmentations
Reference graph
Works this paper leans on
-
[1]
Introduction Self-supervised learning (SSL) for speech representation learns from unlabeled data, using the input signal itself as the super- visory signal. By avoiding manual transcriptions, SSL enables deep neural network training on large-scale raw speech corpora, providing effective pre-training and robust representations for downstream tasks such as ...
-
[2]
Speech signals inherently capture a variety of attributes, in- cluding speaker characteristics, environmental conditions, and linguistic content
and speaker verification [2]. Speech signals inherently capture a variety of attributes, in- cluding speaker characteristics, environmental conditions, and linguistic content. Our primary focus is on extracting linguis- tic context, specifically, latent phonetic properties that charac- terize linguistic information. Previous SSL approaches have employed t...
-
[3]
prediction head to learn monotonic alignments without im- posing strict frame-wise constraints, and (3) in-utterance tem- poral contrastive learning to prevent representation collapse. By explicitly modeling content invariance within utter- ances, SiamCTC captures linguistic representations more effec- tively, even with misaligned views introduced by spee...
-
[4]
Related Works 2.1. Self-Supervised Speech Representation Learning Self-supervised speech representation learning methods can be broadly classified into three categories based on their pretext task. Generative approaches (e.g., VQ-V AE [21], APC [22]) re- construct or predict speech signals, potentially preserving non- linguistic attributes such as speaker...
Pith/arXiv arXiv 2026
-
[5]
local context
SiamCTC This section introduces SiamCTC, a novel framework for learn- ing speech representations invariant to temporal variations by combining a Siamese encoder with a Connectionist Temporal Classification (CTC) [17] alignment head. Auxiliary alignment consistency and temporal contrastive losses further refine align- ment and prevent collapse. The overall...
-
[6]
clean” or “other,
Experimental Details 4.1. Datasets We use LibriSpeech [29] for both pre-training and downstream fine-tuning. LibriSpeech is a widely used corpus of approxi- mately 1,000 hours of read English audiobooks derived from LibriV ox, sampled at 16 kHz. It is partitioned into subsets des- ignated as “clean” or “other,” reflecting differences in recording quality ...
-
[7]
All models are evaluated under identical conditions using the SUPERB benchmark for fair comparison.3 4.4
variants, which are fine-tuned on the same base models as ours. All models are evaluated under identical conditions using the SUPERB benchmark for fair comparison.3 4.4. Evaluation Metrics We report Phoneme Error Rate (PER%) and Word Error Rate (WER%) on the LibriSpeechtest-cleanfor phoneme recogni- tion and ASR tasks, respectively. In addition, we conduc...
-
[8]
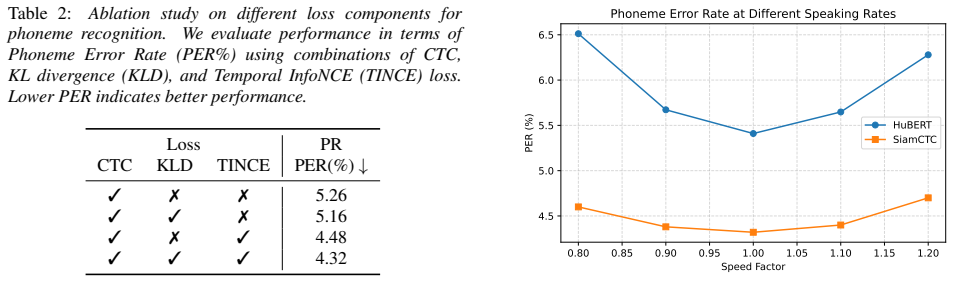
Experiment Results 5.1. Main Results Table 1 summarizes our results in phoneme recognition (PR) and automatic speech recognition (ASR) on LibriSpeech, com- 1https://huggingface.co/s3prl/converted_ ckpts/resolve/main/hubert_base_ls960.pt 2https://huggingface.co/s3prl/converted_ ckpts/resolve/main/wavlm_base.pt 3https://github.com/s3prl/s3prl Table 2:Ablati...
-
[9]
This is complemented by temporal InfoNCE (TINCE) loss and an alignment consistency loss to prevent representation collapse and refine alignment quality
Conclusion We proposed SiamCTC, a self-supervised learning framework that merges Siamese encoding with a Connectionist Tempo- ral Classification (CTC) based alignment objective as its core mechanism to handle temporal perturbations in speech. This is complemented by temporal InfoNCE (TINCE) loss and an alignment consistency loss to prevent representation ...
-
[10]
In particular, we find that using a lower temperature, which produces more peaked logits, is critical for alignment seeking
Limitation While SiamCTC has shown promising performance, we ob- serve that the downstream results can be sensitive to hyper- parameters such as augmentation strategies, negative pair sam- pling, and attention logit temperature. In particular, we find that using a lower temperature, which produces more peaked logits, is critical for alignment seeking. Fut...
-
[11]
Acknowledgements This work was partly supported by Center for Applied Research in Artificial Intelligence (CARAI) grant funded by DAPA and ADD (UD230017TD) and partly supported by Institute of Infor- mation & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No.RS- 2022-II220184, Development and Study of AI...
2022
-
[12]
Effectiveness of self-supervised pre-training for asr,
A. Baevski and A. Mohamed, “Effectiveness of self-supervised pre-training for asr,” inICASSP 2020-2020 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020, pp. 7694–7698
2020
-
[13]
Contrastive predictive coding based feature for au- tomatic speaker verification,
C.-I. Lai, “Contrastive predictive coding based feature for au- tomatic speaker verification,”arXiv preprint arXiv:1904.01575, 2019
Pith/arXiv arXiv 1904
-
[14]
Representation learning with contrastive predictive coding,
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” 2019
2019
-
[15]
wav2vec: Unsupervised pre-training for speech recognition,
S. Schneider, A. Baevski, R. Collobert, and M. Auli, “wav2vec: Unsupervised pre-training for speech recognition,” 2019
2019
-
[16]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” 2020
2020
-
[17]
Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,”IEEE/ACM Trans. Audio, Speech and Lang. Proc., vol. 29, p. 3451–3460, oct 2021
2021
-
[18]
Robust wav2vec 2.0: Analyzing domain shift in self- supervised pre-training,
W.-N. Hsu, A. Sriram, A. Baevski, T. Likhomanenko, Q. Xu, V . Pratap, J. Kahn, A. Lee, R. Collobert, G. Synnaeve, and M. Auli, “Robust wav2vec 2.0: Analyzing domain shift in self- supervised pre-training,” inInterspeech 2021, 2021, pp. 721–725
2021
-
[19]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,” in Proceedings of the 37th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol
-
[20]
1597–1607
PMLR, 13–18 Jul 2020, pp. 1597–1607
2020
-
[21]
Emerging properties in self-supervised vision transformers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bo- janowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), October 2021, pp. 9650–9660
2021
-
[22]
Bootstrap your own latent - a new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Ghesh- laghi Azar, B. Piot, k. kavukcuoglu, R. Munos, and M. Valko, “Bootstrap your own latent - a new approach to self-supervised learning,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 21 271–21 284
2020
-
[23]
Momentum con- trast for unsupervised visual representation learning,
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum con- trast for unsupervised visual representation learning,” inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), June 2020
2020
-
[24]
Exploring simple siamese representation learning,
X. Chen and K. He, “Exploring simple siamese representation learning,” inProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), June 2021, pp. 15 750–15 758
2021
-
[25]
Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clus- tering,
H.-J. Chang, A. H. Liu, and J. Glass, “Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clus- tering,” inProc. Interspeech, 2023
2023
-
[26]
R-spin: Efficient speaker and noise- invariant representation learning with acoustic pieces,
H.-J. Chang and J. Glass, “R-spin: Efficient speaker and noise- invariant representation learning with acoustic pieces,” inPro- ceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Lan- guage Technologies (V olume 1: Long Papers). Mexico City, Mexico: Association for Computational Linguistic...
2024
-
[27]
Contrastive siamese network for semi-supervised speech recog- nition,
S. Khorram, J. Kim, A. Tripathi, H. Lu, Q. Zhang, and H. Sak, “Contrastive siamese network for semi-supervised speech recog- nition,” inICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2022, pp. 7207–7211
2022
-
[28]
Di- nosr: Self-distillation and online clustering for self-supervised speech representation learning,
A. H. Liu, H.-J. Chang, M. Auli, W.-N. Hsu, and J. Glass, “Di- nosr: Self-distillation and online clustering for self-supervised speech representation learning,” inAdvances in Neural Informa- tion Processing Systems, vol. 36, 2023, pp. 58 346–58 362
2023
-
[29]
Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Con- nectionist temporal classification: labelling unsegmented se- quence data with recurrent neural networks,” inProceedings of the 23rd International Conference on Machine Learning, ser. ICML ’06. New York, NY , USA: Association for Computing Machin- ery, 2006, p. 369–376
2006
-
[30]
Wavlm: Large-scale self- supervised pre-training for full stack speech processing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, and F. Wei, “Wavlm: Large-scale self- supervised pre-training for full stack speech processing,” 2021
2021
-
[31]
Error bounds for convolutional codes and an asymp- totically optimum decoding algorithm,
A. Viterbi, “Error bounds for convolutional codes and an asymp- totically optimum decoding algorithm,”IEEE Transactions on In- formation Theory, vol. 13, no. 2, pp. 260–269, 1967
1967
-
[32]
Dynamic programming search for con- tinuous speech recognition,
H. Ney and S. Ortmanns, “Dynamic programming search for con- tinuous speech recognition,”IEEE Signal Processing Magazine, vol. 16, no. 5, pp. 64–83, 1999
1999
-
[33]
Neural dis- crete representation learning,
A. van den Oord, O. Vinyals, and k. kavukcuoglu, “Neural dis- crete representation learning,” inAdvances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[34]
Generative pre-training for speech with autoregressive predictive coding,
Y .-A. Chung and J. Glass, “Generative pre-training for speech with autoregressive predictive coding,” inICASSP, 2020
2020
-
[35]
data2vec: A general framework for self-supervised learning in speech, vision and language,
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A general framework for self-supervised learning in speech, vision and language,” inProceedings of the 39th Inter- national Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 162. PMLR, 17–23 Jul 2022, pp. 1298–1312
2022
-
[36]
Unsupervised learning of visual features by contrast- ing cluster assignments,
M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, and A. Joulin, “Unsupervised learning of visual features by contrast- ing cluster assignments,” inAdvances in Neural Information Pro- cessing Systems, vol. 33, 2020, pp. 9912–9924
2020
-
[37]
Laser: Learning by aligning self- supervised representations of speech for improving content- related tasks,
A. Meghanani and T. Hain, “Laser: Learning by aligning self- supervised representations of speech for improving content- related tasks,” inInterspeech 2024, 2024, pp. 2835–2839
2024
-
[38]
Soft-dtw: a differentiable loss func- tion for time-series,
M. Cuturi and M. Blondel, “Soft-dtw: a differentiable loss func- tion for time-series,” inProceedings of the 34th International Conference on Machine Learning - V olume 70, ser. ICML’17. JMLR.org, 2017, p. 894–903
2017
-
[39]
Towards end-to-end speech recogni- tion with recurrent neural networks,
A. Graves and N. Jaitly, “Towards end-to-end speech recogni- tion with recurrent neural networks,” inProceedings of the 31st International Conference on International Conference on Ma- chine Learning - V olume 32, ser. ICML’14. JMLR.org, 2014, p. II–1764–II–1772
2014
-
[40]
Adamer-ctc: Connectionist temporal classifi- cation with adaptive maximum entropy regularization for auto- matic speech recognition,
S. Eom, E. Yoon, H. S. Yoon, C. Kim, M. Hasegawa-Johnson, and C. D. Yoo, “Adamer-ctc: Connectionist temporal classifi- cation with adaptive maximum entropy regularization for auto- matic speech recognition,” inICASSP 2024 - 2024 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP), 2024, pp. 12 707–12 711
2024
-
[41]
Lib- rispeech: An asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An asr corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
2015
-
[42]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inInternational Conference on Learning Representations, 2019
2019
-
[43]
Analysing discrete self supervised speech representation for spoken language modeling,
A. Sicherman and Y . Adi, “Analysing discrete self supervised speech representation for spoken language modeling,” inICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, Jun. 2023, p. 1–5
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.