Generative Model Proposal based Particle Filtering for Data Assimilation
Pith reviewed 2026-07-02 16:01 UTC · model grok-4.3
The pith
Flow Proposal Particle Filters learn a conditional generative model to approximate the optimal proposal for particle propagation in data assimilation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
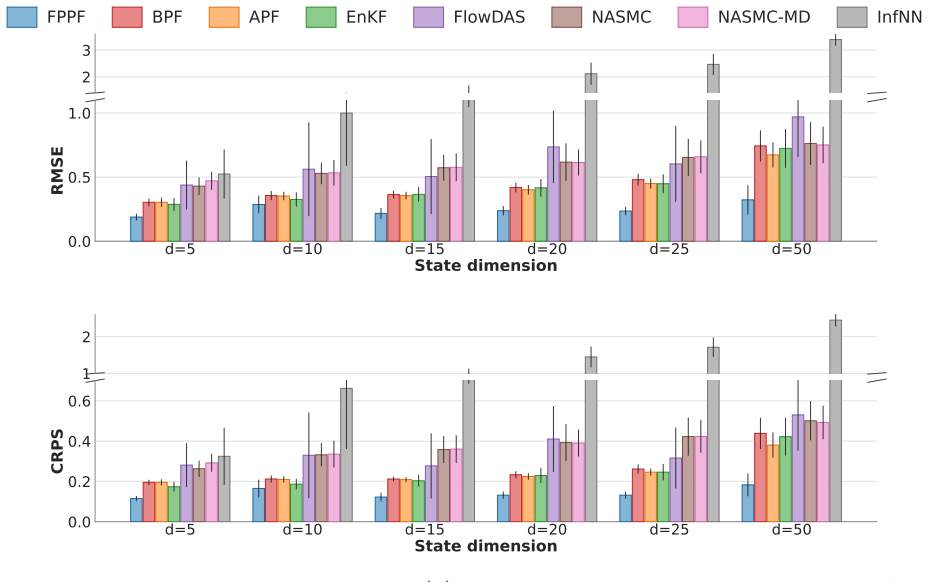
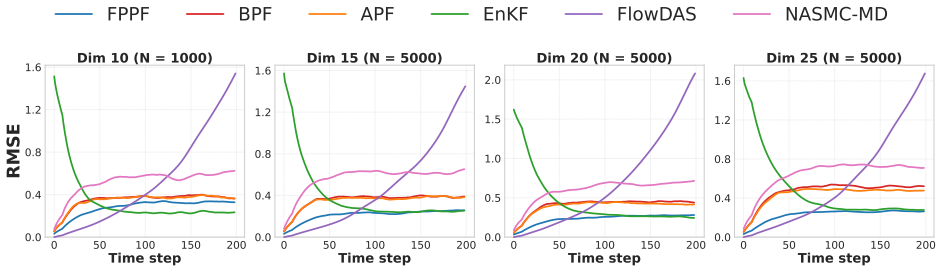
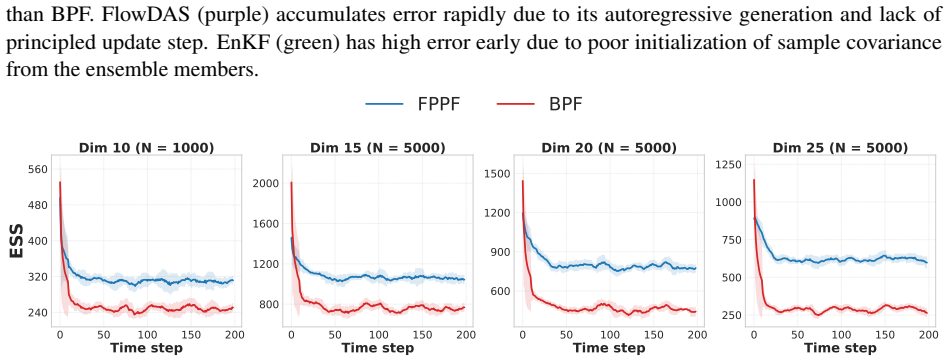
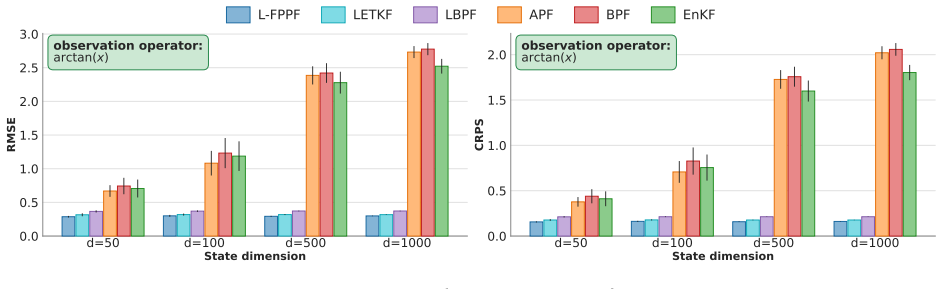
FPPF learns a conditional generative model based proposal approximating the variance-minimizing optimal proposal for particle propagation. Conditioning on observations steers particles toward high-likelihood regions before weighting, reducing weight variance and delaying degeneracy. Since our proposal admits tractable likelihood evaluation, FPPF computes accurate importance weights and retains a Bayesian update step. We further extend FPPF to high-dimensional problems through localization strategies.
What carries the argument
The conditional generative model proposal that approximates the variance-minimizing optimal proposal while admitting tractable likelihood evaluation.
If this is right
- Particles are steered toward high-likelihood regions before weighting, lowering variance.
- Accurate importance weights remain available because the proposal supports tractable likelihood evaluation.
- The Bayesian update step is retained rather than replaced by a learned approximation.
- Localization strategies address degeneracy in high-dimensional settings.
Where Pith is reading between the lines
- The method may support sequential state estimation in domains such as weather modeling where observations arrive over time and state spaces are large.
- Efficient training of the generative proposal could allow the filter to run at speeds suitable for online tracking tasks.
- If localization introduces bias in some geometries, combining it with adaptive proposal training might mitigate that effect.
Load-bearing premise
The learned conditional generative model can be trained to sufficiently approximate the optimal proposal distribution while preserving tractable likelihood evaluation.
What would settle it
A high-dimensional non-linear dynamical system experiment where FPPF exhibits higher weight variance or faster degeneracy than a standard particle filter with the same number of particles.
Figures
read the original abstract
Data assimilation models state dynamics conditioned on sequential observations, and has wide-ranging scientific applications. In the filtering setting, the goal is to model the posterior over the current state given all observations so far. Classical solutions typically make simplifying distributional or functional assumptions, e.g., linear-Gaussian systems, which can be inaccurate in many scenarios. In principle, particle filters (PFs) remove these assumptions, yet often collapse in high dimensions. Recent generative approaches learn conditional state transitions, but without principled Bayesian updates they do not recover the correct filtering posterior and can accumulate error over long horizons. In this work, we introduce Flow Proposal Particle Filters (FPPF), which learn a conditional generative model based proposal approximating the variance-minimizing optimal proposal for particle propagation. Conditioning on observations steers particles toward high-likelihood regions before weighting, reducing weight variance and delaying degeneracy. Since our proposal admits tractable likelihood evaluation, FPPF computes accurate importance weights and retains a Bayesian update step. We further extend FPPF to high-dimensional problems through localization strategies, adressing another standard PF failure mode. Extensive experiments on a variety of dynamical systems show that FPPF outperforms statistical baselines and other generative methods in non-linear, non-Gaussian, and high-dimensional regimes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Flow Proposal Particle Filters (FPPF), which train a conditional generative model (normalizing flow) on simulated triples (x_{t-1}, y_t, x_t) to serve as a proposal distribution approximating the optimal p(x_t | x_{t-1}, y_t) in particle filtering. Conditioning on observations steers particles toward high-likelihood regions to reduce weight variance and degeneracy; because the flow supplies an exact density, the importance weight p(y_t | x_t) p(x_t | x_{t-1}) / q remains a valid Bayesian correction. Localization is added for high-dimensional cases, and the abstract asserts that extensive experiments on varied dynamical systems demonstrate outperformance over statistical baselines and other generative methods in non-linear, non-Gaussian, and high-dimensional regimes.
Significance. If the empirical claims are substantiated, the work would offer a principled integration of modern generative models with classical sequential Monte Carlo methods, preserving theoretical correctness while addressing practical failure modes of particle filters.
major comments (2)
- Abstract: the assertion of outperformance on varied dynamical systems supplies no quantitative results, error bars, dataset details, or ablation studies, so the central empirical claim cannot be evaluated.
- Method description (throughout): no equations, derivations, or explicit training objective are shown that demonstrate how the learned conditional density q approximates the variance-minimizing optimal proposal or how the importance weights are formed, preventing verification that a Bayesian update is retained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify important issues with the presentation of empirical claims and methodological details. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: Abstract: the assertion of outperformance on varied dynamical systems supplies no quantitative results, error bars, dataset details, or ablation studies, so the central empirical claim cannot be evaluated.
Authors: We agree that the abstract, as currently written, states the outperformance claim at a high level without supporting numbers. The Experiments section of the manuscript contains the quantitative results, error bars, dataset descriptions, and ablations, but these are not summarized in the abstract. We will revise the abstract to include a concise statement of the main quantitative improvements (e.g., relative error reductions on the tested nonlinear systems) while respecting length constraints. revision: yes
-
Referee: Method description (throughout): no equations, derivations, or explicit training objective are shown that demonstrate how the learned conditional density q approximates the variance-minimizing optimal proposal or how the importance weights are formed, preventing verification that a Bayesian update is retained.
Authors: The current manuscript version does not contain the requested equations or derivations. We will add a new subsection that (i) states the training objective for the conditional normalizing flow (negative log-likelihood on simulated triples (x_{t-1}, y_t, x_t) to approximate p(x_t | x_{t-1}, y_t)), (ii) derives the importance weight w_t = p(y_t | x_t) p(x_t | x_{t-1}) / q(x_t | x_{t-1}, y_t), and (iii) shows that the resulting weighted particles target the correct filtering posterior. This will make the Bayesian correction explicit and verifiable. revision: yes
Circularity Check
No significant circularity
full rationale
The derivation trains a conditional generative model via maximum likelihood on triples simulated from the known transition and observation models to target the optimal proposal p(x_t | x_{t-1}, y_t). The resulting flow q supplies an exact density, allowing standard importance weights p(y_t | x_t) p(x_t | x_{t-1}) / q to remain a valid Bayesian correction. No equations reduce performance claims to quantities defined by the fit itself, no load-bearing self-citations appear, and localization is presented as a standard extension. The construction is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Ades and P. J. van Leeuwen. The equivalent-weights particle filter in a high-dimensional system. Quarterly Journal of the Royal Meteorological Society, 141(687):484–503, 2015. doi: 10.1002/qj.2370
-
[2]
X. Ai, Y . He, A. Gu, R. Salakhutdinov, J. Z. Kolter, N. M. Boffi, and M. Simchowitz. Joint distillation for fast likelihood evaluation and sampling in flow-based models. InThe Fourteenth International Con- ference on Learning Representations (ICLR), 2026. URL https://openreview.net/forum? id=8uZ5UdIul2. arXiv:2512.02636
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
B. D. O. Anderson and J. B. Moore.Optimal Filtering. Prentice-Hall, Englewood Cliffs, NJ, 1979
1979
-
[4]
J. L. Anderson and S. L. Anderson. A Monte Carlo implementation of the nonlinear filtering problem to produce ensemble assimilations and forecasts.Monthly Weather Review, 127(12):2741–2758, 1999. doi: 10.1175/1520-0493(1999)127<2741:AMCIOT>2.0.CO;2
-
[5]
DAISI: Data Assimilation with Inverse Sampling using Stochastic Interpolants
M. Andrae, E. Larsson, S. Takao, T. Landelius, and F. Lindsten. Daisi: Data assimilation with inverse sampling using stochastic interpolants. InProceedings of the 43rd International Conference on Machine Learning (ICML), 2026. URLhttps://arxiv.org/abs/2512.00252
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
M. S. Arulampalam, S. Maskell, N. Gordon, and T. Clapp. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking.IEEE Transactions on Signal Processing, 50(2):174–188,
-
[7]
doi: 10.1109/78.978374
-
[8]
F. Bao, Z. Zhang, and G. Zhang. An ensemble score filter for tracking high-dimensional nonlinear dynamical systems.Computer Methods in Applied Mechanics and Engineering, 432:117447, Dec. 2024. ISSN 0045-7825. doi: 10.1016/j.cma.2024.117447
-
[9]
Y . Bar-Shalom, X. R. Li, and T. Kirubarajan.Estimation with Applications to Tracking and Navigation: Theory, Algorithms and Software. John Wiley & Sons, New York, 2001. ISBN 9780471416555. doi: 10.1002/0471221279
-
[10]
T. Bengtsson, P. Bickel, and B. Li.Curse-of-dimensionality revisited: Collapse of the particle fil- ter in very large scale systems, page 316–334. Institute of Mathematical Statistics, 2008. ISBN 19 0940600749. doi: 10.1214/193940307000000518. URL http://dx.doi.org/10.1214/ 193940307000000518
-
[11]
C. H. Bishop, B. J. Etherton, and S. J. Majumdar. Adaptive sampling with the ensemble transform Kalman filter. Part I: Theoretical aspects.Monthly Weather Review, 129(3):420–436, 2001. doi: 10.1175/1520-0493(2001)129<0420:ASWTET>2.0.CO;2
-
[12]
M. Bocquet, J. Brajard, A. Carrassi, and L. Bertino. Bayesian inference of chaotic dynamics by merging data assimilation, machine learning and expectation-maximization.Foundations of Data Science, 2(1): 55–80, 2020. doi: 10.3934/fods.2020004
-
[13]
J. Brajard, A. Carrassi, M. Bocquet, and L. Bertino. Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: A case study with the Lorenz 96 model.Journal of Computational Science, 44:101171, 2020. doi: 10.1016/j.jocs.2020.101171
-
[14]
Branchini and V
N. Branchini and V . Elvira. Optimized auxiliary particle filters: adapting mixture proposals via convex optimization. InConference on Uncertainty in Artificial Intelligence, 2020. URL https: //api.semanticscholar.org/CorpusID:235446306
2020
-
[15]
S. Chen, Y . Jia, Q. Qu, H. Sun, and J. A. Fessler. FlowDAS: A stochastic interpolant-based framework for data assimilation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems,
-
[16]
URLhttps://openreview.net/forum?id=1nWqhiulqD
-
[17]
X. Chen and Y . Li. An overview of differentiable particle filters for data-adaptive sequential Bayesian inference.Foundations of Data Science, 2023. doi: 10.3934/fods.2023014
-
[18]
X. Chen and Y . Li. Normalizing flow-based differentiable particle filters.IEEE Transactions on Signal Processing, 2024. arXiv:2403.01499
-
[19]
Y . Chen, D. Sanz-Alonso, and R. Willett. Autodifferentiable ensemble Kalman filters.SIAM Journal on Mathematics of Data Science, 4(2):801–833, 2022. doi: 10.1137/21M1434477
-
[20]
Z. Chen. Bayesian filtering: From kalman filters to particle filters, and beyond.Statistics, 182(1):1–69,
-
[21]
doi: 10.1080/02331880309257
-
[22]
A. J. Chorin and X. Tu. Implicit sampling for particle filters.Proceedings of the National Academy of Sciences, 106(41):17249–17254, 2009. doi: 10.1073/pnas.0909196106
-
[23]
Corenflos, J
A. Corenflos, J. Thornton, G. Deligiannidis, and A. Doucet. Differentiable particle filtering via entropy- regularized optimal transport. InProceedings of the 38th International Conference on Machine Learning (ICML), volume 139 ofProceedings of Machine Learning Research, pages 2100–2111. PMLR, 2021
2021
-
[24]
Cornebise, É
J. Cornebise, É. Moulines, and J. Olsson. Adaptive methods for sequential importance sampling with application to state space models.Statistics and Computing, 18(4):461–480, 2008. doi: 10.1007/ s11222-008-9089-4
2008
-
[25]
P. Courtier, J.-N. Thépaut, and A. Hollingsworth. A strategy for operational implementation of 4D-Var, using an incremental approach.Quarterly Journal of the Royal Meteorological Society, 120(519): 1367–1387, 1994. doi: 10.1002/qj.49712051912
-
[26]
A. J. W. de Wit and C. A. van Diepen. Crop model data assimilation with the Ensemble Kalman Filter for improving regional crop yield forecasts.Agricultural and Forest Meteorology, 146(1–2):38–56,
-
[27]
doi: 10.1016/j.agrformet.2007.05.004. 20
-
[28]
D. P. Dee, S. M. Uppala, A. J. Simmons, P. Berrisford, P. Poli, S. Kobayashi, U. Andrae, M. A. Balmaseda, G. Balsamo, P. Bauer, P. Bechtold, A. C. M. Beljaars, L. van de Berg, J. Bidlot, N. Bormann, C. Delsol, R. Dragani, M. Fuentes, A. J. Geer, L. Haimberger, S. B. Healy, H. Hersbach, E. V . Hólm, L. Isaksen, P. Kållberg, M. Köhler, M. Matricardi, A. P. ...
-
[29]
F. Dellaert, D. Fox, W. Burgard, and S. Thrun. Monte carlo localization for mobile robots. In Proceedings 1999 IEEE International Conference on Robotics and Automation (Cat. No.99CH36288C), volume 2, pages 1322–1328 vol.2, 1999. doi: 10.1109/ROBOT.1999.772544
-
[30]
L. Dlamini, O. Crespo, J. van Dam, and L. Kooistra. A global systematic review of improving crop model estimations by assimilating remote sensing data: Implications for small-scale agricultural systems.Remote Sensing, 15(16), 2023. ISSN 2072-4292. doi: 10.3390/rs15164066. URL https: //www.mdpi.com/2072-4292/15/16/4066
-
[31]
Doucet and A
A. Doucet and A. M. Johansen. A tutorial on particle filtering and smoothing: Fifteen years later. In D. Crisan and B. Rozovskii, editors,The Oxford Handbook of Nonlinear Filtering, pages 656–704. Oxford University Press, Oxford, 2011
2011
-
[32]
Doucet, S
A. Doucet, S. Godsill, and C. Andrieu. On sequential Monte Carlo sampling methods for Bayesian filtering.Statistics and Computing, 10(3):197–208, 2000
2000
-
[33]
A. Doucet, N. de Freitas, and N. Gordon.Sequential Monte Carlo Methods in Practice. Springer, New York, 2001. doi: 10.1007/978-1-4757-3437-9
-
[34]
M. Drton and M. H. Maathuis. Structure learning in graphical modeling.Annual Review of Statistics and Its Application, 4(1):365–393, 2017. doi: 10.1146/annurev-statistics-060116-053803
-
[35]
G. Evensen. Sequential data assimilation with a nonlinear quasi-geostrophic model using monte carlo methods.Journal of Geophysical Research: Oceans, 99(C5):10143–10162, 1994. doi: 10.1029/ 94JC00572. URLhttps://doi.org/10.1029/94JC00572
-
[36]
A. Farchi and M. Bocquet. Review article: Comparison of local particle filters and new implementations. Nonlinear Processes in Geophysics, 25(4):765–807, 2018. doi: 10.5194/npg-25-765-2018
-
[37]
One Step Diffusion via Shortcut Models
K. Frans, D. Hafner, S. Levine, and P. Abbeel. One step diffusion via shortcut models. InInternational Conference on Learning Representations (ICLR), 2025. arXiv:2410.12557
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
G. Gaspari and S. E. Cohn. Construction of correlation functions in two and three dimensions.Quarterly Journal of the Royal Meteorological Society, 125(554):723–757, 1999. doi: 10.1002/qj.49712555417
-
[39]
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He. Mean flows for one-step generative modeling. In Advances in Neural Information Processing Systems, volume 38, 2025. arXiv:2505.13447
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
N. Gordon, D. Salmond, and A. Smith. Novel approach to nonlinear/non-gaussian bayesian state estimation.IEE Proceedings F (Radar and Signal Processing), 140:107–113, 1993. doi: 10.1049/ ip-f-2.1993.0015. URL https://digital-library.theiet.org/doi/abs/10.1049/ ip-f-2.1993.0015
-
[41]
G. A. Gottwald, S. Liu, Y . Marzouk, S. Reich, and X. T. Tong. Localized diffusion models.arXiv preprint arXiv:2505.04417, 2025. doi: 10.48550/arXiv.2505.04417. 21
-
[42]
S. S. Gu, Z. Ghahramani, and R. E. Turner. Neural adaptive sequential Monte Carlo. InAdvances in Neural Information Processing Systems, volume 28, 2015
2015
-
[43]
H. Hersbach, B. Bell, P. Berrisford, S. Hirahara, A. Horányi, J. Muñoz-Sabater, J. Nicolas, C. Peubey, R. Radu, D. Schepers, A. Simmons, C. Soci, S. Abdalla, X. Abellan, G. Balsamo, P. Bechtold, G. Biavati, J. Bidlot, M. Bonavita, G. De Chiara, P. Dahlgren, D. Dee, M. Diamantakis, R. Dragani, J. Flemming, R. Forbes, M. Fuentes, A. Geer, L. Haimberger, S. ...
-
[44]
Ho and T
J. Ho and T. Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021. URL https://openreview.net/ forum?id=qw8AKxfYbI
2021
-
[45]
P. L. Houtekamer and H. L. Mitchell. A sequential ensemble kalman filter for atmospheric data assimilation.Monthly Weather Review, 129(1):123 – 137, 2001. doi: 10.1175/1520-0493(2001) 129<0123:ASEKFF>2.0.CO;2. URL https://journals.ametsoc.org/view/journals/ mwre/129/1/1520-0493_2001_129_0123_asekff_2.0.co_2.xml
-
[46]
P. L. Houtekamer, X. Deng, H. L. Mitchell, S.-J. Baek, and N. Gagnon. Higher resolution in an operational ensemble kalman filter.Monthly Weather Review, 142(3):1143 – 1162, 2014. doi: 10.1175/ MWR-D-13-00138.1. URL https://journals.ametsoc.org/view/journals/mwre/ 142/3/mwr-d-13-00138.1.xml
2014
-
[47]
P. L. Houtekamer, X. Deng, H. L. Mitchell, S.-J. Baek, and N. Gagnon. Higher resolution in an operational ensemble Kalman filter.Monthly Weather Review, 142:1143–1162, 2014
2014
-
[48]
Huang, L
L. Huang, L. Gianinazzi, Y . Yu, P. D. Dueben, and T. Hoefler. DiffDA: a diffusion model for weather- scale data assimilation. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=vhMq3eAB34
2024
-
[49]
B. R. Hunt, E. J. Kostelich, and I. Szunyogh. Efficient data assimilation for spatiotemporal chaos: A local ensemble transform Kalman filter.Physica D: Nonlinear Phenomena, 230(1–2):112–126, 2007. doi: 10.1016/j.physd.2006.11.008
-
[50]
M. F. Hutchinson. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines.Communications in Statistics - Simulation and Computation, 19(2):433–450, 1990. doi: 10.1080/03610919008812866
-
[51]
A. H. Jazwinski.Stochastic Processes and Filtering Theory, volume 64 ofMathematics in Science and Engineering. Academic Press, New York, 1970
1970
-
[52]
Jonschkowski, D
R. Jonschkowski, D. Rastogi, and O. Brock. Differentiable particle filters: End-to-end learning with algorithmic priors. InProceedings of Robotics: Science and Systems (RSS), Pittsburgh, Pennsylvania,
-
[53]
doi: 10.15607/RSS.2018.XIV .001
-
[54]
S. J. Julier and J. K. Uhlmann. New extension of the Kalman filter to nonlinear systems. InSignal Processing, Sensor Fusion, and Target Recognition VI, volume 3068 ofProc. SPIE, pages 182–193,
-
[55]
doi: 10.1117/12.280797
-
[56]
R. E. Kalman. A new approach to linear filtering and prediction problems.Journal of Basic Engineering, 82(1):35–45, 1960. doi: 10.1115/1.3662552. 22
-
[57]
Karkus, D
P. Karkus, D. Hsu, and W. S. Lee. Particle filter networks with application to visual localization. In Proceedings of the 2nd Conference on Robot Learning (CoRL), volume 87 ofProceedings of Machine Learning Research, pages 169–178. PMLR, 2018
2018
-
[58]
Y . Kuramoto. Diffusion-induced chaos in reaction systems.Progress of Theoretical Physics Supplement, 64:346–367, 1978. doi: 10.1143/PTPS.64.346
-
[59]
S. L. Lauritzen.Graphical Models. Number 17 in Oxford Statistical Science Series. Clarendon Press, Oxford, 1996
1996
-
[60]
T. A. Le, M. Igl, T. Rainforth, T. Jin, and F. Wood. Auto-encoding sequential Monte Carlo. In International Conference on Learning Representations, 2018. URL https://openreview.net/ forum?id=BJ8c3f-0b
2018
-
[61]
Lipman, R
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[62]
Y . Lipman, M. Havasi, P. Holderrieth, N. Shaul, M. Le, B. Karrer, R. T. Q. Chen, D. Lopez-Paz, H. Ben-Hamu, and I. Gat. Flow matching guide and code, 2024. URL https://arxiv.org/abs/ 2412.06264
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
J. S. Liu and R. Chen. Sequential Monte Carlo methods for dynamic systems.Journal of the American Statistical Association, 93(443):1032–1044, 1998. doi: 10.1080/01621459.1998.10473765
-
[64]
X. Liu, C. Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=XVjTT1nw5z
2023
-
[65]
A. C. Lorenc. Analysis methods for numerical weather prediction.Quarterly Journal of the Royal Meteorological Society, 112(474):1177–1194, 1986. doi: 10.1002/qj.49711247414
-
[66]
A. C. Lorenc. Analysis methods for numerical weather prediction.Quarterly Journal of the Royal Meteorological Society, 112(474):1177–1194, 1986
1986
-
[69]
E. N. Lorenz. Deterministic nonperiodic flow.Journal of the Atmospheric Sciences, 20(2):130–141,
-
[70]
doi: 10.1175/1520-0469(1963)020<0130:DNF>2.0.CO;2
-
[71]
E. N. Lorenz. Predictability: A problem partly solved. InProceedings of Seminar on Predictability, pages 1–18, Reading, UK, 1995. ECMWF
1995
-
[72]
E. N. Lorenz. Predictability: A problem partly solved. InProc. Seminar on Predictability, volume 1, pages 1–18, Reading, UK, 1996. ECMWF
1996
-
[73]
C. J. Maddison, D. Lawson, G. Tucker, N. Heess, M. Norouzi, A. Mnih, A. Doucet, and Y . W. Teh. Filtering variational objectives. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[74]
J. E. Matheson and R. L. Winkler. Scoring rules for continuous probability distributions.Management Science, 22(10):1087–1096, 1976. doi: 10.1287/mnsc.22.10.1087. 23
-
[75]
M. Morzfeld, X. Tu, E. Atkins, and A. J. Chorin. A random map implementation of implicit filters. Journal of Computational Physics, 231(4):2049–2066, 2012. doi: 10.1016/j.jcp.2011.11.022
-
[76]
C. A. Naesseth, S. W. Linderman, R. Ranganath, and D. M. Blei. Variational sequential Monte Carlo. InProceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), volume 84 ofProceedings of Machine Learning Research, pages 968–977. PMLR, 2018
2018
-
[77]
Paige and F
B. Paige and F. Wood. Inference networks for sequential Monte Carlo in graphical models. In Proceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 3040–3049. PMLR, 2016
2016
-
[78]
S. G. Penny and T. Miyoshi. A local particle filter for high-dimensional geophysical systems.Nonlinear Processes in Geophysics, 23(6):391–405, 2016. doi: 10.5194/npg-23-391-2016
-
[79]
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer.Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. doi: 10.1609/aaai.v32i1.11671. URL https://ojs.aaai.org/index.php/AAAI/ article/view/11671
-
[80]
M. K. Pitt and N. Shephard. Filtering via simulation: Auxiliary particle filters.Journal of the American Statistical Association, 94(446):590–599, 1999. doi: 10.1080/01621459.1999.10474153
-
[81]
J. Poterjoy. A localized particle filter for high-dimensional nonlinear systems.Monthly Weather Review, 144(1):59–76, 2016. doi: 10.1175/MWR-D-15-0163.1
-
[82]
F. Rabier, H. Järvinen, E. Klinker, J.-F. Mahfouf, and A. Simmons. The ECMWF operational im- plementation of four-dimensional variational assimilation. I: Experimental results with simplified physics.Quarterly Journal of the Royal Meteorological Society, 126(564):1143–1170, 2000. doi: 10.1256/smsqj.56414
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.