ARAPDiffusion: ARAP Regularization for Diffusion-Based Deformable Shape Space Learning
Pith reviewed 2026-06-27 22:52 UTC · model grok-4.3
The pith
ARAP regularization in latent diffusion reduces the need for large 3D datasets when learning deformable shape spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
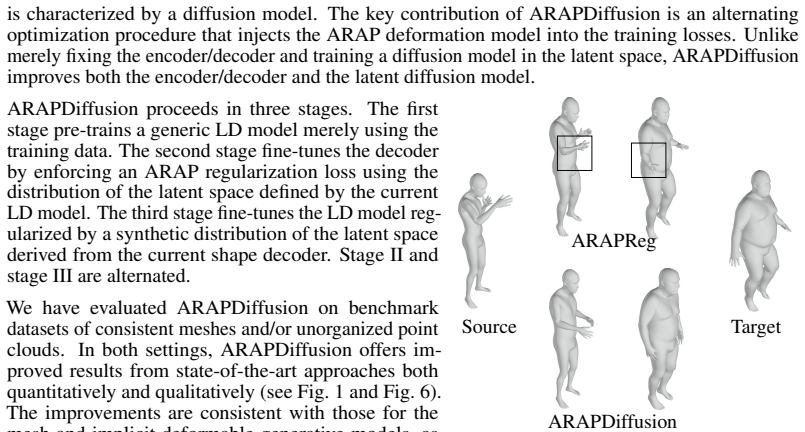
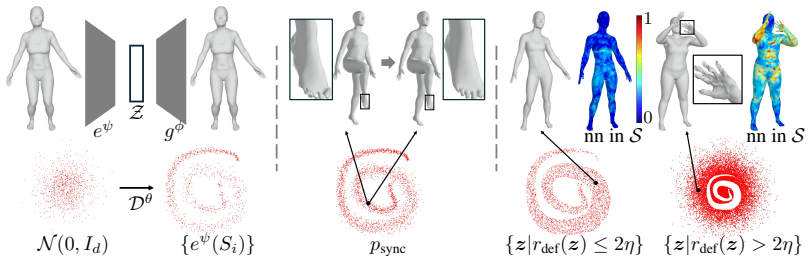
ARAPDiffusion injects the as-rigid-as-possible deformation model as regularization losses into latent diffusion, with an alternating training procedure that uses the synthetic distribution from the diffusion model to improve the shape encoder and decoder and then uses the improved decoder to refine the diffusion model, thereby learning continuous shape spaces from limited 3D data while supporting implicit decoding of unorganized point clouds.
What carries the argument
The ARAP deformation model used as regularization losses inside the latent diffusion objective, combined with the alternating optimization loop between the diffusion model and the shape encoder/decoder.
If this is right
- The method generates shapes from limited training collections where standard latent diffusion fails due to data scarcity.
- The implicit decoder allows direct application to unorganized point clouds without explicit surface representations.
- Both the encoder/decoder and the diffusion model improve through the mutual regularization loop.
- Unconditional and conditional generation tasks benefit from the ARAP constraint in the learned shape space.
Where Pith is reading between the lines
- The alternating regularization pattern could be tested with other local deformation energies beyond ARAP to handle different classes of shapes.
- The representation-free diffusion step might combine with other implicit decoders for tasks such as shape interpolation under physical constraints.
- If the convergence assumption holds, the same loop could be applied to conditional generation from partial observations or images.
Load-bearing premise
The alternating training between the latent diffusion model and the shape decoder will converge to mutual improvement rather than a degenerate fixed point.
What would settle it
Run the alternating procedure on a small collection of deformable shapes and check whether generated shapes violate ARAP energy bounds more than a non-regularized latent diffusion baseline trained on the same data.
Figures






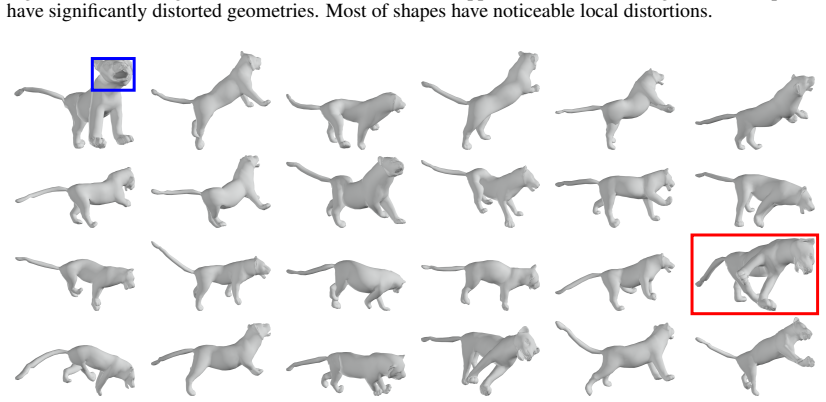
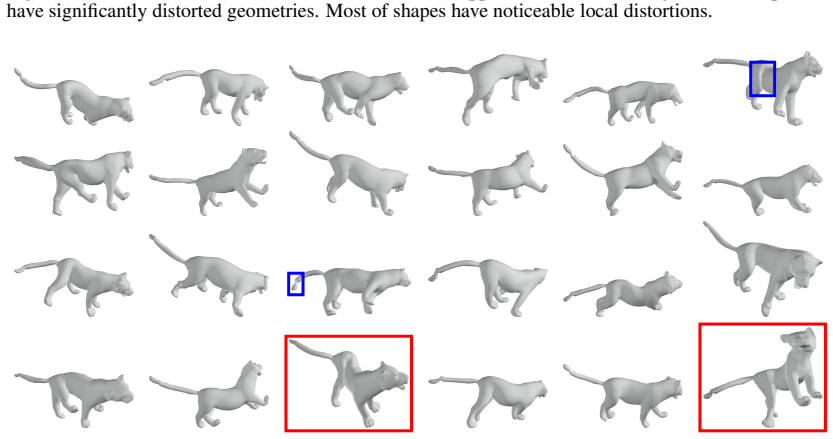
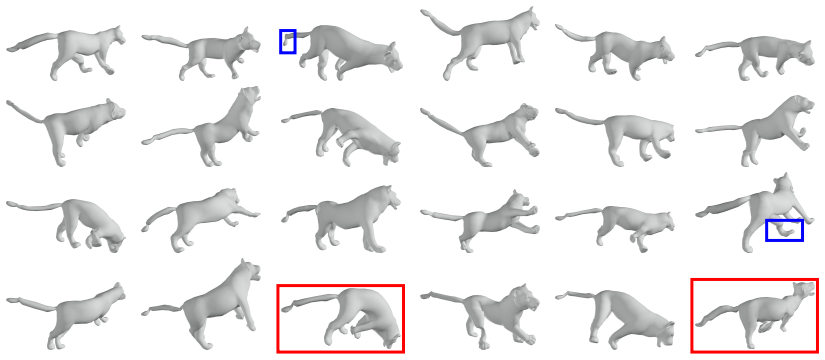
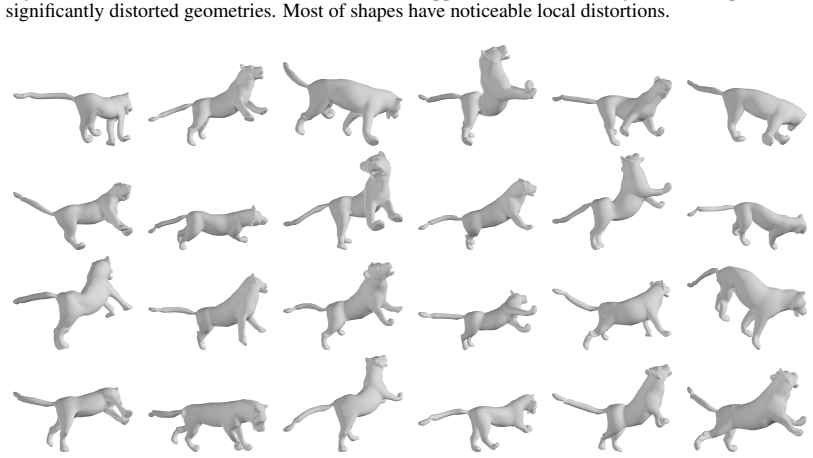
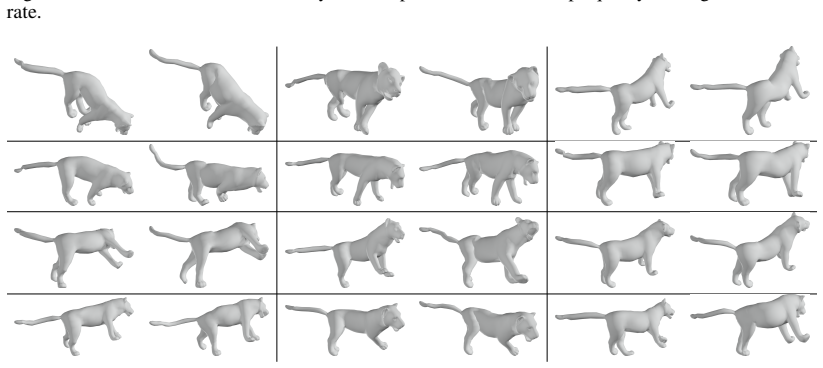


read the original abstract
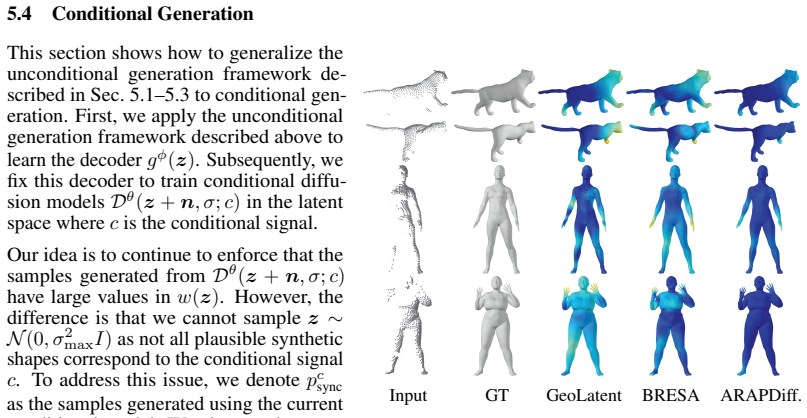
This paper introduces ARAPDiffusion, a latent diffusion model to learn the underlying continuous shape space of a deformation shape collection. The key innovation is in injecting the as-rigid-as-possible (ARAP) deformation model as regularization losses into latent diffusion (LD), releasing the requirement of having abundant 3D training data for learning generative models. In contrast to the standard LD, we show how the ARAP model can be used to improve both the encoder/decoder and the LD model. The training procedure alternates between using the synthetic distribution defined by the LD model to develop a regularization loss that enhances the shape encoder/decoder and using the shape decoder to develop a regularization loss to improve the LD model. We also show the benefit of the LD paradigm in combining a representation-free LD process and an implicit shape decoder that is applicable to unorganized point clouds. The experimental results of unconditional and conditional shape generation demonstrate the advantages of ARAPDiffusion over baseline approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ARAPDiffusion, a latent diffusion model for learning the continuous shape space of deformable shape collections. The core idea is to inject the as-rigid-as-possible (ARAP) deformation model as regularization losses into the latent diffusion process, thereby reducing the need for abundant 3D training data. Training alternates between (i) using synthetic samples from the latent diffusion model to regularize the shape encoder/decoder via ARAP losses and (ii) using the decoder to provide ARAP-based regularization for the diffusion model. The approach combines a representation-free diffusion process with an implicit decoder applicable to unorganized point clouds and reports advantages for unconditional and conditional shape generation over baselines.
Significance. If the alternating ARAP-regularized procedure can be shown to produce stable, non-degenerate improvement rather than collapse, the method would offer a practical route to generative shape modeling under limited 3D data by leveraging a classical geometric prior; this would be of clear interest to the computer-graphics and 3D-vision communities.
major comments (1)
- [Abstract] Abstract (training procedure paragraph): the central claim that ARAP regularization 'releases the requirement of having abundant 3D training data' rests on the alternating loop between the latent diffusion synthetic distribution and the ARAP-regularized decoder producing joint improvement. No convergence analysis, damping mechanism, or fixed-point stability argument is supplied; the procedure is formally analogous to an unregularized alternating game and could converge to a trivial solution (e.g., decoder outputs only near-rigid shapes while the diffusion model matches that narrow distribution) while still satisfying the per-step losses.
minor comments (1)
- [Abstract] Abstract: the phrase 'representation-free LD process' is used without definition; it is unclear whether this refers to the latent space, the diffusion process itself, or the decoder architecture.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the alternating training procedure. We address the concern regarding potential instability or collapse below.
read point-by-point responses
-
Referee: [Abstract] Abstract (training procedure paragraph): the central claim that ARAP regularization 'releases the requirement of having abundant 3D training data' rests on the alternating loop between the latent diffusion synthetic distribution and the ARAP-regularized decoder producing joint improvement. No convergence analysis, damping mechanism, or fixed-point stability argument is supplied; the procedure is formally analogous to an unregularized alternating game and could converge to a trivial solution (e.g., decoder outputs only near-rigid shapes while the diffusion model matches that narrow distribution) while still satisfying the per-step losses.
Authors: We acknowledge that the manuscript does not include a formal convergence analysis, damping mechanism, or fixed-point stability argument for the alternating optimization. The referee is correct that such an analysis is absent. However, the procedure is not an unregularized alternating game: both the encoder/decoder and diffusion model are optimized with a combination of reconstruction losses on the limited real data, ARAP regularization terms that explicitly penalize non-rigid deviations while preserving local rigidity, and the latent diffusion objective that matches the empirical data distribution. This combination discourages collapse to a narrow near-rigid distribution, as the real training shapes contain non-rigid deformations. Our experiments (Sections 4.1–4.3) demonstrate that generated shapes maintain diversity and outperform baselines on metrics such as coverage and MMD without evident degeneracy. We will revise the paper to add an explicit discussion of these empirical safeguards and the role of the combined losses in preventing trivial solutions. revision: partial
Circularity Check
No significant circularity; alternating ARAP regularization is externally grounded
full rationale
The provided abstract and description present ARAP as an external deformation prior injected via alternating losses between LD synthetic samples and the shape decoder. No equations, fitted parameters renamed as predictions, or self-citation chains are visible that would reduce the central claim (ARAP releases need for abundant 3D data) to the inputs by construction. The procedure is described as a methodological choice rather than a self-definitional loop, and no uniqueness theorems or ansatzes from prior author work are invoked. The derivation remains self-contained against standard LD and ARAP benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ARAP deformation energy supplies a useful inductive bias for regularizing both the shape autoencoder and the latent diffusion process on deformable collections.
Reference graph
Works this paper leans on
-
[1]
K. S. Arun, T. S. Huang, and S. D. Blostein. Least-squares fitting of two 3-d point sets.IEEE Transactions on Pattern Analysis and Machine Intelligence, 9(1):67–71, 1987
1987
-
[2]
Atzmon, J
M. Atzmon, J. Huang, F. Williams, and O. Litany. Approximately piecewise E(3) equivariant point networks. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[3]
Atzmon and Y
M. Atzmon and Y . Lipman. SALD: sign agnostic learning with derivatives. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[4]
Atzmon, K
M. Atzmon, K. Nagano, S. Fidler, S. Khamis, and Y . Lipman. Frame averaging for equivariant shape space learning. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 621–631. IEEE, 2022
2022
-
[5]
Atzmon, K
M. Atzmon, K. Nagano, S. Fidler, S. Khamis, and Y . Lipman. Frame averaging for equivariant shape space learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 631–641, June 2022
2022
- [6]
-
[7]
Bouritsas, S
G. Bouritsas, S. Bokhnyak, S. Ploumpis, S. Zafeiriou, and M. M. Bronstein. Neural 3d morphable models: Spiral convolutional networks for 3d shape representation learning and generation. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 7212–7221. IEEE, 2019
2019
-
[8]
Cheng, H.-Y
Y .-C. Cheng, H.-Y . Lee, S. Tulyakov, A. G. Schwing, and L.-Y . Gui. Sdfusion: Multimodal 3d shape completion, reconstruction, and generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4456–4465, 2023
2023
-
[9]
G. Chou, Y . Bahat, and F. Heide. Diffusion-sdf: Conditional generative modeling of signed distance functions. InProceedings of the IEEE International Conference on Computer Vision (ICCV), 2023
2023
-
[10]
Dummer, N
S. Dummer, N. Strisciuglio, and C. Brune. Rda-inr: Riemannian diffeomorphic autoencoding via implicit neural representations.SIAM Journal on Imaging Sciences, 17(4):2302–2330, 2024
2024
-
[11]
Eisenberger, D
M. Eisenberger, D. Novotný, G. Kerchenbaum, P. Labatut, N. Neverova, D. Cremers, and A. Vedaldi. Neuromorph: Unsupervised shape interpolation and correspondence in one go. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 7473–7483. Computer Vision Foundation / IEEE, 2021
2021
-
[12]
S. Foti, B. Koo, D. Stoyanov, and M. J. Clarkson. 3d generative model latent disentanglement via local eigenprojection.Comput. Graph. Forum, 42(6), 2023
2023
-
[13]
Hartman, N
E. Hartman, N. Charon, and M. Bauer. Self supervised networks for learning latent space representations of human body scans and motions, 2024
2024
-
[14]
Hartman, E
E. Hartman, E. Pierson, M. Bauer, N. Charon, and M. Daoudi. Bare-esa: A riemannian framework for unregistered human body shapes. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 14135–14145. IEEE, 2023
2023
-
[15]
Hartman, E
E. Hartman, E. Pierson, M. Bauer, M. Daoudi, and N. Charon. Basis restricted elastic shape analysis on the space of unregistered surfaces.Int. J. Comput. Vis., 133(4):1999–2024, 2025. 10
1999
-
[16]
Hartman, Y
E. Hartman, Y . Sukurdeep, E. Klassen, N. Charon, and M. Bauer. Elastic shape analysis of surfaces with second-order sobolev metrics: A comprehensive numerical framework.Int. J. Comput. Vis., 131(5):1183–1209, 2023
2023
-
[17]
H.-I. Ho, C. Guo, P.-C. Wu, I. Shugurov, C. Tang, A. Mittal, S. An, M. Kaufmann, and L. Zhang. Phd: Personalized 3d human body fitting with point diffusion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7526–7537, 2025
2025
-
[18]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020
2020
-
[19]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022
2022
-
[20]
Huang and D
J. Huang and D. Mumford. Statistics of natural images and models. In1999 Conference on Computer Vision and Pattern Recognition (CVPR ’99), 23-25 June 1999, Ft. Collins, CO, USA, pages 1541–1547. IEEE Computer Society, 1999
1999
-
[21]
Huang, X
Q. Huang, X. Huang, B. Sun, Z. Zhang, J. Jiang, and C. Bajaj. Arapreg: An as-rigid-as possible regularization loss for learning deformable shape generators. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5815–5825, October 2021
2021
-
[22]
Karras, M
T. Karras, M. Aittala, T. Aila, and S. Laine. Elucidating the design space of diffusion-based generative models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28...
2022
-
[23]
M. Kass, A. Witkin, and D. Terzopoulos. Snakes: Active contour models.International Journal of Computer Vision, 1(4):321–331, 1988
1988
-
[24]
M. Kass, A. P. Witkin, and D. Terzopoulos. Snakes: Active contour models.Int. J. Comput. Vis., 1(4):321–331, 1988
1988
-
[25]
Kilian, N
M. Kilian, N. J. Mitra, and H. Pottmann. Geometric modeling in shape space.ACM Trans. Graph., 26(3):64–es, July 2007
2007
-
[26]
Klassen, A
E. Klassen, A. Srivastava, W. Mio, and S. H. Joshi. Analysis of planar shapes using geodesic paths on shape spaces.IEEE Trans. Pattern Anal. Mach. Intell., 26(3):372–383, 2004
2004
-
[27]
Z. Lai, Y . Zhao, H. Liu, Z. Zhao, Q. Lin, H. Shi, X. Yang, M. Yang, S. Yang, Y . Feng, S. Zhang, X. Huang, D. Luo, F. Yang, F. Yang, L. Wang, S. Liu, Y . Tang, Y . Cai, Z. He, T. Liu, Y . Liu, J. Jiang, Linus, J. Huang, and C. Guo. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details.CoRR, abs/2506.16504, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[29]
Loper, N
M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black. SMPL: A skinned multi-person linear model.ACM Transactions on Graphics, 34(6), 2015
2015
-
[30]
J. Lu, J. Lin, H. Dou, A. Zeng, Y . Deng, X. Liu, Z. Cai, L. Yang, Y . Zhang, H. Wang, et al. Dposer-x: Diffusion model as robust 3d whole-body human pose prior. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9988–9997, 2025
2025
-
[31]
Maesumi, P
A. Maesumi, P. Guerrero, N. Aigerman, V . Kim, M. Fisher, S. Chaudhuri, and D. Ritchie. Explorable mesh deformation subspaces from unstructured 3d generative models. InSIGGRAPH Asia 2023 Conference Papers, SA ’23, New York, NY , USA, 2023. Association for Computing Machinery
2023
-
[32]
P. W. Michor and D. B. Mumford. Riemannian geometries on spaces of plane curves.Journal of the European Mathematical Society, 8(1):1–48, 2006. 11
2006
-
[33]
Muralikrishnan, S
S. Muralikrishnan, S. Chaudhuri, N. Aigerman, V . G. Kim, M. Fisher, and N. J. Mitra. GLASS: geometric latent augmentation for shape spaces. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 470–479. IEEE, 2022
2022
-
[34]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: deep hierarchical feature learning on point sets in a metric space. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 5105–5114, Red Hook, NY , USA, 2017. Curran Associates Inc
2017
-
[35]
Ranjan, T
A. Ranjan, T. Bolkart, S. Sanyal, and M. J. Black. Generating 3d faces using convolutional mesh autoencoders. In V . Ferrari, M. Hebert, C. Sminchisescu, and Y . Weiss, editors,Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part III, volume 11207 ofLecture Notes in Computer Science, pages 725–74...
2018
-
[36]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674– 10685. IEEE, 2022
2022
-
[37]
Song and S
Y . Song and S. Ermon. Generative modeling by estimating gradients of the data distribution. In H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver,...
2019
-
[38]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based gen- erative modeling through stochastic differential equations. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[39]
Srivastava, E
A. Srivastava, E. Klassen, S. H. Joshi, and I. H. Jermyn. Shape analysis of elastic curves in euclidean spaces.IEEE Trans. Pattern Anal. Mach. Intell., 33(7):1415–1428, 2011
2011
-
[40]
Stathopoulos, L
A. Stathopoulos, L. Han, and D. N. Metaxas. Score-guided diffusion for 3d human recovery. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 906–915. IEEE, 2024
2024
-
[41]
Q. Tan, L. Gao, Y .-K. Lai, and S. Xia. Variational autoencoders for deforming 3d mesh models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5841–5850, June 2018
2018
-
[42]
Tevet, S
G. Tevet, S. Raab, B. Gordon, Y . Shafir, D. Cohen-Or, and A. H. Bermano. Human motion diffusion model. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023
2023
-
[43]
Vahdat, K
A. Vahdat, K. Kreis, and J. Kautz. Score-based generative modeling in latent space. In M. Ranzato, A. Beygelzimer, Y . N. Dauphin, P. Liang, and J. W. Vaughan, editors,Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pages 11287–11302, 2021
2021
-
[44]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6000–6010, Red Hook, NY , USA,
-
[45]
Curran Associates Inc
-
[46]
J. Wu, C. Zhang, T. Xue, B. Freeman, and J. Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In D. D. Lee, M. Sugiyama, U. von Luxburg, I. Guyon, and R. Garnett, editors,Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-...
2016
-
[47]
Xiang, Z
J. Xiang, Z. Lv, S. Xu, Y . Deng, R. Wang, B. Zhang, D. Chen, X. Tong, and J. Yang. Structured 3d latents for scalable and versatile 3d generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 21469–21480. Computer Vision Foundation / IEEE, 2025
2025
-
[48]
Xiang, Z
J. Xiang, Z. Lv, S. Xu, Y . Deng, R. Wang, B. Zhang, D. Chen, X. Tong, and J. Yang. Structured 3d latents for scalable and versatile 3d generation. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 21469–21480, June 2025
2025
-
[49]
H. Yang, X. Huang, B. Sun, C. L. Bajaj, and Q. Huang. Gencorres: Consistent shape matching via coupled implicit-explicit shape generative models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[50]
H. Yang, B. Sun, L. Chen, A. Pavel, and Q. Huang. Geolatent: A geometric approach to latent space design for deformable shape generators.ACM Trans. Graph., 42(6), Dec. 2023
2023
-
[51]
L. Yang, Z. Zhang, Y . Song, S. Hong, R. Xu, Y . Zhao, W. Zhang, B. Cui, and M.-H. Yang. Diffusion models: A comprehensive survey of methods and applications.ACM Comput. Surv., 56(4), Nov. 2023
2023
- [52]
-
[53]
Zhang, J
B. Zhang, J. Tang, M. Nießner, and P. Wonka. 3dshape2vecset: A 3d shape representation for neural fields and generative diffusion models.ACM Trans. Graph., 42(4), July 2023
2023
-
[54]
Zhang, B
S. Zhang, B. L. Bhatnagar, Y . Xu, A. Winkler, P. Kadlecek, S. Tang, and F. Bogo. Rohm: Robust human motion reconstruction via diffusion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 14606–14617. IEEE, 2024
2024
-
[55]
K. Zhou, B. L. Bhatnagar, and G. Pons-Moll. Unsupervised shape and pose disentanglement for 3d meshes. In A. Vedaldi, H. Bischof, T. Brox, and J.-M. Frahm, editors,ECCV (22), volume 12367 ofLecture Notes in Computer Science, pages 341–357. Springer, 2020
2020
-
[56]
Y . Zhou, C. Wu, Z. Li, C. Cao, Y . Ye, J. M. Saragih, H. Li, and Y . Sheikh. Fully convolutional mesh autoencoder using efficient spatially varying kernels. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, editors,Advances in Neural Information Processing Sys- tems 33: Annual Conference on Neural Information Processing Systems 2020, NeurI...
2020
-
[57]
quality filter
S. Zuffi, A. Kanazawa, D. Jacobs, and M. J. Black. 3D menagerie: Modeling the 3D shape and pose of animals. InIEEE Conf. on Computer Vision and Pattern Recognition (CVPR), July 2017. 13 A Normalized ARAP Reg Our goal is to compute the derivative of rθ(z) =Tr Eθ(z)− 1 2 H θ(z)E θ(z)− 1 2 =Tr H θ(z)E θ(z)−1 where Eθ(z) =J θ(z) T J θ(z), H θ(z) =J θ(z) T H θ...
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.