Neuron ranking -- an informed way to condense convolutional neural networks architecture
Pith reviewed 2026-05-25 09:56 UTC · model grok-4.3
The pith
Two unrelated methods for ranking CNN filters by importance produce nearly identical results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
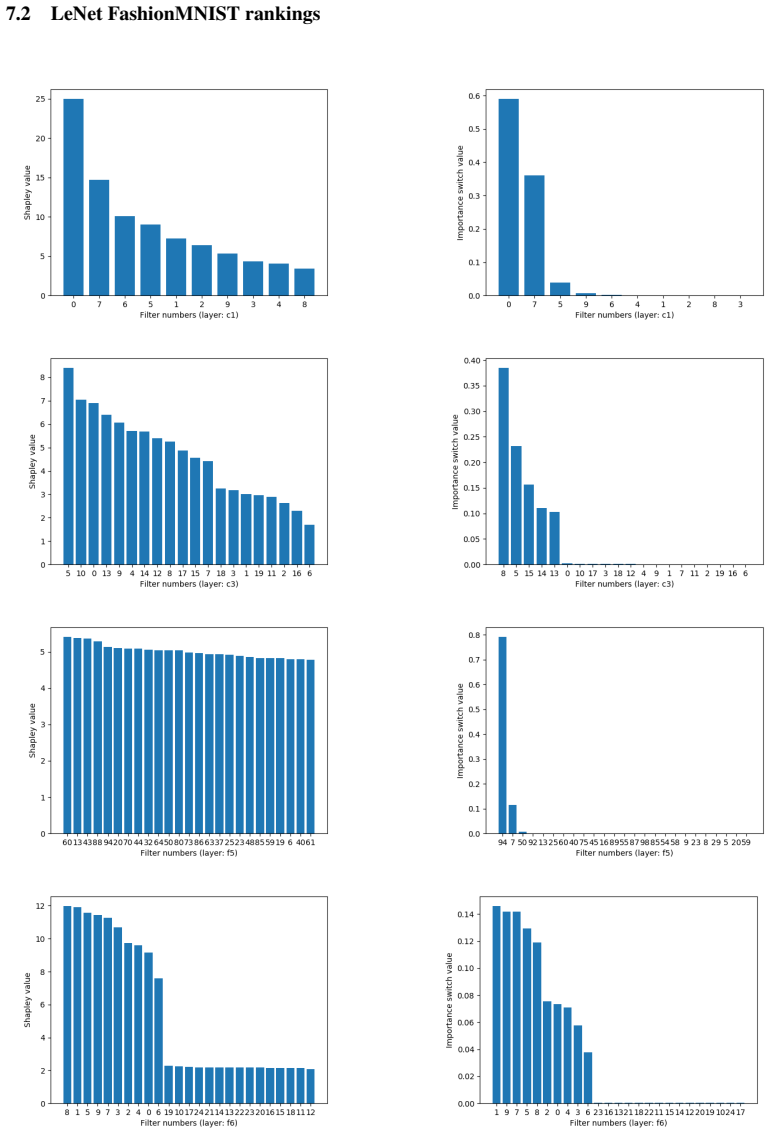
Filters in a trained convolutional network possess stable, task-specific importance that can be recovered either by computing each filter's Shapley value (its marginal contribution averaged over all coalitions) or by fitting a variational importance switch that learns a probability of necessity for each filter; the two procedures yield closely matching orderings on real architectures.
What carries the argument
Filter importance ranking obtained by Shapley-value marginal contributions or by variational importance-switch probabilities.
If this is right
- Low-ranked filters can be removed to produce a smaller network whose accuracy remains close to the original.
- The same ranks supply an explicit ordering for deciding which learned features matter most for the output.
- The procedure requires no additional training after the network has converged.
- Because the two independent calculations converge, the resulting ranking is unlikely to be an artifact of a single modeling choice.
Where Pith is reading between the lines
- The same ranking idea could be tested on architectures other than plain CNNs, such as residual or attention-based networks, to see whether filter importance remains stable across design families.
- If the ranks are used for interpretability, one could check whether high-ranked filters align with human-labeled concepts on the input images.
- The agreement between game-theoretic and variational methods suggests a deeper invariance in how importance is distributed; this invariance might be exploited to derive a single closed-form importance score that avoids both Shapley enumeration and variational optimization.
Load-bearing premise
That agreement between the two ranking procedures means both are measuring each filter's actual causal contribution rather than merely sharing a similar bias.
What would settle it
Prune the lowest-ranked filters according to either method and compare final accuracy against an equal number of randomly chosen filters; if the importance-based pruning does not retain higher accuracy, the claim that the ranks reflect true contribution is falsified.
Figures


read the original abstract
Convolutional neural networks (CNNs) in recent years have made a dramatic impact in science, technology and industry, yet the theoretical mechanism of CNN architecture design remains surprisingly vague. The CNN neurons, including its distinctive element, convolutional filters, are known to be learnable features, yet their individual role in producing the output is rather unclear. The thesis of this work is that not all neurons are equally important and some of them contain more useful information to perform a given task . Consequently, we quantify the significance of each filter and rank its importance in describing input to produce the desired output. This work presents two different methods: (1) a game theoretical approach based on Shapley value which computes the marginal contribution of each filter; and (2) a probabilistic approach based on what-we-call, the Importance switch using variational inference. Strikingly, these two vastly different methods produce similar experimental results, confirming the general theory that some of the filters are inherently more important that the others. The learned ranks can be readily useable for network compression and interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that not all convolutional filters in CNNs are equally important for task performance. It introduces two independent methods to rank filter importance: (1) a game-theoretic Shapley-value computation of each filter's marginal contribution and (2) a variational-inference approach based on an 'importance switch.' The central claim is that these two methods produce similar experimental rankings, thereby confirming that some filters are inherently more important and that the resulting ranks are directly usable for network compression and interpretability.
Significance. If the reported agreement between the two rankings were shown to be robust, reproducible, and grounded in actual task performance (rather than shared methodological bias), the work would supply a principled, dual-method route to neuron-level pruning and interpretability. The absence of any quantitative validation, however, prevents assessment of whether the approach offers a genuine advance over existing pruning heuristics.
major comments (2)
- [Abstract] Abstract: the claim that 'these two vastly different methods produce similar experimental results' is presented with no datasets, architectures, quantitative metrics, baselines, error bars, or even a description of the experimental protocol, so the central empirical assertion cannot be evaluated.
- [Abstract] Abstract: the inference that agreement between the Shapley and variational rankings 'confirm[s] the general theory that some of the filters are inherently more important' treats inter-method concordance as evidence of correctness; no ablation, oracle comparison, or downstream compression result is supplied to distinguish true marginal contribution from correlated non-causal proxies (e.g., filter norm or activation magnitude).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for clearer validation of the central claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'these two vastly different methods produce similar experimental results' is presented with no datasets, architectures, quantitative metrics, baselines, error bars, or even a description of the experimental protocol, so the central empirical assertion cannot be evaluated.
Authors: We agree that the abstract is too high-level and omits key experimental details, making the claim difficult to assess from the abstract alone. The full paper contains the experimental protocol, but to improve clarity we will revise the abstract to briefly specify the datasets (MNIST, CIFAR-10), architectures tested, and the quantitative similarity metrics used for the rankings. revision: yes
-
Referee: [Abstract] Abstract: the inference that agreement between the Shapley and variational rankings 'confirm[s] the general theory that some of the filters are inherently more important' treats inter-method concordance as evidence of correctness; no ablation, oracle comparison, or downstream compression result is supplied to distinguish true marginal contribution from correlated non-causal proxies (e.g., filter norm or activation magnitude).
Authors: The two methods were chosen precisely because they rest on unrelated foundations (exact marginal contribution via Shapley values versus variational inference over an importance switch), so their agreement is offered as converging evidence rather than proof. We acknowledge that this does not yet rule out shared bias with simpler proxies. In revision we will add explicit comparisons of the derived rankings against filter-norm and activation-magnitude baselines, together with downstream compression accuracy results that demonstrate gains beyond those baselines. revision: yes
Circularity Check
No circularity: two independent methods yield agreement presented as external confirmation.
full rationale
The paper defines two distinct ranking procedures (Shapley marginal contribution and variational importance-switch) and reports their empirical agreement on filter importance. No equation reduces one method to the other by construction, no parameter is fitted on a subset and then relabeled a prediction, and no load-bearing premise rests on a self-citation chain. The agreement is treated as confirmatory evidence rather than a definitional identity, satisfying the default expectation of a non-circular derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Not all convolutional filters are equally important for producing the desired output on a task
Reference graph
Works this paper leans on
-
[1]
Network Dissection: Quantifying Interpretability of Deep Visual Representations
doi: 10.1371/journal.pone.0130140. URL https://doi.org/10.1371/journal.pone.0130140. David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. CoRR, abs/1704.05796,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1371/journal.pone.0130140
-
[2]
URL http://arxiv.org/abs/1704.05796. R. Fergus, P. Perona, and A. Zisserman. Object class recognition by unsupervised scale-invariant learning. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[3]
Mikhail Figurnov, Shakir Mohamed, and Andriy Mnih
doi: 10.1109/CVPR.2003.1211479. Mikhail Figurnov, Shakir Mohamed, and Andriy Mnih. Implicit reparameterization gra- dients. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems 31 , pages 441–452. Curran Associates, Inc.,
-
[4]
ISSN 0031-3203. doi: https://doi.org/ 10.1016/j.patcog.2017.10.013. URL http://www.sciencedirect.com/science/article/ pii/S0031320317304120. Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j.patcog.2017.10.013 2017
-
[5]
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Forrest N Iandola, Song Han, Matthew W Moskewicz, Khalid Ashraf, William J Dally, and Kurt Keutzer. Squeezenet: Alexnet-level accuracy with 50x fewer parameters and< 0.5 mb model size. arXiv preprint arXiv:1602.07360,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
David A. Knowles. Stochastic gradient variational Bayes for gamma approximating distributions. arXiv e-prints, art. arXiv:1509.01631, Sep
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Vadim Lebedev and Victor Lempitsky. Fast convnets using group-wise brain damage.2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Jun
work page 2016
-
[9]
doi: 10.1109/cvpr. 2016.280. URL http://dx.doi.org/10.1109/CVPR.2016.280. Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner, et al. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11):2278–2324,
-
[10]
Pruning Filters for Efficient ConvNets
Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets.arXiv preprint arXiv:1608.08710,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
9 Christos Louizos, Max Welling, and Diederik P. Kingma. Learning Sparse Neural Networks through $L_0$ Regularization. arXiv e-prints, art. arXiv:1712.01312, Dec
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Playing Atari with Deep Reinforcement Learning
URL https://arxiv.org/pdf/1312.5602.pdf. Dmitry Molchanov, Arsenii Ashukha, and Dmitry Vetrov. Variational dropout sparsifies deep neural networks. arXiv preprint arXiv:1701.05369,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Explaining NonLinear Classification Decisions with Deep Taylor Decomposition
URL http://arxiv.org/abs/1512.02479. Guido F Montufar, Razvan Pascanu, Kyunghyun Cho, and Yoshua Bengio. On the number of linear regions of deep neural networks. In Advances in neural information processing systems , pages 2924–2932,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Abhishek Das, Ramakrishna Vedantam, Michael Cogswell, Devi Parikh, and Dhruv Batra. Grad-cam: Why did you say that? visual explanations from deep networks via gradient-based localization. CoRR, abs/1610.02391,
-
[17]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Data-free parameter pruning for Deep Neural Networks
Suraj Srinivas and R Venkatesh Babu. Data-free parameter pruning for deep neural networks. arXiv preprint arXiv:1507.06149,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Dropout: a simple way to prevent neural networks from overfitting
Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1):1929–1958,
work page 1929
-
[20]
FLOPs as a Direct Optimization Objective for Learning Sparse Neural Networks
Raphael Tang, Ashutosh Adhikari, and Jimmy Lin. Flops as a direct optimization objective for learning sparse neural networks. arXiv preprint arXiv:1811.03060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Soft Weight-Sharing for Neural Network Compression
10 Karen Ullrich, Edward Meeds, and Max Welling. Soft weight-sharing for neural network compression. arXiv preprint arXiv:1702.04008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Learning structured sparsity in deep neural networks
Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, and Hai Li. Learning structured sparsity in deep neural networks. In Advances in Neural Information Processing Systems , pages 2074–2082,
work page 2074
-
[23]
Understanding Neural Networks Through Deep Visualization
Jason Yosinski, Jeff Clune, Anh Mai Nguyen, Thomas J. Fuchs, and Hod Lipson. Understanding neural networks through deep visualization. CoRR, abs/1506.06579,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Visualizing and Understanding Convolutional Networks
Matthew D. Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.