Representation-Aware Advantage Estimation: Your Reward Model Provides More Than A Scalar Output
Pith reviewed 2026-06-27 13:37 UTC · model grok-4.3
The pith
Reward model hidden states, modeled as graphs of response similarity, produce better advantage estimates than scalar rewards alone in RLHF.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
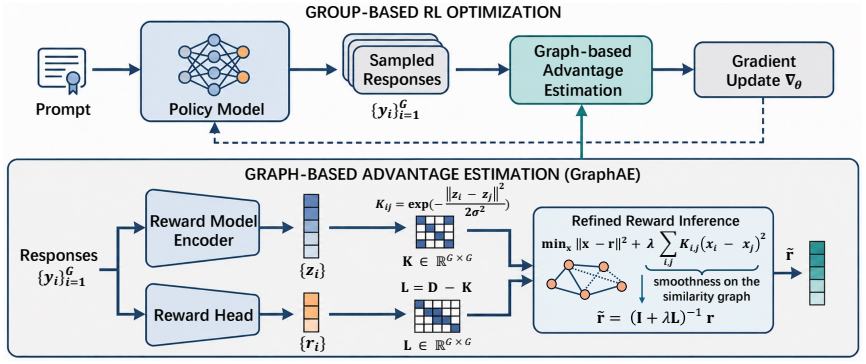
The paper establishes that representation-aware advantage estimation, implemented as Graph-based Advantage Estimation, models each sampled group as a graph whose nodes are responses and whose edges reflect similarity in the reward model's hidden space; advantages are then obtained by propagating information across these edges, allowing each sample to incorporate contextual signals from neighbors and yielding more accurate estimates than scalar rewards alone.
What carries the argument
Graph-based Advantage Estimation (GraphAE), which constructs a graph over responses using similarity edges in reward-model hidden space and computes advantages by propagation across those edges.
If this is right
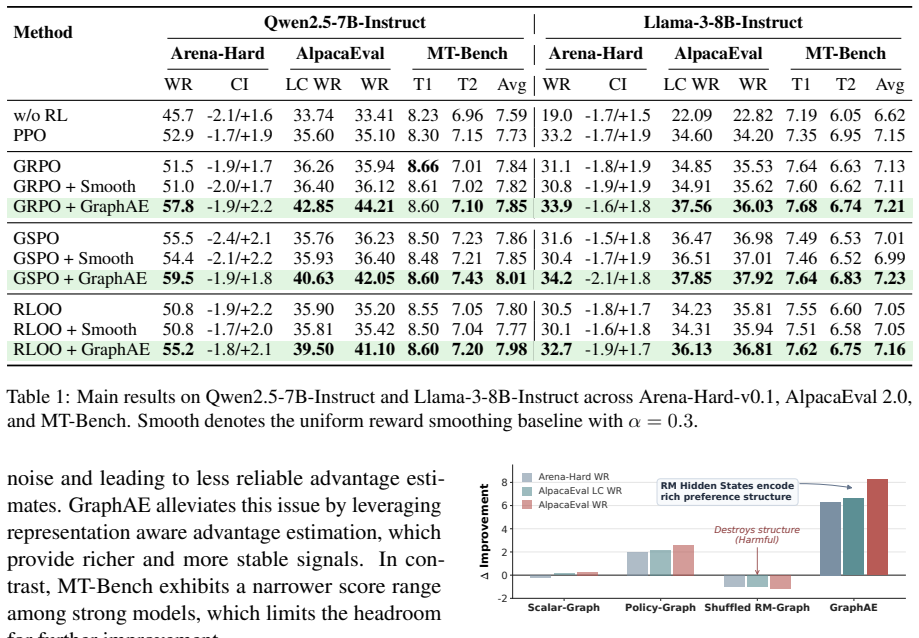
- GraphAE integrates into GRPO, GSPO and RLOO and produces consistent gains on Arena-Hard-v0.1, AlpacaEval 2.0 and MT-Bench.
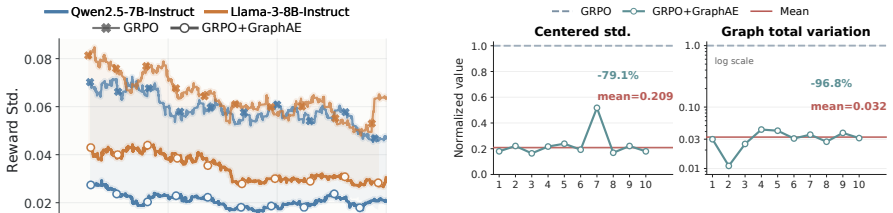
- RLHF training becomes more sample-efficient because each response benefits from contextual information drawn from similar neighbors.
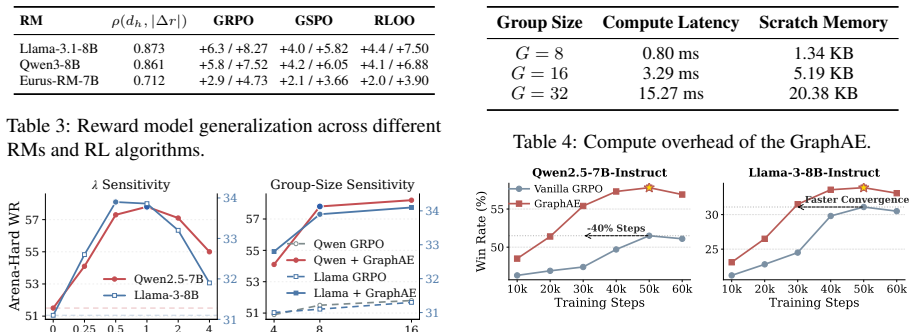
- The method remains lightweight and requires only the hidden states already produced by a standard reward model.
Where Pith is reading between the lines
- Reward-model training objectives could be extended to encourage richer internal representations rather than scalar accuracy alone.
- The same graph-propagation idea might apply to other reinforcement-learning settings that already compute auxiliary representations.
- Different choices of similarity metric or propagation rule could be tested to further refine the advantage estimates.
Load-bearing premise
Reward-model hidden states contain preference information that can be captured by similarity edges and usefully propagated to improve advantage estimates.
What would settle it
An experiment that applies the graph-propagation procedure to the same RLHF setups and records no improvement or a decline on the three reported benchmarks would falsify the central claim.
Figures



read the original abstract
Current reinforcement learning from human feedback (RLHF) methods primarily rely on scalar rewards from a trained reward model (RM). While effective, scalar rewards are often noisy and fail to capture fine-grained preference differences, whereas RM hidden states encode richer semantic and preference information. We introduce the representation-aware advantage estimation, which leverages RM hidden states and models them as auxiliary signals for better advantage estimation. Specifically, we propose the Graph-based Advantage Estimation (GraphAE), treat each sampled group as a graph, where nodes correspond to responses and edges capture their similarity in the RM hidden space. Then advantages are computed via graph propagation, enabling each sample to incorporate contextual information from its neighbors. GraphAE is lightweight and can be seamlessly integrated into existing group-based RL algorithms. We apply GraphAE to GRPO, GSPO and RLOO, and conduct extensive experiments on different models and benchmarks. Empirical results show consistent improvements across three benchmarks, with gains of up to + 6.3 on Arena-Hard-v0.1, + 8.27 on AlpacaEval 2.0, and + 0.22 on MT-Bench. These results demonstrate that leveraging RM representations leads to more sample efficient and robust RLHF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reward model (RM) hidden states contain richer semantic and preference information than their scalar outputs alone. It introduces Graph-based Advantage Estimation (GraphAE), which constructs a graph over responses in each sampled group with edges defined by hidden-state similarity and computes advantages via graph propagation. The method is integrated into GRPO, GSPO, and RLOO, with reported gains of up to +6.3 on Arena-Hard-v0.1, +8.27 on AlpacaEval 2.0, and +0.22 on MT-Bench, arguing for more sample-efficient and robust RLHF.
Significance. If the gains arise specifically from preference information encoded in RM representations (rather than generic smoothing), the approach would meaningfully improve existing group-based RLHF pipelines by extracting additional signal from already-trained reward models without extra training cost.
major comments (2)
- [Section 4] Experiments (Section 4): The reported benchmark improvements lack any ablation that isolates the contribution of RM hidden-state similarity; there are no controls using random graphs, policy-embedding graphs, or scalar-reward-distance graphs. Without these, it is impossible to determine whether the observed deltas (+6.3 Arena-Hard, etc.) result from richer preference information or from the addition of any propagation operator.
- [Section 3] Method (Section 3): The graph-construction and propagation procedure is presented without reporting edge-density statistics, the precise similarity metric, or hyperparameter sensitivity; the central claim that hidden states encode information orthogonal to the scalar RM output therefore rests on an untested modeling assumption rather than a controlled demonstration.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use the phrase "consistent improvements" without defining consistency (e.g., across seeds, models, or runs).
- [Section 4] Implementation details (number of runs, statistical tests, error bars) are absent from the experimental description, making reproducibility and significance assessment difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to strengthen the experimental controls and methodological details, which we address point by point below. We will incorporate revisions to improve clarity and rigor.
read point-by-point responses
-
Referee: [Section 4] Experiments (Section 4): The reported benchmark improvements lack any ablation that isolates the contribution of RM hidden-state similarity; there are no controls using random graphs, policy-embedding graphs, or scalar-reward-distance graphs. Without these, it is impossible to determine whether the observed deltas (+6.3 Arena-Hard, etc.) result from richer preference information or from the addition of any propagation operator.
Authors: We agree that the current experiments do not include the specific control ablations suggested (random graphs, policy-embedding graphs, or scalar-reward-distance graphs). The manuscript reports improvements relative to the base group-based RL algorithms (GRPO, GSPO, RLOO) without the graph propagation step, which provides a baseline for the effect of adding the operator. However, these controls do not fully isolate whether gains derive from RM-specific semantic information versus generic propagation. We will add the requested ablations in the revised version to more directly support the claim that RM hidden states provide orthogonal preference information. revision: yes
-
Referee: [Section 3] Method (Section 3): The graph-construction and propagation procedure is presented without reporting edge-density statistics, the precise similarity metric, or hyperparameter sensitivity; the central claim that hidden states encode information orthogonal to the scalar RM output therefore rests on an untested modeling assumption rather than a controlled demonstration.
Authors: We acknowledge that the manuscript does not report edge-density statistics, the exact similarity metric (e.g., cosine similarity on hidden states), or hyperparameter sensitivity results. These details will be added to Section 3 in the revision, along with sensitivity analysis, to make the procedure fully reproducible and to provide empirical support for the modeling assumption that hidden states capture information beyond the scalar reward. revision: yes
Circularity Check
No significant circularity; method is a self-contained empirical proposal.
full rationale
The paper introduces GraphAE as a novel graph-propagation technique on RM hidden-state similarities, applied to existing RL algorithms like GRPO. The abstract and described approach contain no equations, derivations, or self-citations that reduce the claimed advantage estimates to fitted inputs or prior results by construction. Benchmark gains are presented as empirical outcomes, not tautological predictions. The central claim rests on an untested modeling assumption rather than a definitional loop, qualifying as a standard non-circular method paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward model hidden states encode richer semantic and preference information than the scalar output alone.
invented entities (1)
-
GraphAE
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of NeurIPS , year=
Deep reinforcement learning from human preferences , author=. Proceedings of NeurIPS , year=
-
[2]
arXiv preprint arXiv:2212.08073 , year=
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
-
[3]
arXiv preprint arXiv:2209.07858 , year=
Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned , author=. arXiv preprint arXiv:2209.07858 , year=
-
[4]
arXiv preprint arXiv:1707.06347 , year=
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
-
[5]
arXiv preprint arXiv:2402.03300 , year=
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
-
[6]
arXiv preprint arXiv:2507.01352 , year=
Skywork-reward-v2: Scaling preference data curation via human-ai synergy , author=. arXiv preprint arXiv:2507.01352 , year=
-
[7]
Proceedings of ICML , year=
Ultrafeedback: Boosting language models with scaled ai feedback , author=. Proceedings of ICML , year=
-
[8]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[9]
Proceedings of ICML , year=
Semi-supervised learning using Gaussian fields and harmonic functions , author=. Proceedings of ICML , year=
-
[10]
Proceedings of COLT , year=
Kernels and regularization on graphs , author=. Proceedings of COLT , year=
-
[11]
arXiv preprint arXiv:2507.18071 , year=
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
-
[12]
Proceedings of ACL , year=
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs , author=. Proceedings of ACL , year=
-
[13]
arXiv preprint arXiv:2406.11939 , year=
From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline , author=. arXiv preprint arXiv:2406.11939 , year=
-
[14]
arXiv preprint arXiv:2404.04475 , year=
Length-controlled alpacaeval: A simple way to debias automatic evaluators , author=. arXiv preprint arXiv:2404.04475 , year=
-
[15]
Proceedings of NeurIPS , year=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Proceedings of NeurIPS , year=
-
[16]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[17]
2023 , booktitle=
Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization , author=. 2023 , booktitle=
2023
-
[18]
arXiv preprint arXiv:2310.00212 , year=
Pairwise proximal policy optimization: Harnessing relative feedback for llm alignment , author=. arXiv preprint arXiv:2310.00212 , year=
-
[19]
1998 , publisher=
Reinforcement learning: An introduction , author=. 1998 , publisher=
1998
-
[20]
Proceedings of NeurIPS , year=
Direct preference optimization: Your language model is secretly a reward model , author=. Proceedings of NeurIPS , year=
-
[21]
Proceedings of NeurIPS , year=
Simpo: Simple preference optimization with a reference-free reward , author=. Proceedings of NeurIPS , year=
-
[22]
arXiv preprint arXiv:2402.01306 , year=
Kto: Model alignment as prospect theoretic optimization , author=. arXiv preprint arXiv:2402.01306 , year=
-
[23]
Proceedings of EMNLP , year=
Orpo: Monolithic preference optimization without reference model , author=. Proceedings of EMNLP , year=
-
[24]
arXiv preprint arXiv:2404.10719 , year=
Is dpo superior to ppo for llm alignment? a comprehensive study , author=. arXiv preprint arXiv:2404.10719 , year=
-
[25]
arXiv preprint arXiv:2305.20050 , year=
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
-
[26]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[27]
arXiv preprint arXiv:2404.02078 , year=
Advancing llm reasoning generalists with preference trees , author=. arXiv preprint arXiv:2404.02078 , year=
-
[28]
Proceedings of NeurIPS , year=
Policy gradient methods for reinforcement learning with function approximation , author=. Proceedings of NeurIPS , year=
-
[29]
Proceedings of NeurIPS , year=
Training language models to follow instructions with human feedback , author=. Proceedings of NeurIPS , year=
-
[30]
Proceedings of ACL , year=
Dialogpt: Large-scale generative pre-training for conversational response generation , author=. Proceedings of ACL , year=
-
[31]
Proceedings of NeurIPS , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. Proceedings of NeurIPS , year=
-
[32]
arXiv preprint arXiv:2502.18770 , year=
Reward shaping to mitigate reward hacking in rlhf , author=. arXiv preprint arXiv:2502.18770 , year=
-
[33]
arXiv preprint arXiv:2303.00001 , year=
Reward design with language models , author=. arXiv preprint arXiv:2303.00001 , year=
-
[34]
Proceedings of ICML , year=
Policy filtration for rlhf to mitigate noise in reward models , author=. Proceedings of ICML , year=
-
[35]
Proceedings of AAAI , year=
Interpretable reward model via sparse autoencoder , author=. Proceedings of AAAI , year=
-
[36]
Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts
Wang, Haoxiang and Xiong, Wei and Xie, Tengyang and Zhao, Han and Zhang, Tong. Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts. Findings of EMNLP. 2024
2024
-
[37]
arXiv preprint arXiv:2401.06080 , year=
Secrets of rlhf in large language models part ii: Reward modeling , author=. arXiv preprint arXiv:2401.06080 , year=
-
[38]
Proceedings of NeurIPS , year=
Regularizing hidden states enables learning generalizable reward model for llms , author=. Proceedings of NeurIPS , year=
-
[39]
arXiv preprint arXiv:2410.04503 , year=
LRHP: Learning Representations for Human Preferences via Preference Pairs , author=. arXiv preprint arXiv:2410.04503 , year=
-
[40]
Proceedings of NeurIPS , year=
Dapo: An open-source llm reinforcement learning system at scale , author=. Proceedings of NeurIPS , year=
-
[41]
arXiv preprint arXiv:2503.20783 , year=
Understanding r1-zero-like training: A critical perspective , author=. arXiv preprint arXiv:2503.20783 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.