AffordVLA: Injecting Affordance Representations into Vision-Language-Action Models via Implicit Feature Alignment
Pith reviewed 2026-05-20 12:45 UTC · model grok-4.3
The pith
AffordVLA improves robotic action accuracy by aligning VLA visual features with task-conditioned affordance representations from a zero-shot teacher.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
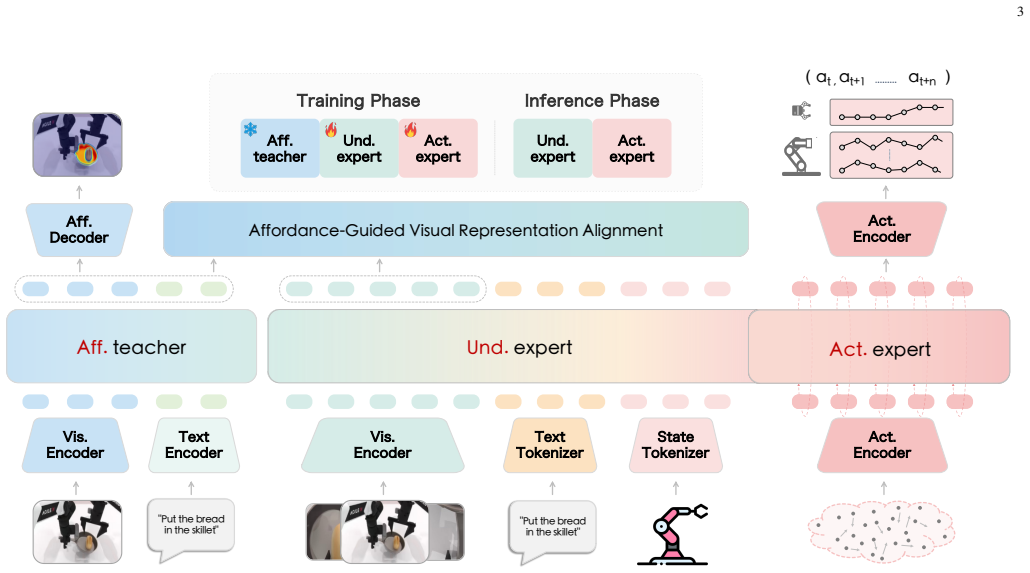
AffordVLA constructs a zero-shot affordance teacher to extract task-conditioned affordance visual representations from RGB observations and language instructions. The framework then aligns the intermediate visual representations of the VLA with the affordance visual representations extracted by the teacher, thereby implicitly injecting manipulation-centric affordance perception into VLA visual representations and improving action accuracy.
What carries the argument
Implicit representation alignment that matches VLA intermediate visual features to outputs of the zero-shot affordance teacher, reshaping the VLA's focus toward functional interaction regions.
If this is right
- VLA models achieve state-of-the-art manipulation success rates in simulation and real-world settings.
- The method outperforms strong baselines while preserving original inference speed.
- Training efficiency increases because the reshaped representations require fewer iterations to reach high performance.
- Visual representations inside the VLA become more focused on task-relevant functional regions without explicit masks.
- No additional perception modules or annotations are needed at deployment time.
Where Pith is reading between the lines
- Similar implicit alignment could be applied to other sensory cues such as object semantics or physics properties inside the same VLA backbone.
- The approach may reduce the amount of task-specific robot data needed by leveraging the teacher's zero-shot capability.
- Robots using this method could maintain higher performance when environments change rapidly or contain previously unseen objects.
- The technique might transfer to other multimodal control architectures that currently suffer from appearance-dominated visual features.
Load-bearing premise
The zero-shot affordance teacher can reliably extract accurate task-conditioned affordance visual representations from RGB observations and language instructions without introducing errors or requiring additional annotations.
What would settle it
Remove the alignment loss during training and measure whether action success rates drop in both simulation and real-robot experiments; alternatively, inspect whether the teacher's affordance maps contain systematic errors on novel objects or instructions.
Figures









read the original abstract
Recent advances in Vision-Language-Action (VLA) models have shown strong potential for general-purpose robotic manipulation. However, the visual representations of most VLA models are often dominated by global object appearance and struggle to focus on task-relevant functional interaction regions, which limits their robustness in unstructured environments. Existing affordance-based methods typically rely on explicit mask injection or external perception modules, requiring additional annotations while introducing cascading perception errors and inference overhead. To address these limitations, we propose AffordVLA, an affordance-enhanced VLA framework that internalizes manipulation-centric affordance perception into VLA visual representations through implicit representation alignment. Specifically, we construct a zero-shot affordance teacher to extract task-conditioned affordance visual representations from RGB observations and language instructions. AffordVLA aligns the intermediate visual representations of the VLA with the affordance visual representations extracted by the teacher, thereby implicitly injecting manipulation-centric affordance perception into VLA visual representations and improving action accuracy. Extensive simulation and real-world experiments demonstrate that AffordVLA and its affordance teacher achieve state-of-the-art performance and outperform strong baselines. Ablation analyses show that AffordVLA effectively reshapes VLA visual representations while preserving inference efficiency, leading to improved manipulation success rates and training efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AffordVLA, a framework for enhancing Vision-Language-Action (VLA) models in robotic manipulation by implicitly aligning the VLA's intermediate visual representations with task-conditioned affordance visual features extracted by a separate zero-shot affordance teacher model from RGB observations and language instructions. This approach aims to focus VLA representations on functional interaction regions without explicit mask injection, additional annotations, or external modules at inference time. The authors report state-of-the-art performance on simulation and real-world manipulation tasks, along with ablation studies indicating improved action accuracy, training efficiency, and representation reshaping while preserving inference speed.
Significance. If the central claims hold, the work offers a practical way to internalize manipulation-centric affordance perception into VLA backbones via implicit alignment, potentially improving robustness in unstructured environments compared to explicit affordance methods. The implicit alignment strategy is a positive aspect as it avoids inference overhead. Ablation analyses are noted as a strength for supporting the representation-level effects.
major comments (2)
- [Method and Experiments sections] The zero-shot affordance teacher is load-bearing for the central claim of injecting useful affordance perception (as stated in the abstract and method overview). However, no quantitative validation metrics for the teacher's affordance extraction accuracy (e.g., on manipulation-specific scenes or task-conditioned regions) are reported in the experiments or method sections. Without this, it is unclear whether reported gains arise from genuine affordance structure or from incidental effects such as regularization.
- [§4] §4 (Experiments): The reported SOTA performance and ablation results lack details on experimental setup including number of trials, error bars, statistical significance tests, data exclusion rules, and environment/task specifications. This makes it impossible to verify whether the quantitative improvements in action accuracy and success rates are robustly supported by the data.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction could more explicitly reference prior affordance literature in robotics to better situate the implicit alignment contribution.
- [Method section] Notation for the alignment objective (e.g., any loss formulation or feature extraction equations) would benefit from an explicit equation number and clearer variable definitions for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below and indicate the corresponding revisions planned for the next version of the paper.
read point-by-point responses
-
Referee: [Method and Experiments sections] The zero-shot affordance teacher is load-bearing for the central claim of injecting useful affordance perception (as stated in the abstract and method overview). However, no quantitative validation metrics for the teacher's affordance extraction accuracy (e.g., on manipulation-specific scenes or task-conditioned regions) are reported in the experiments or method sections. Without this, it is unclear whether reported gains arise from genuine affordance structure or from incidental effects such as regularization.
Authors: We agree that direct quantitative validation of the zero-shot affordance teacher's extraction accuracy would provide stronger support for the claim that gains derive from meaningful affordance structure rather than incidental regularization. The current manuscript validates the overall approach through end-to-end task performance and representation-level ablations, but we recognize this leaves room for ambiguity regarding the teacher's specific contribution. In the revised manuscript, we will add a dedicated evaluation subsection reporting quantitative metrics (such as region overlap with task-relevant interaction areas on held-out manipulation scenes) to directly assess the teacher's affordance quality and address this concern. revision: yes
-
Referee: [§4] §4 (Experiments): The reported SOTA performance and ablation results lack details on experimental setup including number of trials, error bars, statistical significance tests, data exclusion rules, and environment/task specifications. This makes it impossible to verify whether the quantitative improvements in action accuracy and success rates are robustly supported by the data.
Authors: We acknowledge that the current experimental section would benefit from expanded details on the protocol to enable full verification and assessment of robustness. While the manuscript already includes ablation studies and reports performance across simulation and real-world settings, additional specifics on trial counts, variability, and statistical analysis were not fully elaborated. In the revised version of Section 4, we will include comprehensive information on the number of evaluation trials, error bars across multiple seeds, statistical significance testing, data exclusion criteria, and precise environment and task specifications to strengthen the evidence for the reported improvements. revision: yes
Circularity Check
No circularity: method uses independent zero-shot teacher and alignment
full rationale
The paper's core derivation introduces a separate zero-shot affordance teacher to extract task-conditioned representations from RGB and language, followed by an implicit alignment step to inject those into the VLA backbone. This is an architectural choice with external teacher and empirical validation through simulation/real-world experiments, not a self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. No equations or steps in the abstract reduce the claimed gains to tautological inputs by construction; the approach remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A zero-shot affordance teacher can extract meaningful task-conditioned affordance representations from RGB images and language instructions without additional annotations.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
AffordVLA aligns the intermediate visual representations of the VLA with the affordance visual representations extracted by the teacher... Lalign = -1/N sum cos(ˆxV,(m)t,i , ˜zafft,i)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
zero-shot affordance teacher... task-conditioned affordance visual representations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Y . Wang, H. Guo, H. Wu, and H. Dong, “Flexible robotic hand harnesses large deformations for full-coverage human-like multimodal haptic perception,”Nature Communications, 2025
work page 2025
-
[2]
Language-conditioned affordance-pose detection in 3d point clouds,
T. Nguyen, M. N. Vu, B. Huanget al., “Language-conditioned affordance-pose detection in 3d point clouds,” inProc. IEEE Int. Conf. Robot. Autom., Yokohama, Japan, 2024, pp. 3071–3078
work page 2024
-
[3]
Uad: Unsupervised affordance distillation for generalization in robotic manipulation,
Y . Tang, W. Huang, Y . Wanget al., “Uad: Unsupervised affordance distillation for generalization in robotic manipulation,” inProc. IEEE Int. Conf. Robot. Autom., Atlanta, GA, USA, 2025, pp. 3822–3831
work page 2025
-
[4]
Affordancenet: An end-to-end deep learning approach for object affordance detection,
T.-T. Do, A. Nguyen, and I. Reid, “Affordancenet: An end-to-end deep learning approach for object affordance detection,” inProc. IEEE Int. Conf. Robot. Autom., Brisbane, Australia, 2018, pp. 5882–5889
work page 2018
-
[5]
M. Pan, J. Zhang, T. Wu, Y . Zhao, W. Gao, and H. Dong, “Omnimanip: Towards general robotic manipulation via object-centric interaction primitives as spatial constraints,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Nashville, TN, USA, 2025, pp. 17 359–17 369
work page 2025
-
[6]
A0: An affordance-aware hierarchical model for general robotic manipulation,
R. Xu, J. Zhang, M. Guoet al., “A0: An affordance-aware hierarchical model for general robotic manipulation,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Honolulu, HI, USA, 2025, pp. 13 491–13 501
work page 2025
-
[7]
S. Huang, I. Ponomarenko, Z. Jianget al., “Manipvqa: Injecting robotic affordance and physically grounded information into multi-modal large language models,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Abu Dhabi, United Arab Emirates, 2024, pp. 7580–7587
work page 2024
-
[8]
G. Jiang, Y . Sun, T. Huanget al., “Robots pre-train robots: Manipulation- centric robotic representation from large-scale robot datasets,” inProc. 13th Int. Conf. Learn. Represent., Singapore, 2025
work page 2025
-
[9]
Tars: Tactile affor- dance in robot synesthesia for dexterous manipulation,
Q. Wu, H. Wang, J. Zhou, X. Xiong, and Y . Lou, “Tars: Tactile affor- dance in robot synesthesia for dexterous manipulation,”IEEE Robotics and Automation Letters, vol. 10, no. 1, pp. 327–334, 2024
work page 2024
-
[10]
Y . Wang, W. Yu, H. Wu, H. Guo, and H. Dong, “Sa-dem: Dexterous ex- trinsic robotic manipulation of non-graspable objects via stiffness-aware dual-stage reinforcement learning,”IEEE Transactions on Automation Science and Engineering, vol. 23, pp. 347–362, 2025
work page 2025
-
[11]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohanet al., “Rt-1: Robotics transformer for real-world control at scale,” inProc. Robot. Sci. Syst., Daegu, Republic of Korea, 2023
work page 2023
-
[12]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xuet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inProc. Conf. Robot Learn., Atlanta, GA, USA, 2023, pp. 2165–2183
work page 2023
-
[13]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brownet al., “π 0: A vision-language-action flow model for general robot control,”arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
OpenVLA: An open- source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamchetiet al., “OpenVLA: An open- source vision-language-action model,” inProc. 8th Conf. Robot Learn., Munich, Germany, 2024
work page 2024
-
[15]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadevet al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv preprint arXiv:2503.14734, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Vla-jepa: Enhancing vision-language-action model with latent world model, 2026
J. Sun, W. Zhang, Z. Qiet al., “Vla-jepa: Enhancing vision- language-action model with latent world model,”arXiv preprint arXiv:2602.10098, 2026
-
[17]
Reconvla: Reconstructive vision- language-action model as effective robot perceiver,
W. Song, Z. Zhou, H. Zhaoet al., “Reconvla: Reconstructive vision- language-action model as effective robot perceiver,” inProc. AAAI Conf. Artif. Intell., vol. 40, no. 22, Singapore, 2026, pp. 18 549–18 557
work page 2026
-
[18]
Spatial forcing: Implicit spatial representation alignment for vision-language-action model,
F. Li, W. Song, H. Zhaoet al., “Spatial forcing: Implicit spatial representation alignment for vision-language-action model,” inProc. 14th Int. Conf. Learn. Represent., Rio de Janeiro, Brazil, 2026
work page 2026
-
[19]
Rt-affordance: Affordances are versatile intermediate representations for robot manipulation,
S. Nasiriany, S. Kirmani, T. Dinget al., “Rt-affordance: Affordances are versatile intermediate representations for robot manipulation,” inProc. IEEE Int. Conf. Robot. Autom., Atlanta, GA, USA, 2025, pp. 8249–8257
work page 2025
-
[20]
Moka: Open-world robotic manipulation through mark-based visual prompting,
K. Fang, F. Liu, P. Abbeel, and S. Levine, “Moka: Open-world robotic manipulation through mark-based visual prompting,” inProc. Robot. Sci. Syst., Delft, Netherlands, 2024
work page 2024
-
[21]
Knowledge enhanced bottom-up affordance grounding for robotic interaction,
W. Quet al., “Knowledge enhanced bottom-up affordance grounding for robotic interaction,”PeerJ Computer Science, vol. 10, p. e2097, 2024
work page 2024
-
[22]
Uncertainty-aware state space transformer for egocentric 3d hand trajectory forecasting,
W. Bao, L. Chenet al., “Uncertainty-aware state space transformer for egocentric 3d hand trajectory forecasting,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, 2023, pp. 13 702–13 711
work page 2023
-
[23]
arXiv preprint arXiv:2507.10672 , year=
M. U. Din, W. Akram, L. S. Saoud, J. Rosell, and I. Hussain, “Vision language action models in robotic manipulation: A systematic review,” arXiv preprint arXiv:2507.10672, 2025
-
[24]
Coa-vla: Improving vision-language- action models via visual-text chain-of-affordance,
J. Li, Y . Zhu, Z. Tanget al., “Coa-vla: Improving vision-language- action models via visual-text chain-of-affordance,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Honolulu, HI, USA, 2025, pp. 9759–9769
work page 2025
-
[25]
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation
Y . Liu, J. Zhu, Y . Moet al., “Palm: Progress-aware policy learning via affordance reasoning for long-horizon robotic manipulation,”arXiv preprint arXiv:2601.07060, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
J. Achiam, S. Adler, S. Agarwalet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
S. Bai, Y . Cai, R. Chenet al., “Qwen3-vl technical report,”arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brownet al., “π 0.5: a vision- language-action model with open-world generalization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,
A. O’Neill, A. Rehman, A. Maddukuriet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collab- oration 0,” inProc. IEEE Int. Conf. Robot. Autom., Yokohama, Japan, 2024, pp. 6892–6903
work page 2024
-
[30]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,
Q. Zhao, Y . Luet al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Nashville, TN, USA, 2025, pp. 1702–1713
work page 2025
-
[31]
Latent Reasoning VLA: Latent Thinking and Prediction for Vision-Language-Action Models
S. Bai, J. Lyu, W. Zhouet al., “Latent reasoning vla: Latent think- ing and prediction for vision-language-action models,”arXiv preprint arXiv:2602.01166, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Q. Lv, W. Kong, H. Liet al., “F1: A vision-language-action model bridging understanding and generation to actions,”arXiv preprint arXiv:2509.06951, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Anicetoet al., “π ∗ 0.6: a vla that learns from experience,”arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Ig-rft: An interaction-guided rl framework for vla models in long-horizon robotic manipulation,
Z. Su, W. Kong, H. Dong, and H. Dong, “Ig-rft: An interaction-guided rl framework for vla models in long-horizon robotic manipulation,”arXiv preprint arXiv:2602.20715, 2026
-
[35]
VLA-RL: Towards Masterful and General Robotic Manipulation with Scalable Reinforcement Learning
G. Lu, W. Guo, C. Zhanget al., “Vla-rl: Towards masterful and general robotic manipulation with scalable reinforcement learning,” arXiv preprint arXiv:2505.18719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
The ecological approach to visual perception,
J. J. Gibson, “The ecological approach to visual perception,”Hilldale, USA, vol. 1, no. 2, pp. 67–82, 1977
work page 1977
-
[37]
W. Kong, Z. Lin, W. Yu, H. Guo, Z. Su, and H. Dong, “Affpose: An integrated rgb-based framework for simultaneous pose estimation and affordance detection in robotic tool manipulation,”IEEE Robotics and Automation Letters, 2025
work page 2025
-
[38]
Affordancellm: Grounding affordance from vision language models,
S. Qian, W. Chen, M. Baiet al., “Affordancellm: Grounding affordance from vision language models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Seattle, W A, USA, 2024, pp. 7587–7597
work page 2024
-
[39]
Object affordance detection with relationship-aware network,
X. Zhao, Y . Cao, and Y . Kang, “Object affordance detection with relationship-aware network,”Neural Computing and Applications, vol. 32, no. 18, pp. 14 321–14 333, 2020
work page 2020
-
[40]
K. Rana, J. Abou-Chakra, S. Garg, R. Lee, I. Reid, and N. Suenderhauf, “Affordance-centric policy learning: Sample efficient and generalis- able robot policy learning using affordance-centric task frames,”arXiv preprint arXiv:2410.12124, vol. 2, 2024
-
[41]
Closed-loop visuomotor control with generative expectation for robotic manipulation,
Q. Bu, J. Zeng, L. Chenet al., “Closed-loop visuomotor control with generative expectation for robotic manipulation,”Advances in Neural Information Processing Systems, vol. 37, pp. 139 002–139 029, 2024
work page 2024
-
[42]
T. Kim, H. Bae, Z. Liet al., “Manipgpt: Is affordance segmentation by large vision models enough for articulated object manipulation?” in Proc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Hangzhou, China, 2025, pp. 20 974–20 981
work page 2025
-
[43]
R3M: A Universal Visual Representation for Robot Manipulation
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta, “R3m: A universal visual representation for robot manipulation,”arXiv preprint arXiv:2203.12601, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Representation alignment for generation: Training diffusion transformers is easier than you think,
S. Yu, S. Kwak, H. Janget al., “Representation alignment for generation: Training diffusion transformers is easier than you think,” inProc. 13th Int. Conf. Learn. Represent., Singapore, 2025
work page 2025
-
[45]
3drs: Mllms need 3d-aware representation supervision for scene understanding,
X. Huang, J. Wu, Q. Xie, and K. Han, “3drs: Mllms need 3d-aware representation supervision for scene understanding,” inAdv. Neural Inf. Process. Syst., San Diego, CA, USA, 2025
work page 2025
-
[46]
Genhancer: Imperfect generative models are secretly strong vision-centric enhancers,
S. Ma, Y . Ge, T. Wanget al., “Genhancer: Imperfect generative models are secretly strong vision-centric enhancers,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Honolulu, HI, USA, 2025, pp. 24 402–24 412
work page 2025
-
[47]
Reconstructive visual instruction tuning,
H. Wang, A. Zheng, Y . Zhaoet al., “Reconstructive visual instruction tuning,” inProc. 13th Int. Conf. Learn. Represent., Singapore, 2025
work page 2025
-
[48]
B. Ren and D. Shi, “Cross-modality alignment perception and multi- head self-attention mechanism for vision-language-action of humanoid robot,”Sensors, vol. 26, no. 1, p. 165, 2025
work page 2025
-
[49]
Spatialvla: Exploring spatial repre- sentations for visual-language-action model,
D. Qu, H. Song, Q. Chenet al., “Spatialvla: Exploring spatial repre- sentations for visual-language-action model,” inProc. Robot. Sci. Syst., Los Angeles, CA, USA, 2025
work page 2025
-
[50]
FLARE: Robot Learning with Implicit World Modeling
R. Zheng, J. Wang, S. Reedet al., “Flare: Robot learning with implicit world modeling,”arXiv preprint arXiv:2505.15659, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inProc. 11th Int. Conf. Learn. Represent., Kigali, Rwanda, 2023
work page 2023
-
[52]
SAM 3: Segment anything with concepts,
N. Carion, L. Gustafson, Y .-T. Huet al., “SAM 3: Segment anything with concepts,” inProc. 14th Int. Conf. Learn. Represent., Rio de Janeiro, Brazil, 2026
work page 2026
-
[53]
Deciphering cross-modal alignment in large vision- language models via modality integration rate,
Q. Huanget al., “Deciphering cross-modal alignment in large vision- language models via modality integration rate,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Honolulu, HI, USA, 2025, pp. 218–227
work page 2025
-
[54]
Learning affordance grounding from exocentric images,
H. Luo, W. Zhai, J. Zhang, Y . Cao, and D. Tao, “Learning affordance grounding from exocentric images,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., New Orleans, LA, USA, 2022, pp. 2252–2261
work page 2022
-
[55]
Locate: Localize and transfer object parts for weakly supervised affordance grounding,
G. Li, V . Jampani, D. Sun, and L. Sevilla-Lara, “Locate: Localize and transfer object parts for weakly supervised affordance grounding,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Vancouver, Canada, 2023, pp. 10 922–10 931
work page 2023
-
[56]
What do different evaluation metrics tell us about saliency models?
Z. Bylinskii, T. Judd, A. Oliva, A. Torralba, and F. Durand, “What do different evaluation metrics tell us about saliency models?”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 3, pp. 740–757, 2018
work page 2018
-
[57]
M. J. Swain and D. H. Ballard, “Color indexing,”International journal of computer vision, vol. 7, no. 1, pp. 11–32, 1991
work page 1991
-
[58]
Components of bottom-up gaze allocation in natural images,
R. J. Peterset al., “Components of bottom-up gaze allocation in natural images,”Vision research, vol. 45, no. 18, pp. 2397–2416, 2005
work page 2005
-
[59]
Understanding 3d object interaction from a single image,
S. Qian and D. F. Fouhey, “Understanding 3d object interaction from a single image,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, 2023, pp. 21 753–21 763
work page 2023
-
[60]
One-shot open affordance learning with foundation models,
G. Li, D. Sun, L. Sevilla-Lara, and V . Jampani, “One-shot open affordance learning with foundation models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Seattle, W A, USA, 2024, pp. 3086–3096
work page 2024
-
[61]
Affordancesam: Segment anything once more in affordance grounding.arXiv preprint arXiv:2504.15650,
D. Jiang, Z. Wang, H. Liet al., “Affordancesam: Segment anything once more in affordance grounding,”arXiv preprint arXiv:2504.15650, 2025
-
[62]
Grounded human- object interaction hotspots from video,
T. Nagarajan, C. Feichtenhofer, and K. Grauman, “Grounded human- object interaction hotspots from video,” inProc. IEEE/CVF Int. Conf. Comput. Vis., Seoul, Republic of Korea, 2019, pp. 8688–8697
work page 2019
-
[63]
Intra: Interaction relationship-aware weakly supervised affordance grounding,
J. H. Jang, H. Seo, and S. Y . Chun, “Intra: Interaction relationship-aware weakly supervised affordance grounding,” inProc. Eur . Conf. Comput. Vis., Milan, Italy, 2024, pp. 18–34
work page 2024
-
[64]
Resource-efficient affordance grounding with com- plementary depth and semantic prompts,
Y . Huanget al., “Resource-efficient affordance grounding with com- plementary depth and semantic prompts,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Hangzhou, China, 2025, pp. 7788–7795
work page 2025
-
[65]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chenet al., “Lisa: Reasoning segmentation via large language model,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Seattle, W A, USA, 2024, pp. 9579–9589
work page 2024
-
[66]
MMR: A large-scale benchmark dataset for multi-target and multi-granularity reasoning segmentation,
D. Jang, Y . Cho, S. Leeet al., “MMR: A large-scale benchmark dataset for multi-target and multi-granularity reasoning segmentation,” inProc. 13th Int. Conf. Learn. Represent., Singapore, 2025
work page 2025
-
[67]
J. Lee, E. Park, C. Park, D. Kang, and M. Cho, “Affogato: Learning open-vocabulary affordance grounding with automated data generation at scale,”arXiv preprint arXiv:2506.12009, 2025. 13
-
[68]
T. Chen, Z. Chen, B. Chenet al., “Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation,”arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inProc. Robot. Sci. Syst., Daegu, Republic of Korea, 2023
work page 2023
-
[70]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Fenget al., “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
work page 2025
-
[71]
3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations,” inProc. Robot. Sci. Syst., Delft, Netherlands, 2024
work page 2024
-
[72]
RDT-1b: a diffusion foundation model for bimanual manipulation,
S. Liu, L. Wu, B. Liet al., “RDT-1b: a diffusion foundation model for bimanual manipulation,” inProc. 13th Int. Conf. Learn. Represent., Singapore, 2025
work page 2025
-
[73]
One-shot transfer of affordance regions? affcorrs!
D. Hadjivelichkov, S. Zwane, L. Agapito, M. P. Deisenroth, and D. Kanoulas, “One-shot transfer of affordance regions? affcorrs!” in Proc. Conf. Robot Learn., Atlanta, GA, USA, 2023, pp. 550–560
work page 2023
-
[74]
Weakly supervised multimodal affordance grounding for egocentric images,
L. Xu, Y . Gao, W. Song, and A. Hao, “Weakly supervised multimodal affordance grounding for egocentric images,” inProc. AAAI Conf. Artif. Intell., vol. 38, no. 6, Vancouver, Canada, 2024, pp. 6324–6332
work page 2024
-
[75]
Weakly-supervised affordance grounding guided by part-level semantic priors,
P. Xu and Y . MU, “Weakly-supervised affordance grounding guided by part-level semantic priors,” inProc. 13th Int. Conf. Learn. Represent., Singapore, 2025
work page 2025
-
[76]
Y . Wang, A. Wu, M. Yang, Y . Min, Y . Zhu, and C. Deng, “Reasoning mamba: Hypergraph-guided region relation calculating for weakly su- pervised affordance grounding,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Nashville, TN, USA, 2025, pp. 27 618–27 627
work page 2025
-
[77]
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of machine learning research, vol. 9, no. 11, 2008
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.