Where to Refine, When to Stop: Rethinking Redundancy via Latent Discrepancy for Efficient Visual Autoregressive Generation
Pith reviewed 2026-06-28 22:36 UTC · model grok-4.3
The pith
Latent discrepancy pruning removes redundant tokens in visual autoregressive models by tracking model state changes, yielding up to 2.35 times faster inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
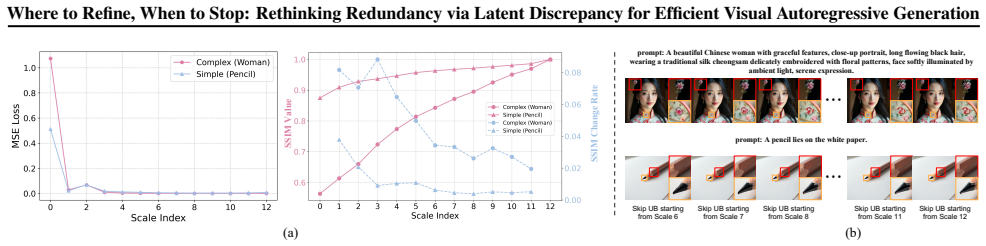
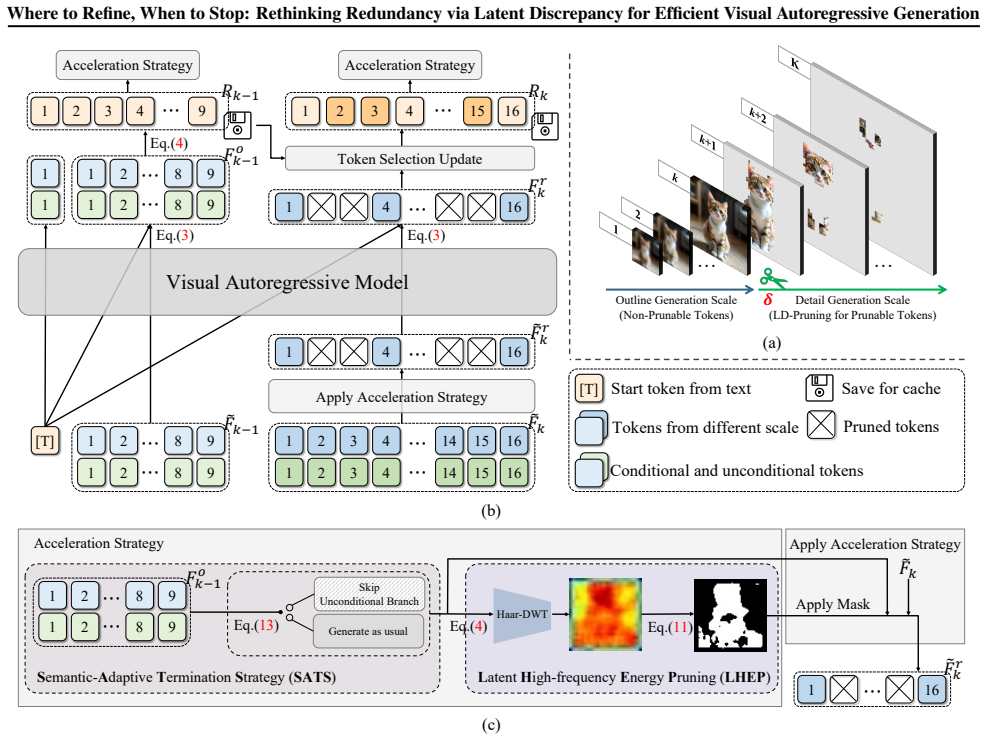
By quantifying a token's contribution through the change in model states measured as latent discrepancy, and observing dynamic trends in conditional-unconditional branches, LD-Pruning prunes tokens and skips branches in a decoding-free and adaptive manner to reduce latency in high-resolution image generation while keeping quality high.
What carries the argument
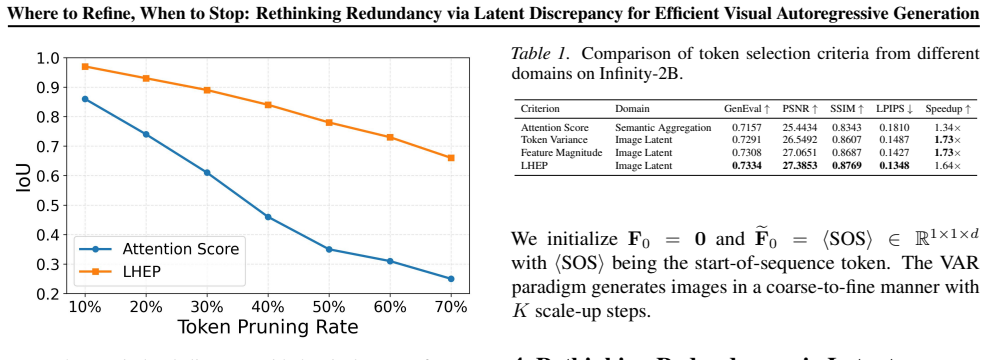
Latent Discrepancy, a metric that quantifies a token's contribution by measuring the change in model states during generation guided by image latent or pixel-space signals.
If this is right
- Redundancy identification improves when guided by pixel-space signals instead of layer-feature heuristics.
- Decoding-free region selection combined with adaptive unconditional-branch skipping becomes feasible.
- Inference latency drops substantially, reaching up to 2.35x speedup on Infinity-8B.
- Generation quality remains high without retraining or prompt-specific tuning.
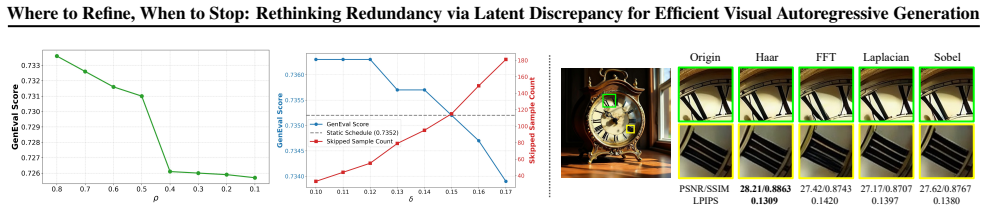
- The method adapts to varying convergence dynamics in classifier-free guidance across different prompts.
Where Pith is reading between the lines
- The same discrepancy signal could be tested for pruning decisions in non-VAR autoregressive vision models.
- High-resolution generation pipelines might incorporate this to lower hardware requirements for interactive use.
- Prompt-dependent branch convergence patterns suggest opportunities for per-sample guidance scale adjustments.
- If the metric proves stable, it could extend to video or 3D autoregressive generation tasks.
Load-bearing premise
Redundancy can be accurately identified by measuring changes in model states guided by image latent or pixel-space signals without degrading final image quality across prompts.
What would settle it
A clear drop in standard image quality metrics or introduction of visible artifacts when LD-Pruning is applied to held-out prompts on models like Infinity-8B would falsify the claim.
Figures






read the original abstract
Visual Autoregressive (VAR) models deliver high-quality image generation but suffer from significant inference latency at high resolutions. Recent acceleration approaches most rely on heuristic measures with layer features to prune tokens. Such heuristics are sensitive to complex contextual semantics, leading to inaccurate identification of redundant computation and poor adaptability across prompts. We rethink redundancy in VAR from the perspective of its impact on pixel-space generation and introduce Latent Discrepancy. This unified metric quantifies a token's contribution by measuring the change in model states during generation. Our analysis shows that redundancy is more accurately identified when guided by image latent or pixel-space signals. We further observed that in classifier-free guidance (CFG), the convergence trend of the discrepancy between conditional and unconditional branches exhibits high dynamics with different prompts. Based on these findings, we propose LD-Pruning (Latent Discrepancy Pruning), a training-free framework that removes redundancy via latent discrepancy by integrating decoding-free region selection and adaptive unconditional-branch skipping. Extensive experiments show that LD-Pruning substantially reduces inference latency while maintaining high generation quality, achieving up to 2.35x speedup on Infinity-8B.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Latent Discrepancy (LD) as a metric to identify redundant tokens in Visual Autoregressive (VAR) models by quantifying changes in model states during generation, guided by image latent or pixel-space signals. It proposes the training-free LD-Pruning framework, which combines decoding-free region selection with adaptive skipping of the unconditional branch in classifier-free guidance (CFG) based on observed convergence dynamics. The central empirical claim is that this approach substantially reduces inference latency while preserving generation quality, with reported speedups up to 2.35x on Infinity-8B.
Significance. If the reported empirical results hold under rigorous controls, the work offers a practical, training-free acceleration technique for high-resolution VAR generation that improves upon heuristic layer-feature pruning by tying redundancy directly to pixel-space impact. The analysis of CFG branch dynamics provides a reusable insight, and the absence of training or additional parameters strengthens applicability. Reproducible experiments on latency and quality metrics would make this a useful contribution to efficient generative modeling.
minor comments (3)
- The abstract states that 'extensive experiments show' latency reduction and quality maintenance but does not report specific metrics, baselines, or controls; adding these quantitative details to the abstract would improve immediate clarity without altering the manuscript scope.
- The description of how latent discrepancy is computed from model-state changes (e.g., exact layer or token indices used) would benefit from an explicit equation or pseudocode in the methods section to allow direct reproduction.
- Figure captions and axis labels for latency/quality trade-off plots should explicitly state the number of prompts, resolution settings, and random seeds used, as these details are referenced in the text but not visible in the figures themselves.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and the recommendation of minor revision. The provided summary accurately captures the core ideas and empirical claims of the LD-Pruning framework. No specific major comments appear in the report, so there are no individual points requiring point-by-point rebuttal. We will incorporate the referee's suggestion to emphasize reproducible latency and quality experiments in the revised version.
Circularity Check
No significant circularity identified
full rationale
The paper defines Latent Discrepancy directly from observed changes in model states during VAR generation and uses it to drive a training-free pruning procedure whose decisions are validated by separate latency and quality experiments. No equation reduces a claimed prediction to a fitted input by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Diffedit: Diffusion-based semantic image editing with mask guidance.arXiv preprint arXiv:2210.11427,
Couairon, G., Verbeek, J., Schwenk, H., and Cord, M. Diffedit: Diffusion-based semantic image editing with mask guidance.arXiv preprint arXiv:2210.11427,
-
[2]
Guo, H., Li, Y ., Zhang, T., Wang, J., Dai, T., Xia, S.- T., and Benini, L. Fastvar: Linear visual autoregres- sive modeling via cached token pruning.arXiv preprint arXiv:2503.23367,
-
[3]
Imagen Video: High Definition Video Generation with Diffusion Models
Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D. P., Poole, B., Norouzi, M., Fleet, D. J., et al. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022a. Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., and Fleet, D. J. Video diffusion models.Advances in neural inf...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[5]
Li, J., Ma, Y ., Zhang, X., Wei, Q., Liu, S., and Zhang, L. Skipvar: Accelerating visual autoregressive modeling via adaptive frequency-aware skipping.arXiv preprint arXiv:2506.08908, 2025a. 10 Where to Refine, When to Stop: Rethinking Redundancy via Latent Discrepancy for Efficient Visual Autoregressive Generation Li, K., Chen, Z., Yang, C.-Y ., and Hwan...
-
[6]
Liu, D., Zhao, S., Zhuo, L., Lin, W., Xin, Y ., Li, X., Qin, Q., Qiao, Y ., Li, H., and Gao, P. Lumina-mgpt: Illu- minate flexible photorealistic text-to-image generation with multimodal generative pretraining.arXiv preprint arXiv:2408.02657,
-
[7]
Ma, X., Fang, G., Bi Mi, M., and Wang, X. Learning- to-cache: Accelerating diffusion transformer via layer caching.Advances in Neural Information Processing Systems, 37:133282–133304, 2024a. Ma, X., Fang, G., and Wang, X. Deepcache: Acceler- ating diffusion models for free. InProceedings of the IEEE/CVF conference on computer vision and pattern recognitio...
-
[8]
Progressive Distillation for Fast Sampling of Diffusion Models
Salimans, T. and Ho, J. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
V ., Zettle- moyer, L., and Yu, L
Shi, W., Han, X., Zhou, C., Liang, W., Lin, X. V ., Zettle- moyer, L., and Yu, L. Lmfusion: Adapting pretrained lan- guage models for multimodal generation.arXiv preprint arXiv:2412.15188,
-
[10]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y ., Chen, S., Zhang, S., Peng, B., Luo, P., and Yuan, Z. Autoregressive model beats diffusion: Llama for scalable image generation.arXiv preprint arXiv:2406.06525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Hart: Efficient visual generation with hybrid autoregressive transformer
Tang, H., Wu, Y ., Yang, S., Xie, E., Chen, J., Chen, J., Zhang, Z., Cai, H., Lu, Y ., and Han, S. Hart: Efficient visual generation with hybrid autoregressive transformer. arXiv preprint arXiv:2410.10812,
-
[12]
Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding
Teng, Y ., Shi, H., Liu, X., Ning, X., Dai, G., Wang, Y ., Li, Z., and Liu, X. Accelerating auto-regressive text-to-image generation with training-free speculative jacobi decoding. arXiv preprint arXiv:2410.01699,
-
[13]
Wang, J., Tian, Z., Wang, X., Zhang, X., Huang, W., Wu, Z., and Jiang, Y .-G. Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl.arXiv preprint arXiv:2504.11455,
-
[14]
Wu, X., Hao, Y ., Sun, K., Chen, Y ., Zhu, F., Zhao, R., and Li, H. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Yu, J., Xu, Y ., Koh, J. Y ., Luong, T., Baid, G., Wang, Z., Va- sudevan, V ., Ku, A., Yang, Y ., Ayan, B. K., et al. Scaling autoregressive models for content-rich text-to-image gen- eration.arXiv preprint arXiv:2206.10789, 2(3):5,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Zou, C., Liu, X., Liu, T., Huang, S., and Zhang, L. Ac- celerating diffusion transformers with token-wise feature caching.arXiv preprint arXiv:2410.05317,
-
[17]
Derivation of LHEP as a Decoding-free Approximation of Pixel-space Refinement We further elaborate on the pixel-level refinement score introduced in Eq
12 Where to Refine, When to Stop: Rethinking Redundancy via Latent Discrepancy for Efficient Visual Autoregressive Generation A. Derivation of LHEP as a Decoding-free Approximation of Pixel-space Refinement We further elaborate on the pixel-level refinement score introduced in Eq. (6), and show how it leads to a decoding-free latent approximation. Let PΩ ...
1954
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.