nCMD: Benign-Anchored Feature Selection for Imbalanced Network Intrusion Detection
Pith reviewed 2026-06-27 18:39 UTC · model grok-4.3
The pith
Anchoring feature scores to the benign-class mean improves detection of attacks in highly imbalanced network traffic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
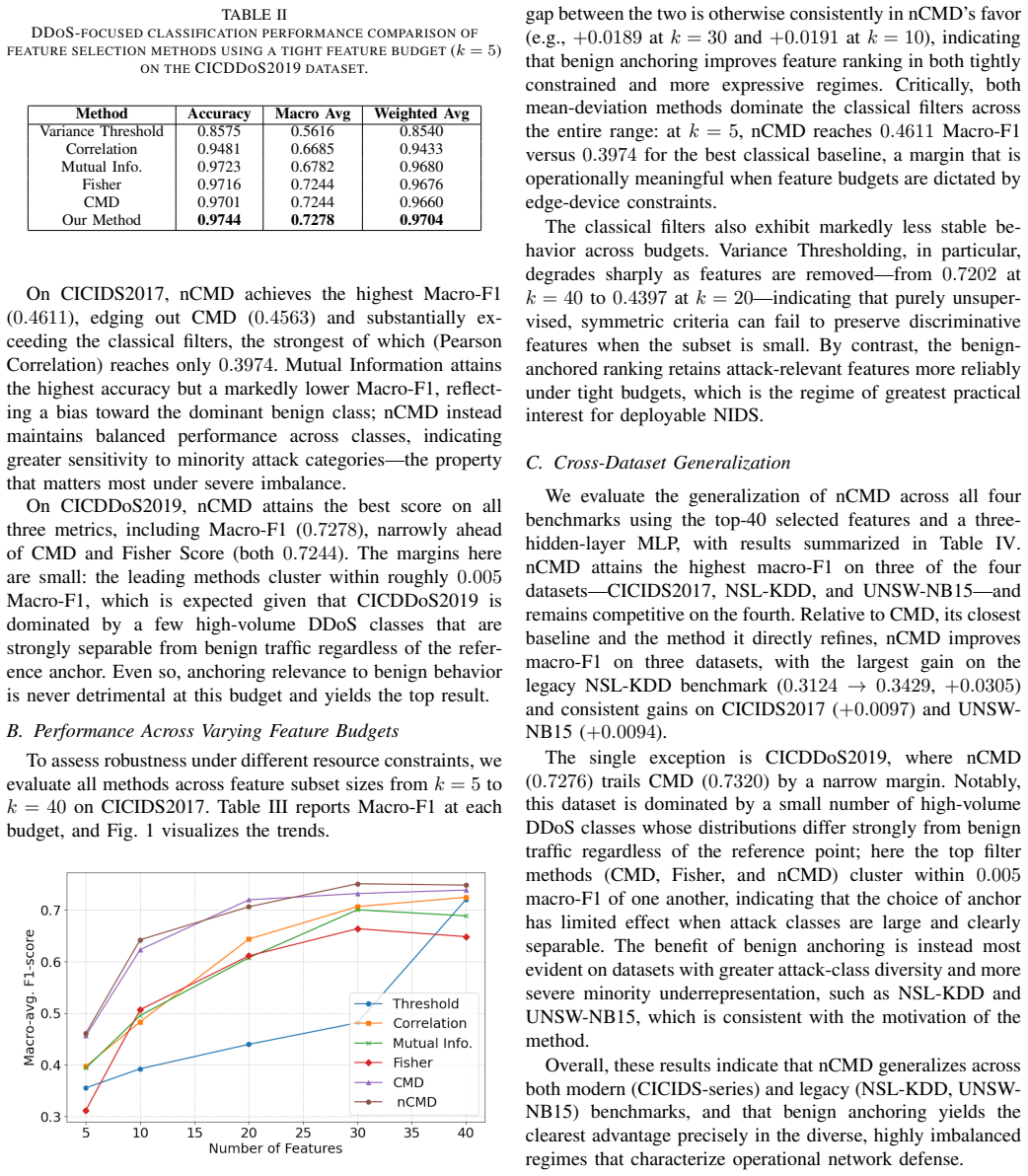
nCMD scores each feature by the classwise mean deviation of the attack distributions from the benign-class mean, rather than from a global or symmetric reference. This produces rankings aligned with the operational reality that attacks are deviations from dominant normal traffic. On CICIDS2017, CICDDoS2019, NSL-KDD and UNSW-NB15, across multiple budgets and three downstream classifiers, the resulting subsets deliver macro-averaged F1 scores that equal or surpass those of classical filter baselines, with the largest margins under tight budgets and severe imbalance.
What carries the argument
benign-anchored Classwise Mean Deviation (nCMD), which computes feature relevance as the deviation of attack-class distributions from the benign-class mean
If this is right
- The method equals or exceeds classical filters on three of four benchmarks under every tested classifier.
- Improvements are largest when feature budgets are small and class imbalance is severe.
- No extra computation is required beyond standard filter ranking.
- The rankings remain interpretable because each score directly quantifies deviation from normal traffic.
Where Pith is reading between the lines
- The same anchoring idea could be tried in other anomaly-detection domains where one class overwhelmingly dominates.
- Live deployment would require checking whether the benign mean drifts over time and how often it must be recomputed.
- Pairing nCMD with a lightweight wrapper stage might further improve results for a chosen classifier.
Load-bearing premise
Deviation of attack classes from the benign mean is the right reference for measuring feature usefulness in real NIDS traffic.
What would settle it
A new collection of imbalanced network traces on which nCMD produces lower macro F1 than the strongest classical filter, under the same budgets and classifiers, would falsify the performance claim.
Figures
read the original abstract
Feature selection is critical for network intrusion detection systems (NIDS) operating under high-dimensional, highly imbalanced traffic, as found in operational and defense networks. Traditional filter methods rank features using global statistics computed symmetrically across classes and thus fail to capture the asymmetry of intrusion detection, where attacks are best characterized as deviations from dominant benign traffic. We propose benign-anchored Classwise Mean Deviation (nCMD), a lightweight and interpretable method that scores feature relevance based on the deviation of attack-class distributions from the benign-class mean, rather than a globally biased reference. This approach aligns feature selection with the operational semantics of NIDS at no additional computational cost. Across four benchmark datasets (CICIDS2017, CICDDoS2019, NSL-KDD, and UNSW-NB15), multiple feature budgets, and three downstream classifiers, nCMD matches or exceeds classical filter baselines in macro-averaged F1-score. It achieves the best result on three of the four datasets and under every classifier, with the strongest improvements observed under tight feature budgets and severe class imbalance. These results support benign-anchored ranking as a scalable and interpretable preprocessing component for resource-constrained NIDS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes benign-anchored Classwise Mean Deviation (nCMD), a lightweight feature selection method that ranks features by the deviation of attack-class distributions from the benign-class mean rather than symmetric global statistics. It evaluates the approach on four benchmark datasets (CICIDS2017, CICDDoS2019, NSL-KDD, UNSW-NB15) across multiple feature budgets and three downstream classifiers, claiming that nCMD matches or exceeds classical filter baselines in macro-averaged F1-score and achieves the best result on three of the four datasets under every classifier, with strongest gains under tight budgets and severe imbalance.
Significance. If the empirical results hold under rigorous verification, the work supplies a simple, interpretable, and zero-extra-cost preprocessing step explicitly aligned with the operational asymmetry of NIDS (benign-dominant traffic). This could be a practical addition to resource-constrained intrusion detection pipelines and illustrates the value of class-specific anchoring over symmetric filters in imbalanced settings.
major comments (1)
- [Evaluation] Evaluation section: the central claim of consistent superiority in macro F1 is presented without statistical significance tests, error bars, explicit dataset splits, or a description of how class imbalance was handled during train/test partitioning and scoring; these omissions prevent independent verification of the reported performance edge.
minor comments (1)
- [Abstract] Abstract: the acronym nCMD is used in the title and text without an immediate parenthetical expansion or the explicit scoring formula.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential contribution and for the constructive comment on evaluation rigor. We address the single major comment point-by-point below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the central claim of consistent superiority in macro F1 is presented without statistical significance tests, error bars, explicit dataset splits, or a description of how class imbalance was handled during train/test partitioning and scoring; these omissions prevent independent verification of the reported performance edge.
Authors: We agree that the original manuscript omitted explicit details on these aspects, which limits independent verification. In the revised version we will: (1) state the exact train/test split ratios and confirm the use of stratified partitioning to preserve class proportions; (2) clarify that no resampling was performed and that macro F1 was chosen precisely to evaluate performance under imbalance; (3) add statistical significance testing (Wilcoxon signed-rank tests across the four datasets for each classifier and budget) together with error bars obtained from five independent random seeds. These additions will be placed in a new subsection of the evaluation and will not alter the core claims or computational profile of nCMD. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines nCMD directly from class means (benign as anchor) and evaluates the resulting feature rankings on four external public benchmark datasets using standard classifiers and F1 metrics. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the provided text. The derivation chain is a straightforward definition plus empirical comparison with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four benchmark datasets (CICIDS2017, CICDDoS2019, NSL-KDD, UNSW-NB15) are representative of real-world imbalanced NIDS traffic
Reference graph
Works this paper leans on
-
[1]
Toward generating a new intrusion detection dataset and intrusion traffic characterization,
I. Sharafaldin, A. H. Lashkari, and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization,” inInternational Conference on Information Systems Security and Privacy, 2018, canadian Institute for Cybersecurity. [Online]. Available: https://api.semanticscholar.org/CorpusID:4707749
2018
-
[2]
Devel- oping realistic distributed denial of service (ddos) attack dataset and taxonomy,
I. Sharafaldin, A. Habibi Lashkari, I. Sahib, and A. Ghorbani, “Devel- oping realistic distributed denial of service (ddos) attack dataset and taxonomy,” inIEEE 53rd International Carnahan Conference on Secu- rity Technology, Chennai, India., 10 2019, pp. 1–8, canadian Institute for Cybersecurity
2019
-
[3]
Outside the closed world: On using machine learning for network intrusion detection,
R. Sommer and V . Paxson, “Outside the closed world: On using machine learning for network intrusion detection,” inIEEE Symposium on Security and Privacy, 2010
2010
-
[4]
Learning from imbalanced data,
H. He and E. A. Garcia, “Learning from imbalanced data,”IEEE Transactions on Knowledge and Data Engineering, vol. 21, no. 9, pp. 1263–1284, 2009
2009
-
[5]
A survey of data mining and machine learning methods for cyber security intrusion detection,
A. L. Buczak and E. Guven, “A survey of data mining and machine learning methods for cyber security intrusion detection,”IEEE Commu- nications Surveys & Tutorials, 2016
2016
-
[6]
Feature selection: A data perspective,
J. Li, K. Cheng, S. Wang, F. Morstatter, R. P. Trevino, J. Tang, and H. Liu, “Feature selection: A data perspective,”ACM Computing Surveys (CSUR), vol. 50, no. 6, p. 94, 2018
2018
-
[7]
On the scalability of feature selection methods on high-dimensional data,
V . Bol ´on-Canedo, D. Rego-Fern ´andez, D. Peteiro-Barral, A. Alonso- Betanzos, B. Guijarro-Berdi ˜nas, and N. S ´anchez-Maro˜no, “On the scalability of feature selection methods on high-dimensional data,”Knowledge and Information Systems, vol. 56, pp. 395– 442, 2018. [Online]. Available: https://link.springer.com/article/10. 1007/s10115-017-1140-3
2018
-
[8]
A survey of network-based intrusion detection data sets,
M. Ring, S. Wunderlich, D. Gr ¨undl, D. Landes, and A. Hotho, “A survey of network-based intrusion detection data sets,”Computers & Security, 2019
2019
-
[9]
A review of feature selection methods based on mutual information,
J. R. Vergara and P. A. Est ´evez, “A review of feature selection methods based on mutual information,”Neural Computing and Applications, vol. 24, pp. 175–186, 2014
2014
-
[10]
Generalized fisher score for feature selection,
Q. Gu, Z. Li, and J. Han, “Generalized fisher score for feature selection,” arXiv preprint arXiv:1202.3725, 2012
Pith/arXiv arXiv 2012
-
[11]
Correlation-based feature selection for machine learning,
M. A. Hall, “Correlation-based feature selection for machine learning,” Ph.D. dissertation, University of Waikato, 1999. [Online]. Available: https://www.lri.fr/ ∼pierres/donnees/save/these/ articles/lpr-queue/hall99correlationbased.pdf
1999
-
[12]
Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min- redundancy,
H. Peng, F. Long, and C. Ding, “Feature selection based on mutual information: Criteria of max-dependency, max-relevance, and min- redundancy,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 27, no. 8, pp. 1226–1238, 2005
2005
-
[13]
Feature se- lection via class-wise mean deviation,
A. F. Ahmad, J. Liu, Q. Gong, S. Misra, and J. Harikumar, “Feature se- lection via class-wise mean deviation,” in2025 International Conference on Machine Learning and Applications (ICMLA), 2025, pp. 698–703
2025
-
[14]
A detailed analysis of the kdd cup 99 data set,
M. Tavallaee, E. Bagheri, W. Lu, and A. A. Ghorbani, “A detailed analysis of the kdd cup 99 data set,” in2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, 2009, pp. 1–6
2009
-
[15]
UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set),
N. Moustafa and J. Slay, “UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set),” in2015 Military Communications and Information Systems Conference (MilCIS). IEEE, 2015, pp. 1–6
2015
-
[16]
Feature selection for network intrusion detection,
C. Westphal, S. Hailes, and M. Musolesi, “Feature selection for network intrusion detection,” inProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .1, ser. KDD ’25. Association for Computing Machinery, 2025, p. 1599–1610. [Online]. Available: https://doi.org/10.1145/3690624.3709339
-
[17]
Variancethreshold — scikit-learn 1.7.0 documentation,
Scikit-learn, “Variancethreshold — scikit-learn 1.7.0 documentation,” 2025, https://scikit-learn.org/stable/modules/generated/sklearn.feature selection.VarianceThreshold.html
2025
-
[18]
Pearson correlation-based feature selection for document classification using balanced training,
I. M. Nasir, M. A. Khan, M. Yasmin, J. H. Shah, M. Gabryel, R. Scherer, and R. Dama ˇseviˇcius, “Pearson correlation-based feature selection for document classification using balanced training,”Sensors, vol. 20, no. 23, p. 6793, 2020. [Online]. Available: https://www.mdpi. com/1424-8220/20/23/6793
2020
-
[19]
Feature selection via mutual information: New theoretical insights,
M. Beraha, A. M. Metelli, M. Papini, A. Tirinzoni, and M. Restelli, “Feature selection via mutual information: New theoretical insights,” arXiv preprint arXiv:1907.07384, 2019
Pith/arXiv arXiv 1907
-
[20]
Scikit-learn: Machine learning in python,
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in python,” pp. 2825–2830, 2011. [Online]. Available: https://scikit-learn.org
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.