Phun-Bench: Evaluating LLMs on Phonological Understanding in Chinese
Pith reviewed 2026-06-27 22:17 UTC · model grok-4.3
The pith
LLMs recall Chinese pronunciations accurately but struggle to apply phonological knowledge flexibly like humans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
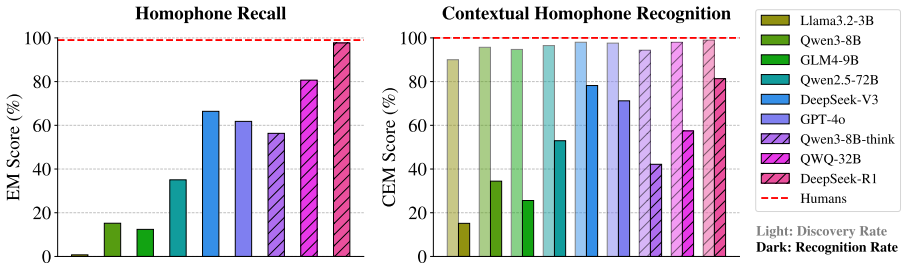
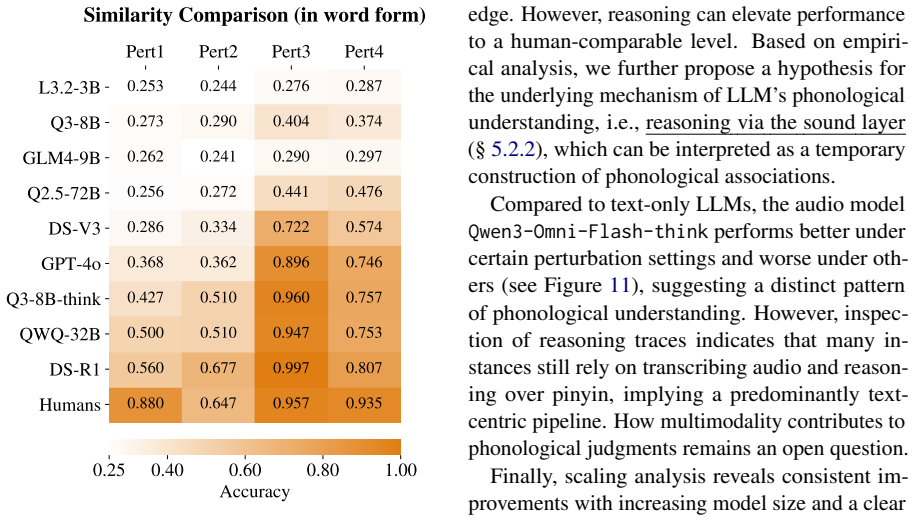
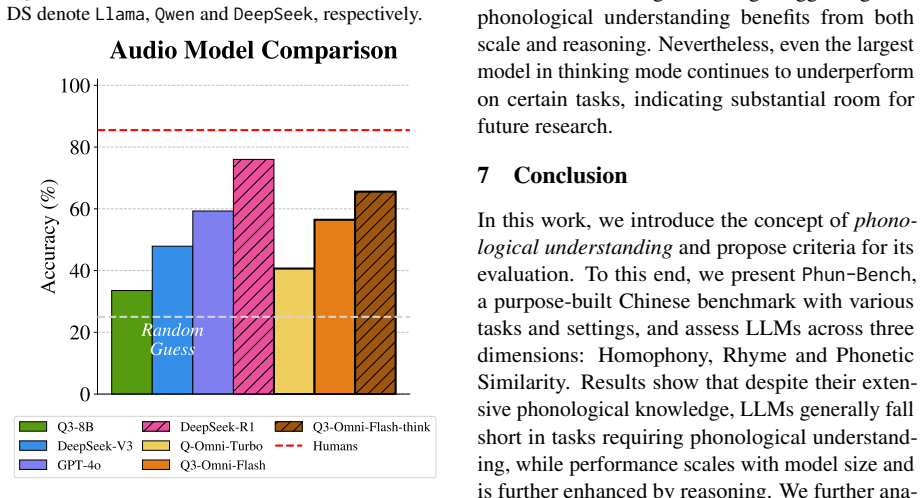
While LLMs excel at recalling correct pronunciations, they generally struggle to leverage phonological knowledge in the flexible and intuitive way that human speakers do.
What carries the argument
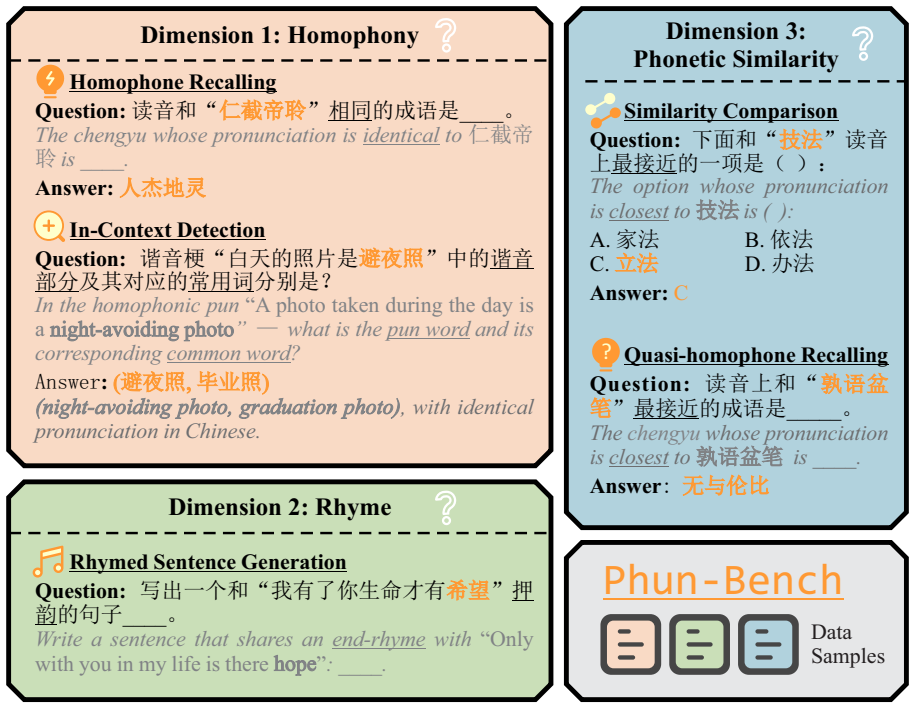
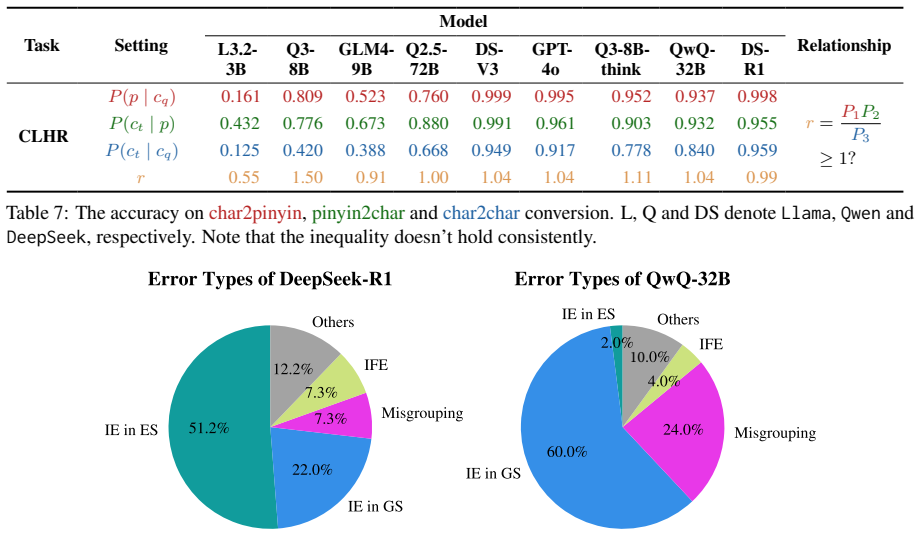
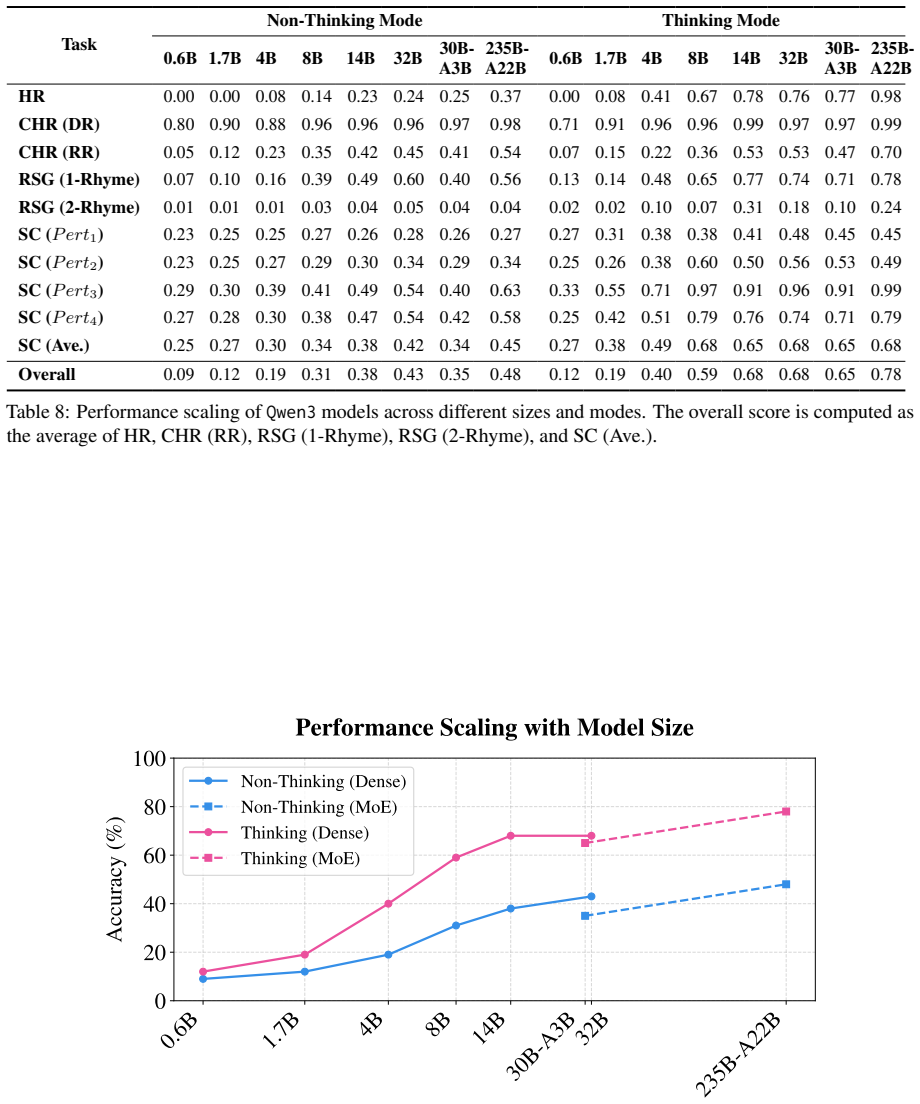
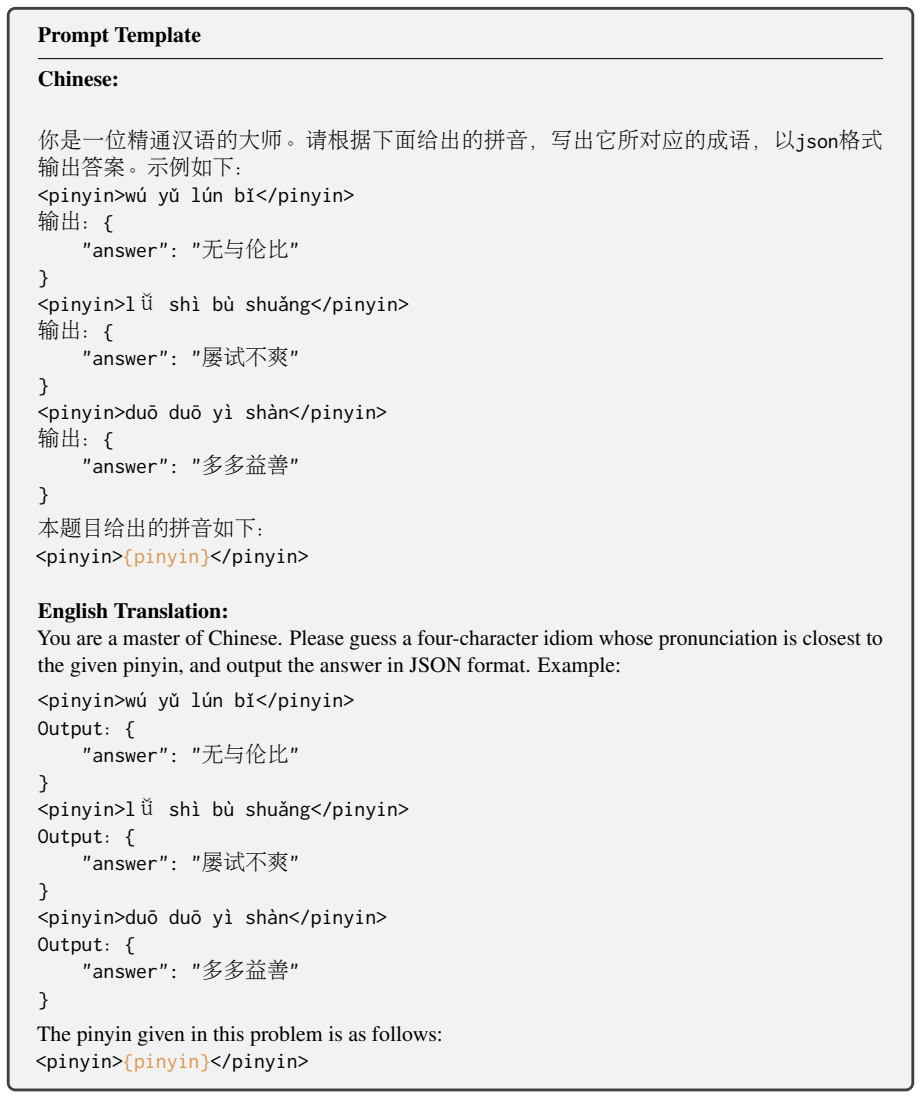
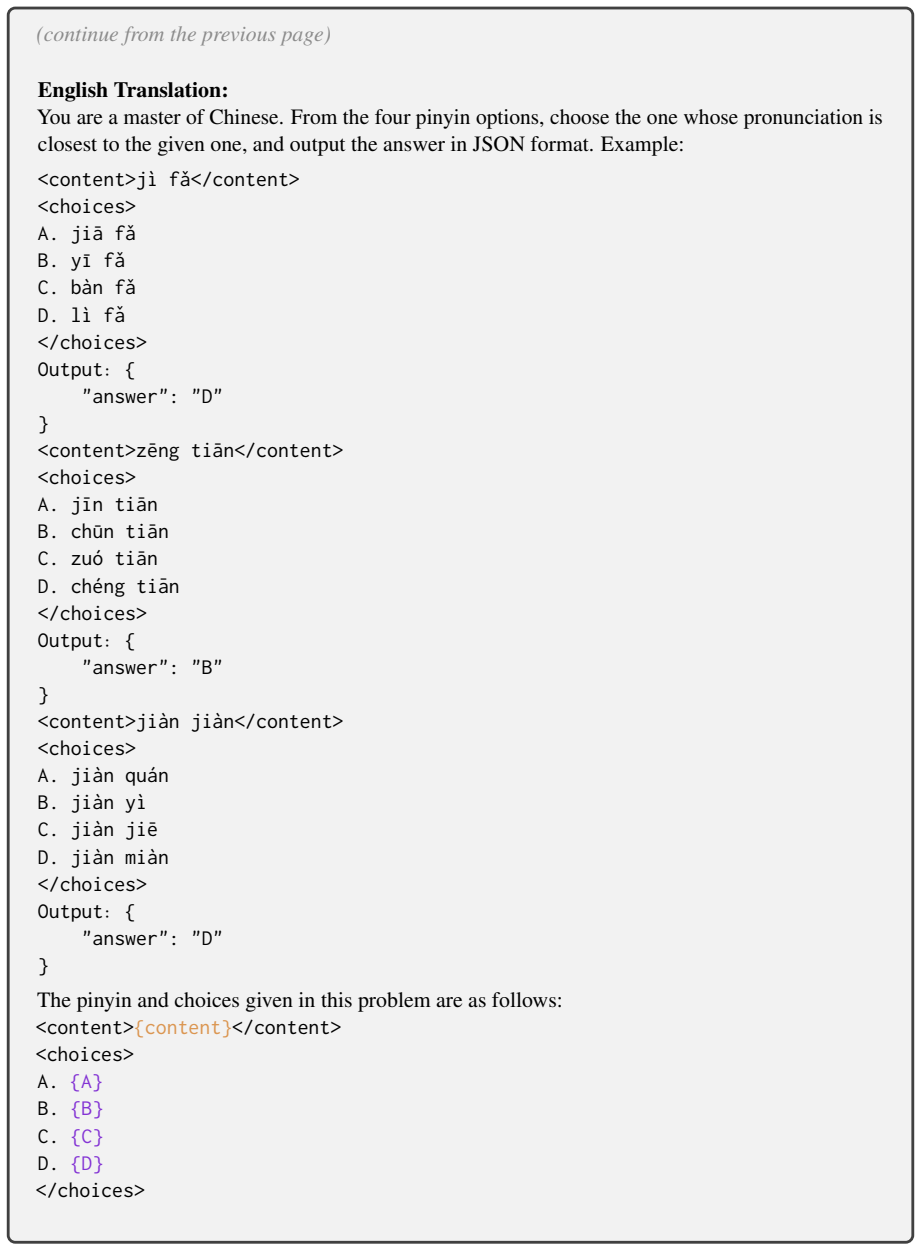
Phun-Bench, a benchmark with diverse tasks and settings across the dimensions of Homophony, Rhyme, and Phonetic Similarity.
If this is right
- LLM training approaches may need to incorporate explicit mechanisms for handling sound patterns beyond recall.
- Evaluation protocols for language models should include tests that separate pronunciation memory from applied phonological reasoning.
- Improvements in phonological handling could enhance model performance on generation tasks that rely on rhyme, homophony, or sound similarity.
- The proposed hypothesis on LLM phonological perception offers a direction for targeted analysis of internal representations.
Where Pith is reading between the lines
- Comparable benchmarks in other languages could test whether the observed gap is specific to Chinese or reflects a broader architectural limit.
- Models that process audio input directly might bypass some of the limitations seen in text-only phonological tasks.
- The gap suggests potential value in hybrid systems that combine symbolic phonological rules with neural learning.
Load-bearing premise
The benchmark tasks isolate genuine phonological understanding and cannot be solved through rote memorization of pronunciations.
What would settle it
An LLM achieving human-level scores on all Phun-Bench tasks while demonstrating non-memorized, flexible application of phonological rules would falsify the central claim of struggle.
Figures




























read the original abstract
Language is a vehicle for thought, intricately tied to sounds, symbols, and meaning. However, most large language model (LLM) research focuses on meaning (semantics) and symbols (spelling) while largely overlooking sounds. Existing benchmarks on LLMs' phonological abilities are either solvable through rote memorization or intertwined with other abilities, making them inadequate to measure LLMs' genuine ability in phonological understanding. Here, we present Phun-Bench, a purpose-built Chinese benchmark with diverse tasks and settings across three dimensions (Homophony, Rhyme, and Phonetic Similarity), designed to systematically evaluate LLMs' phonological understanding. Our results show that while LLMs excel at recalling correct pronunciations, they generally struggle to leverage phonological knowledge in the flexible and intuitive way that human speakers do. Moreover, through detailed analyses, we propose a hypothesis regarding the underlying mechanism of LLMs' phonological understanding and "perception", highlighting an underexplored frontier for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Phun-Bench, a Chinese-language benchmark with tasks across three dimensions (Homophony, Rhyme, Phonetic Similarity) intended to evaluate LLMs' phonological understanding beyond rote memorization. It reports that models recall correct pronunciations effectively but struggle to apply phonological knowledge flexibly in the manner of human speakers, and offers a hypothesis on the underlying mechanism of LLM phonological 'perception' based on detailed analyses.
Significance. If the benchmark tasks genuinely isolate flexible phonological reasoning from semantic, orthographic, or lexical cues, the work would usefully document a limitation in current LLMs and supply an evaluation resource for an underexplored capability. The proposed mechanism hypothesis could stimulate targeted follow-up experiments.
major comments (2)
- [Benchmark construction] Benchmark construction section: the three task dimensions are presented as isolating phonological manipulation, yet the manuscript does not describe explicit controls (e.g., distractors matched on semantics or orthography but differing in phonology, or human baselines restricted to phonological cues). Without such controls, low model performance could arise from failure to exploit non-phonological regularities in the Chinese training distribution rather than from inability to apply phonological knowledge flexibly, directly undermining the central claim.
- [Results and analysis] Results and analysis sections: the reported superiority on pronunciation recall versus the three Phun-Bench dimensions is load-bearing for the 'flexible application' conclusion, but no ablation or error analysis is described that rules out lexical co-occurrence statistics as an alternative explanation for model failures.
minor comments (2)
- [Abstract] The abstract states that existing benchmarks are 'solvable through rote memorization,' but the manuscript does not cite or compare against specific prior phonological benchmarks with quantitative evidence.
- [Benchmark description] Notation for the three dimensions is introduced without a summary table listing task formats, number of items, and example stimuli, which would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help clarify the scope and limitations of our benchmark. We address each major point below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the three task dimensions are presented as isolating phonological manipulation, yet the manuscript does not describe explicit controls (e.g., distractors matched on semantics or orthography but differing in phonology, or human baselines restricted to phonological cues). Without such controls, low model performance could arise from failure to exploit non-phonological regularities in the Chinese training distribution rather than from inability to apply phonological knowledge flexibly, directly undermining the central claim.
Authors: The referee is correct that the current manuscript does not provide an explicit description of controls for semantic or orthographic cues. While the task items were constructed to minimize such confounds through the use of minimal pairs and frequency-matched items, this design rationale is not sufficiently documented. We will revise the benchmark construction section to include a dedicated subsection on controls (e.g., semantic/orthographic distractors and human baselines collected under phonological-only presentation), along with any quantitative verification that non-phonological cues alone do not solve the tasks. revision: yes
-
Referee: [Results and analysis] Results and analysis sections: the reported superiority on pronunciation recall versus the three Phun-Bench dimensions is load-bearing for the 'flexible application' conclusion, but no ablation or error analysis is described that rules out lexical co-occurrence statistics as an alternative explanation for model failures.
Authors: We agree that the absence of targeted ablations leaves open the possibility that model failures reflect lexical co-occurrence patterns rather than a lack of flexible phonological reasoning. In the revision we will add an error-analysis subsection that (1) correlates model errors with lexical n-gram statistics from the training corpus and (2) reports performance on a control set of items matched for co-occurrence but differing in required phonological manipulation. This will allow readers to assess whether the performance gap persists after accounting for statistical regularities. revision: yes
Circularity Check
No derivation chain or fitted quantities; benchmark evaluation is self-contained
full rationale
The paper presents an empirical benchmark (Phun-Bench) for LLM phonological tasks across three dimensions, with results reported directly from model evaluations. No equations, derivations, parameter fittings, or predictions appear in the provided text or abstract. Claims rest on observed performance differences rather than any chain that reduces to self-definition, self-citation, or renamed inputs. The evaluation is therefore self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shiyang Cheng, Pengcheng Zhu, Jueting Liu, and Zehua Wang
ACM. Shiyang Cheng, Pengcheng Zhu, Jueting Liu, and Zehua Wang. 2024. A Survey of Grapheme-to- Phoneme Conversion Methods.Applied Sciences, 14(24):11790. Geoffrey Cideron, Sertan Girgin, Mauro Verzetti, Damien Vincent, Matej Kastelic, Zalán Borsos, Brian McWilliams, Victor Ungureanu, Olivier Bachem, Olivier Pietquin, Matthieu Geist, Léonard Hussenot, Neil...
Pith/arXiv arXiv 2024
-
[2]
Avia Efrat, Or Honovich, and Omer Levy
Deepseek-V3 Technical Report.arXiv.org, abs/2412.19437. Avia Efrat, Or Honovich, and Omer Levy. 2023. LMen- try: A language model benchmark of elementary language tasks. InFindings of the Association for Computational Linguistics: ACL 2023, pages 10476– 10501, Toronto, Canada. Association for Computa- tional Linguistics. Anjie Fang, Simone Filice, Nut Lim...
Pith/arXiv arXiv 2023
-
[3]
Academy & Industry Research Collaboration Center. Jackson L. Lee, Lucas F. E. Ashby, M. Elizabeth Garza, Yeonju Lee-Sikka, Sean Miller, Alan Wong, Arya D. McCarthy, and Kyle Gorman. 2020. Massively Mul- tilingual Pronunciation Modeling with WikiPron. In International Conference on Language Resources and Evaluation (LREC). Shunwei Lei, Yaoxun Xu, Zhiwei Li...
arXiv 2020
-
[4]
Junyu Lu, Bo Xu, Xiaokun Zhang, Changrong Min, Liang Yang, and Hongfei Lin
Comparing Apples to Oranges: A Dataset & Analysis of LLM Humour Understanding from Traditional Puns to Topical Jokes.arXiv. Junyu Lu, Bo Xu, Xiaokun Zhang, Changrong Min, Liang Yang, and Hongfei Lin. 2023. Facilitating fine-grained detection of Chinese toxic language: Hi- erarchical taxonomy, resources, and benchmarks. In Proceedings of the 61st Annual Me...
2023
-
[5]
Ziqian Ning, Huakang Chen, Yuepeng Jiang, Chunbo Hao, Guobin Ma, Shuai Wang, Jixun Yao, and Lei Xie
ACM. Ziqian Ning, Huakang Chen, Yuepeng Jiang, Chunbo Hao, Guobin Ma, Shuai Wang, Jixun Yao, and Lei Xie. 2025. Diffrhythm: Blazingly Fast and Embar- rassingly Simple End-to-End Full-Length Song Gen- eration with Latent Diffusion.arXiv. open-dict data. ipa-dict - monolingual wordlists with pronunciation information in ipa [online]. OpenAI. 2025. Openai o3...
arXiv 2025
-
[6]
SongRewriter: A Chinese song rewriting sys- tem with controllable content and rhyme scheme. In Findings of the Association for Computational Lin- guistics: ACL 2023, pages 12863–12880, Toronto, Canada. Association for Computational Linguistics. Ashima Suvarna, Harshita Khandelwal, and Nanyun Peng. 2024. PhonologyBench: Evaluating phono- logical skills of ...
Pith/arXiv arXiv 2023
-
[7]
“a good pun is its own reword”: Can large language models understand puns? InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 11766–11782, Miami, Florida, USA. Association for Computational Linguistics. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, C...
Pith/arXiv arXiv 2024
-
[8]
一直都这 样孤独地来 去
were developed to generate verses end-to- end, conditioned on stylistic attributes like rhyme and meter. With the advancement of LLMs, poems generated by GPT-3.5 are even rated more favor- ably than human-written ones in certain aspects such as rhythm (Porter and Machery, 2024). Addi- tionally, Chen et al. (2024b) examine diversity in automatic poetry gen...
2024
-
[9]
“案”拼音是an,可能的汉字有案、安、暗等。
-
[10]
“怖”拼音是bu,可能的汉字有怖、布、步等。
-
[11]
“臼”拼音是jiu,可能的汉字有臼、旧、就等。
-
[12]
案”可能对应“安
“颁”拼音是ban,可能的汉字有颁、班、搬等。 接下来,我需要将这些可能的汉字组合成四字成语,并且每个字的拼音要与原短语中的 拼音一致。例如,第一个字是an,第二个是bu,第三个是jiu,第四个是ban。那么可能 的组合是:安布旧班?但这样组合起来似乎没有意义,可能需要调整每个字的可能选 项。 或者,可能每个拼音对应的字不是直接对应,而是每个字的拼音与原短语中的拼音 相同,但字形不同。例如,“案”可能对应“安”,“怖”对应“布”,“臼”对应“旧”,“颁”对 应“班”,这样组合成“安布旧班”,但这样的成语不存在。 可能我需要重新考虑每个拼音对应的字。例如,“案”可能对应“按”,但拼音是an,所 以可能没问题。或者“怖”可能对应“捕”(bu),但拼音是bu,所以可能。然后“臼”可能 对应“就”(jiu),而“...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.