Data Facts: A Metadata Schema for Structured Data Exchange in the NANDini Multi-Agent Ecosystem
Pith reviewed 2026-06-26 01:47 UTC · model grok-4.3
The pith
Data Facts is a JSON metadata schema that lets autonomous agents advertise, verify, and securely exchange datasets via a single registry pointer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
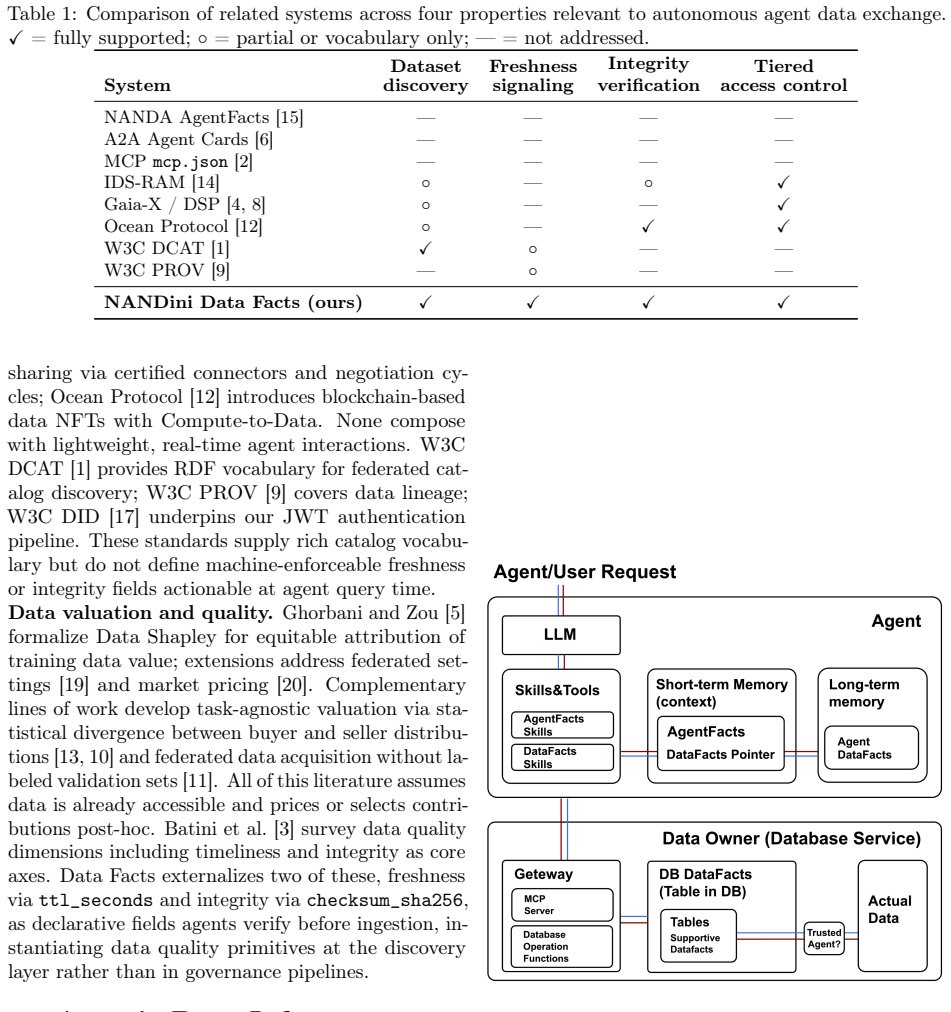
Data Facts is a lightweight JSON metadata schema that encodes dataset identity, access tier (public, semi-private, or private), endpoint, time-to-live for freshness validation, and SHA-256 integrity checksum. It is referenced by adding a data_facts_url pointer to an existing Agent Facts registry record. For private and semi-private data a three-layer security pipeline applies JWT authentication, capability-scoped gateway authorization, and A2A credential delegation. Across 840 decision-making evaluations data-informed agents achieve 100 percent accuracy versus 35.2 percent without data access; TTL enforcement reduces stale-data errors from 37.6 percent to 8.8 percent; checksum verification a
What carries the argument
Data Facts JSON metadata schema, which carries dataset identity, access tier, endpoint, TTL freshness marker, and SHA-256 checksum through a single registry pointer, backed by a three-layer security pipeline of JWT authentication, capability-scoped authorization, and A2A credential delegation.
If this is right
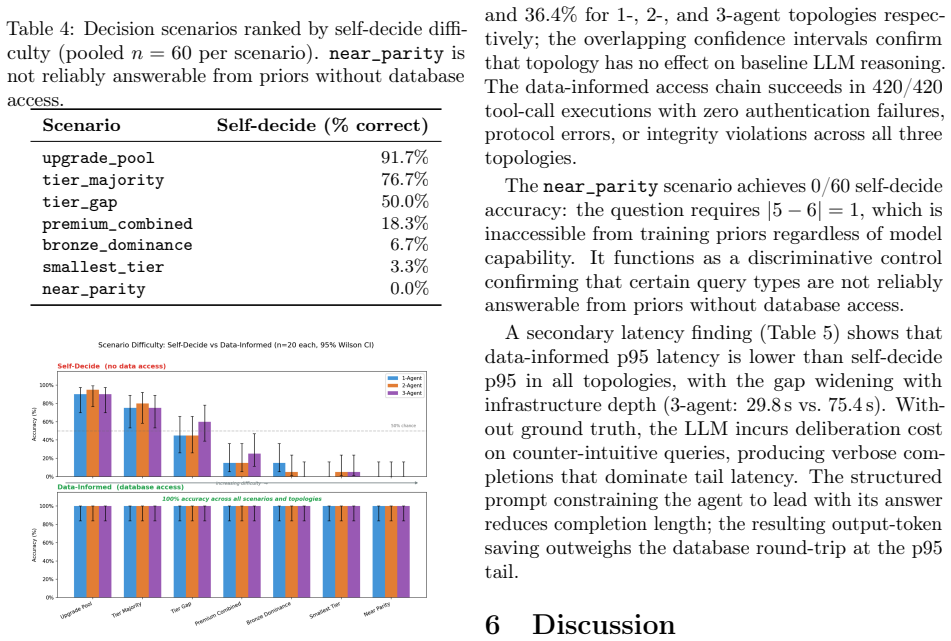
- Agents using Data Facts reach 100 percent accuracy in 840 decision-making evaluations versus 35.2 percent without data access.
- TTL enforcement reduces stale-data errors from 37.6 percent to 8.8 percent.
- SHA-256 checksum verification detects 100 percent of corruptions at all tested injection rates.
- The three-layer security pipeline blocks all 46 forgery attempts with zero data leakage.
Where Pith is reading between the lines
- Standardizing data pointers this way could let separate agent ecosystems interoperate on data discovery without custom integrations.
- The same pointer-plus-checksum pattern might be tested for live sensor or transaction streams where freshness is critical.
- Extending the schema to include usage-cost or provenance metadata would address a natural next requirement for agent marketplaces.
Load-bearing premise
The 840 decision-making evaluations and 46 forgery attempts accurately represent performance in real-world autonomous agent interactions and data scenarios.
What would settle it
A deployment in which data-informed agents fall below 100 percent accuracy or the security pipeline allows even one successful forgery with data leakage would falsify the performance claims.
Figures
read the original abstract
NANDini (Networked Agents Natural Distillation of Interconnected Nodal Intelligence) envisions an automated ecosystem where intelligent agents independently create, process, and exchange data to drive decisions at scale. Realizing this vision requires infrastructure beyond agent discovery and communication: agents must be able to advertise, evaluate, and verify the datasets they hold. Current protocols, including NANDA for federated registry and A2A and MCP for inter-agent messaging, address identity and communication but provide no mechanism for structured data exchange. Existing enterprise data-sharing frameworks, such as IDS-RAM, Gaia-X, and Ocean Protocol, assume human-in-the-loop governance that is incompatible with autonomous, real-time agent interactions. We introduce Data Facts, a core NANDini concept: a lightweight JSON metadata schema that bridges agent discovery and data access through a single pointer, `data_facts_url`, added to an existing Agent Facts registry record. The linked document encodes dataset identity, access tier, whether public, semi-private, or private, endpoint, a time-to-live for freshness validation, and a SHA-256 integrity checksum. For private and semi-private data, we implement a three-layer security pipeline: JWT authentication, capability-scoped gateway authorization, and an A2A credential delegation protocol. Across 840 decision-making evaluations, data-informed agents achieve 100% accuracy versus 35.2% without data access (p < 0.001); TTL enforcement reduces stale-data errors from 37.6% to 8.8%; checksum verification achieves 100% corruption detection at all injection rates; and the security pipeline blocks all 46 forgery attempts with zero data leakage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Data Facts, a lightweight JSON metadata schema for structured data exchange in the NANDini multi-agent ecosystem. It extends existing agent registries (e.g., NANDA) by adding a `data_facts_url` pointer to a document encoding dataset identity, access tier (public/semi-private/private), endpoint, TTL for freshness, and SHA-256 checksum. A three-layer security pipeline (JWT authentication, capability-scoped gateway authorization, A2A credential delegation) is proposed for private data. The authors report results from 840 decision-making evaluations in which data-informed agents reach 100% accuracy versus 35.2% without data access (p < 0.001), TTL enforcement reduces stale-data errors from 37.6% to 8.8%, checksum verification detects 100% of corruption, and the pipeline blocks all 46 forgery attempts with zero leakage.
Significance. If the reported performance gains prove reproducible, the work would address a genuine gap in autonomous agent infrastructure by supplying a machine-to-machine data-verification mechanism absent from NANDA/A2A/MCP and incompatible with human-centric frameworks such as IDS-RAM or Gaia-X. The concrete, pointer-based design and explicit integration with existing registries constitute a practical contribution; the quantitative claims, if supported by transparent methods, would strengthen the case for adoption in multi-agent decision systems.
major comments (1)
- [Abstract] Abstract: the central empirical claims (100% accuracy across 840 evaluations, p < 0.001, zero leakage on 46 forgery attempts, checksum detection at all injection rates) are presented without any description of experimental design, decision tasks, sampling procedure for the 840 instances, baseline agent architecture, data_facts_url consumption mechanism, forgery attack vectors, or the statistical test used. These details are load-bearing for attributing the observed gap to the Data Facts schema rather than unstated simplifications in the test harness.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in the abstract regarding our empirical claims. We address this point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (100% accuracy across 840 evaluations, p < 0.001, zero leakage on 46 forgery attempts, checksum detection at all injection rates) are presented without any description of experimental design, decision tasks, sampling procedure for the 840 instances, baseline agent architecture, data_facts_url consumption mechanism, forgery attack vectors, or the statistical test used. These details are load-bearing for attributing the observed gap to the Data Facts schema rather than unstated simplifications in the test harness.
Authors: We agree that the abstract as submitted omits these methodological details, which limits the ability to evaluate the claims from the abstract alone. The full manuscript contains sections describing the experimental design (including the specific decision tasks, sampling of the 840 instances from a controlled multi-agent simulation environment, baseline agent architecture without data access, the data_facts_url consumption mechanism, the forgery attack vectors consisting of checksum tampering and credential spoofing, and the statistical test used for the p < 0.001 result). To address the concern, we will revise the abstract to include a concise description of the evaluation setup, baseline, attack vectors, and statistical method while respecting length constraints. revision: yes
Circularity Check
No circularity detected in schema definition or performance claims
full rationale
The paper introduces Data Facts as a JSON metadata schema with fields for identity, access tier, endpoint, TTL, and checksum, then adds a data_facts_url pointer to an Agent Facts registry. Performance metrics (100% accuracy, 35.2% baseline, p<0.001, zero leakage on 46 attempts) are explicitly presented as outcomes of separate 840 evaluations and forgery tests rather than being algebraically or definitionally entailed by the schema. No equations, fitted parameters renamed as predictions, self-citations, uniqueness theorems, or ansatzes appear in the text. The chain is schema definition followed by external empirical validation, which remains self-contained and falsifiable outside the schema itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A lightweight JSON metadata document can effectively bridge agent discovery and structured data access
Reference graph
Works this paper leans on
-
[1]
Data catalog vocabulary (DCAT) — version 2
Riccardo Albertoni, David Browning, Simon Cox, Alejandra Gonzalez Beltran, Andrea Perego, and Peter Winstanley. Data catalog vocabulary (DCAT) — version 2. W3C recommendation, World Wide Web Consortium, February 2020
2020
-
[2]
Introducing the model context proto- col
Anthropic. Introducing the model context proto- col. Anthropic Blog, November 2024
2024
-
[3]
Methodologies for data quality assessment and improvement.ACM Computing Surveys, 41(3):16:1–16:52, 2009
Carlo Batini, Cinzia Cappiello, Chiara Fran- calanci, and Andrea Maurino. Methodologies for data quality assessment and improvement.ACM Computing Surveys, 41(3):16:1–16:52, 2009
2009
-
[4]
Gaia-X: Technical architecture
Gaia-X AISBL. Gaia-X: Technical architecture. Technical report, Gaia-X European Association for Data and Cloud, 2021
2021
-
[5]
Data shapley: Equitable valuation of data for machine learn- ing
Amirata Ghorbani and James Zou. Data shapley: Equitable valuation of data for machine learn- ing. InProceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 2242–2251. PMLR, 2019
2019
-
[6]
Announcing the Agent2Agent (A2A) protocol
Google. Announcing the Agent2Agent (A2A) protocol. Google Developers Blog, April 2025
2025
-
[7]
Aafaq Hussain, Junaid Qadir, et al. A survey of agent interoperability protocols: Model Context Protocol (MCP), Agent Communication Proto- col (ACP), Agent-to-Agent Protocol (A2A), and Agent Network Protocol (ANP).arXiv preprint arXiv:2505.02279, 2025
arXiv 2025
-
[8]
Datas- pace protocol specification
International Data Spaces Association. Datas- pace protocol specification. Technical report, IDSA, 2023
2023
-
[9]
PROV-O: The PROV ontology
Timothy Lebo, Satya Sahoo, Deborah McGuin- ness, Khalid Belhajjame, James Cheney, David Corsar, Daniel Garijo, Stian Soiland-Reyes, Stephan Zednik, and Jun Zhao. PROV-O: The PROV ontology. W3C recommendation, World Wide Web Consortium, April 2013
2013
-
[10]
Private data measurements for decentralized data markets
Charles Lu, Mohammad Mohammadi Amiri, and Ramesh Raskar. Private data measurements for decentralized data markets. InICLR 2024 Work- shop on Data-centric Machine Learning Research (DMLR): Harnessing Momentum for Science, 2024
2024
-
[11]
DAVED: Data acquisition via experimental design for data markets
Charles Lu, Baihe Huang, Sai Praneeth Karim- ireddy, Praneeth Vepakomma, Michael Jordan, and Ramesh Raskar. DAVED: Data acquisition via experimental design for data markets. InAd- vances in Neural Information Processing Systems, volume 37, 2024
2024
-
[12]
Ocean protocol: Tools for the Web3 data economy
Trent McConaghy. Ocean protocol: Tools for the Web3 data economy. InHandbook on Blockchain, volume 194 ofSpringer Optimization and Its Ap- plications. Springer, 2022
2022
-
[13]
Fundamentals of task- agnostic data valuation
Mohammad Mohammadi Amiri, Frederic Berdoz, and Ramesh Raskar. Fundamentals of task- agnostic data valuation. InProceedings of the AAAI Conference on Artificial Intelligence, vol- ume 37, pages 9226–9234, 2023
2023
-
[14]
International data spaces: Reference architecture for the digi- tization of industries
Boris Otto, Sebastian Steinbuß, Andreas Teuscher, and Steffen Lohmann. International data spaces: Reference architecture for the digi- tization of industries. InDesigning Data Spaces: The Ecosystem Approach to Competitive Advan- tage. Springer, 2019
2019
-
[15]
Ramesh Raskar, Pradyumna Chari, John Zinky, Mahesh Lambe, Jared James Grogan, Sichao Wang, Rajesh Ranjan, Rekha Singhal, Shailja Gupta, et al. Beyond DNS: Unlocking the internet of AI agents via the NANDA in- dex and verified AgentFacts.arXiv preprint arXiv:2507.14263, 2025
arXiv 2025
-
[16]
Aditi Singh, Abul Ehtesham, Ramesh Raskar, Mahesh Lambe, Pradyumna Chari, Jared James Grogan, Abhishek Singh, and Saket Kumar. Evo- lution of AI agent registry solutions: Centralized, enterprise, and distributed approaches.arXiv preprint arXiv:2508.03095, 2025
arXiv 2025
-
[17]
Decentralizedidentifiers(DIDs)v1.0
Manu Sporny, Dave Longley, Markus Sabadello, Drummond Reed, Orie Steele, and Christopher Allen. Decentralizedidentifiers(DIDs)v1.0. W3C recommendation, World Wide Web Consortium, July 2022
2022
-
[18]
NANDini: Networked agents natural distillation of interconnected nodal intelligence
Tresata. NANDini: Networked agents natural distillation of interconnected nodal intelligence. Tresata AI Blog, 2025. 9
2025
-
[19]
Efficient and fair data valuation for hor- izontal federated learning
Suyi Wei, Yongxin Tong, Zimu Zhou, and Tian- shu Song. Efficient and fair data valuation for hor- izontal federated learning. InFederated Learning: Privacy and Incentive, pages 139–152. Springer, 2020
2020
-
[20]
A survey on data markets.arXiv preprint arXiv:2411.07267, 2024
Jiayao Zhang, Yunshu Bi, Meng Cheng, Ji Liu, Kui Ren, Qiang Sun, Yuncheng Wu, Yang Cao, Raul Castro Fernandez, and Haifeng Xu. A survey on data markets.arXiv preprint arXiv:2411.07267, 2024. 10
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.