Cross-Platform Software Birthmarking for Real-World Binaries via Intermediate Representation
Pith reviewed 2026-06-26 11:48 UTC · model grok-4.3
The pith
Lifting binaries to Ghidra P-code produces birthmarks consistent across CPU architectures with correlation r=0.9846.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
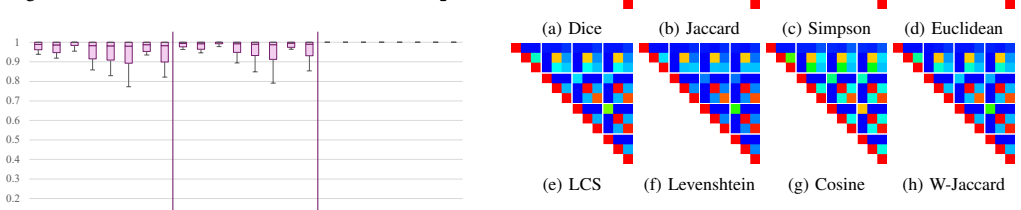
By lifting disparate binary formats into Ghidra P-code, the extracted birthmark features exhibit exceptional consistency across CPU architectures with a correlation of r=0.9846, independent of ISA-specific details, even while a dilution effect from library-derived functions degrades scores in Windows binaries.
What carries the argument
Ghidra P-code intermediate representation, which normalizes binaries from varied formats and architectures to allow feature extraction for birthmarking.
If this is right
- Birthmark comparison becomes possible between binaries compiled for entirely different CPUs without custom per-architecture rules.
- The Simpson index remains effective for ranking similarity even when library noise is present.
- Cross-platform plagiarism checks can be performed on real-world software distributions that mix Windows, Linux, and other binaries.
- The dilution effect requires explicit handling or filtering when Windows binaries are involved.
Where Pith is reading between the lines
- The same lifting approach might generalize to other decompilers if they produce similarly normalized representations.
- This could support malware variant detection where the same code appears on multiple operating systems.
- Further tests on heavily optimized or obfuscated binaries would clarify whether the consistency holds beyond the reported experiments.
Load-bearing premise
Lifting binaries to Ghidra P-code yields features that reflect the original program's identity rather than platform artifacts or library code.
What would settle it
Repeating the experiments on the same set of cross-platform binaries but using a different decompiler or IR and finding similarity correlations drop substantially below r=0.9846.
Figures




read the original abstract
Software birthmarking detects plagiarism through characteristic program features, yet cross-platform resilience remains under-evaluated. This paper proposes a unified birthmarking approach for real-world binaries by lifting disparate formats into a common intermediate representation via Ghidra P-code. Experiments across diverse platforms and languages demonstrate exceptional consistency across CPU architectures ($r=0.9846$), independent of ISA (Instruction Set Architecture) specific details. The study also identifies a ``dilution effect'' in Windows binaries, in which the proliferation of library-derived functions degrades similarity scores. Despite this noise, the Simpson index demonstrates superior discriminative power. These findings clarify the practical capabilities and essential requirements for robust cross-platform birthmarking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes lifting real-world binaries from diverse formats and platforms into Ghidra P-code as a common intermediate representation for software birthmarking. It reports a high cross-architecture correlation (r=0.9846) in the resulting birthmarks, claims this consistency is independent of ISA-specific details, identifies a dilution effect from library code in Windows binaries, and finds the Simpson index to have superior discriminative power.
Significance. If the experimental pipeline proves sound and library-code effects are properly isolated, the IR-lifting approach could offer a practical route to cross-platform birthmarking that is more resilient than platform-specific methods. The choice of Ghidra P-code as a unifying representation is a concrete technical contribution that merits further evaluation.
major comments (2)
- [Abstract] Abstract: the central claim of r=0.9846 consistency 'independent of ISA specific details' is presented without any dataset description, sample sizes, platform/language breakdown, exclusion criteria, or statistical controls, so the reported correlation cannot be evaluated or reproduced from the given information.
- [Abstract] Abstract: the manuscript flags a 'dilution effect' from library-derived functions in Windows binaries but supplies no description of any filtering step (symbol resolution, address-range exclusion, or call-graph pruning) applied during P-code feature extraction; without such a step the high cross-architecture correlation may be driven by shared library implementations rather than program-specific logic.
minor comments (1)
- The abstract would be clearer if it listed the concrete languages, binary formats, and CPU architectures used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment below and will revise the abstract to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of r=0.9846 consistency 'independent of ISA specific details' is presented without any dataset description, sample sizes, platform/language breakdown, exclusion criteria, or statistical controls, so the reported correlation cannot be evaluated or reproduced from the given information.
Authors: The abstract is a concise summary; full details on the dataset (including sample sizes, platform/language breakdown, exclusion criteria, and statistical controls for the correlation) appear in Sections 3 and 4. We agree the abstract would benefit from a brief mention of dataset scale and will revise it accordingly to support evaluation and reproducibility. revision: yes
-
Referee: [Abstract] Abstract: the manuscript flags a 'dilution effect' from library-derived functions in Windows binaries but supplies no description of any filtering step (symbol resolution, address-range exclusion, or call-graph pruning) applied during P-code feature extraction; without such a step the high cross-architecture correlation may be driven by shared library implementations rather than program-specific logic.
Authors: No filtering steps (symbol resolution, address-range exclusion, or call-graph pruning) were applied during P-code feature extraction; the dilution effect is an observed phenomenon in unmodified real-world Windows binaries and is analyzed in the results. We will revise the abstract to state this explicitly and note the potential implications for interpreting the correlation. revision: yes
Circularity Check
No circularity detected; empirical claims rest on independent measurements
full rationale
The paper advances an empirical birthmarking method via Ghidra P-code lifting and reports measured cross-architecture correlation (r=0.9846) plus a dilution effect in Windows binaries. No equations, parameter-fitting steps, self-citations, or uniqueness theorems appear in the provided text that would reduce any claimed result to a redefinition or renaming of its own inputs. The central assertions are grounded in experimental outcomes rather than a closed derivation chain, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Java birthmarks —detecting the software theft —,
H. Tamada, M. Nakamura, A. Monden, and K. Matsumoto, “Java birthmarks —detecting the software theft —,”IEICE Transactions on Information and Systems, vol. E88-D, no. 9, pp. 2148–2158, Sept. 2005
2005
-
[2]
Software birthmark design and estimation: A systematic literature review,
S. Nazir, S. Shahzad, and N. Mukhtar, “Software birthmark design and estimation: A systematic literature review,”Arabian Journal for Science and Engineering, vol. 44, no. 4, pp. 3342–3387, Jan. 2019
2019
-
[3]
LLVM: A compilation framework for lifelong program analysis & transformation,
C. Lattner and V . Adve, “LLVM: A compilation framework for lifelong program analysis & transformation,” inProc. International Symposium on Code Generation and Optimization (CGO 2004), 2004, pp. 75–86
2004
-
[4]
Microsoft portable executable and common object file format specification,
Microsoft Corporation, “Microsoft portable executable and common object file format specification,” 1999. [Online]. Available: https: //learn.microsoft.com/en-us/windows/win32/debug/pe-format
1999
-
[5]
Mach-O runtime architecture,
Apple Inc., “Mach-O runtime architecture,” 2004. [Online]. Available: https://math-atlas.sourceforge.net/devel/assembly/MachORuntime.pdf
2004
-
[6]
Tool interface standard (TIS) executable and linking format (ELF) specification,
T. Committee, “Tool interface standard (TIS) executable and linking format (ELF) specification,” 1995. [Online]. Available: https://refspecs. linuxfoundation.org/elf/elf.pdf
1995
-
[7]
k-gram based software birthmarks,
G. Myles and C. Collberg, “k-gram based software birthmarks,” inProc. 2005 ACM Symposium on Applied Computing (SAC ’05), 2005, pp. 314– 318
2005
-
[8]
A survey of binary code similarity,
I. U. Haq and J. Caballero, “A survey of binary code similarity,”ACM Computing Surveys, vol. 54, no. 3, pp. 1–38, 2021
2021
-
[9]
discovre: Efficient cross-architecture identification of bugs in binary code,
S. Eschweiler, K. Yakdan, and E. Gerhards-Padilla, “discovre: Efficient cross-architecture identification of bugs in binary code,” inProc. 23rd Annual Network and Distributed System Security Symposium (NDSS 2016), 2016
2016
-
[10]
BinGo: Cross-architecture cross-OS binary search,
M. Chandramohan, Y . Xue, Z. Xu, Y . Liu, C. Y . Cho, and H. B. K. Tan, “BinGo: Cross-architecture cross-OS binary search,” inProc. 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE 2016), 2016, pp. 678–689
2016
-
[11]
Code is not natural language: Unlock the power of semantics- oriented graph representation for binary code similarity detection,
H. He, X. Lin, Z. Weng, R. Zhao, S. Gan, L. Chen, Y . Ji, J. Wang, and Z. Xue, “Code is not natural language: Unlock the power of semantics- oriented graph representation for binary code similarity detection,” in Proc. 33rd USENIX Security Symposium, 2024
2024
-
[12]
mituba: Scaling up software theft detection with the search engine,
J. Nakamura and H. Tamada, “mituba: Scaling up software theft detection with the search engine,” inProc. International Conference on Software Engineering and Information Management (ICSIM 2018), 2018, pp. 6–10
2018
-
[13]
BSim: Ghidra behavioral similarity,
National Security Agency, “BSim: Ghidra behavioral similarity,” 2023
2023
-
[14]
Comparison of similarity functions forn-gram software birthmarks,
N. Fedorov, H. Tamada, H. Inayoshi, and A. Monden, “Comparison of similarity functions forn-gram software birthmarks,” inProc. 6th World Symposium on Software Engineering (WSSE 2024), Dec. 2024, pp. 169–176
2024
-
[15]
The hungarian method for the assignment problem,
H. W. Kuhn, “The hungarian method for the assignment problem,”Naval Research Logistics Quarterly, vol. 2, no. 1-2, pp. 83–97, 1955
1955
-
[16]
A shortest augmenting path algorithm for dense and sparse linear assignment problems,
R. Jonker and A. V olgenant, “A shortest augmenting path algorithm for dense and sparse linear assignment problems,”Computing, vol. 38, no. 4, pp. 325–340, 1987
1987
-
[17]
Improvement of the dynamic software birthmark process by reducing the time of the extraction,
T. Yokoi and H. Tamada, “Improvement of the dynamic software birthmark process by reducing the time of the extraction,”International Journal of Networked and Distributed Computing, vol. 6, no. 4, pp. 224–231, Sept. 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.