Learning Agent-Compatible Context Management for Long-Horizon Tasks
Pith reviewed 2026-06-28 22:33 UTC · model grok-4.3
The pith
An external LLM trained with reinforcement learning can manage context for frozen agents on long-horizon tasks without retraining them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
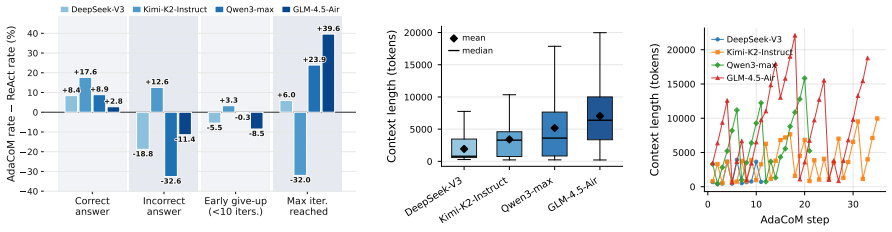
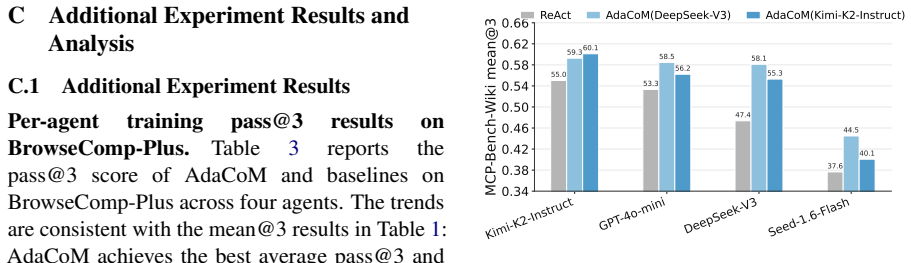
AdaCoM trains an external LLM to manage the context of a frozen agent through flexible modification actions and end-to-end reinforcement learning. Across diverse agents on web search and deep research benchmarks, AdaCoM substantially improves performance by preserving task constraints and progress while pruning stale content. The learned strategies reveal a Fidelity-Reliability Trade-off: agents with higher vanilla ReAct performance benefit from higher-fidelity context preservation, whereas lower-performing agents require more aggressive compression to stay within a reliable reasoning regime. Transfer experiments show that AdaCoM generalizes most effectively across agents with similar capabi
What carries the argument
AdaCoM, an external LLM that applies modification actions to agent context and is trained via end-to-end RL on the agent's task outcomes.
Load-bearing premise
An external LLM can learn generalizable context modification strategies from only the agent's final performance outcomes without access to its internal state or gradients.
What would settle it
If testing AdaCoM on new long-horizon benchmarks with agents of varying capabilities shows no consistent performance gains or reversal of the fidelity-reliability pattern.
Figures


read the original abstract
LLM agents increasingly face long-horizon tasks such as web search and deep research in real-world applications, where accumulated context can cause long-context degradation and reasoning failures. Prior work mitigates this through context management with agent-side context control or fixed strategies such as summarization, which require training the agent itself for adaptation - making it impractical for closed-source agents and ignoring that different agents may require different strategies. We introduce Adaptive Context Management (AdaCoM), which trains an external LLM to manage the context of a frozen agent through flexible modification actions and end-to-end reinforcement learning. Across diverse agents on web search and deep research benchmarks, AdaCoM substantially improves performance by preserving task constraints and progress while pruning stale content. The learned strategies reveal a Fidelity-Reliability Trade-off: agents with higher vanilla ReAct performance benefit from higher-fidelity context preservation, whereas lower-performing agents require more aggressive compression to stay within a reliable reasoning regime. Transfer experiments show that AdaCoM generalizes most effectively across agents with similar capability (measured by vanilla ReAct performance), suggesting a practical path toward reusable context managers for agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Adaptive Context Management (AdaCoM), an external LLM trained via end-to-end reinforcement learning to perform flexible context modifications (preserve constraints/progress, prune stale content) on frozen LLM agents for long-horizon tasks such as web search and deep research. It claims substantial performance gains across diverse agents, identifies a Fidelity-Reliability Trade-off (higher vanilla ReAct agents benefit from high-fidelity preservation; lower-performing agents need aggressive compression), and shows that learned managers transfer best across agents of similar capability.
Significance. If the empirical claims hold with rigorous validation, AdaCoM would provide a practical route to context management for closed-source agents without retraining them and could yield reusable managers for similar-capability agents. The trade-off observation, if reproducible, would be a useful empirical regularity for agent system design.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim of 'substantially improves performance' across agents and benchmarks is stated without any quantitative numbers, error bars, baseline comparisons, or ablation results in the abstract; the reader's report confirms the same absence of verifiable data, so the magnitude and reliability of the gains cannot be assessed.
- [§3] §3 (Method) and skeptic note: the end-to-end RL objective optimizes only against the scalar final-task outcome of a long-horizon trajectory; because the manager has no access to the frozen agent's internal state, hidden activations, or per-step reasoning quality, credit assignment for individual context edits is extremely sparse and delayed, directly undermining the claim that the learned policies reliably discover 'preserve constraints + prune stale' strategies.
- [§4.3] §4.3 (Transfer experiments): the reported generalization 'most effectively across agents with similar capability' is presented as an observed pattern, but without details on how capability similarity was quantified, how many agents were tested, or controls for task difficulty, it is impossible to determine whether the transfer result is robust or an artifact of the chosen agent set.
minor comments (2)
- [§3] Notation for the modification actions and the RL reward formulation should be introduced with explicit equations rather than prose descriptions.
- [§4] Figure captions and axis labels for any performance or trade-off plots need to state the exact metrics, number of runs, and confidence intervals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We will revise the abstract to include quantitative results and update §4.3 with additional experimental details. For the RL credit assignment concern, we will add further analysis while noting the limitations of sparse rewards. Point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim of 'substantially improves performance' across agents and benchmarks is stated without any quantitative numbers, error bars, baseline comparisons, or ablation results in the abstract; the reader's report confirms the same absence of verifiable data, so the magnitude and reliability of the gains cannot be assessed.
Authors: We agree the abstract should report specific numbers to allow immediate assessment of gains. The revised abstract will include key quantitative improvements (e.g., average success rate deltas with standard deviations across agents), baseline comparisons, and references to ablations and error bars already detailed in §4 tables. This directly addresses verifiability without altering the underlying results. revision: yes
-
Referee: [§3] §3 (Method) and skeptic note: the end-to-end RL objective optimizes only against the scalar final-task outcome of a long-horizon trajectory; because the manager has no access to the frozen agent's internal state, hidden activations, or per-step reasoning quality, credit assignment for individual context edits is extremely sparse and delayed, directly undermining the claim that the learned policies reliably discover 'preserve constraints + prune stale' strategies.
Authors: The sparse and delayed nature of the final-outcome reward is inherent to the end-to-end setup and limits direct causal attribution of individual edits. We identify the preserve/prune behaviors via post-hoc inspection of manager actions on held-out trajectories rather than claiming the RL process alone guarantees their discovery. In revision we will add action-frequency statistics and note this limitation explicitly; the cross-agent performance gains remain the primary empirical support. revision: partial
-
Referee: [§4.3] §4.3 (Transfer experiments): the reported generalization 'most effectively across agents with similar capability' is presented as an observed pattern, but without details on how capability similarity was quantified, how many agents were tested, or controls for task difficulty, it is impossible to determine whether the transfer result is robust or an artifact of the chosen agent set.
Authors: We will expand §4.3 to state that capability similarity is quantified by each agent's vanilla ReAct success rate on the identical benchmark tasks. Transfer was evaluated across five agents. All transfer pairs use the same web-search and deep-research task distributions to control difficulty; we will also report a random-pairing control to show the similarity-based pattern exceeds chance. revision: yes
Circularity Check
No significant circularity; empirical RL method with observed trade-off
full rationale
The paper presents an empirical approach: training an external LLM manager via end-to-end RL on downstream agent success for context modifications. No equations, fitted parameters, or derivation chain are described in the provided text. The Fidelity-Reliability Trade-off is reported as an observed pattern across agents, not derived from or equivalent to any input by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on experimental results rather than reducing to self-defined quantities or prior author work by definition. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WebSailor: Navigating Super-human Reasoning for Web Agent
Websailor: Navigating super-human reasoning for web agent.arXiv preprint arXiv:2507.02592. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language models use long contexts.Trans. Assoc. Comput. Linguistics, 12:157–173. Shih-Yang Liu, Xin Dong, Ximing Lu, Shizhe D...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
arXiv preprint arXiv:2508.20453
Mcp-bench: Benchmarking tool-using llm agents with complex real-world tasks via mcp servers. arXiv preprint arXiv:2508.20453. Jason Wei, Zhiqing Sun, Spencer Papay, Scott McK- inney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. 2025. Browsecomp: A simple yet challeng- ing benchmark for browsing agents.a...
-
[3]
Resum: Unlocking long-horizon search in- telligence via context summarization.arXiv preprint arXiv:2509.13313. Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient streaming lan- guage models with attention sinks. InInternational Conference on Learning Representations, volume 2024, pages 21875–21895. Wujiang Xu, Zujie Liang...
-
[4]
Agent Context: The complete context window including the original task description, previous agent actions and results, and any existing summaries or hints from prior rounds
-
[5]
modifications
Token Usage Ratio: Current token usage (0% to 100% scale). {{Background}} Memory Modification Process Follow this reasoning chain: (1)Analyze Context: Understand the task progress and the agent’s goal in the current round. (2)Apply Strategy: Apply the compression strategy to the specific context. Output FormatReturn{"modifications":[]}if no changes are ne...
-
[6]
Extract the final answer primarily from the agent’s final answer field
-
[7]
Use the explanation as supporting context that can clarify, refine, or contradict the final answer
-
[8]
Compare the agent’s overall output with the ground truth answer
-
[9]
The agent’s answer is correctonly ifit is semantically equivalent to the ground truth
-
[10]
Allow for minor variations in phrasing, but the core information must match exactly
-
[11]
For numerical answers, allow small rounding differences (within 1% or 0.1 units)
-
[12]
If the final answer contains additional information that does not contradict the ground truth, it can still be marked as correct
-
[13]
If the final answer is ambiguous, contradictory, or contains incorrect information, mark it as incorrect
-
[14]
extracted_answer
If the agent did not provide a clear final answer, mark it as incorrect. Output Format: Respond with a valid JSON object only (no additional text): { "extracted_answer": "<exact answer extracted from the agent's output, or null>", "ground_truth": "<the ground truth answer>", "reasoning": "<why the answer is correct or incorrect>", "score": 1.0 or 0.0 } Ta...
-
[15]
• 1–3: Perfectly completes 10–30% of requirements
Task fulfillment and quality. • 1–3: Perfectly completes 10–30% of requirements. • 4–6: Perfectly completes 40–60% of requirements. • 7–8: Perfectly completes 70–80% of requirements. • 9–10: Perfectly completes 90–100% of requirements. NOTE: requirements come from the task presented to agent only. Format (JSON/text) isnota requirement unless explicitly st...
-
[16]
• 1–3: 10–30% of claims are perfectly grounded in tool outputs
Grounding. • 1–3: 10–30% of claims are perfectly grounded in tool outputs. • 4–6: 40–60% of claims are perfectly grounded in tool outputs. • 7–8: 70–80% of claims are perfectly grounded in tool outputs. • 9–10: 90–100% of claims are perfectly grounded in tool outputs. Tool usage rubric(1–10 per subdimension)
-
[17]
• 1–3: 10–30% of tools were perfectly selected for their subtasks
Tool appropriateness. • 1–3: 10–30% of tools were perfectly selected for their subtasks. • 4–6: 40–60% of tools were perfectly selected for their subtasks. • 7–8: 70–80% of tools were perfectly selected for their subtasks. • 9–10: 90–100% of tools were perfectly selected for their subtasks
-
[18]
• 1–3: 10–30% of tool calls have perfectly accurate and complete parameters
Parameter accuracy. • 1–3: 10–30% of tool calls have perfectly accurate and complete parameters. • 4–6: 40–60% of tool calls have perfectly accurate and complete parameters. • 7–8: 70–80% of tool calls have perfectly accurate and complete parameters. • 9–10: 90–100% of tool calls have perfectly accurate and complete parameters. Planning effectiveness and ...
-
[19]
• 1–3: 10–30% of dependency chains are perfectly executed
Dependency awareness. • 1–3: 10–30% of dependency chains are perfectly executed. • 4–6: 40–60% of dependency chains are perfectly executed. • 7–8: 70–80% of dependency chains are perfectly executed. • 9–10: 90–100% of dependency chains are perfectly executed
-
[20]
• 1–3: More than 70% of tool calls are redundant or unnecessary
Efficiency. • 1–3: More than 70% of tool calls are redundant or unnecessary. • 4–6: 40–60% of tool calls are redundant or unnecessary. • 7–8: 10–30% of tool calls are redundant or unnecessary. • 9–10: Less than 10% of tool calls are redundant or unnecessary. Percentage-based scoring system. How to calculate scores: for each dimension, calculate the defect...
-
[21]
well executed
When evaluating percentages, assess what counts as “well executed” for each dimension: • Task fulfillment: requirements completed correctly. • Grounding: claims supported by actual tool outputs. • Tool appropriateness: suitable tools chosen for each subtask. • Parameter accuracy: correct and complete parameters in tool calls. • Dependency awareness: prope...
-
[22]
Minor imperfections reduce the percentage proportionally, not to zero
-
[23]
Key principles: 1.Alwayscalculate as percentage,notabsolute numbers
Map the resulting defect rate to the score range above. Key principles: 1.Alwayscalculate as percentage,notabsolute numbers
-
[24]
10 errors in 100 calls (10%)=same score as 1 error in 10 calls (10%)
-
[25]
Use the full 1–10 range
Consider the opportunity count for each dimension: • Tool calls: how many total calls were made? • Parallelization: how many taskscouldhave been parallel? • Parameters: how many total parameters across all calls? • Claims: how many factual statements were made? • Dependencies: how many dependency relationships exist? Score each dimension based on the defe...
-
[26]
For task fulfillment, use chain-of-thought: first listallrequirements from the task, then for each state whether fulfilled with evidence, then count fulfilled/total = percentage, then map to score range
-
[27]
Youmustmap each score to the exact percentage ranges in the rubrics
-
[28]
Task completion and tool usagemustbe evaluated against the concrete task reference, not the fuzzy task
-
[29]
Planning effectiveness should be evaluated based on the proportion of dependencies correctly handled, not the absolute number of steps executed or exact conformance to the dependency analysis
-
[30]
First calculate the actual percentage of completion/success, then assign the corresponding score range
-
[31]
task_fulfillment_reasoning
Focus on completionratiosnot absolute numbers — completing 7/10 steps (70%) should score similarly to completing 14/20 steps (70%), regardless of task complexity. Please score based on completion percentages and proportional success, not absolute numbers. Return your evaluation scoring and reasoning in this exact JSON format.All six numeric score fields (...
-
[32]
Original Question
Relevance is Key: Include only the information that directly or potentially contributes to answering the “Original Question”. Eliminate irrelevant or redundant details. 2.Refine, Don’t Just Append: • Merge: Consolidate new information with existing points to enhance clarity and complete- ness. • Update: Replace general statements with more precise or spec...
-
[33]
No-Change Option: If the new chunk provides no relevant information, simply return the unchanged Existing Reading Note
-
[34]
Avoid summarizing the entire document; this is a working reference, not a comprehensive report
Be Concise: Keep the note succinct, capturing only the most critical and essential facts. Avoid summarizing the entire document; this is a working reference, not a comprehensive report
-
[35]
Updated Reading Note
No Premature Conclusions: Focus strictly on refining the note at each step. Save final judgments or conclusions until all chunks have been processed. Output Format Your response must only consist of the full text of the revised “Updated Reading Note”. Do not write any explanations, commentary, or other additional text. Progress:{{chunk_idx}}out of{{total_...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.