MRI2Rep: Autoregressive Structured Report Generation for 3D Liver MRI
Pith reviewed 2026-06-25 20:53 UTC · model grok-4.3
The pith
An autoregressive model generates LI-RADS structured reports directly from 3D liver MRI volumes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
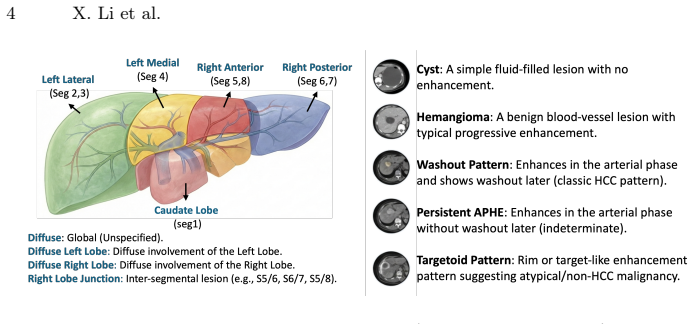
MRI2Rep is the first end-to-end autoregressive system for generating LI-RADS-structured reports from 3D liver MRI. Using 3,929 real-world MRI-report pairs, a Report-to-Label Canonicalization module produces training targets from free-text, enabling the model to reach 76.0 percent case-level sensitivity, 29.4 percent lesion-level F1, and 82.4 percent liver-level accuracy on held-out data, with 70-75 percent of generated reports rated clinically acceptable by radiologists.
What carries the argument
The Report-to-Label Canonicalization (RLC) module that transforms free-text reports into structured, closed-vocabulary diagnostic sequences to supervise the autoregressive vision-to-report model.
If this is right
- Structured LI-RADS reports become available immediately after image acquisition without additional manual dictation.
- Lesion-level detection performance improves over generic vision-language baselines when the training targets are canonicalized sequences.
- An LLM-based judge can serve as a conservative proxy for human reader studies on report quality.
- The same pipeline supplies a scalable route to consistent, machine-readable diagnostic sequences across large retrospective cohorts.
Where Pith is reading between the lines
- The canonicalization step could be reused to create training data for structured reporting in other organs or modalities where only free-text reports exist.
- Performance numbers may shift when the model encounters scanner vendors or patient populations absent from the original 10-year single-site cohort.
- Pairing the generated reports with downstream decision-support tools could standardize care pathways that currently rely on variable free-text documentation.
Load-bearing premise
The Report-to-Label Canonicalization module reliably produces accurate structured sequences from free-text reports without lesion-level annotations, and the single-institution cohort is representative enough for the observed performance to hold more broadly.
What would settle it
Testing the trained model on a multi-institution collection of 3D liver MRI cases and measuring whether case-level sensitivity stays above 70 percent and radiologist acceptability stays above 65 percent.
Figures


read the original abstract
Manual reporting of 3D MRI studies is time-consuming, yet end-to-end structured report generation for 3D liver MRI remains underexplored due to volumetric complexity and scarce paired data. We propose MRI2Rep, an autoregressive framework for liver MRI report generation. From 3,929 real-world MRI-report pairs acquired over a 10-year single-institution cohort, a Report-to-Label Canonicalization (RLC) module converts free-text reports into structured, closed-vocabulary diagnostic sequences without lesion-level annotations. On a held-out test set, MRI2Rep achieves 76.0% case-level sensitivity, 29.4% lesion-level F1, compared with no more than 8.3% for adapted medical vision-language baselines, and 82.4% liver-level accuracy. In a blinded reader study, two radiologists rated 75% and 70% of AI-generated reports as clinically acceptable, compared with 95% and 100% for original reports. Our automated LLM-based judge, LLM-Eval, rated 61.8% of AI-generated reports as acceptable, applying a stricter standard and supporting its use as a conservative proxy. To our knowledge, this is the first end-to-end LI-RADS-structured reporting system for 3D liver MRI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MRI2Rep, an autoregressive framework for end-to-end generation of LI-RADS-structured reports from 3D liver MRI. From 3,929 single-institution MRI-report pairs, a Report-to-Label Canonicalization (RLC) module produces closed-vocabulary diagnostic sequences from free-text reports without lesion-level annotations. On a held-out test set the model reports 76.0% case-level sensitivity, 29.4% lesion-level F1 and 82.4% liver-level accuracy, substantially above adapted vision-language baselines; a blinded reader study finds two radiologists rating 75% and 70% of generated reports clinically acceptable (versus 95-100% for originals), with an LLM-Eval proxy at 61.8%. The work claims to be the first such system for 3D liver MRI.
Significance. If the results hold, the work would be a meaningful advance in medical vision-language modeling by showing that autoregressive generation can produce clinically usable structured reports for volumetric imaging where manual reporting is burdensome. The blinded reader study with two radiologists and the introduction of LLM-Eval as a stricter automated proxy are concrete strengths that provide direct human-grounded evidence beyond automatic metrics.
major comments (2)
- [Methods (RLC module)] Methods section describing the Report-to-Label Canonicalization (RLC) module: no quantitative validation, accuracy metrics, or inter-rater study is reported for the RLC outputs despite their use as both training targets and ground truth for all reported metrics (76.0% sensitivity, 29.4% lesion F1, 82.4% liver accuracy). Systematic mismatches between RLC sequences and true LI-RADS findings would directly corrupt both training and evaluation.
- [Results (Evaluation)] Results (held-out test set evaluation): performance is reported solely on a single-institution 10-year cohort with no external validation set, multi-center testing, or cross-institution RLC fidelity check. Because RLC canonicalization depends on institution-specific report phrasing, this directly limits the strength of the generalization and clinical-utility claims.
minor comments (1)
- [Abstract] Abstract: the phrase 'compared with no more than 8.3% for adapted medical vision-language baselines' does not list the individual baseline scores or adaptation details; adding these would improve transparency without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address each major comment below with honest responses and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Methods (RLC module)] Methods section describing the Report-to-Label Canonicalization (RLC) module: no quantitative validation, accuracy metrics, or inter-rater study is reported for the RLC outputs despite their use as both training targets and ground truth for all reported metrics (76.0% sensitivity, 29.4% lesion F1, 82.4% liver accuracy). Systematic mismatches between RLC sequences and true LI-RADS findings would directly corrupt both training and evaluation.
Authors: We agree this is a valid concern, as the RLC outputs serve as both training targets and evaluation ground truth. The RLC module uses rule-based parsing combined with LI-RADS-specific keyword and phrase matching to convert free-text reports into closed-vocabulary sequences without requiring lesion-level annotations. In the revised manuscript, we will expand the Methods section to provide a detailed description of the RLC rules with illustrative examples. Additionally, we will conduct and report an inter-rater agreement study on a subset of 100 randomly selected reports, comparing RLC outputs against independent manual canonicalization by two radiologists, including accuracy metrics and disagreement analysis. revision: yes
-
Referee: [Results (Evaluation)] Results (held-out test set evaluation): performance is reported solely on a single-institution 10-year cohort with no external validation set, multi-center testing, or cross-institution RLC fidelity check. Because RLC canonicalization depends on institution-specific report phrasing, this directly limits the strength of the generalization and clinical-utility claims.
Authors: We concur that the single-institution nature of the 3,929-pair cohort limits the strength of generalization claims, particularly given potential institution-specific phrasing in reports that affects RLC. Our dataset spans a 10-year period with natural variations in reporting styles, but we lack access to external multi-center datasets due to privacy regulations and data-sharing restrictions. In the revision, we will add an explicit limitations paragraph in the Discussion section acknowledging this constraint, clarifying that all metrics (including 76.0% case-level sensitivity) are cohort-specific, and outlining plans for future multi-center studies. We will also note the RLC's dependence on local report phrasing as a factor requiring site-specific adaptation. revision: partial
Circularity Check
No circularity in derivation or evaluation chain
full rationale
The paper presents an empirical ML pipeline for autoregressive report generation. The RLC module generates training targets from free-text reports, and performance is reported on a held-out test set using those targets. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described process. The central claims rest on standard supervised training and external reader study evaluation rather than any reduction of outputs to inputs by construction. This is the expected non-finding for a data-driven vision-language model paper without mathematical derivation steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic: Claude 3.5 sonnet (2024),https://www.anthropic.com/news/ claude-3-5-sonnet, announcements, Jun 21, 2024
2024
-
[2]
arXiv preprint arXiv:2404.00578 (2024)
Bai, F., Du, Y., Huang, T., Meng, M.Q.H., Zhao, B.: M3d: Advancing 3d medical image analysis with multi-modal large language models. arXiv preprint arXiv:2404.00578 (2024)
arXiv 2024
-
[3]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bassi, P.R., Yavuz, M.C., Hamamci, I.E., Er, S., Chen, X., Li, W., Menze, B., Decherchi, S., Cavalli, A., Wang, K., et al.: Radgpt: Constructing 3d image-text tumor datasets. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 23720–23730 (2025)
2025
-
[4]
Radiology252(2), 458– 467 (2009)
Bhargavan, M., Kaye, A.H., Forman, H.P., Sunshine, J.H.: Workload of radiologists in united states in 2006–2007 and trends since 1991–1992. Radiology252(2), 458– 467 (2009)
2006
-
[5]
https://doi.org/10.48550/arXiv.2406.06512
Blankemeier, L., Cohen, J.P., Kumar, A., Van Veen, D., Gardezi, S.J.S., Paschali, M., Chen, Z., Delbrouck, J.B., Reis, E., Truyts, C., Bluethgen, C., Jensen, M.E.K., Ostmeier, S., Varma, M., Valanarasu, J.M.J., Fang, Z., Huo, Z., Nabulsi, Z., Ardila, D., Weng, W.H., Amaro Junior, E., Ahuja, N., Fries, J., Shah, N.H., Johnston, A., Boutin, R.D., Wentland, ...
-
[6]
arXiv preprint arXiv:2411.05085 (2024)
Castro, D.C., Bustos, A., Bannur, S., et al.: Padchest-gr: A bilingual chest x-ray dataset for grounded radiology report generation. arXiv preprint arXiv:2411.05085 (2024)
arXiv 2024
-
[7]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Chen, Z., Song, Y., Chang, T.H., Wan, X.: Generating radiology reports via memory-driven transformer. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 1439–1449 (2020)
2020
-
[8]
Academic Radiology26(4), 526–533 (2019)
Chetlen, A.L., Chan, T.L., Ballard, D.H., Frigini, L.A., Hildebrand, A., Kim, S., et al.: Addressing burnout in radiologists. Academic Radiology26(4), 526–533 (2019)
2019
-
[9]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Cui, Y., Jia, M., Lin, T.Y., Song, Y., Belongie, S.: Class-balanced loss based on effective number of samples. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
2019
-
[10]
Germain, T., Favelier, S., Cercueil, J.P., Denys, A., Krause, D., Guiu, B.: Liver segmentation: practical tips. Diagnostic and Interventional Imaging95(11), 1003– 1016 (2014).https://doi.org/10.1016/j.diii.2013.12.005
-
[11]
Deng, J., Li, T.-W., Zhang, S., Liu, S., Pan, Y ., Huang, H., Wang, X., Hu, P., Zhang, X., et al
Guo, D., Yang, D., Zhang, H., et al.: Deepseek-r1 incentivizes reasoning in llms through reinforcement learning. Nature645, 633–638 (2025).https://doi.org/ 10.1038/s41586-025-09422-z
-
[12]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI)
Hamamci, I.E., et al.: Ct2rep: Automated radiology report generation for 3d medical imaging. In: International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI). Springer (2024)
2024
-
[13]
arXiv preprint arXiv:2306.06466 (2023) 10 X
Hou, W., Xu, K., Cheng, Y., Li, W., Liu, J.: Organ: Observation-guided radiology report generation via tree reasoning. arXiv preprint arXiv:2306.06466 (2023) 10 X. Li et al
arXiv 2023
-
[14]
In: Proceedings of the AAAI conference on artificial intelligence
Irvin, J., Rajpurkar, P., Ko, M., Yu, Y., Ciurea-Ilcus, S., Chute, C., Marklund, H., Haghgoo, B., Ball, R., Shpanskaya, K., et al.: Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In: Proceedings of the AAAI conference on artificial intelligence. vol. 33, pp. 590–597 (2019)
2019
-
[15]
In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL) (2015)
Iyyer, M., Manjunatha, V., Boyd-Graber, J., Daumé III, H.: Deep unordered com- position rivals syntactic methods for text classification. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL) (2015)
2015
-
[16]
In: Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks)
Jain, S., Agrawal, A., Saporta, A., Truong, S., Duong, D.N., Bui, T., Chambon, P., Zhang, Y., Lungren, M.P., Ng, A.Y., Langlotz, C.P., Rajpurkar, P.: RadGraph: Extracting clinical entities and relations from radiology reports. In: Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks). v...
2021
-
[17]
Justifying recommendations using distantly- labeled reviews and fine-grained aspects
Jing, B., Xie, P., Xing, E.: On the automatic generation of medical imaging reports. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2577–2586. Association for Computa- tional Linguistics, Melbourne, Australia (2018).https://doi.org/10.18653/v1/ P18-1240
-
[18]
Scientific data6(1), 317 (2019)
Johnson, A.E., Pollard, T.J., Berkowitz, S.J., Greenbaum, N.R., Lungren, M.P., Deng, C.y., Mark, R.G., Horng, S.: Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports. Scientific data6(1), 317 (2019)
2019
-
[19]
In: Advances in Neural Information Processing Systems
Kojima, T., Gu, S.S., Reid, M., Matsuo, Y., Iwasawa, Y.: Large language models are zero-shot reasoners. In: Advances in Neural Information Processing Systems. vol. 35, pp. 22199–22213 (2022)
2022
-
[20]
Computer Science Bulletin8(1), 477–489 (2025).https: //doi.org/10.71465/csb178
Liang, J.: Multi-task learning for radiology report generation with structured findings consistency. Computer Science Bulletin8(1), 477–489 (2025).https: //doi.org/10.71465/csb178
-
[21]
Neural Networks p
Lou, M., Ying, H., Liu, X., Zhou, H.Y., Zhang, Y., Yu, Y.: Sdr-former: A siamese dual-resolution transformer for liver lesion classification using 3d multi-phase imag- ing. Neural Networks p. 107228 (2025)
2025
-
[22]
arXiv preprint arXiv:2504.03600 (2025)
Ma, J., Yang, Z., Kim, S., Chen, B., Baharoon, M., Fallahpour, A., Asakereh, R., Lyu, H., Wang, B.: Medsam2: Segment anything in 3d medical images and videos. arXiv preprint arXiv:2504.03600 (2025)
arXiv 2025
-
[23]
OpenAI technical report (2025),https://openai
OpenAI: GPT-5 system card. OpenAI technical report (2025),https://openai. com/index/gpt-5-system-card/
2025
-
[24]
AMIA Summits on Translational Science Proceedings2018, 188 (2018)
Peng, Y., Wang, X., Lu, L., Bagheri, M., Summers, R., Lu, Z.: Negbio: a high- performance tool for negation and uncertainty detection in radiology reports. AMIA Summits on Translational Science Proceedings2018, 188 (2018)
2018
-
[25]
Abdominal Radiology 43(1), 75–81 (2018).https://doi.org/10.1007/s00261-017-1291-4
Santillan, C., Fowler, K., Kono, Y., Chernyak, V.: Li-rads major features: Ct, mri with extracellular agents, and mri with hepatobiliary agents. Abdominal Radiology 43(1), 75–81 (2018).https://doi.org/10.1007/s00261-017-1291-4
-
[26]
Applied Sciences 15(23), 12578 (2025).https://doi.org/10.3390/app152312578
Song, J., Hu, Y., Wang, H., Chen, Y.W.: Liver-vlm: Enhancing focal liver lesion classification with self-supervised vision-language pretraining. Applied Sciences 15(23), 12578 (2025).https://doi.org/10.3390/app152312578
-
[27]
In: Advances in Neural Information Processing Systems (NeurIPS)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 30 (2017)
2017
-
[28]
Wang, L., et al.: A generative vision-language model for holistic pathological as- sessment using preoperative imaging in hepatocellular carcinoma. eBioMedicine 122, 106060 (2025).https://doi.org/10.1016/j.ebiom.2025.106060 MRI2Rep: Structured Report Generation for 3D Liver MRI 11
-
[29]
Medical Image Analysis110, 103992 (2026).https: //doi.org/10.1016/j.media.2026.103992
Wang, S., Safari, M., Li, Q., Chang, C.W., Qiu, R.L.J., Roper, J., Yu, D.S., Yang, X.: Vision foundation model for 3d magnetic resonance imaging segmentation, classification, and registration. Medical Image Analysis110, 103992 (2026).https: //doi.org/10.1016/j.media.2026.103992
-
[30]
Advances in neural information processing systems35, 24824–24837 (2022)
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Xia, F., Chi, E., Le, Q.V., Zhou, D., et al.: Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems35, 24824–24837 (2022)
2022
-
[31]
Nature Communications16(1), 7866 (2025).https://doi.org/10.1038/ s41467-025-62385-7
Wu, C., Zhang, X., Zhang, Y., Hui, H., Wang, Y., Xie, W.: Towards gen- eralist foundation model for radiology by leveraging web-scale 2d&3d medical data. Nature Communications16(1), 7866 (2025).https://doi.org/10.1038/ s41467-025-62385-7
2025
-
[32]
arXiv preprint arXiv:2509.21249 (2025)
Yang,Z.,DSouza,N.,Megyeri,I.,etal.:Decipher-mr:Avision-languagefoundation model for 3d mri representations. arXiv preprint arXiv:2509.21249 (2025)
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.