Listening Like a Judge: A Music-Aware Framework for Automatic Singing Performance Evaluation
Pith reviewed 2026-06-26 00:27 UTC · model grok-4.3
The pith
MusicJudge evaluates singing by aligning lyric blocks with pitch-rhythm fidelity through multi-signal matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
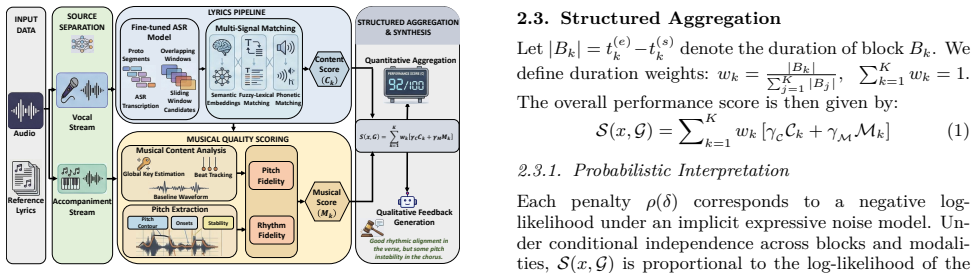
MusicJudge performs block-aligned multimodal analysis by coupling lyric correctness with pitch-rhythm fidelity. It detects semantically meaningful lyric blocks using multi-signal matching that integrates semantic embeddings, lexical similarity, and phonetic alignment. To improve singing audio transcription, it introduces Modality-Guided LoRA for ASR fine-tuning. Experiments across datasets demonstrate strong agreement with human expert judgments and validate the generalizability of the approach.
What carries the argument
Block-aligned multimodal analysis via multi-signal matching of semantic embeddings, lexical similarity, and phonetic alignment, paired with Modality-Guided LoRA for singing transcription.
If this is right
- Singing quality assessment can integrate both lyrical and musical dimensions in aligned blocks rather than treating them separately.
- Lyric blocks can be detected robustly enough to support consistent multimodal scoring across expressive performances.
- Targeted LoRA fine-tuning can enhance transcription accuracy for singing audio.
- The resulting scores generalize across datasets while matching human judgments.
Where Pith is reading between the lines
- The block-alignment technique could extend to automated coaching systems that provide synchronized lyric and pitch feedback.
- Similar multi-signal matching might apply to evaluating other vocal performances such as spoken poetry or rap.
- Real-time versions could be tested on live recordings to check robustness under variable recording conditions.
Load-bearing premise
Multi-signal matching can reliably identify lyric blocks and Modality-Guided LoRA sufficiently improves transcription to allow integration of lyric and musical analysis despite melisma, vibrato, and tempo elasticity.
What would settle it
A held-out singing dataset where multi-signal block detection produces misaligned segments and the overall correlation with human expert scores drops below the levels reported in the paper's experiments.
Figures

read the original abstract
Automatic singing quality assessment (SQA) requires evaluating lyrical correctness and musical fidelity while handling expressive variations. However, existing systems largely rely on either acoustic cues or lyric transcriptions exclusively, limiting holistic performance evaluation. Furthermore, their integration is non-trivial due to challenges in robust singing transcription amid melisma, vibrato, and tempo elasticity. To this end, we propose MusicJudge, a modality-guided framework for automated SQA that performs block-aligned multimodal analysis by coupling lyric correctness with pitch-rhythm fidelity. It detects semantically meaningful lyric blocks using multi-signal matching that integrates semantic embeddings, lexical similarity, and phonetic alignment. To improve singing audio transcription, we introduce Modality-Guided LoRA for ASR fine-tuning. Experiments across datasets demonstrate strong agreement with human expert judgments and validate the generalizability of MusicJudge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MusicJudge, a modality-guided framework for automatic singing quality assessment (SQA) that performs block-aligned multimodal analysis by coupling lyric correctness with pitch-rhythm fidelity. Lyric blocks are detected via multi-signal matching integrating semantic embeddings, lexical similarity, and phonetic alignment; Modality-Guided LoRA is introduced to improve singing audio transcription; and experiments across datasets are stated to demonstrate strong agreement with human expert judgments along with generalizability.
Significance. If the core technical claims hold after verification, the work would advance SQA by enabling integrated evaluation of lyrics and musical fidelity in a single framework, addressing a clear gap in existing single-modality systems. The Modality-Guided LoRA component could prove useful for expressive audio if shown to improve transcription under the cited challenges.
major comments (2)
- [Abstract] Abstract: the load-bearing claim that multi-signal matching (semantic embeddings + lexical similarity + phonetic alignment) reliably detects semantically meaningful lyric blocks is asserted without any reported precision/recall, boundary accuracy, or ablation on expressive subsets exhibiting melisma, vibrato, or tempo elasticity; this directly undermines the multimodal integration step.
- [Abstract] Abstract: the statements of 'strong agreement with human expert judgments' and 'validate the generalizability of MusicJudge' are presented with zero accompanying metrics, baselines, dataset descriptions, or error analysis, so the central empirical claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each major comment below and agree that the abstract would benefit from additional quantitative support to better substantiate the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the load-bearing claim that multi-signal matching (semantic embeddings + lexical similarity + phonetic alignment) reliably detects semantically meaningful lyric blocks is asserted without any reported precision/recall, boundary accuracy, or ablation on expressive subsets exhibiting melisma, vibrato, or tempo elasticity; this directly undermines the multimodal integration step.
Authors: We agree that the abstract asserts the effectiveness of multi-signal matching without supporting metrics. The full manuscript reports precision, recall, and boundary accuracy for lyric block detection in the Experiments section, including results on expressive singing subsets. To directly address the concern, we will revise the abstract to include key quantitative results (e.g., precision/recall figures) and a brief reference to the ablation studies on melisma, vibrato, and tempo variations. revision: yes
-
Referee: [Abstract] Abstract: the statements of 'strong agreement with human expert judgments' and 'validate the generalizability of MusicJudge' are presented with zero accompanying metrics, baselines, dataset descriptions, or error analysis, so the central empirical claim cannot be evaluated.
Authors: We acknowledge that the abstract summarizes the empirical outcomes without specific metrics or dataset details. The manuscript contains these elements in the Experiments section, including correlation metrics with human judgments, baseline comparisons, dataset descriptions, and error analysis. We will revise the abstract to incorporate representative quantitative results (such as agreement scores and generalizability indicators) while respecting length constraints. revision: yes
Circularity Check
No circularity: framework proposal contains no derivations or fitted predictions
full rationale
The paper describes a proposed framework (MusicJudge) that couples lyric and musical analysis via multi-signal block detection and Modality-Guided LoRA, with claims resting on experimental agreement with human judgments. No equations, parameter fits, predictions, or self-citations appear in the provided text that could reduce a result to its own inputs by construction. The load-bearing elements are empirical validation steps rather than self-definitional or fitted-input mechanisms, making the work self-contained on the circularity axis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Singing quality assessment (SQA) is a multifaceted prob- lem involving lyrical accuracy, pitch intonation and rhythmic timing. Human experts evaluate vocal perfor- mances based on correct lyric pronunciation and adher- ence to the underlying melodic and rhythmic structure of the music (e.g., Raag in Indian classical music). How- ever, objecti...
-
[2]
Problem Formulation Let x(t) denote a singing performance waveform defined over t ∈ [0, T ], where T is the total duration. Let arXiv:2606.26451v1 [cs.SD] 24 Jun 2026 Audio Reference Lyrics SOURCE SEPARATION LYRICS PIPELINE Musical Content Analysis MUSICAL QUALITY SCORING Beat Tracking Pitch Extraction Baseline Waveform Rhythm Fidelity Pitch Fidelity Mult...
Pith/arXiv arXiv 2026
-
[3]
Methodology Our framework targets SQA through block-aligned multi- modal analysis, integrating lyrics-aware content scoring and pitch–rhythm modeling as depicted in Fig. 1. 3.1. Dataset Curation and ASR Adaptation To improve lyric transcription robustness, we fine-tune whisper-large-v3 on singing data. Many existing datasets [8, 11] lack pitch-related inf...
-
[4]
Experimental Results Configuration: We conduct experiments on Linux workstation equipped with 2 × NVIDIA Tesla V100- SXM2 GPUs (32 GB each), using GPU accelera- tion for ASR fine-tuning and inference. We fine- tune whisper-large-v3 using parameter-efficient LoRA adapters ( r = 16 , α = 32 , dropout = 0 .05) applied to the attention projection layers ( q_pr...
2048
-
[5]
On SwaraLyrics and SingMOS- Pro, MusicJudge achieves Spearman ρ = 0 .683|0.483, outperforming lyric-only and music-only baselines by +31.9%| + 48.2% and +38.0%|−, respectively
Conclusion We introduce MusicJudge for automatic SQA, provid- ing a practical foundation for assistive training tools, synthetic music evaluation, and scalable judging support in music competitions. On SwaraLyrics and SingMOS- Pro, MusicJudge achieves Spearman ρ = 0 .683|0.483, outperforming lyric-only and music-only baselines by +31.9%| + 48.2% and +38.0...
-
[6]
3.5 (examples presented in Supplementary)
Generative AI Use Disclosure Research usage of gpt-oss-120b is for natural language feedback generation as described in Sec. 3.5 (examples presented in Supplementary). Other generative AI us- age is strictly limited to permitted re-formatting of ta- bles/plots
-
[7]
Automatic evaluation of singing quality without a reference,
C. Gupta, H. Li, and Y. Wang, “Automatic evaluation of singing quality without a reference,” in 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference , 2018, pp. 990–997
2018
-
[8]
Mbnet: Mos prediction for synthesized speech with mean-bias network,
Y. Leng, X. Tan, S. Zhao, F. Soong, X.-Y. Li, and T. Qin, “Mbnet: Mos prediction for synthesized speech with mean-bias network,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Sig- nal Processing. IEEE, 2021, pp. 391–395
2021
-
[9]
Vocal performance evaluation based on bidirec- tional gated recurrent units and caps net,
H. Wu, “Vocal performance evaluation based on bidirec- tional gated recurrent units and caps net,” in 2024 In- ternational Conference on Data Science and Network Security (ICDSNS) , 2024, pp. 1–5
2024
-
[10]
Marble: Mu- sic audio representation benchmark for universal evalua- tion,
R. Yuan, Y. Ma, Y. Li, G. Zhang, X. Chen, H. Yin, Y. Liu, J. Huang, Z. Tian, B. Deng et al. , “Marble: Mu- sic audio representation benchmark for universal evalua- tion,” Advances in Neural Information Processing Sys- tems, vol. 36, pp. 39 626–39 647, 2023
2023
-
[11]
Hclas-x: Hierarchical and cascaded lyrics alignment system using multimodal cross-correlation,
M. Kang, S. Park, and K. Choi, “Hclas-x: Hierarchical and cascaded lyrics alignment system using multimodal cross-correlation,” arXiv preprint arXiv:2307.04377 , 2023
arXiv 2023
-
[12]
Tonality-based accompaniment-guided automatic singing evaluation,
P.-C. Hsieh, Y.-L. Shen, N.-S. Tran, and T.-S. Chi, “Tonality-based accompaniment-guided automatic singing evaluation,” in Proceedings of the Annual Con- ference of the International Speech Communication As- sociation, INTERSPEECH. International Speech Com- munication Association, 2025, pp. 3085–3089
2025
-
[13]
Songtrans: An unified song transcription and alignment method for lyrics and notes,
S. Wu, J. He, R. Yuan, H. Wei, X. Wei, C. Lin, J. Xu, and J. Lin, “Songtrans: An unified song transcription and alignment method for lyrics and notes,” arXiv preprint arXiv:2409.14619, 2024
arXiv 2024
-
[14]
Singmos-pro: An comprehensive bench- mark for singing quality assessment,
Y. Tang, L. Liu, W. Feng, Y. Zhao, J. Han, Y. Yu, J. Shi, and Q. Jin, “Singmos-pro: An comprehensive bench- mark for singing quality assessment,” arXiv preprint arXiv:2510.01812, 2025
arXiv 2025
-
[15]
Automatic estimation of singing voice musical dynam- ics,
J. Narang, N. C. Tamer, V. De La Vega, and X. Serra, “Automatic estimation of singing voice musical dynam- ics,” arXiv preprint arXiv:2410.20540 , 2024
arXiv 2024
-
[16]
Contrastive learning-based audio to lyrics alignment for multiple lan- guages,
S. Durand, D. Stoller, and S. Ewert, “Contrastive learning-based audio to lyrics alignment for multiple lan- guages,” in 2023 IEEE International Conference on Acoustics, Speech and Signal Processing , Rhodes Island, Greece, 2023, pp. 1–5
2023
-
[17]
End-to-end lyrics alignment for polyphonic music using an audio- to-character recognition model,
D. Stoller, S. Durand, and S. Ewert, “End-to-end lyrics alignment for polyphonic music using an audio- to-character recognition model,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 2019, pp. 181–185
2019
-
[18]
Hybrid trans- formers for music source separation,
S. Rouard, F. Massa, and A. Défossez, “Hybrid trans- formers for music source separation,” in ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing . IEEE, 2023, pp. 1–5
2023
-
[19]
Robust speech recogni- tion via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recogni- tion via large-scale weak supervision,” in International conference on machine learning . PMLR, 2023, pp. 28 492–28 518
2023
-
[20]
Pyin: A fundamental fre- quency estimator using probabilistic threshold distribu- tions,
M. Mauch and S. Dixon, “Pyin: A fundamental fre- quency estimator using probabilistic threshold distribu- tions,” in 2014 IEEE International Conference on Acous- tics, Speech and Signal Processing , 2014, pp. 659–663
2014
-
[21]
The proof and measurement of association between two things
C. Spearman, “The proof and measurement of association between two things. ” The American Journal of Psychol- ogy, 1961
1961
-
[22]
A new measure of rank correlation,
M. G. Kendall, “A new measure of rank correlation,” Biometrika, vol. 30, no. 1-2, pp. 81–93, 1938
1938
-
[23]
On the mathematical foundations of theo- retical statistics,
R. A. Fisher, “On the mathematical foundations of theo- retical statistics,” Philosophical transactions of the Royal Society of London. Series A, containing papers of a mathematical or physical character , vol. 222, no. 594- 604, pp. 309–368, 1922
1922
-
[24]
A mathematical examination of the methods of determining the accuracy of observation by the mean er- ror, and by the mean square error,
——, “A mathematical examination of the methods of determining the accuracy of observation by the mean er- ror, and by the mean square error,” Monthly Notices of the Royal Astronomical Society , vol. 80, no. 8, pp. 758– 770, 1920
1920
-
[25]
The influence curve and its role in robust estimation,
F. R. Hampel, “The influence curve and its role in robust estimation,” Journal of the american statistical associa- tion, vol. 69, no. 346, pp. 383–393, 1974
1974
-
[26]
Singmos: An ex- tensive open-source singing voice dataset for mos predic- tion,
Y. Tang, J. Shi, Y. Wu, and Q. Jin, “Singmos: An ex- tensive open-source singing voice dataset for mos predic- tion,” arXiv preprint arXiv:2406.10911 , 2024
arXiv 2024
-
[27]
UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for VoiceMOS Challenge 2022,” in Interspeech 2022 , 2022, pp. 4521–4525
2022
-
[28]
Dnsmos: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors,
C. K. Reddy, V. Gopal, and R. Cutler, “Dnsmos: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Sig- nal Processing. IEEE, 2021, pp. 6493–6497
2021
-
[29]
A sawtooth waveform in- spired pitch estimator for speech and music,
A. Camacho and J. G. Harris, “A sawtooth waveform in- spired pitch estimator for speech and music,” The Jour- nal of the Acoustical Society of America , vol. 124, no. 3, pp. 1638–1652, 2008
2008
-
[30]
Crepe: A convolutional representation for pitch estimation,
J. W. Kim, J. Salamon, P. Li, and J. P. Bello, “Crepe: A convolutional representation for pitch estimation,” in 2018 IEEE international conference on acoustics, speech and signal processing . IEEE, 2018, pp. 161–165
2018
-
[31]
Figures of merit for assessing connected- word recognisers,
M. J. Hunt, “Figures of merit for assessing connected- word recognisers,” Speech Communication, vol. 9, no. 4, pp. 329–336, 1990
1990
-
[32]
From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition,
A. C. Morris, V. Maier, and P. Green, “From WER and RIL to MER and WIL: improved evaluation measures for connected speech recognition,” in Interspeech 2004, 2004, pp. 2765–2768
2004
-
[33]
Hubert: Self- supervised speech representation learning by masked pre- diction of hidden units,
W.-N. Hsu, B. Bolte, Y.-H. H. Tsai, K. Lakhotia, R. Salakhutdinov, and A. Mohamed, “Hubert: Self- supervised speech representation learning by masked pre- diction of hidden units,” IEEE/ACM transactions on au- dio, speech, and language processing , vol. 29, pp. 3451– 3460, 2021
2021
-
[34]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances in neural information processing systems, vol. 33, pp. 12 449–12 460, 2020
2020
-
[35]
gpt-oss-120b & gpt-oss-20b model card,
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y. Bai, B. Baker, H. Bao et al. , “gpt-oss-120b & gpt-oss-20b model card,” arXiv preprint arXiv:2508.10925, 2025
Pith/arXiv arXiv 2025
-
[36]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers,” Advances in neural information processing systems , vol. 33, pp. 5776–5788, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.