Deep Modular Co-Attention Networks for Visual Question Answering
Pith reviewed 2026-05-25 16:17 UTC · model grok-4.3
The pith
Cascading modular co-attention layers achieves 70.63 percent accuracy on visual question answering.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
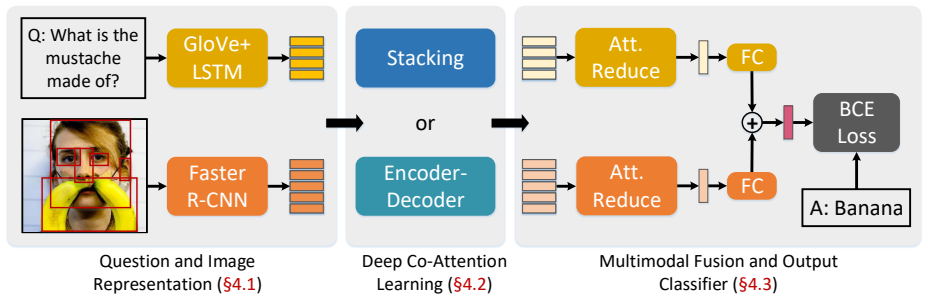
The central claim is that cascading Modular Co-Attention (MCA) layers in depth, where each MCA layer jointly models question self-attention, image self-attention, and question-guided image attention through modular composition of two basic attention units, produces significantly better fine-grained cross-modal associations than shallow co-attention models and reaches 70.63 percent overall accuracy on the VQA-v2 test-dev set.
What carries the argument
The Modular Co-Attention (MCA) layer, which performs self-attention on questions and images plus guided attention using modular composition of two basic attention units.
If this is right
- Deeper stacking of MCA layers improves VQA accuracy over shallow counterparts.
- The modular design enables effective depth without richer cross-modal fusion.
- The approach sets a new state-of-the-art single-model result on VQA-v2.
- Ablation studies isolate the contributions of depth and modularity to the gains.
Where Pith is reading between the lines
- The success of simple modular stacking may reduce the need for complex cross-modal fusion designs in other vision-language tasks.
- Similar modular depth could be tested on related benchmarks such as visual grounding or referring expression comprehension.
- Extending the cascade further might yield additional gains if training stability is maintained.
Load-bearing premise
The assumption that the modular composition of two basic attention units inside each MCA layer is sufficient to capture the fine-grained word-object associations required for VQA.
What would settle it
An experiment in which a non-modular or non-cascaded attention architecture achieves higher than 70.63 percent accuracy on the identical VQA-v2 test-dev split would falsify the central claim.
Figures







read the original abstract
Visual Question Answering (VQA) requires a fine-grained and simultaneous understanding of both the visual content of images and the textual content of questions. Therefore, designing an effective `co-attention' model to associate key words in questions with key objects in images is central to VQA performance. So far, most successful attempts at co-attention learning have been achieved by using shallow models, and deep co-attention models show little improvement over their shallow counterparts. In this paper, we propose a deep Modular Co-Attention Network (MCAN) that consists of Modular Co-Attention (MCA) layers cascaded in depth. Each MCA layer models the self-attention of questions and images, as well as the guided-attention of images jointly using a modular composition of two basic attention units. We quantitatively and qualitatively evaluate MCAN on the benchmark VQA-v2 dataset and conduct extensive ablation studies to explore the reasons behind MCAN's effectiveness. Experimental results demonstrate that MCAN significantly outperforms the previous state-of-the-art. Our best single model delivers 70.63$\%$ overall accuracy on the test-dev set. Code is available at https://github.com/MILVLG/mcan-vqa.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Modular Co-Attention Network (MCAN) for Visual Question Answering, consisting of cascaded Modular Co-Attention (MCA) layers. Each MCA layer models question and image self-attention plus guided cross-attention via a modular composition of two basic attention units. The central empirical claim is that the best single MCAN model reaches 70.63% overall accuracy on the VQA-v2 test-dev set, outperforming prior state-of-the-art, with supporting ablation studies on the architecture and code release.
Significance. If the reported gains hold, the work establishes that deep cascaded co-attention can deliver clear improvements over shallow baselines in VQA through modular attention composition, advancing cross-modal fusion. The extensive ablations and public code release are strengths that enable direct verification of the design choices and support reproducibility.
major comments (2)
- [Abstract] Abstract: the motivation that 'deep co-attention models show little improvement over their shallow counterparts' is stated without quantitative citations or numbers from the referenced prior works; this underpins the need for the proposed depth and modularity.
- [Ablation studies] Experimental results (ablation studies): while the modular composition of two attention units per MCA layer is presented as sufficient for fine-grained associations, the ablations should include a direct control comparing against richer cross-modal fusion mechanisms (e.g., more than two units or alternative connectivity) to confirm this is not an under-capacity design.
minor comments (2)
- [Abstract] The abstract reports the 70.63% figure without error bars, number of runs, or statistical significance tests against the prior SOTA; adding these would strengthen the reliability assessment of the central performance claim.
- [Experiments] Dataset split details and training hyperparameters (e.g., exact VQA-v2 train/val/test-dev partitions and random seeds) are referenced but could be expanded in the experimental section for full reproducibility.
Simulated Author's Rebuttal
Thank you for the positive review and recommendation of minor revision. We appreciate the constructive feedback on the abstract motivation and ablation studies. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the motivation that 'deep co-attention models show little improvement over their shallow counterparts' is stated without quantitative citations or numbers from the referenced prior works; this underpins the need for the proposed depth and modularity.
Authors: We agree that the abstract would be strengthened by quantitative support. The claim draws from the broader literature on co-attention models, but specific numbers and citations were omitted for brevity. In the revision we will update the abstract to include concrete accuracy figures (e.g., from Bottom-Up Top-Down and related shallow vs. deeper baselines) together with the relevant references. revision: yes
-
Referee: [Ablation studies] Experimental results (ablation studies): while the modular composition of two attention units per MCA layer is presented as sufficient for fine-grained associations, the ablations should include a direct control comparing against richer cross-modal fusion mechanisms (e.g., more than two units or alternative connectivity) to confirm this is not an under-capacity design.
Authors: Our existing ablations already examine the effect of stacking MCA layers and varying attention heads, showing consistent gains from the modular two-unit design. Nevertheless, the referee's suggestion for an explicit control against richer per-layer mechanisms is reasonable to further rule out under-capacity. We will add this comparison (more than two units and alternative connectivities) to the ablation section in the revised manuscript. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claim is an empirical accuracy result (70.63% on VQA-v2 test-dev) obtained by training the proposed MCAN architecture of cascaded MCA layers. Each MCA layer is defined as a modular composition of two basic attention units for self-attention and guided-attention. No equations, parameters, or predictions in the manuscript reduce the reported accuracy to a fitted input by construction. No self-citation chain, uniqueness theorem, or ansatz is invoked to force the result; ablations and code release supply independent empirical controls. The derivation chain consists of model design followed by standard supervised training and evaluation, remaining self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of MCA layers
- attention module dimensions and heads
axioms (1)
- domain assumption Attention units can jointly model intra-modal and inter-modal dependencies in vision-language data
Reference graph
Works this paper leans on
-
[1]
Bottom-up and top-down attention for image captioning and visual question answering
Peter Anderson, Xiaodong He, Chris Buehler, Damien Teney, Mark Johnson, Stephen Gould, and Lei Zhang. Bottom-up and top-down attention for image captioning and visual question answering. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages 6077–6086, 2018
work page 2018
-
[2]
Vqa: Visual question answering
Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In International Conference on Computer Vision (ICCV), pages 2425–2433, 2015
work page 2015
-
[3]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450 , 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[5]
Training Deeper Neural Machine Translation Models with Transparent Attention
Ankur Bapna, Mia Xu Chen, Orhan Firat, Yuan Cao, and Yonghui Wu. Training deeper neural machine translation models with transparent attention. arXiv preprint arXiv:1808.07561, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Mutan: Multimodal tucker fusion for visual question answering
Hedi Ben-Younes, R ´emi Cadene, Matthieu Cord, and Nicolas Thome. Mutan: Multimodal tucker fusion for visual question answering. In International Conference on Computer Vision (ICCV), pages 2612–2620, 2017
work page 2017
-
[7]
ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering
Kan Chen, Jiang Wang, Liang-Chieh Chen, Haoyuan Gao, Wei Xu, and Ram Nevatia. Abc-cnn: An attention based convolutional neural network for visual question answering. arXiv preprint arXiv:1511.05960, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
Attention-based models for speech recognition
Jan K Chorowski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyunghyun Cho, and Yoshua Bengio. Attention-based models for speech recognition. In Advances in neural information processing systems (NIPS) , pages 577–585, 2015
work page 2015
-
[9]
Long-term recurrent convolutional networks for visual recognition and description
Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional networks for visual recognition and description. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 2625–2634, 2015
work page 2015
-
[10]
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding
Akira Fukui, Dong Huk Park, Daylen Yang, Anna Rohrbach, Trevor Darrell, and Marcus Rohrbach. Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv preprint arXiv:1606.01847, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6904–6913, 2017
work page 2017
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
work page 2016
-
[13]
Sepp Hochreiter and J ¨urgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997
work page 1997
-
[14]
Jin-Hwa Kim, Jaehyun Jun, and Byoung-Tak Zhang. Bilinear attention networks. Advances in neural information processing systems (NIPS), 2018
work page 2018
-
[15]
Multimodal residual learning for visual qa
Jin-Hwa Kim, Sang-Woo Lee, Donghyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. Multimodal residual learning for visual qa. In Advances in neural information processing systems (NIPS) , pages 361– 369, 2016
work page 2016
-
[16]
Hadamard Product for Low-rank Bilinear Pooling
Jin-Hwa Kim, Kyoung Woon On, Woosang Lim, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. Hadamard Product for Low-rank Bilinear Pooling. In International Conference on Learning Representation (ICLR), 2017
work page 2017
-
[17]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[18]
Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations
Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalan- tidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. arXiv preprint arXiv:1602.07332, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European Conference on Computer Vision (ECCV) , pages 740–755, 2014
work page 2014
-
[20]
Hierarchical question-image co-attention for visual question answering
Jiasen Lu, Jianwei Yang, Dhruv Batra, and Devi Parikh. Hierarchical question-image co-attention for visual question answering. In Advances in neural information processing systems (NIPS), pages 289–297, 2016
work page 2016
-
[21]
A multi-world approach to question answering about real-world scenes based on uncertain input
Mateusz Malinowski and Mario Fritz. A multi-world approach to question answering about real-world scenes based on uncertain input. In Advances in neural information processing systems (NIPS), pages 1682–1690, 2014
work page 2014
-
[22]
Recurrent models of visual attention
V olodymyr Mnih, Nicolas Heess, Alex Graves, et al. Recurrent models of visual attention. In Advances in neural information processing systems (NIPS) , pages 2204–2212, 2014
work page 2014
-
[23]
Dual Attention Networks for Multimodal Reasoning and Matching
Hyeonseob Nam, Jung-Woo Ha, and Jeonghee Kim. Dual attention networks for multimodal reasoning and matching. arXiv preprint arXiv:1611.00471, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[24]
Duy-Kien Nguyen and Takayuki Okatani. Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering.IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 6087–6096, 2018
work page 2018
-
[25]
Glove: Global vectors for word representation
Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In EMNLP, pages 1532–1543, 2014
work page 2014
-
[26]
Faster r-cnn: Towards real-time object detection with region proposal networks
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in neural information processing systems (NIPS), pages 91–99, 2015
work page 2015
-
[27]
Where to look: Focus regions for visual question answering
Kevin J Shih, Saurabh Singh, and Derek Hoiem. Where to look: Focus regions for visual question answering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 4613–4621, 2016
work page 2016
-
[28]
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
Damien Teney, Peter Anderson, Xiaodong He, and Anton van den Hengel. Tips and tricks for visual question answering: Learnings from the 2017 challenge. arXiv preprint arXiv:1708.02711, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems , pages 6000–6010, 2017
work page 2017
-
[30]
Show, attend and tell: Neural image caption generation with visual attention
Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C Courville, Ruslan Salakhutdinov, Richard S Zemel, and Yoshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In International Conference on Machine Learning (ICML), volume 14, pages 77–81, 2015
work page 2015
-
[31]
Stacked attention networks for image question answering
Zichao Yang, Xiaodong He, Jianfeng Gao, Li Deng, and Alex Smola. Stacked attention networks for image question answering. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 21–29, 2016
work page 2016
-
[32]
Multi-modal factorized bilinear pooling with co-attention learning for visual question answering
Zhou Yu, Jun Yu, Jianping Fan, and Dacheng Tao. Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. IEEE International Conference on Computer Vision (ICCV), pages 1839–1848, 2017
work page 2017
-
[33]
Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering
Zhou Yu, Jun Yu, Chenchao Xiang, Jianping Fan, and Dacheng Tao. Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Transactions on Neural Networks and Learning Systems, 29(12):5947–5959, 2018
work page 2018
-
[34]
Zhou Yu, Jun Yu, Chenchao Xiang, Zhou Zhao, Qi Tian, and Dacheng Tao. Rethinking diversified and discriminative proposal generation for visual grounding.International Joint Conference on Artificial Intelligence (IJCAI) , pages 1114– 1120, 2018
work page 2018
-
[35]
Learning to count objects in natural images for visual question answering
Yan Zhang, Jonathon Hare, and Adam Pr ¨ugel-Bennett. Learning to count objects in natural images for visual question answering. International Conference on Learning Representation (ICLR), 2018
work page 2018
-
[36]
Open-ended long- form video question answering via adaptive hierarchical reinforced networks
Zhou Zhao, Zhu Zhang, Shuwen Xiao, Zhou Yu, Jun Yu, Deng Cai, Fei Wu, and Yueting Zhuang. Open-ended long- form video question answering via adaptive hierarchical reinforced networks. In International Joint Conference on Artificial Intelligence (IJCAI), pages 3683–3689, 2018
work page 2018
-
[37]
Simple Baseline for Visual Question Answering
Bolei Zhou, Yuandong Tian, Sainbayar Sukhbaatar, Arthur Szlam, and Rob Fergus. Simple baseline for visual question answering. arXiv preprint arXiv:1512.02167, 2015. Appendix A. Model Ensembling To compare MCAN to the best results on VQA-v2 leaderboard2, we train 4 MCAN ed-6 models with slightly different hyper-parameters for ensemble. The comparative resu...
work page internal anchor Pith review Pith/arXiv arXiv 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.