Does VLA Even Know the Basics? Measuring Commonsense and World Knowledge Retention in Vision-Language-Action Models
Pith reviewed 2026-06-26 20:53 UTC · model grok-4.3
The pith
Vision-language-action models retain commonsense on simple concepts but show larger gaps on richer categories than their source vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
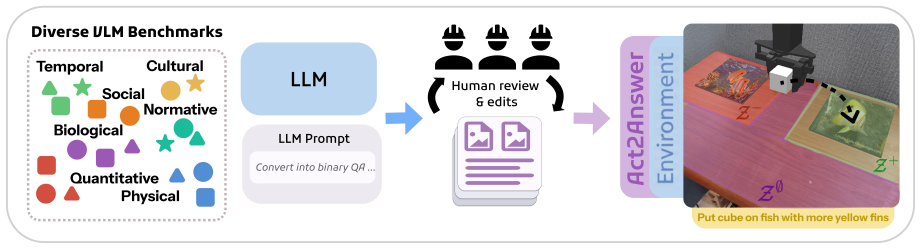
VLAs show solid performance on simple concepts while exhibiting larger gaps on richer semantic categories relative to their source VLMs; VQA co-training is associated with better knowledge retention; and answer-relevant signals peak in middle VLA layers but attenuate in upper layers. These patterns are measured by converting knowledge questions into episodes that require a single object-placement action to select among candidate answers.
What carries the argument
Act2Answer, the protocol that adapts VLM knowledge benchmarks to VLA evaluation by requiring the agent to perform a single object-placement action to indicate the selected answer.
If this is right
- VLAs perform adequately on basic commonsense but lose more ground on complex semantic categories than the VLMs they are derived from.
- Including VQA data during fine-tuning is linked to higher retention rates across the tested categories.
- Answer-relevant information concentrates in the middle layers of the VLM backbone and declines in the upper layers.
- The action-grounded protocol provides a way to rank models by retained knowledge with reduced control confounds.
Where Pith is reading between the lines
- Designers of future VLAs could add objectives that protect middle-layer representations to limit knowledge loss during action fine-tuning.
- The single-action format could be extended to multi-step sequences to test whether retained knowledge supports longer reasoning chains.
- Robotics tasks that depend on factual or commonsense understanding may require explicit selection of VLA checkpoints that score high on Act2Answer-style probes.
- The observed layer attenuation pattern suggests that knowledge extraction methods for VLAs should target intermediate rather than final layers.
Load-bearing premise
That requiring a single object-placement action sufficiently isolates knowledge retention from low-level control confounds so that success rate directly reflects retained information.
What would settle it
A VLA model that fails an Act2Answer episode but correctly answers the identical question when evaluated directly as a VLM would indicate that the failure stems from execution rather than missing knowledge.
Figures






read the original abstract
Embodied Vision-Language-Action (VLA) models are typically obtained by fine-tuning powerful pretrained VLMs on robotics data, yet it is unclear how much commonsense and factual knowledge they retain after adaptation. Failures on knowledge-sensitive tasks are ambiguous, conflating missing knowledge with poor generalization of low-level control. We introduce Act2Answer, a lightweight protocol that adapts VLM knowledge benchmarks to VLA evaluation by requiring agents to answer through action. Each question becomes a short tabletop episode where the agent performs a single object-placement action to select among candidate answers, yielding an action-grounded success rate with reduced control confounds. We curate a test suite of such environments across diverse commonsense and world-knowledge categories and introduce layerwise intent probing to localize answer-relevant information across the VLM backbone and action head. In a large-scale study of 7 VLA models and 9 VLM baselines, we systematically rank models across categories, finding that VLAs show solid performance on simple concepts while exhibiting larger gaps on richer semantic categories relative to their source VLMs, that VQA co-training is associated with better knowledge retention, and that answer-relevant signals peak in middle VLA layers but attenuate in upper layers. Act2Answer is available at https://tttonyalpha.github.io/act2answer/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Act2Answer, a protocol that converts VLM knowledge benchmarks into short tabletop episodes where VLAs answer via a single object-placement action, claiming this yields an action-grounded success rate with reduced control confounds. In a study of 7 VLA models and 9 VLM baselines across commonsense and world-knowledge categories, it reports solid VLA performance on simple concepts but larger gaps on richer semantics relative to source VLMs, better retention with VQA co-training, and answer-relevant signals peaking in middle layers before attenuating in upper layers.
Significance. If the protocol validly isolates retained knowledge, the work provides a practical evaluation method for post-adaptation knowledge in embodied models and identifies actionable patterns (VQA co-training benefits, layerwise localization) that could inform VLA training. The large-scale comparative design across multiple models and categories is a strength.
major comments (1)
- [Abstract] Abstract: The central claim that a single object-placement action produces 'an action-grounded success rate with reduced control confounds' is load-bearing for all reported performance gaps and layerwise findings, yet the description provides no concrete controls (scene randomization, distractor objects, non-semantic baseline comparisons, or statistical tests ruling out placement heuristics and visual shortcuts). Without these, success rates could reflect environmental biases rather than retained VLM knowledge.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for recognizing the potential value of the Act2Answer protocol and the large-scale comparative study. We address the single major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that a single object-placement action produces 'an action-grounded success rate with reduced control confounds' is load-bearing for all reported performance gaps and layerwise findings, yet the description provides no concrete controls (scene randomization, distractor objects, non-semantic baseline comparisons, or statistical tests ruling out placement heuristics and visual shortcuts). Without these, success rates could reflect environmental biases rather than retained VLM knowledge.
Authors: We agree that the abstract is concise and omits explicit mention of the controls. Section 3 of the manuscript details the protocol, including scene randomization across episodes, inclusion of distractor objects, non-semantic baseline comparisons (e.g., random placement and color-based heuristics), and statistical tests (binomial tests and permutation tests) to rule out placement heuristics and visual shortcuts. We will revise the abstract to briefly reference these controls and point to Section 3 for details, ensuring the claim is better supported at the abstract level. revision: yes
Circularity Check
Empirical benchmarking study with no derivation chain
full rationale
The paper introduces an evaluation protocol (Act2Answer) that converts VLM benchmarks into single-action tabletop episodes and reports observed success rates and layerwise probing results across 7 VLAs and 9 VLMs. No equations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described methodology; all claims are framed as direct empirical outcomes rather than reductions to prior inputs by construction. The central assumption about reduced control confounds is an experimental design choice, not a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The curated tabletop episodes accurately map knowledge questions to object-placement actions without introducing new biases or control demands that differ across models.
Reference graph
Works this paper leans on
-
[1]
D'Amato, M. R. and Van Sant, Paul , title =. Journal of Experimental Psychology: Animal Behavior Processes , year =
-
[2]
Learning and Motivation , year =
Bovet, Dalila and Vauclair, Jacques , title =. Learning and Motivation , year =
-
[3]
Animal Cognition , year =
Tanaka, Masayuki , title =. Animal Cognition , year =
-
[4]
Animal Cognition , year =
Range, Friederike and Aust, Ulrike and Steurer, Michael and Huber, Ludwig , title =. Animal Cognition , year =
-
[5]
How to read a picture: Lessons from nonhuman primates , journal =
Fagot, Jo. How to read a picture: Lessons from nonhuman primates , journal =. 2010 , volume =
2010
-
[6]
MLLM-CompBench: A Comparative Reasoning Benchmark for Multimodal LLMs , url =
Kil, Jihyung and Mai, Zheda and Lee, Justin and Chowdhury, Arpita and Wang, Zihe and Cheng, Kerrie and Wang, Lemeng and Liu, Ye and Chao, Wei-Lun , booktitle =. MLLM-CompBench: A Comparative Reasoning Benchmark for Multimodal LLMs , url =
-
[7]
2023 , eprint=
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning , author=. 2023 , eprint=
2023
-
[8]
2022 , eprint=
CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks , author=. 2022 , eprint=
2022
-
[12]
2024 , eprint=
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks , author=. 2024 , eprint=
2024
-
[13]
2024 , eprint=
BEHAVIOR-1K: A Human-Centered, Embodied AI Benchmark with 1,000 Everyday Activities and Realistic Simulation , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
Memory, Benchmark & Robots: A Benchmark for Solving Complex Tasks with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[15]
2025 , eprint=
Bring the Apple, Not the Sofa: Impact of Irrelevant Context in Embodied AI Commands on VLA Models , author=. 2025 , eprint=
2025
-
[16]
Agentic AI in the Wild: From Hallucinations to Reliable Autonomy , year=
Steering Large Language Models Toward Clarification through Sparse Autoencoders , author=. Agentic AI in the Wild: From Hallucinations to Reliable Autonomy , year=
-
[18]
2025 , eprint=
Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization , author=. 2025 , eprint=
2025
-
[19]
2025 , eprint=
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics , author=. 2025 , eprint=
2025
-
[20]
2025 , eprint=
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model , author=. 2025 , eprint=
2025
-
[22]
2024 , eprint=
_0 : A Vision-Language-Action Flow Model for General Robot Control , author=. 2024 , eprint=
2024
-
[23]
2025 , eprint=
Magma: A Foundation Model for Multimodal AI Agents , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
MolmoAct: Action Reasoning Models that can Reason in Space , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
OpenVLA: An Open-Source Vision-Language-Action Model , author=. 2024 , eprint=
2024
-
[26]
2024 , eprint=
Evaluating Real-World Robot Manipulation Policies in Simulation , author=. 2024 , eprint=
2024
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Docvqa: A dataset for vqa on document images , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[29]
2016 , eprint=
A Diagram Is Worth A Dozen Images , author=. 2016 , eprint=
2016
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[32]
The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering , author=. The 36th Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[33]
Conference on Robot Learning , pages=
Rt-2: Vision-language-action models transfer web knowledge to robotic control , author=. Conference on Robot Learning , pages=. 2023 , organization=
2023
-
[39]
arXiv preprint arXiv:2504.16054 , year=
pi\_ \ 0.5 \ : a Vision-Language-Action Model with Open-World Generalization , author=. arXiv preprint arXiv:2504.16054 , year=
-
[40]
Advances in Neural Information Processing Systems , year =
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning , author =. Advances in Neural Information Processing Systems , year =
-
[41]
European Conference on Computer Vision , year =
MMBench: Is Your Multi-modal Model an All-around Player? , author =. European Conference on Computer Vision , year =
-
[42]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
OK-VQA: A Visual Question Answering Benchmark Requiring External Knowledge , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[44]
Optical Memory and Neural Networks , volume=
Spatial traces: Enhancing vla models with spatial-temporal understanding , author=. Optical Memory and Neural Networks , volume=. 2025 , publisher=
2025
-
[45]
Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, Danny Driess, and 1 others. 2025. pi*0.6: a vla that learns from experience. arXiv preprint arXiv:2511.14759
Pith/arXiv arXiv 2025
-
[46]
Alisson Azzolini, Junjie Bai, Hannah Brandon, Jiaxin Cao, Prithvijit Chattopadhyay, Huayu Chen, Jinju Chu, Yin Cui, Jenna Diamond, Yifan Ding, and 1 others. 2025. Cosmos-reason1: From physical common sense to embodied reasoning. arXiv preprint arXiv:2503.15558
Pith/arXiv arXiv 2025
-
[47]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, and 5 others. 2024. https://arxiv.org/abs/2410.24164 _0 : A vision-language-action ...
Pith/arXiv arXiv 2024
-
[49]
Rui Cai, Jun Guo, Xinze He, Piaopiao Jin, Jie Li, Bingxuan Lin, Futeng Liu, Wei Liu, Fei Ma, Kun Ma, and 1 others. 2026 b . Xiaomi-robotics-0: An open-sourced vision-language-action model with real-time execution. arXiv preprint arXiv:2602.12684
arXiv 2026
-
[50]
Xinyi Chen, Yilun Chen, Yanwei Fu, Ning Gao, Jiaya Jia, Weiyang Jin, Hao Li, Yao Mu, Jiangmiao Pang, Yu Qiao, and 1 others. 2025. Internvla-m1: A spatially guided vision-language-action framework for generalist robot policy. arXiv preprint arXiv:2510.13778
Pith/arXiv arXiv 2025
-
[51]
Egor Cherepanov, Nikita Kachaev, Alexey K. Kovalev, and Aleksandr I. Panov. 2025. https://arxiv.org/abs/2502.10550 Memory, benchmark & robots: A benchmark for solving complex tasks with reinforcement learning . Preprint, arXiv:2502.10550
arXiv 2025
-
[52]
Drew A Hudson and Christopher D Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700--6709
2019
-
[53]
Anastasia Ivanova, Bakaeva Eva, Zoya Volovikova, Alexey Kovalev, and Aleksandr Panov. 2025. https://doi.org/10.18653/v1/2025.acl-long.1593 A mbi K : Dataset of ambiguous tasks in kitchen environment . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 33216--33241, Vienna, Austria. Ass...
-
[54]
Nikita Kachaev, Mikhail Kolosov, Daniil Zelezetsky, Alexey K. Kovalev, and Aleksandr I. Panov. 2025. https://arxiv.org/abs/2510.25616 Don't blind your vla: Aligning visual representations for ood generalization . Preprint, arXiv:2510.25616
arXiv 2025
-
[55]
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. 2016. https://arxiv.org/abs/1603.07396 A diagram is worth a dozen images . Preprint, arXiv:1603.07396
Pith/arXiv arXiv 2016
-
[56]
Jihyung Kil, Zheda Mai, Justin Lee, Arpita Chowdhury, Zihe Wang, Kerrie Cheng, Lemeng Wang, Ye Liu, and Wei-Lun Chao. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/file/32923dff09f75cf1974c145764a523e2-Paper-Datasets_and_Benchmarks_Track.pdf Mllm-compbench: A comparative reasoning benchmark for multimodal llms . In Advances in Neural Informa...
2024
-
[57]
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024. https://arxiv.org/abs/2406.09246 Openvla: An open-source vision-language-action m...
Pith/arXiv arXiv 2024
-
[58]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Wensi Ai, Benjamin Martinez, Hang Yin, Michael Lingelbach, Minjune Hwang, Ayano Hiranaka, Sujay Garlanka, Arman Aydin, Sharon Lee, Jiankai Sun, Mona Anvari, and 16 others. 2024 a . https://arxiv.org/abs/2403.09227 Behavior-1k: A human-...
Pith/arXiv arXiv 2024
-
[59]
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. 2024 b . https://arxiv.org/abs/2405.05941 Evaluating real-world robot manipulation policies in simulation . Preprint, arXiv:2405.05941
Pith/arXiv arXiv 2024
-
[60]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. 2023. https://arxiv.org/abs/2306.03310 Libero: Benchmarking knowledge transfer for lifelong robot learning . Preprint, arXiv:2306.03310
Pith/arXiv arXiv 2023
-
[61]
Weiheng Liu, Yuxuan Wan, Jilong Wang, Yuxuan Kuang, Xuesong Shi, Haoran Li, Dongbin Zhao, Zhizheng Zhang, and He Wang. 2025. Fetchbot: Object fetching in cluttered shelves via zero-shot sim2real. arXiv preprint arXiv:2502.17894
arXiv 2025
-
[62]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. 2024. Mmbench: Is your multi-modal model an all-around player? In European Conference on Computer Vision
2024
-
[63]
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering. In The 36th Conference on Neural Information Processing Systems (NeurIPS)
2022
-
[64]
Pan Lu, Liang Qiu, Jiaqi Chen, Tony Xia, Yizhou Zhao, Wei Zhang, Zhou Yu, Xiaodan Liang, and Song-Chun Zhu. 2021. Iconqa: A new benchmark for abstract diagram understanding and visual language reasoning. In Advances in Neural Information Processing Systems. Datasets and Benchmarks Track
2021
-
[65]
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. In IEEE/CVF Conference on Computer Vision and Pattern Recognition
2019
-
[66]
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. 2021. Docvqa: A dataset for vqa on document images. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2200--2209
2021
-
[67]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. 2022. https://arxiv.org/abs/2112.03227 Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks . Preprint, arXiv:2112.03227
arXiv 2022
-
[68]
Maxim A Patratskiy, Alexey K Kovalev, and Aleksandr I Panov. 2025. Spatial traces: Enhancing vla models with spatial-temporal understanding. Optical Memory and Neural Networks, 34(Suppl 1):S72--S82
2025
-
[69]
Alisa Petrova and Alexey Kovalev. 2026. https://openreview.net/forum?id=YBgS2GCqXQ Steering large language models toward clarification through sparse autoencoders . In Agentic AI in the Wild: From Hallucinations to Reliable Autonomy
2026
-
[70]
Daria Pugacheva, Andrey Moskalenko, Denis Shepelev, Andrey Kuznetsov, Vlad Shakhuro, and Elena Tutubalina. 2025. https://arxiv.org/abs/2510.07067 Bring the apple, not the sofa: Impact of irrelevant context in embodied ai commands on vla models . Preprint, arXiv:2510.07067
arXiv 2025
-
[71]
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. 2025. https://arxiv.org/abs/2501.15830 Spatialvla: Exploring spatial representations for visual-language-action model . Preprint, arXiv:2501.15830
Pith/arXiv arXiv 2025
-
[72]
Arth Shukla, Stone Tao, and Hao Su. 2024. Maniskill-hab: A benchmark for low-level manipulation in home rearrangement tasks. arXiv preprint arXiv:2412.13211
arXiv 2024
-
[73]
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, Simon Alibert, Matthieu Cord, Thomas Wolf, and Remi Cadene. 2025. https://arxiv.org/abs/2506.01844 Smolvla: A vision-language-action model for affordable and efficient robotics . Preprint, a...
Pith/arXiv arXiv 2025
-
[74]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards vqa models that can read. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8317--8326
2019
-
[75]
Konstantin Soshin, Alexander Krapukhin, Andrei Spiridonov, Denis Shepelev, Gregorii Bukhtuev, Andrey Kuznetsov, and Vlad Shakhuro. 2025. Robobenchmart: Benchmarking robots in retail environment. arXiv preprint arXiv:2511.10276
Pith/arXiv arXiv 2025
-
[76]
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lars Liden, and Jianfeng Gao. 2025. https://arxiv.org/abs/2502.13130 Magma: A foundation model for multimodal ai agents . Preprint, arXiv:2502.13130
arXiv 2025
-
[77]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, and 1 others. 2024. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556--9567
2024
-
[78]
Jianke Zhang, Xiaoyu Chen, Qiuyue Wang, Mingsheng Li, Yanjiang Guo, Yucheng Hu, Jiajun Zhang, Shuai Bai, Junyang Lin, and Jianyu Chen. 2026. Vlm4vla: Revisiting vision-language-models in vision-language-action models. arXiv preprint arXiv:2601.03309
Pith/arXiv arXiv 2026
-
[79]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. 2024. https://arxiv.org/abs/2412.18194 Vlabench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks . Preprint, arXiv:2412.18194
arXiv 2024
-
[80]
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, and 1 others. 2023. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165--2183. PMLR
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.