Escaping the Self-Confirmation Trap: An Execute-Distill-Verify Paradigm for Agentic Experience Learning
Pith reviewed 2026-06-25 23:47 UTC · model grok-4.3
The pith
Decoupling execution, distillation and verification across agents prevents self-confirmation of mistaken trajectories in experience learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
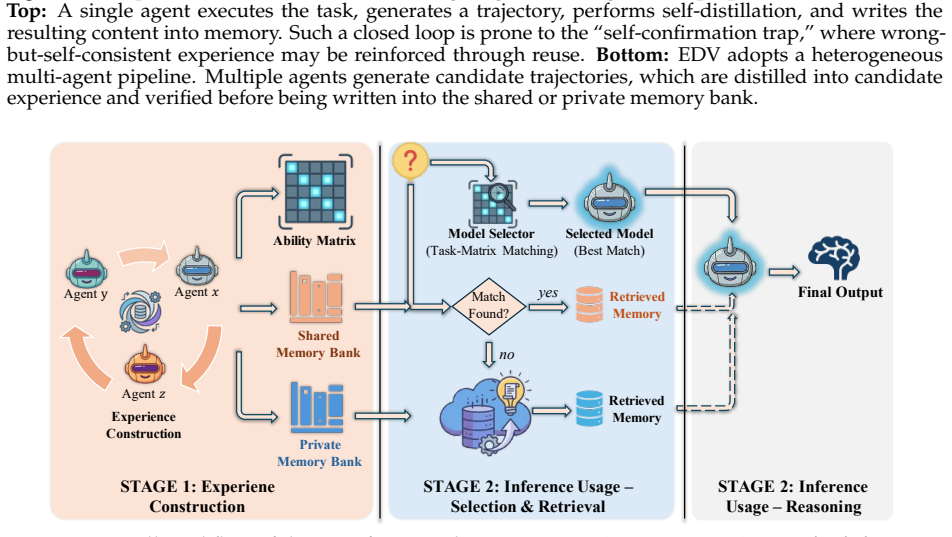
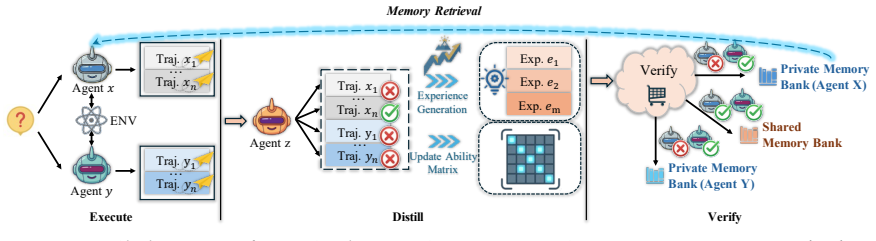
The authors claim that the Execute-Distill-Verify framework transforms experience learning from isolated self-reflection into collaborative construction by having multiple agents explore tasks in parallel, a dedicated distiller comparatively analyze trajectories, and a consensus step filter candidates, so that only approved experiences enter shared or private memory and erroneous content is excluded before reuse.
What carries the argument
The three-stage EDV decoupling that separates trajectory generation by heterogeneous executors, comparative distillation by a third-party agent, and consensus verification by the execution group.
If this is right
- Agents accumulate fewer cumulative errors during later retrieval and reuse of stored experiences.
- Performance gains appear on long-horizon benchmarks that require repeated use of prior experience.
- Experience memory can be written to both shared and private stores with lower noise.
- Self-evolution through open-world interaction becomes more robust once the three stages are decoupled.
Where Pith is reading between the lines
- The same separation of roles could be tested on non-agent LLM workflows that rely on self-generated training signals.
- Scaling the number of heterogeneous executors might further increase trajectory diversity and reduce residual bias.
- If consensus verification proves stable, it could reduce reliance on external human review for memory curation.
Load-bearing premise
The Verify-stage consensus run by the same execution agents can reliably separate correct experiences from self-consistent errors without reintroducing the original confirmation bias or new group biases.
What would settle it
A controlled test on tasks with known ground-truth trajectories where the Verify consensus approves a high fraction of known-incorrect but internally consistent trajectories at rates comparable to single-agent baselines.
Figures

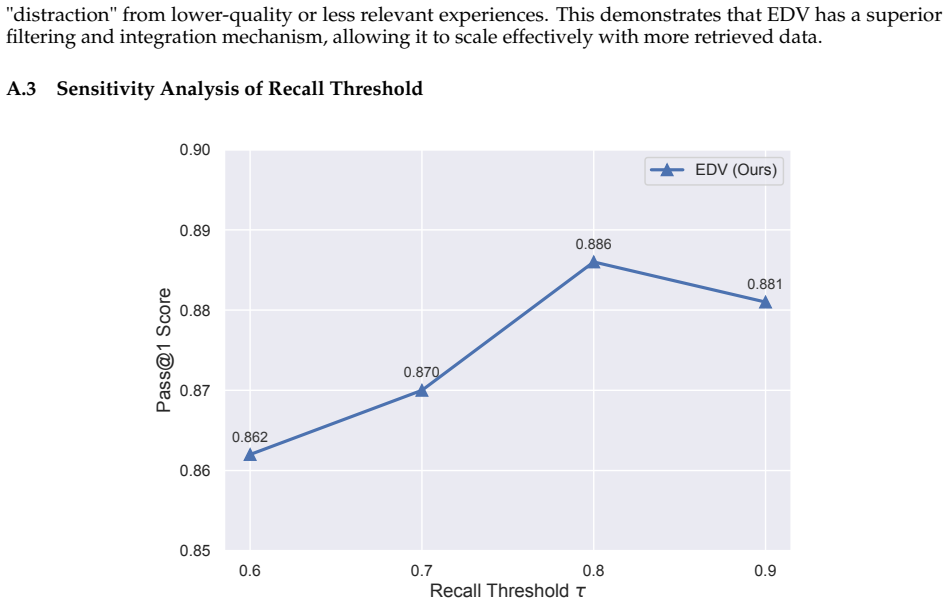





read the original abstract
Experience-driven self-evolution is critical for large language model (LLM) agents to improve through open-world interaction. However, existing experience learning methods mostly rely on single-agent loops, where the same agent executes tasks, summarizes outcomes, and determines memory content. This setup makes agents vulnerable to the Self-Confirmation Trap: wrong-but-self-consistent trajectories are misidentified as successful experience, leading to cumulative errors during retrieval and reuse. To address this issue, we propose EDV, an Execute-Distill-Verify framework for reliable experience learning. In the Execute stage, multiple heterogeneous agents explore the same task space in parallel to generate diverse candidate trajectories. In the Distill stage, a dedicated third-party agent comparatively analyzes these trajectories to produce candidate experiences, reducing executor-centric summarization bias. In the Verify stage, the execution group validates candidates via a consensus mechanism, and only approved experiences are written into shared or private memory. By decoupling the three stages, EDV transforms experience learning from isolated self-reflection into collaborative construction, filtering erroneous and noisy content before memory insertion. We evaluate EDV on three challenging long-horizon benchmarks: tau2-bench, Mind2Web and MMTB. Results show EDV consistently outperforms strong baselines, validating that reliable experience construction is essential for robust agent self-evolution. Our code is available at https://github.com/shidingz/EDV.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the EDV (Execute-Distill-Verify) framework to address the self-confirmation trap in LLM agent experience learning. Multiple heterogeneous agents generate diverse trajectories in parallel during Execute; a dedicated third-party agent comparatively analyzes them to distill candidate experiences during Distill; and the execution group validates candidates via consensus during Verify, with only approved experiences inserted into memory. The authors claim this decoupling filters erroneous content more reliably than single-agent self-reflection loops and report consistent outperformance over strong baselines on the tau2-bench, Mind2Web, and MMTB benchmarks.
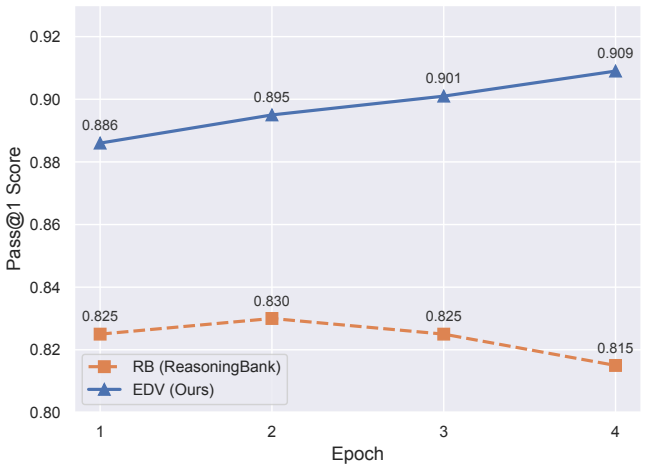
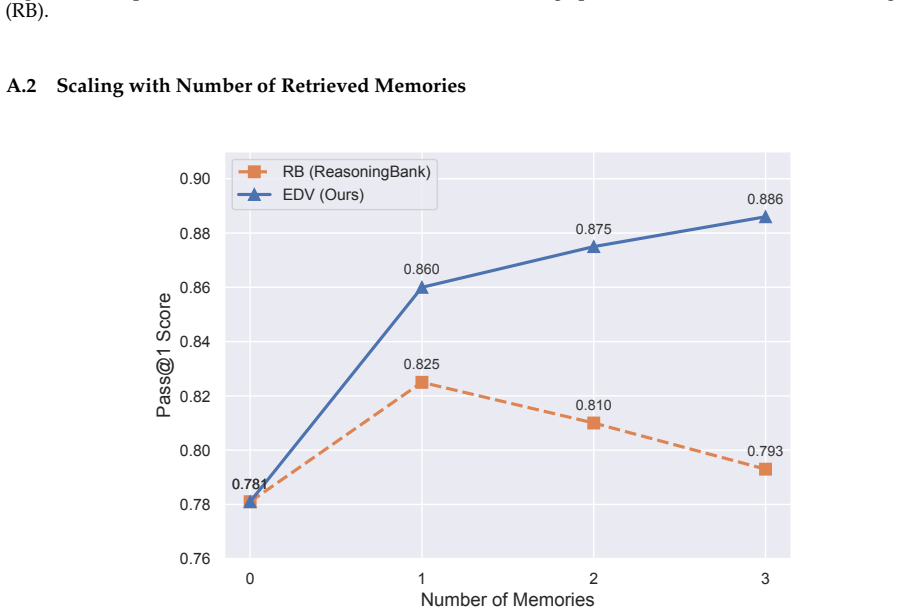
Significance. If the empirical results and filtering mechanism hold under detailed scrutiny, the work provides a concrete collaborative architecture that could improve the robustness of experience-driven self-evolution in LLM agents. The public code release is a clear strength that enables direct verification and extension.
major comments (2)
- Abstract (Verify stage): the central claim that consensus 'filters erroneous and noisy content' before memory insertion is load-bearing, yet the description supplies no implementation details on voting procedure, agreement threshold, disagreement resolution, or safeguards against correlated reasoning flaws among the same execution agents that generated the trajectories.
- Abstract (results claim): the statement that 'EDV consistently outperforms strong baselines' on three long-horizon benchmarks lacks any quantitative deltas, ablation on the consensus step, or controls for group bias, leaving the outperformance evidence under-supported relative to the filtering guarantee.
minor comments (1)
- The distinction between 'shared or private memory' is mentioned but not elaborated, which could affect how the framework scales.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the EDV framework. We address the two major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: Abstract (Verify stage): the central claim that consensus 'filters erroneous and noisy content' before memory insertion is load-bearing, yet the description supplies no implementation details on voting procedure, agreement threshold, disagreement resolution, or safeguards against correlated reasoning flaws among the same execution agents that generated the trajectories.
Authors: We agree the abstract is high-level and will revise it to include a concise description of the consensus procedure (majority vote requiring two-thirds agreement), disagreement handling (via re-execution or third-party arbitration), and the use of heterogeneous agents to reduce correlated flaws. These elements are already detailed in Section 3.3; the revision will make the abstract self-contained while preserving its length constraints. revision: yes
-
Referee: Abstract (results claim): the statement that 'EDV consistently outperforms strong baselines' on three long-horizon benchmarks lacks any quantitative deltas, ablation on the consensus step, or controls for group bias, leaving the outperformance evidence under-supported relative to the filtering guarantee.
Authors: We will update the abstract to report specific performance deltas from our experiments. The manuscript already contains an ablation isolating the Verify/consensus stage (Section 4.3) and describes the heterogeneous-agent design in Section 3.1 as a control for group bias. We are prepared to add further explicit controls or experiments if the referee recommends them. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical Execute-Distill-Verify framework evaluated on external benchmarks (tau2-bench, Mind2Web, MMTB) with no equations, fitted parameters, or mathematical derivations. Claims rest on experimental comparisons rather than self-referential definitions, self-citation chains, or reductions of predictions to inputs by construction. The architecture is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Single-agent experience loops create a self-confirmation trap that produces cumulative errors during retrieval and reuse.
- domain assumption Heterogeneous parallel execution plus third-party distillation plus consensus verification can filter erroneous trajectories before memory insertion.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2509.25140 , year=
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory , author=. arXiv preprint arXiv:2509.25140 , year=
-
[2]
arXiv preprint arXiv:2510.08529 , year=
CoMAS: Co-Evolving Multi-Agent Systems via Interaction Rewards , author=. arXiv preprint arXiv:2510.08529 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
Mind2web: Towards a generalist agent for the web , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2506.07982 , year=
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. arXiv preprint arXiv:2506.07982 , year=
-
[5]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[6]
arXiv preprint arXiv:2504.02623 , year=
Multi-mission tool bench: Assessing the robustness of llm based agents through related and dynamic missions , author=. arXiv preprint arXiv:2504.02623 , year=
-
[7]
arXiv preprint arXiv:2411.15594 , year =
A Survey on LLM-as-a-Judge , author =. arXiv preprint arXiv:2411.15594 , year =
-
[8]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[9]
2025 , howpublished =
2025
-
[10]
2025 , url=
MiMo-V2-Flash Technical Report , author=. 2025 , url=
2025
-
[11]
2023 , url =
He, Pengcheng and Gao, Jianfeng and Chen, Weizhu , booktitle =. 2023 , url =
2023
-
[12]
arXiv preprint arXiv:2107.03374 , year=
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[13]
arXiv preprint arXiv:2510.16079 , year=
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle , author=. arXiv preprint arXiv:2510.16079 , year=
-
[14]
arXiv preprint arXiv:2404.09982 , year=
Memory sharing for large language model based agents , author=. arXiv preprint arXiv:2404.09982 , year=
-
[15]
arXiv preprint arXiv:2511.06449 , year=
Flex: Continuous agent evolution via forward learning from experience , author=. arXiv preprint arXiv:2511.06449 , year=
-
[16]
arXiv preprint arXiv:2510.08191 , year=
Training-free group relative policy optimization , author=. arXiv preprint arXiv:2510.08191 , year=
-
[17]
arXiv preprint arXiv:2505.16997 , year=
X-MAS: Towards Building Multi-Agent Systems with Heterogeneous LLMs , author=. arXiv preprint arXiv:2505.16997 , year=
-
[18]
arXiv preprint arXiv:2510.08558 , year=
Agent learning via early experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[19]
2023 , month = sep, howpublished =
MindAct\_CandidateGeneration\_deberta-v3-base , author =. 2023 , month = sep, howpublished =
2023
-
[20]
arXiv preprint arXiv:2504.01990 , year=
Advances and challenges in foundation agents: From brain-inspired intelligence to evolutionary, collaborative, and safe systems , author=. arXiv preprint arXiv:2504.01990 , year=
-
[21]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[22]
arXiv preprint arXiv:2511.10395 , year=
Agentevolver: Towards efficient self-evolving agent system , author=. arXiv preprint arXiv:2511.10395 , year=
-
[23]
arXiv preprint arXiv:2512.17260 , year=
Seed-prover 1.5: Mastering undergraduate-level theorem proving via learning from experience , author=. arXiv preprint arXiv:2512.17260 , year=
-
[24]
arXiv preprint arXiv:2511.18423 , year=
General agentic memory via deep research , author=. arXiv preprint arXiv:2511.18423 , year=
-
[25]
arXiv preprint arXiv:2510.23595 , year=
Multi-agent evolve: Llm self-improve through co-evolution , author=. arXiv preprint arXiv:2510.23595 , year=
-
[26]
arXiv preprint arXiv:2410.16670 , year=
Cops: Empowering llm agents with provable cross-task experience sharing , author=. arXiv preprint arXiv:2410.16670 , year=
-
[27]
arXiv preprint arXiv:2506.14234 , year=
Xolver: Multi-Agent Reasoning with Holistic Experience Learning Just Like an Olympiad Team , author=. arXiv preprint arXiv:2506.14234 , year=
-
[28]
arXiv preprint arXiv:2510.08002 , year=
Learning on the job: An experience-driven self-evolving agent for long-horizon tasks , author=. arXiv preprint arXiv:2510.08002 , year=
-
[29]
arXiv preprint arXiv:2508.00271 , year=
MetaAgent: Toward Self-Evolving Agent via Tool Meta-Learning , author=. arXiv preprint arXiv:2508.00271 , year=
-
[30]
arXiv preprint arXiv:2512.17102 , year=
Reinforcement learning for self-improving agent with skill library , author=. arXiv preprint arXiv:2512.17102 , year=
-
[31]
arXiv preprint arXiv:2511.03773 , year=
Scaling agent learning via experience synthesis , author=. arXiv preprint arXiv:2511.03773 , year=
-
[32]
arXiv preprint arXiv:2512.02472 , year=
Guided self-evolving llms with minimal human supervision , author=. arXiv preprint arXiv:2512.02472 , year=
-
[33]
arXiv preprint arXiv:2511.20639 , year=
Latent collaboration in multi-agent systems , author=. arXiv preprint arXiv:2511.20639 , year=
-
[34]
arXiv preprint arXiv:2503.05944 , year=
Enhancing reasoning with collaboration and memory , author=. arXiv preprint arXiv:2503.05944 , year=
-
[35]
arXiv preprint arXiv:2411.02337 , year=
Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning , author=. arXiv preprint arXiv:2411.02337 , year=
-
[36]
arXiv preprint arXiv:2402.17574 , year=
Agent-pro: Learning to evolve via policy-level reflection and optimization , author=. arXiv preprint arXiv:2402.17574 , year=
-
[37]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Contextual Experience Replay for Self-Improvement of Language Agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[38]
arXiv preprint arXiv:2509.24704 , year=
Memgen: Weaving generative latent memory for self-evolving agents , author=. arXiv preprint arXiv:2509.24704 , year=
-
[39]
arXiv preprint arXiv:2511.20857 , year=
Evo-Memory: Benchmarking LLM Agent Test-time Learning with Self-Evolving Memory , author=. arXiv preprint arXiv:2511.20857 , year=
-
[40]
arXiv preprint arXiv:2506.21605 , year=
MemBench: Towards More Comprehensive Evaluation on the Memory of LLM-based Agents , author=. arXiv preprint arXiv:2506.21605 , year=
-
[41]
The Thirteenth International Conference on Learning Representations , year=
Breaking mental set to improve reasoning through diverse multi-agent debate , author=. The Thirteenth International Conference on Learning Representations , year=
-
[42]
arXiv preprint arXiv:2505.07313 , year=
Towards multi-agent reasoning systems for collaborative expertise delegation: An exploratory design study , author=. arXiv preprint arXiv:2505.07313 , year=
-
[43]
Journal of King Saud University Computer and Information Sciences , volume=
Adaptive heterogeneous multi-agent debate for enhanced educational and factual reasoning in large language models , author=. Journal of King Saud University Computer and Information Sciences , volume=. 2025 , publisher=
2025
-
[44]
arXiv preprint arXiv:2503.06072 , year=
Large Language Models Post-training: Surveying Techniques from Alignment to Reasoning , author=. arXiv preprint arXiv:2503.06072 , year=
-
[45]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A survey of post-training scaling in large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
arXiv preprint arXiv:2312.01058 , year=
A survey of progress on cooperative multi-agent reinforcement learning in open environment , author=. arXiv preprint arXiv:2312.01058 , year=
-
[47]
Judging the judges: A systematic study of position bias in llm-as-a-judge , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[48]
arXiv preprint arXiv:2406.18665 , year=
Routellm: Learning to route llms with preference data , author=. arXiv preprint arXiv:2406.18665 , year=
-
[49]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[50]
2018 , publisher=
Improving language understanding by generative pre-training , author=. 2018 , publisher=
2018
-
[51]
OpenAI blog , volume=
Language models are unsupervised multitask learners , author=. OpenAI blog , volume=
-
[52]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[53]
arXiv preprint arXiv:2303.08774 , year=
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
-
[54]
What can researchers do? , author=
The AI revolution is running out of data. What can researchers do? , author=. Nature , volume=. 2024 , publisher=
2024
-
[55]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Revisiting scaling laws for language models: The role of data quality and training strategies , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[56]
arXiv preprint arXiv:2402.10669 , year=
Humans or llms as the judge? a study on judgement biases , author=. arXiv preprint arXiv:2402.10669 , year=
-
[57]
arXiv preprint arXiv:2412.12509 , year=
Can you trust llm judgments? reliability of llm-as-a-judge , author=. arXiv preprint arXiv:2412.12509 , year=
-
[58]
arXiv preprint arXiv:2203.11171 , year=
Self-consistency improves chain of thought reasoning in language models , author=. arXiv preprint arXiv:2203.11171 , year=
-
[59]
arXiv preprint arXiv:2310.01798 , year=
Large language models cannot self-correct reasoning yet , author=. arXiv preprint arXiv:2310.01798 , year=
-
[60]
arXiv preprint arXiv:2406.04692 , year=
Mixture-of-agents enhances large language model capabilities , author=. arXiv preprint arXiv:2406.04692 , year=
-
[61]
arXiv preprint arXiv:2402.05120 , year=
More agents is all you need , author=. arXiv preprint arXiv:2402.05120 , year=
-
[62]
arXiv preprint arXiv:2305.17493 , year=
The curse of recursion: Training on generated data makes models forget , author=. arXiv preprint arXiv:2305.17493 , year=
-
[63]
Advances in Neural Information Processing Systems , volume=
Toward self-improvement of llms via imagination, searching, and criticizing , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
arXiv preprint arXiv:2408.07199 , year=
Agent q: Advanced reasoning and learning for autonomous ai agents , author=. arXiv preprint arXiv:2408.07199 , year=
-
[65]
Advances in neural information processing systems , volume=
Camel: Communicative agents for" mind" exploration of large language model society , author=. Advances in neural information processing systems , volume=
-
[66]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Chatdev: Communicative agents for software development , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[67]
The twelfth international conference on learning representations , year=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. The twelfth international conference on learning representations , year=
-
[68]
The Twelfth International Conference on Learning Representations , year=
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors , author=. The Twelfth International Conference on Learning Representations , year=
-
[69]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[70]
First Conference on Language Modeling , year=
A dynamic LLM-powered agent network for task-oriented agent collaboration , author=. First Conference on Language Modeling , year=
-
[71]
Self-contrast: Better reflection through inconsistent solving perspectives , author=
-
[72]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large language model , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[73]
arXiv preprint arXiv:2502.12110 , year=
A-mem: Agentic memory for llm agents , author=. arXiv preprint arXiv:2502.12110 , year=
-
[74]
arXiv preprint arXiv:2601.03192 , year=
Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory , author=. arXiv preprint arXiv:2601.03192 , year=
-
[75]
arXiv preprint arXiv:2402.01680 , year=
Large language model based multi-agents: A survey of progress and challenges , author=. arXiv preprint arXiv:2402.01680 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.