FrameVGGT: Coherence-Preserving Memory for Bounded Streaming Geometry
Pith reviewed 2026-05-15 14:38 UTC · model grok-4.3
The pith
FrameVGGT organizes each frame's KV contribution as a coherent segment summarized by key-space prototypes to bound memory while preserving multi-view geometric support in streaming VGGT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
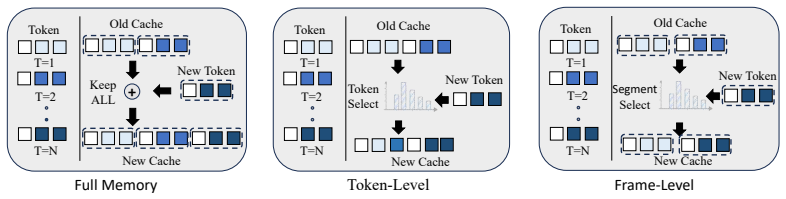
FrameVGGT is a bounded explicit-memory framework that organizes each frame's incremental KV contribution as a coherent frame-level segment. It summarizes each segment with a lightweight key-space prototype and maintains a fixed-capacity memory of complementary segments, with an optional sparse anchor tier for difficult long-horizon intervals. This yields favorable accuracy-memory trade-offs across long-sequence 3D reconstruction, video depth estimation, and camera pose estimation while maintaining more stable geometry over long streams.
What carries the argument
frame-level KV segments summarized by lightweight key-space prototypes that preserve redundant multi-view geometric support within bounded memory
If this is right
- Frame-level organization avoids fragmenting within-frame evidence under fixed memory budgets.
- More stable geometry is maintained over long streams than with token-level retention.
- Favorable accuracy-memory trade-offs hold across 3D reconstruction, video depth estimation, and camera pose estimation.
- Optional sparse anchors extend support to difficult long-horizon intervals without exceeding capacity.
Where Pith is reading between the lines
- The design implies that geometric tasks gain more from preserving frame-level coherence than from token-level compression, unlike language-model caching.
- Adaptive segment selection based on geometric uncertainty could extend efficiency gains to scenes with varying complexity.
- The approach may transfer to other streaming multi-view problems such as visual SLAM where long-term consistency matters.
Load-bearing premise
Summarizing each frame's KV contribution into a key-space prototype retains the redundant multi-view information needed for coherent geometric reasoning.
What would settle it
A controlled experiment on long-sequence 3D reconstruction showing that token-level retention under identical memory limits produces higher accuracy or greater long-term stability than FrameVGGT would falsify the central claim.
Figures










read the original abstract
Streaming Visual Geometry Transformers such as StreamVGGT enable strong online 3D perception, but their KV-cache grows unbounded over long streams, limiting practical deployment. We study bounded-memory streaming geometry from the perspective of memory organization: unlike language modeling, where useful information can often be compressed at token level, geometry-driven inference relies on coherent and mutually compatible observations across views. Under fixed memory budgets, retaining history as isolated entries can progressively fragment the geometric context needed for stable long-horizon matching and fusion. We therefore propose \textbf{FrameVGGT}, a bounded-memory framework that maintains a fixed-capacity set of complementary memory units for streaming geometry. In our implementation, each unit is instantiated as a frame-wise KV segment summarized by a compact key-space prototype, together with a sparse anchor tier for persistent long-range references. Across long-sequence 3D reconstruction, video depth estimation, and camera pose estimation, FrameVGGT achieves favorable accuracy--memory trade-offs under bounded budgets while maintaining more stable geometry over long streams.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FrameVGGT, a bounded explicit-memory framework for streaming Visual Geometry Transformers. It organizes each frame's incremental KV contribution as a coherent frame-level segment, summarizes segments via lightweight key-space prototypes, maintains a fixed-capacity memory of complementary segments, and adds an optional sparse anchor tier for difficult long-horizon intervals. The central claim is that this geometry-aligned design yields favorable accuracy-memory trade-offs under bounded memory while delivering more stable geometry than token-level retention across long-sequence 3D reconstruction, video depth estimation, and camera pose estimation.
Significance. If the empirical claims hold, the work addresses a practical deployment barrier in online 3D perception by replacing unbounded KV growth with a fixed-budget, frame-coherent memory that better preserves multi-view geometric support. The design choice is motivated by domain observation rather than parameter fitting, and the optional anchor tier offers a concrete mechanism for handling long-horizon drift.
major comments (3)
- [Abstract] Abstract: the claim of 'favorable accuracy-memory trade-offs' and 'more stable geometry' is stated without any quantitative results, ablation tables, or error metrics, so the magnitude and reliability of the improvement cannot be assessed from the provided text.
- [Method] Method (frame-level segment and key-space prototype construction): the central assumption that lightweight prototypes on frame-level segments preserve the redundant multi-view evidence (epipolar consistency, depth coherence) required for stable long-horizon geometry is not directly tested; no measurement of information loss relative to the original token-level KV is reported, leaving the bounded-memory advantage unverified.
- [Experiments] Experiments: without reported numbers on memory usage, accuracy deltas, or stability metrics (e.g., pose drift over sequence length) for the three tasks, it is impossible to confirm that the prototype summarization does not discard the very geometric constraints that token-level retention is said to fragment.
minor comments (1)
- [Method] Notation for 'key-space prototype' and 'sparse anchor tier' should be defined with explicit equations or pseudocode on first use to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to strengthen the quantitative support and clarity of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'favorable accuracy-memory trade-offs' and 'more stable geometry' is stated without any quantitative results, ablation tables, or error metrics, so the magnitude and reliability of the improvement cannot be assessed from the provided text.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised version we will insert concise highlights of key results (e.g., memory reduction percentages, accuracy deltas, and stability metrics across the three tasks) drawn directly from the experimental tables. revision: yes
-
Referee: [Method] Method (frame-level segment and key-space prototype construction): the central assumption that lightweight prototypes on frame-level segments preserve the redundant multi-view evidence (epipolar consistency, depth coherence) required for stable long-horizon geometry is not directly tested; no measurement of information loss relative to the original token-level KV is reported, leaving the bounded-memory advantage unverified.
Authors: This is a fair observation. While downstream task performance provides indirect evidence, we will add a targeted analysis (new subsection or appendix) that quantifies information preservation, for instance by reporting geometric consistency metrics or reconstruction fidelity differences between full token-level KV and the prototype summaries. revision: yes
-
Referee: [Experiments] Experiments: without reported numbers on memory usage, accuracy deltas, or stability metrics (e.g., pose drift over sequence length) for the three tasks, it is impossible to confirm that the prototype summarization does not discard the very geometric constraints that token-level retention is said to fragment.
Authors: The manuscript already contains these metrics in the experimental section, including tables for memory usage, accuracy deltas, and long-sequence stability (pose drift) on all three tasks. We will revise the text to make these results more explicitly linked to the method claims and to reference them from the abstract and method sections. revision: partial
Circularity Check
No circularity: design motivated by domain observation, no equations or self-referential reductions
full rationale
The paper introduces FrameVGGT as an architectural proposal for bounded-memory streaming visual geometry transformers. It is motivated by the stated observation that geometry depends on redundant multi-view support which token-level KV retention can fragment. The framework organizes frame-level segments, applies lightweight key-space prototypes, and maintains fixed-capacity memory with an optional sparse anchor tier. No equations, derivations, or fitted parameters are presented that reduce the central claims to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The claims rest on empirical accuracy-memory trade-offs across reconstruction, depth, and pose tasks rather than any self-referential chain. This qualifies as a self-contained design choice evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- fixed memory capacity
axioms (1)
- domain assumption Geometry-driven reasoning depends on redundant and mutually compatible multi-view support.
invented entities (3)
-
frame-level segment
no independent evidence
-
key-space prototype
no independent evidence
-
sparse anchor tier
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FrameVGGT summarizes each segment with a lightweight key-space prototype v^(l)_t = 1/(H|T_t|) Σ K^(l)_t,h,τ followed by ℓ2 normalization and cosine distance d(S_i,S_j)=1−⟨v̄_i,v̄_j⟩; selection uses coverage score m(S)=min d(S,S′) with greedy update.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We treat each frame’s incremental KV contribution as a coherent frame-level segment … maintains a fixed-capacity memory of complementary segments, with an optional sparse anchor tier.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
MyGO-Splat: Multi-Objective Closed-Loop Geometric Feedback for RGB-Only Gaussian SLAM
MyGO-Splat is a closed-loop RGB-only Gaussian SLAM system that rasterizes depth and normals from the map to supervise pose optimization and align monocular depth priors for scale consistency.
-
Good Token Hunting: A Hitchhiker's Guide to Token Selection for Visual Geometry Transformers
A two-stage diversity-plus-entropy token selection framework speeds up visual geometry transformers by over 85% on 500-image scenes while preserving baseline accuracy.
-
PanoImager: Geometry-Guided Novel View Synthesis and Reconstruction from Sparse Panoramic Views
PanoImager is an SfM-free pipeline combining feed-forward priors, geometry-conditioned diffusion view completion, and depth-guided 3DGS optimization to reconstruct from sparse panoramic images.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.